Python爬虫实战,matplotlib模块,Python实现网易云音乐歌单数据可视化 |
您所在的位置:网站首页 › python网易云音乐下载 › Python爬虫实战,matplotlib模块,Python实现网易云音乐歌单数据可视化 |
Python爬虫实战,matplotlib模块,Python实现网易云音乐歌单数据可视化
|
前言
利用Python实现网易云音乐歌单数据可视化。废话不多说。 让我们愉快地开始吧~ 开发工具Python版本: 3.6.4 相关模块: requests模块 pandas模块 matplotlib模块; 以及一些Python自带的模块。 环境搭建安装Python并添加到环境变量,pip安装需要的相关模块即可。 本次通过对网易云音乐华语歌单数据的获取,对华语歌单数据进行可视化分析。 使用matplotlib可视化库,利用这个底层库来进行可视化展示。 网页分析 歌单索引页
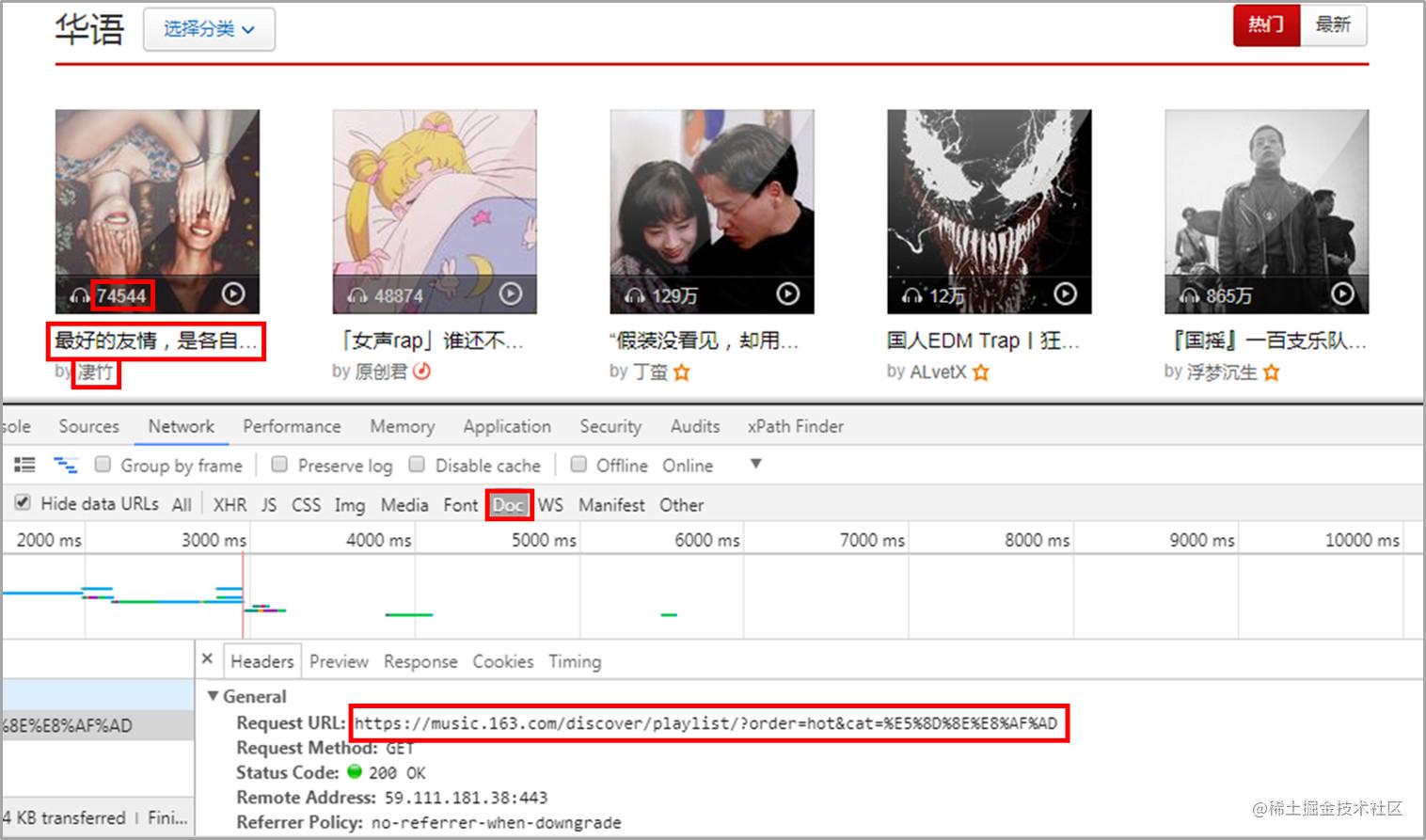
选取华语热门歌单页面。 获取歌单播放量,名称,及作者,还有歌单详情页链接。 本次一共获取了1302张华语歌单。 歌单详情页
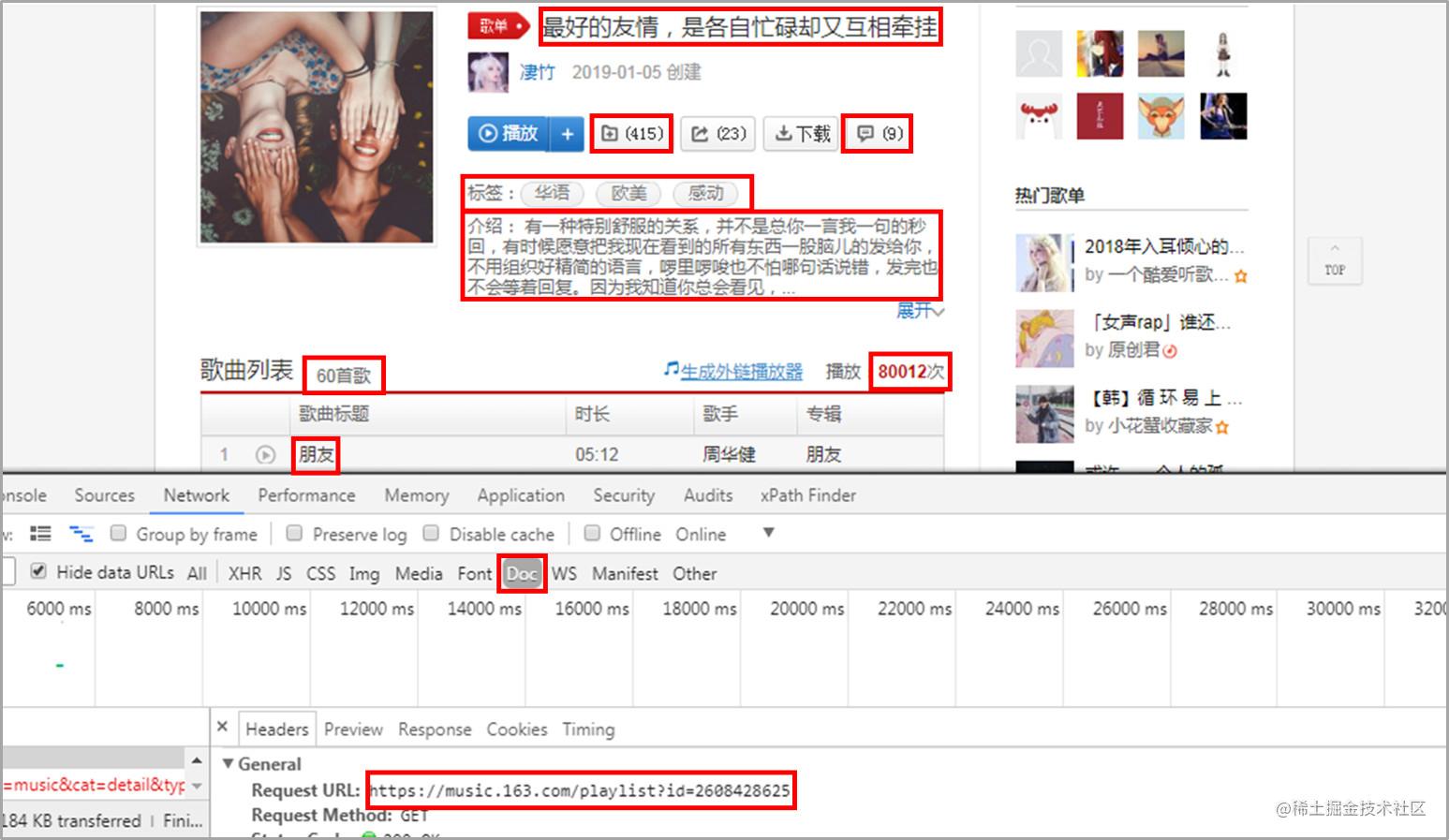
获取歌单详情页信息,信息比较多。 有歌单名,收藏量,评论数,标签,介绍,歌曲总数,播放量,收录的歌名。 这里歌曲的时长、歌手、专辑信息在网页的iframe中。 如果想要获取信息可以使用selenium 获取数据 歌单索引页 from bs4 import BeautifulSoup import requests import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } for i in range(0, 1330, 35): print(i) time.sleep(2) url = 'https://music.163.com/discover/playlist/?cat=欧美&order=hot&limit=35&offset=' + str(i) response = requests.get(url=url, headers=headers) html = response.text soup = BeautifulSoup(html, 'html.parser') # 获取包含歌单详情页网址的标签 ids = soup.select('.dec a') # 获取包含歌单索引页信息的标签 lis = soup.select('#m-pl-container li') print(len(lis)) for j in range(len(lis)): # 获取歌单详情页地址 url = ids[j]['href'] # 获取歌单标题 title = ids[j]['title'] # 获取歌单播放量 play = lis[j].select('.nb')[0].get_text() # 获取歌单贡献者名字 user = lis[j].select('p')[1].select('a')[0].get_text() # 输出歌单索引页信息 print(url, title, play, user) # 将信息写入CSV文件中 with open('playlist.csv', 'a+', encoding='utf-8-sig') as f: f.write(url + ',' + title + ',' + play + ',' + user + '\n') 复制代码通过上述代码我们获取歌单索引页信息
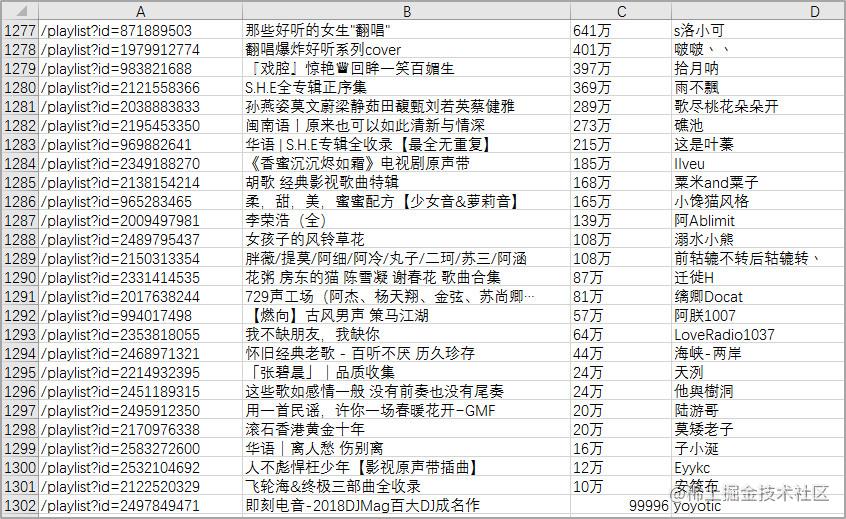
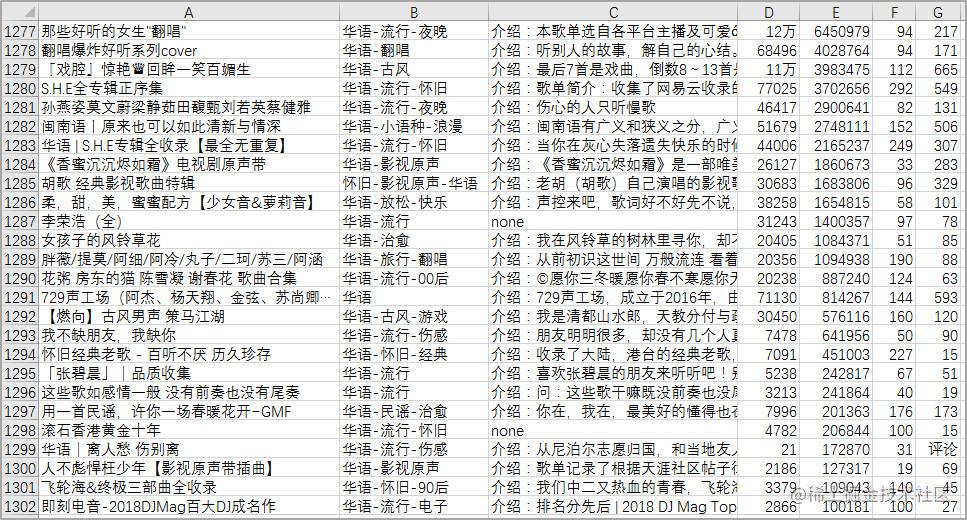
获取的1302张华语歌单的详情
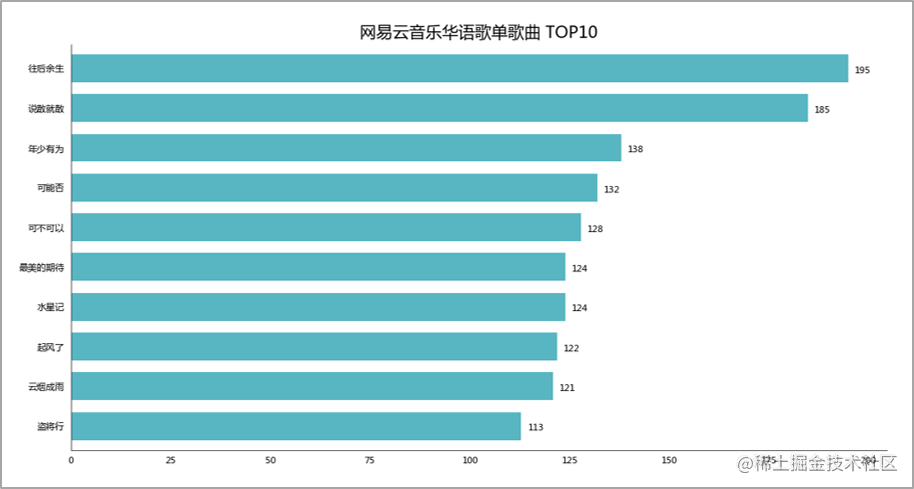
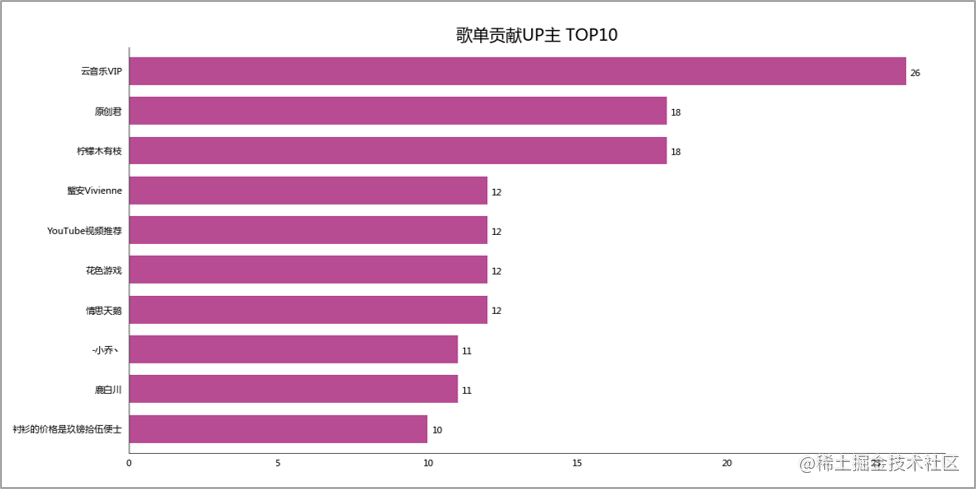
榜上的十首歌,除了「水星记」,小F听得次数都不少。 歌单贡献UP主 TOP10
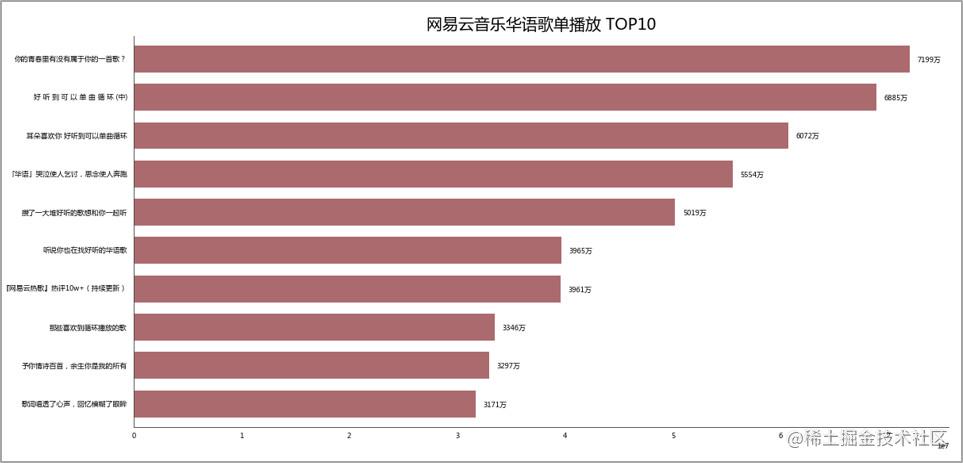
歌单播放量前十名单,第一名7000多万播放量。 歌单收藏量 TOP10
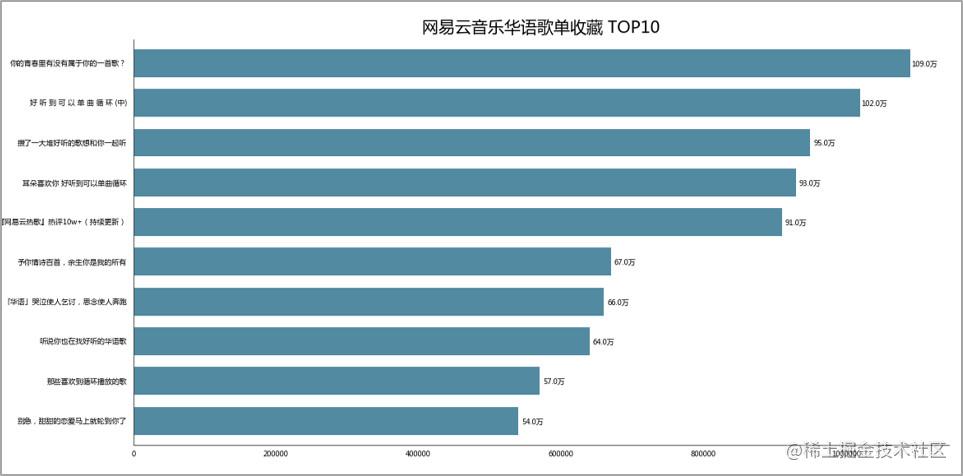
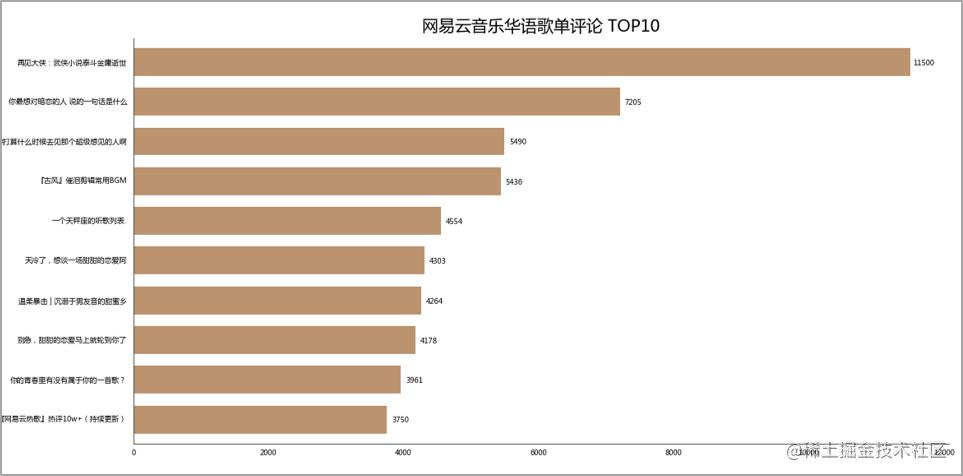
建议收藏 歌单评论数 TOP10
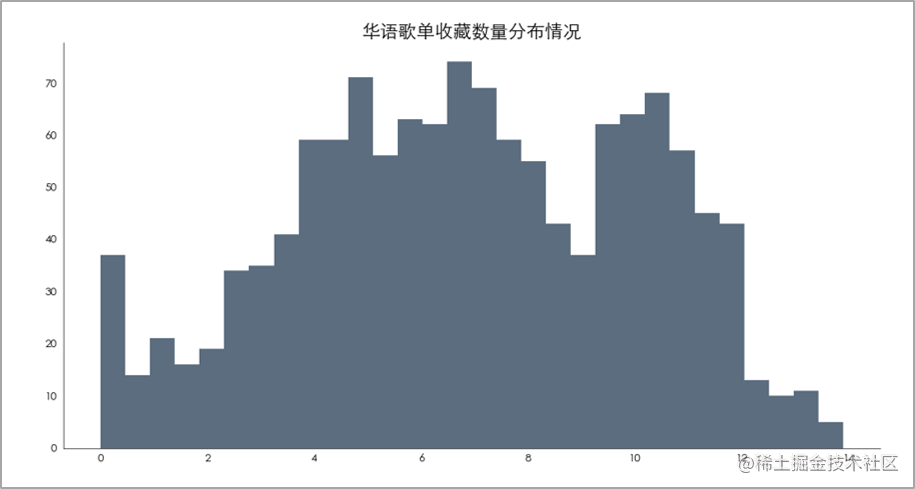
歌单「再见大侠:武侠小说泰斗金庸逝世」评论数最多。 歌单收藏数量分布情况
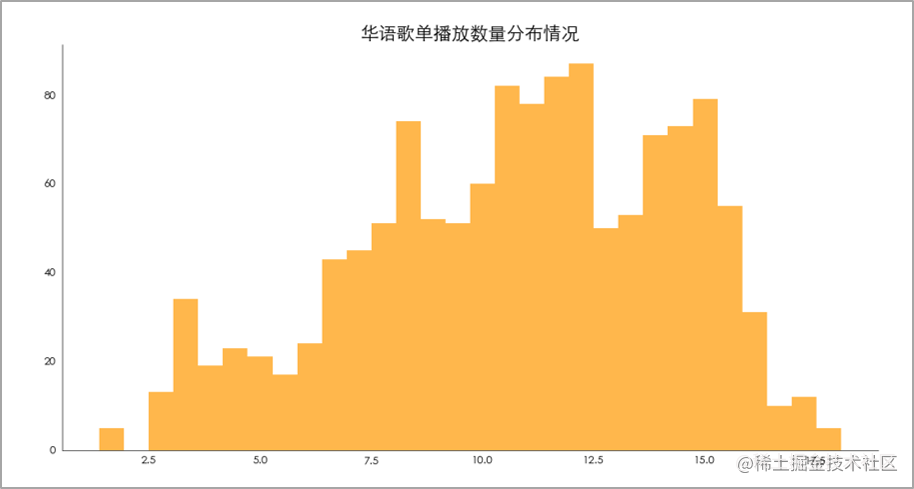
主要分布在0-15万之间(ln(150000)=12)。 歌单播放数量分布情况
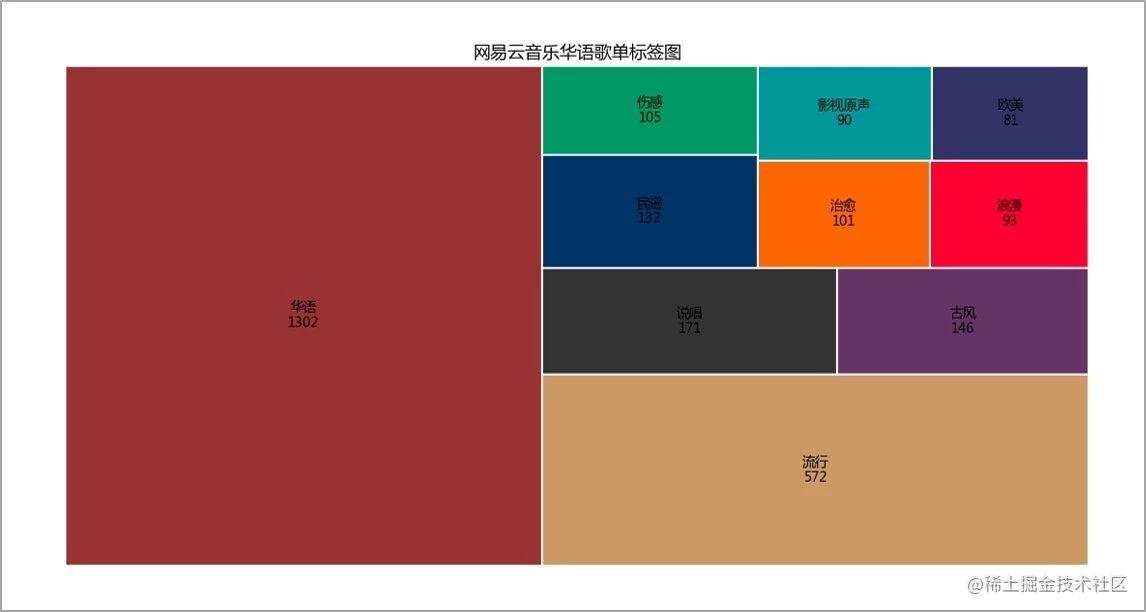
歌单播放数主要分布在0-1000万。 歌单标签图
既然选取的是华语歌单,那么华语这二字必不可少 歌单介绍词云图、
歌单介绍词云图,希望你能找到你喜欢某首歌 |

【本文地址】
今日新闻 |
推荐新闻 |