一、获得接口 url
打开百度翻译:百度翻译右键检查 或者 F12 打开控制台、点击网络这一项: 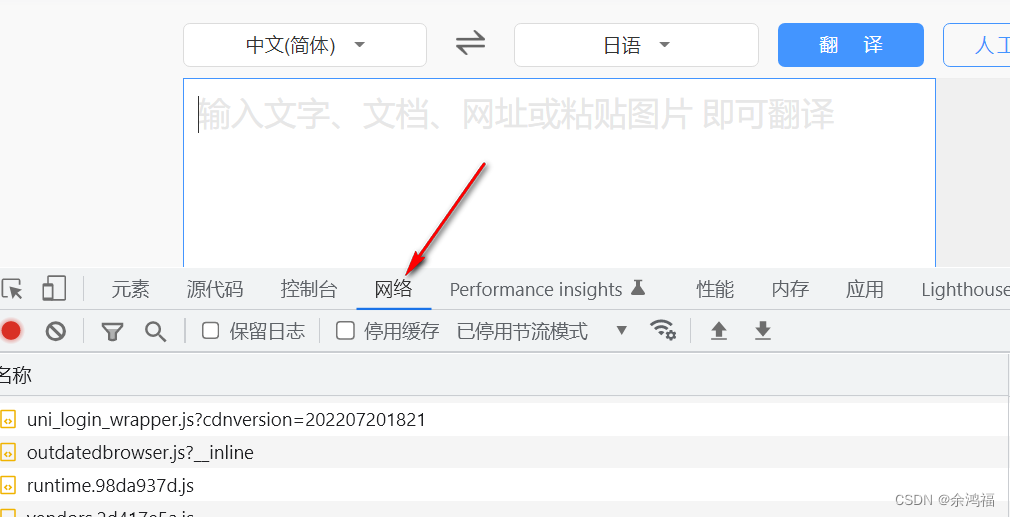 输入文字:哈哈,点击图中的过滤按钮,选择全部 输入文字:哈哈,点击图中的过滤按钮,选择全部 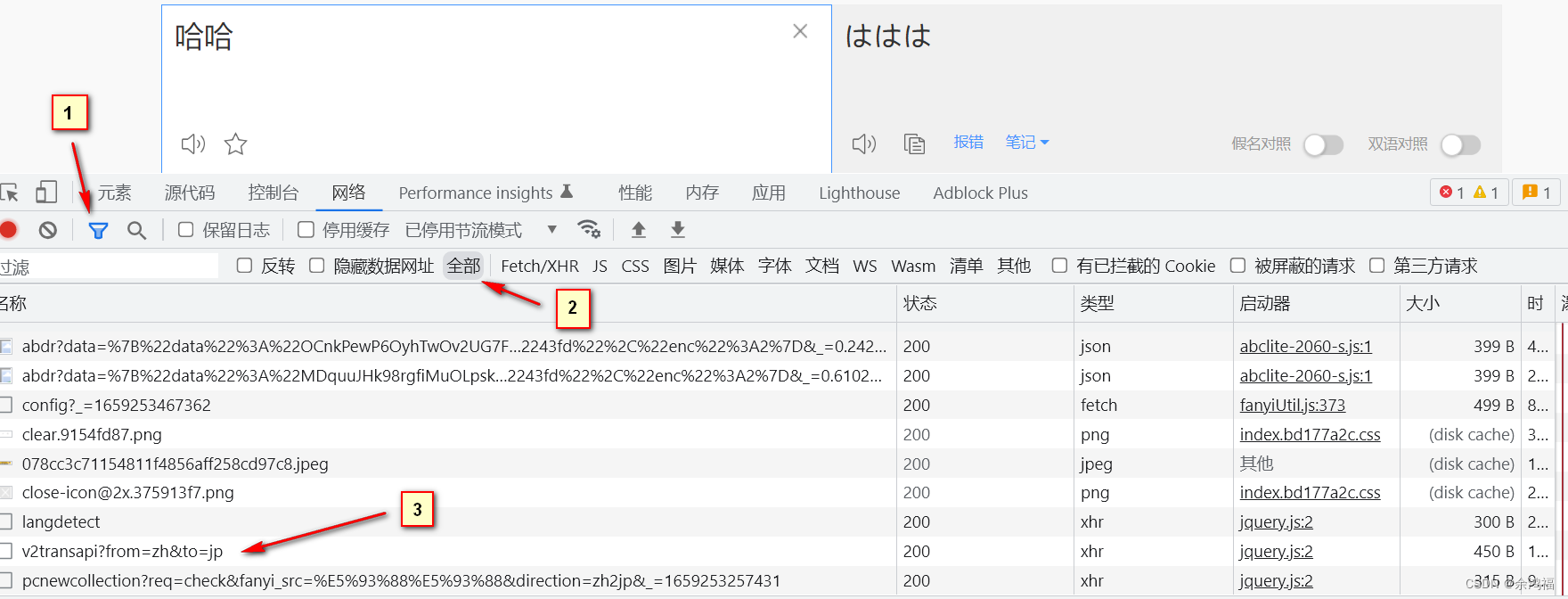 可以看到,v2transapi?from=zh&to=jp 请求的预览中就是我们需要的响应数据: 可以看到,v2transapi?from=zh&to=jp 请求的预览中就是我们需要的响应数据: 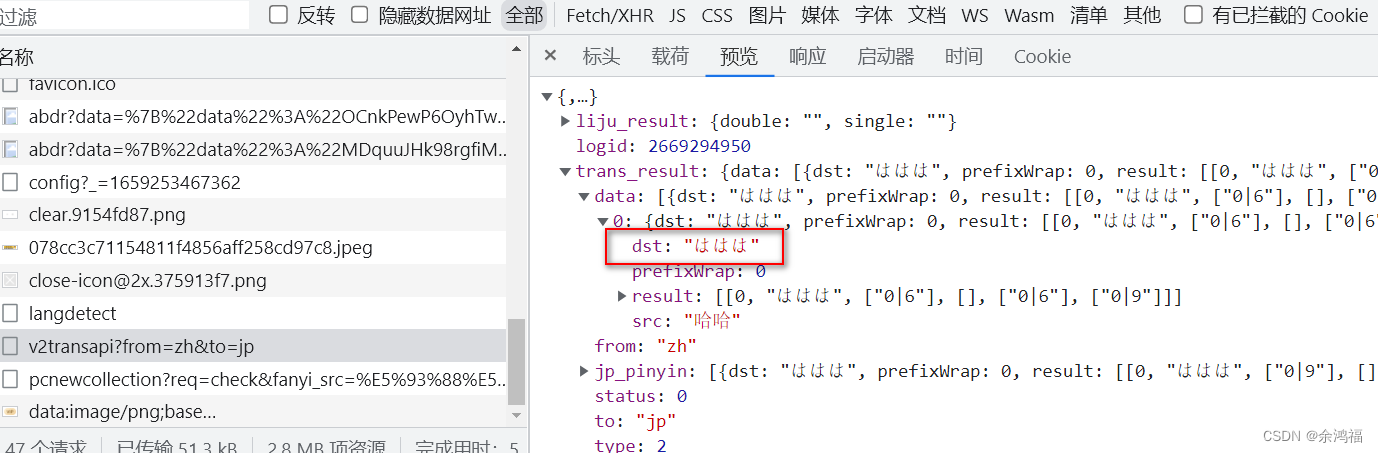 同时看到 headers 中有我们的 Cookie 字段: 同时看到 headers 中有我们的 Cookie 字段: 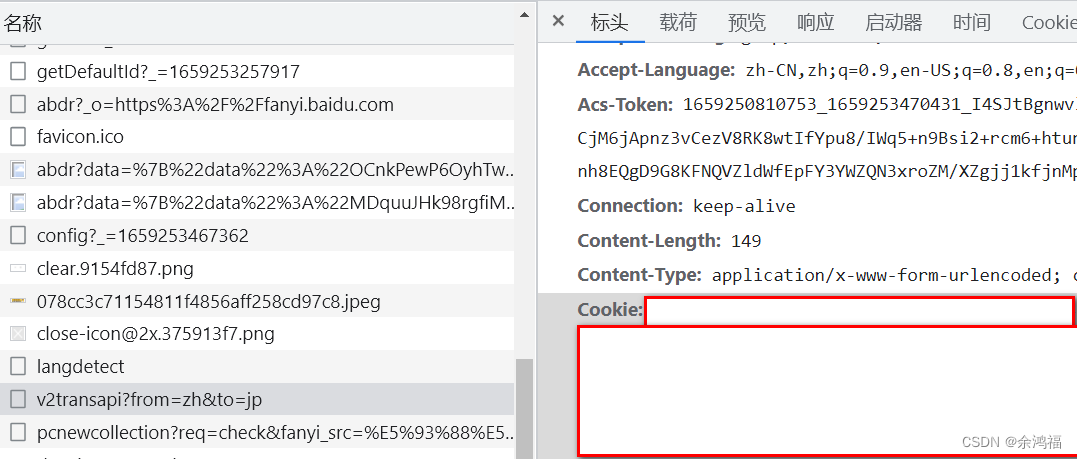 二、查看POST表单格式
二、查看POST表单格式
因为是POST请求,点击载荷看到我们的表单格式: 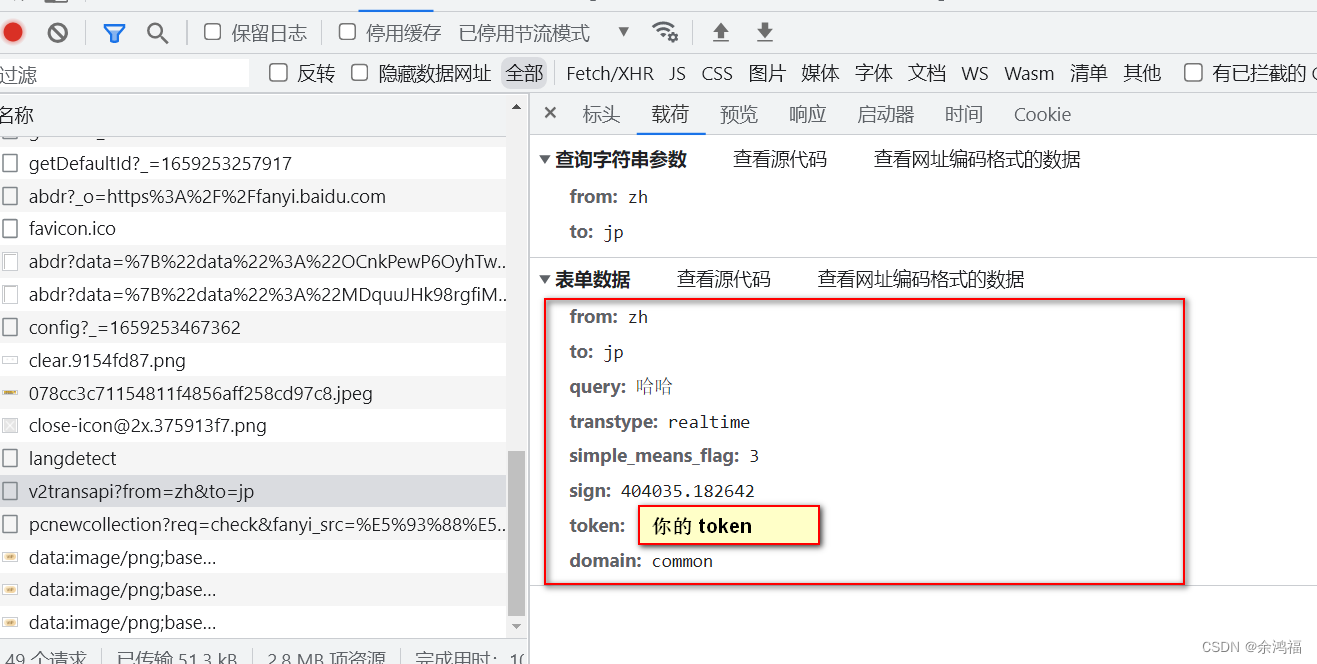
三、python 访问百度翻译 v2transapi 接口初试
将之前获得的 cookie、token 填入:
import json
import urllib.request
import urllib.parse
# 第一步中咱们知道接口是这个 url
url = 'https://fanyi.baidu.com/v2transapi?from=zh&to=jp'
# headers 必须带 Cookie,百度翻译的反扒手段之一
headers = {
'Cookie': 你的 cookie
}
# 要翻译的单词
query = '哈哈'
# 表单数据,将第二步中的kv全部复制过来
data = {
'from': 'zh',
'to': 'jp',
'query': query,
'simple_means_flag': '3',
'sign': ‘404035.182642’,
'token': 你的 token,
'domain': 'common'
}
# 封装 request 对象
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
# 调用 urlopen,获得返回值
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 用 json 可以解码返回值中的 Unicode 字符
print(json.loads(content))
运行结果:  看起来成功了!换个单词翻译试试:将 query 改为 啦啦啦 再运行: 看起来成功了!换个单词翻译试试:将 query 改为 啦啦啦 再运行:  居然是未知错误,观察我们的表单数据发现有个特殊字段:'sign': ‘404035.182642’,所以我们需要知道这个 sign 字段是如何生成的 居然是未知错误,观察我们的表单数据发现有个特殊字段:'sign': ‘404035.182642’,所以我们需要知道这个 sign 字段是如何生成的
四、探究原因
重新查看我们控制台中的接口: 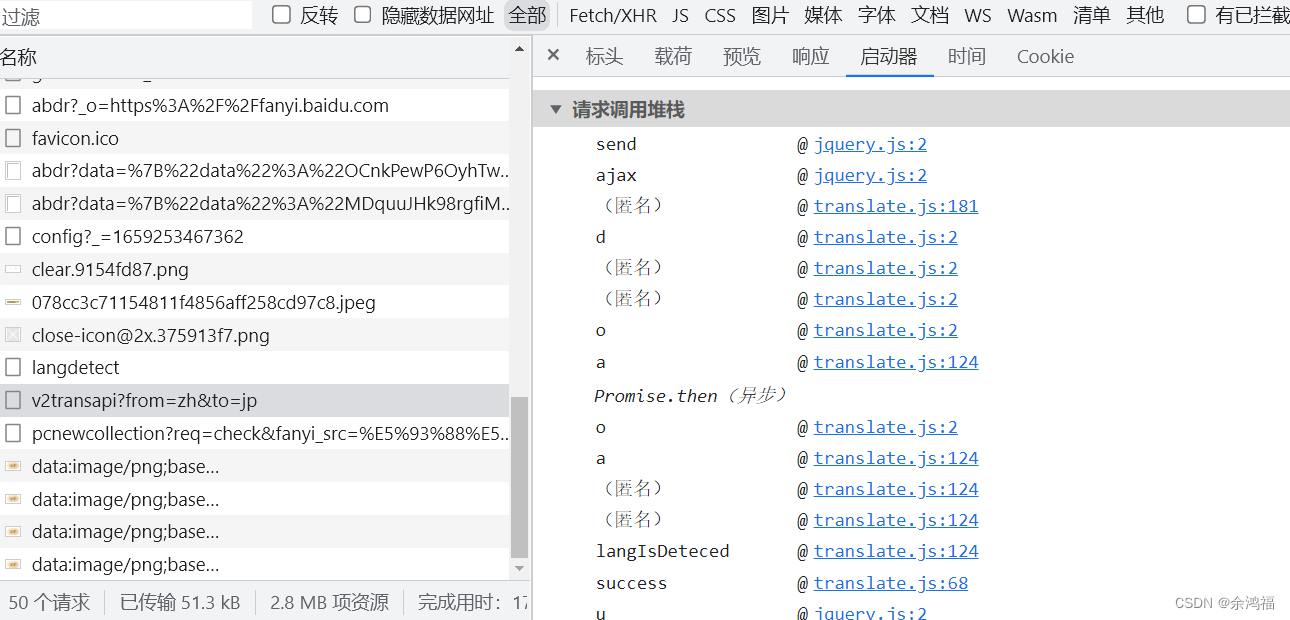 启动器中可以看到所有的调用栈,点击第一个不是 jquery 的 js:@ translate.js:181 启动器中可以看到所有的调用栈,点击第一个不是 jquery 的 js:@ translate.js:181 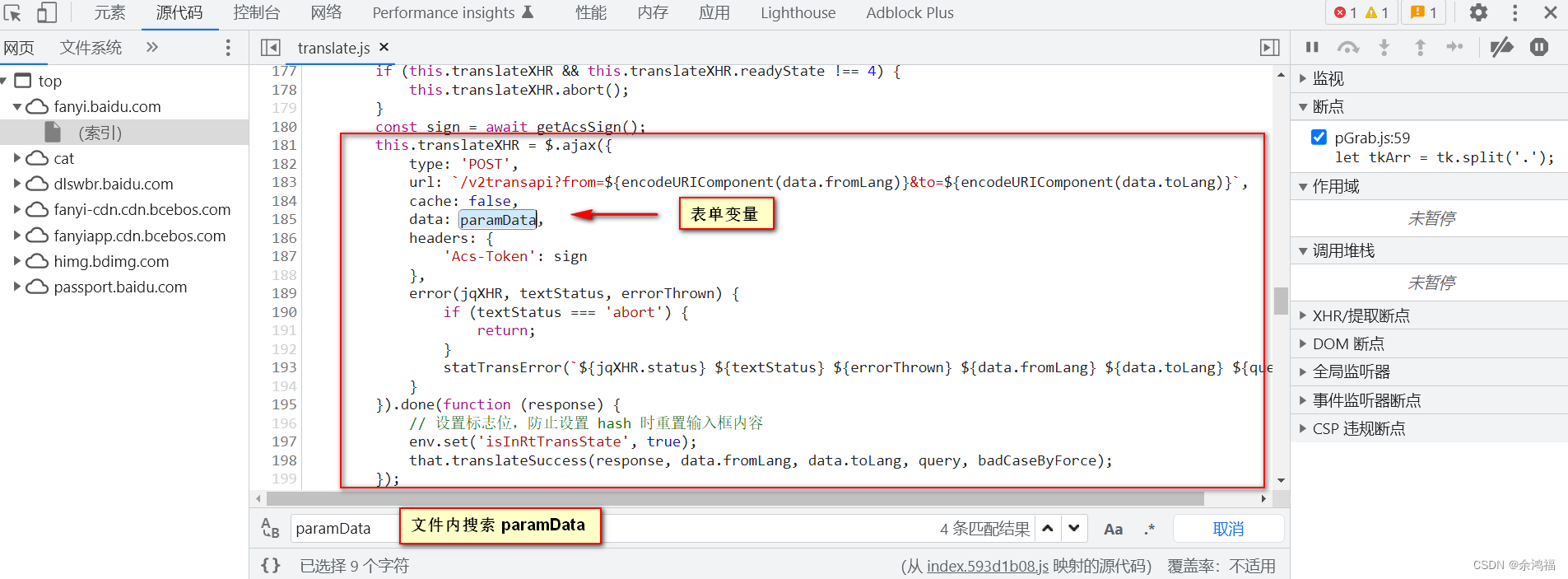 可以发现该方法正是我们的 $.ajax 方法,我们得知 data 的变量名为 paramData,在该文件内摁 ctrl+f 搜索这个变量: 可以发现该方法正是我们的 $.ajax 方法,我们得知 data 的变量名为 paramData,在该文件内摁 ctrl+f 搜索这个变量: 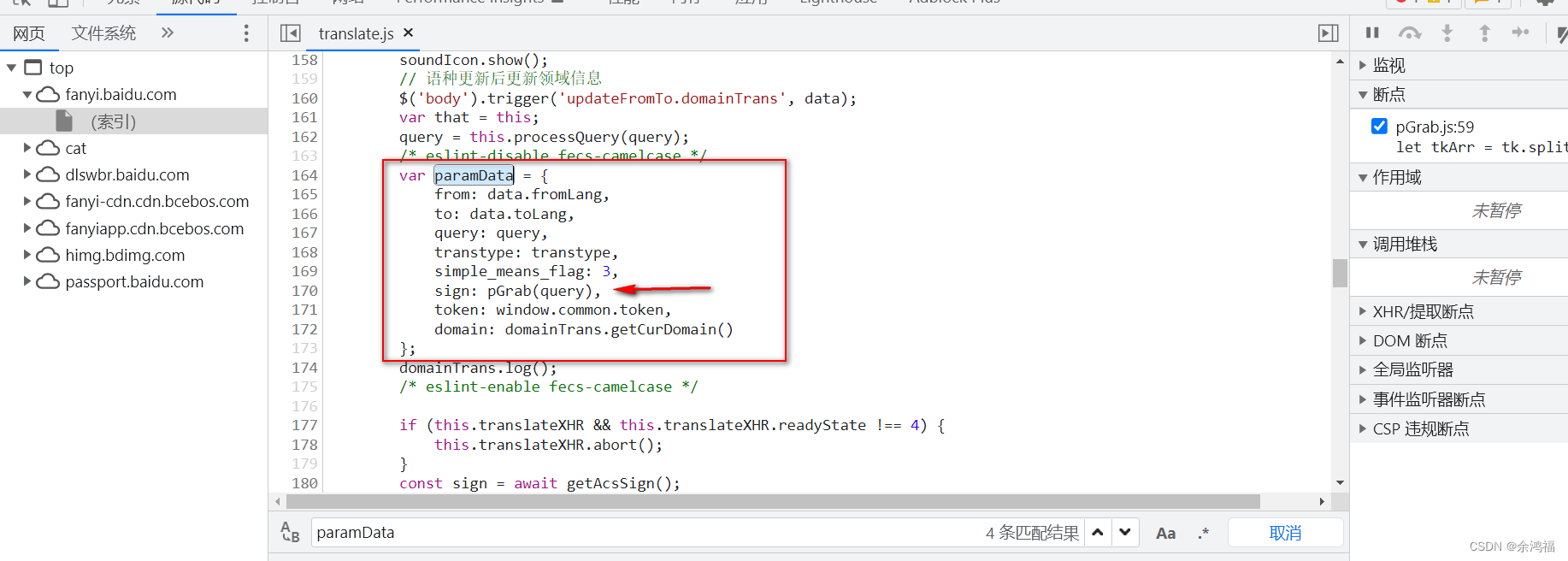 发现 sign 是调用了 pGrab( qeury ) 方法:这个 qeury 正是我们的待翻译文字。我们 ctrl+f 搜索 pGrab 发现是导入别的 js 文件中的方法: 发现 sign 是调用了 pGrab( qeury ) 方法:这个 qeury 正是我们的待翻译文字。我们 ctrl+f 搜索 pGrab 发现是导入别的 js 文件中的方法:

全局搜索该文件:点击控制台左边这三个点 - 打开文件,或者 ctrl+p。  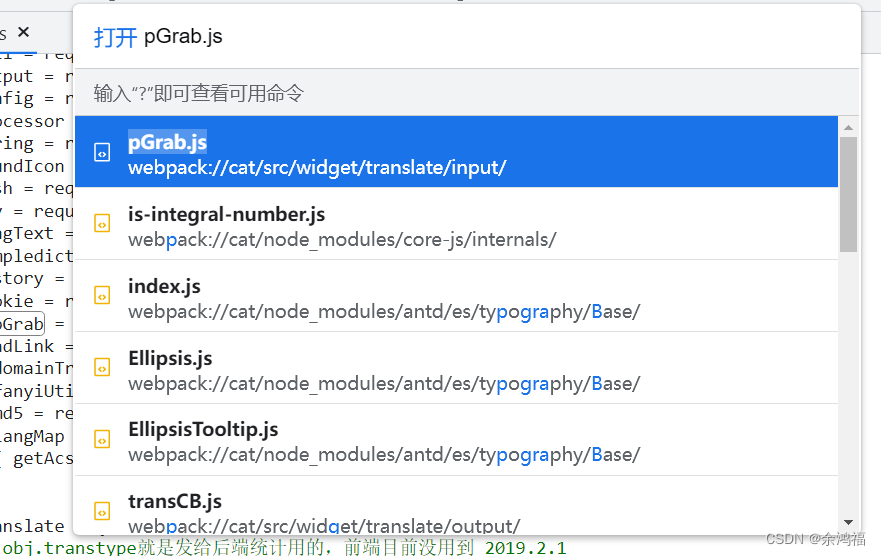 翻到文件末尾看到导出的方法是 tl,所以实质 sign = tl( query ),右键该文件点击另存为,将 pGrab.js 文件放入我们的项目路径。 翻到文件末尾看到导出的方法是 tl,所以实质 sign = tl( query ),右键该文件点击另存为,将 pGrab.js 文件放入我们的项目路径。
五、python 访问百度翻译 v2transapi 接口再试
现在的思路就是需要在 python 中调用该 js 中的 tl( query ) 方法生成我们的 sign,此时我们需要导入 execjs 模块(需要 nodejs 环境:本人版本 v14.0.0)
安装 pip install PyExecJS
导入: import execjs
使用: query = '哈哈'
with open('pGrab.js', mode='r', encoding='utf-8') as f:
sign = execjs.compile(f.read()).call("tl", query)
print(sign)
运行  提示 window 未定义,在 pGrab.js 中搜索发现只有一处使用了该变量: 提示 window 未定义,在 pGrab.js 中搜索发现只有一处使用了该变量: 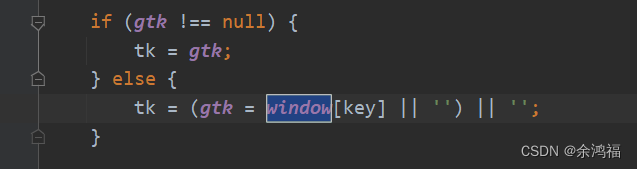 现在的目标就变成了如何知道这个 window “长什么样” 现在的目标就变成了如何知道这个 window “长什么样” 此时我们可以利用浏览器的调试功能,直接定位到这行代码查看 window 变量! 在图示这行打上断点: 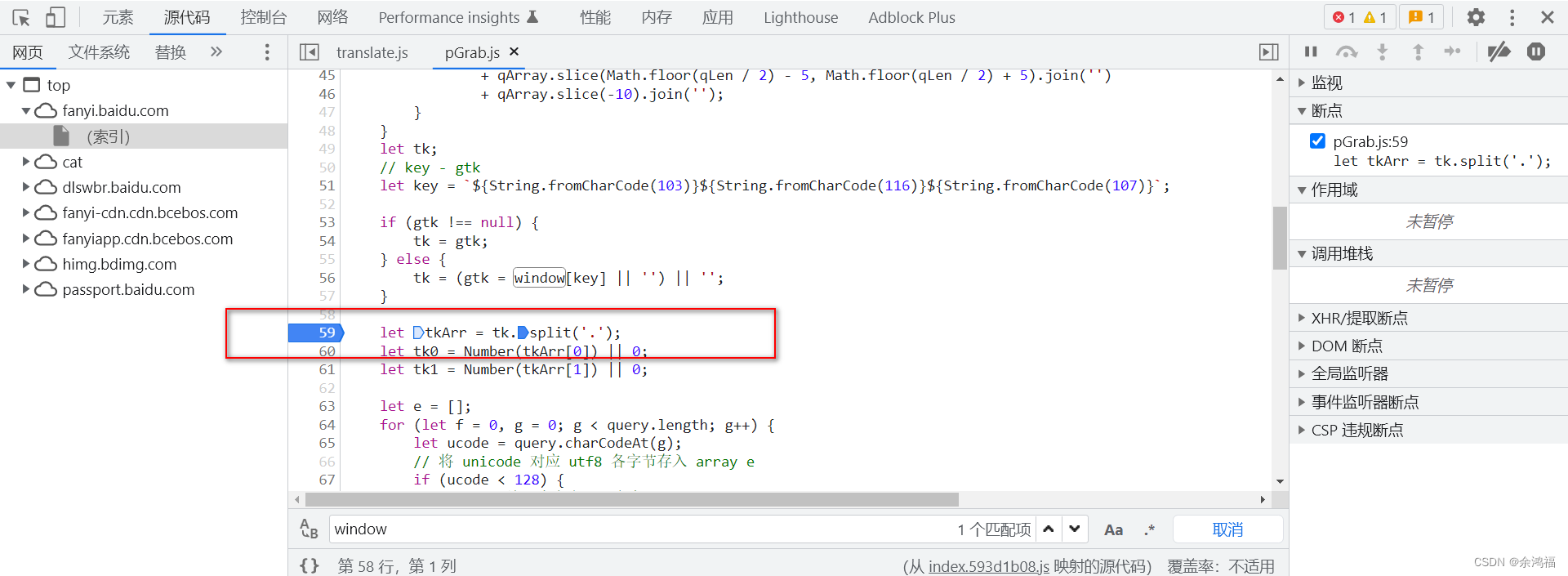 然后在翻译框随便输入,js 会暂停在断点这行。鼠标指上 window 变量,在里面寻找 key = gtk 然后在翻译框随便输入,js 会暂停在断点这行。鼠标指上 window 变量,在里面寻找 key = gtk 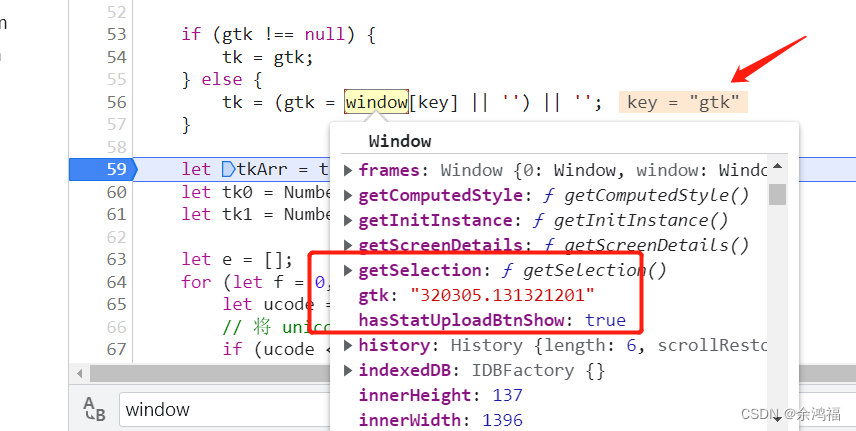 因为我们通过搜索 pGrab.js 知道只用了 window 中的这一个 kv,所以我们在项目中的 pGrap.js 文件首行添加 因为我们通过搜索 pGrab.js 知道只用了 window 中的这一个 kv,所以我们在项目中的 pGrap.js 文件首行添加 window = { 'gtk': '320305.131321201' }
重新运行我们第3步的代码: 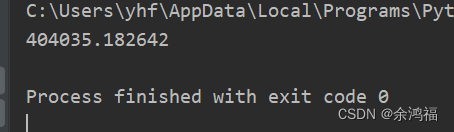 对比我们之前的 query = '哈哈' 对应的 sign 值是同一个值: 对比我们之前的 query = '哈哈' 对应的 sign 值是同一个值: 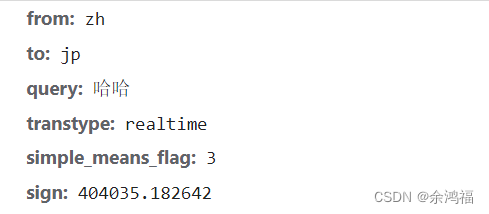 问题全部解决了,上代码最终版! 问题全部解决了,上代码最终版!
六、代码最终版
import json
import urllib.request
import urllib.parse
import execjs
# 第一步中咱们知道接口是这个 url
url = 'https://fanyi.baidu.com/v2transapi?from=zh&to=jp'
# headers 必须带 Cookie,百度翻译的反扒手段之一
headers = {
'Cookie': 你的 cookie
}
# 要翻译的单词
query = '哈哈'
# 生成 sign
with open('pGrab.js', mode='r', encoding='utf-8') as f:
sign = execjs.compile(f.read()).call("tl", query)
print(sign)
# 表单数据,将第二步中的kv全部复制过来
data = {
'from': 'zh',
'to': 'jp',
'query': query,
'simple_means_flag': '3',
'sign': sign,
'token': 你的 token,
'domain': 'common'
}
# 封装 request 对象
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
# 调用 urlopen,获得返回值
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 用 json 可以解码返回值中的 Unicode 字符
print(json.loads(content))
运行结果:  pGrab.js pGrab.js
window = {'gtk': '320305.131321201'};
function rl(num, rule) {
for (let i = 0; i
// 非 BMP 的 unicode 在 js 会以高低位保存在,导致 string.length 返回是 2,与后端不一致
// https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/charCodeAt
let noBMPChar = query.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (noBMPChar === null) {
let qLen = query.length;
if (qLen > 30) {
query = `${query.substr(0, 10)}${query.substr(Math.floor(qLen / 2) - 5, 10)}${query.substr(-10, 10)}`;
}
} else {
let bmpPart = query.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/);
let i = 0;
let len = bmpPart.length;
let qArray = [];
for (; i
qArray.push(...bmpPart[i].split(''));
}
if (i !== len - 1) {
qArray.push(noBMPChar[i]);
}
}
let qLen = qArray.length;
// query 截取
if (qLen > 30) {
// query = `${query.substr(0, 10)}${query.substr(Math.floor(qLen / 2) - 5, 10)}${query.substr(-10, 10)}`;
query = qArray.slice(0, 10).join('')
+ qArray.slice(Math.floor(qLen / 2) - 5, Math.floor(qLen / 2) + 5).join('')
+ qArray.slice(-10).join('');
}
}
let tk;
// key - gtk
let key = `${String.fromCharCode(103)}${String.fromCharCode(116)}${String.fromCharCode(107)}`;
if (gtk !== null) {
tk = gtk;
} else {
tk = (gtk = window[key] || '') || '';
}
let tkArr = tk.split('.');
let tk0 = Number(tkArr[0]) || 0;
let tk1 = Number(tkArr[1]) || 0;
let e = [];
for (let f = 0, g = 0; g
// utf 编码为变字节,参考 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
// 单字节 操作
e[f++] = ucode;
} else {
if (ucode
// charCodeAt 总是返回一个小于 65,536 的值。
// 这是因为高位编码单元(higher code point)使用一对(低位编码(lower valued))代理伪字符("surrogate" pseudo-characters)来表示,从而构成一个真正的字符。
// 因此,为了查看或复制(reproduce)65536 及以上编码字符的完整字符,需要在获取 charCodeAt(i) 的值的同时获取 charCodeAt(i+1) 的值
// 貌似是因为一个 char 两个字节(16位),支持 unicode \u0000 - \uffff
if (55296 === (ucode & 64512)
&& g + 1
// 三字节 操作
e[f++] = ucode >> 12 | 224;
}
e[f++] = ucode >> 6 & 63 | 128;
}
// 末字节
e[f++] = ucode & 63 | 128;
}
}
let rlt = tk0;
// let rule1 = '+-a^+6';
let rule1 = `${String.fromCharCode(43)}${String.fromCharCode(45)}${String.fromCharCode(97)}`
+ `${String.fromCharCode(94)}${String.fromCharCode(43)}${String.fromCharCode(54)}`;
// let rule2 = '+-3^+b+-f'
let rule2 = `${String.fromCharCode(43)}${String.fromCharCode(45)}${String.fromCharCode(51)}`
+ `${String.fromCharCode(94)}${String.fromCharCode(43)}${String.fromCharCode(98)}`
+ `${String.fromCharCode(43)}${String.fromCharCode(45)}${String.fromCharCode(102)}`;
for (let i = 0; i rlt.toString()}.${rlt ^ tk0}`;
}
七、补充
scrapy 访问百度翻译 v2transapi 接口
settings.py 中注释掉:
# ROBOTSTXT_OBEY = True
新建 spider:
import scrapy
import execjs
class BaiduFanyiSpider(scrapy.Spider):
name = 'baidu_fanyi'
allowed_domains = ['fanyi.baidu.com']
# 必须注释
# start_urls = ['https://fanyi.baidu.com/v2transapi']
# 必须改名
def parse_second(self, response):
print(response.json())
pass
def start_requests(self):
url = 'https://fanyi.baidu.com/v2transapi?from=zh&to=jp'
query = '哈哈'
with open('pGrab.js', mode='r', encoding='utf-8') as f:
sign = execjs.compile(f.read()).call("tl", query)
# print(sign)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
}
cookies = {
将 cookies 按分号拆开,等号改写成 kv 形式,例如:
'BIDUPSID': xxx,
...
}
data = {
'from': 'zh',
'to': 'jp',
'query': query,
'simple_means_flag': '3',
'sign': sign,
'token': 你的token,
'domain': 'common'
}
yield scrapy.FormRequest(url=url, headers=headers, formdata=data, cookies=cookies, callback=self.parse_second)
运行结果: 
完结撒花
|