基于python豆瓣电影爬虫数据可视化分析推荐系统(完整系统源码+数据库+详细文档+论文+详细部署教程) |
您所在的位置:网站首页 › python爬虫编写毕业论文 › 基于python豆瓣电影爬虫数据可视化分析推荐系统(完整系统源码+数据库+详细文档+论文+详细部署教程) |
基于python豆瓣电影爬虫数据可视化分析推荐系统(完整系统源码+数据库+详细文档+论文+详细部署教程)
|
文章目录
基于python豆瓣电影爬虫数据可视化分析推荐系统(完整系统源码+数据库+详细文档+论文+详细部署教程)一、 选题背景二、研究目的三、开发技术介绍1、Django框架2、LDA3、机器学习推荐算法4、大数据爬虫5、大数据Echarts可视化
四、系统设计思想五、部分代码讲解六、系统实现七、源码文档等资料获取
基于python豆瓣电影爬虫数据可视化分析推荐系统(完整系统源码+数据库+详细文档+论文+详细部署教程)
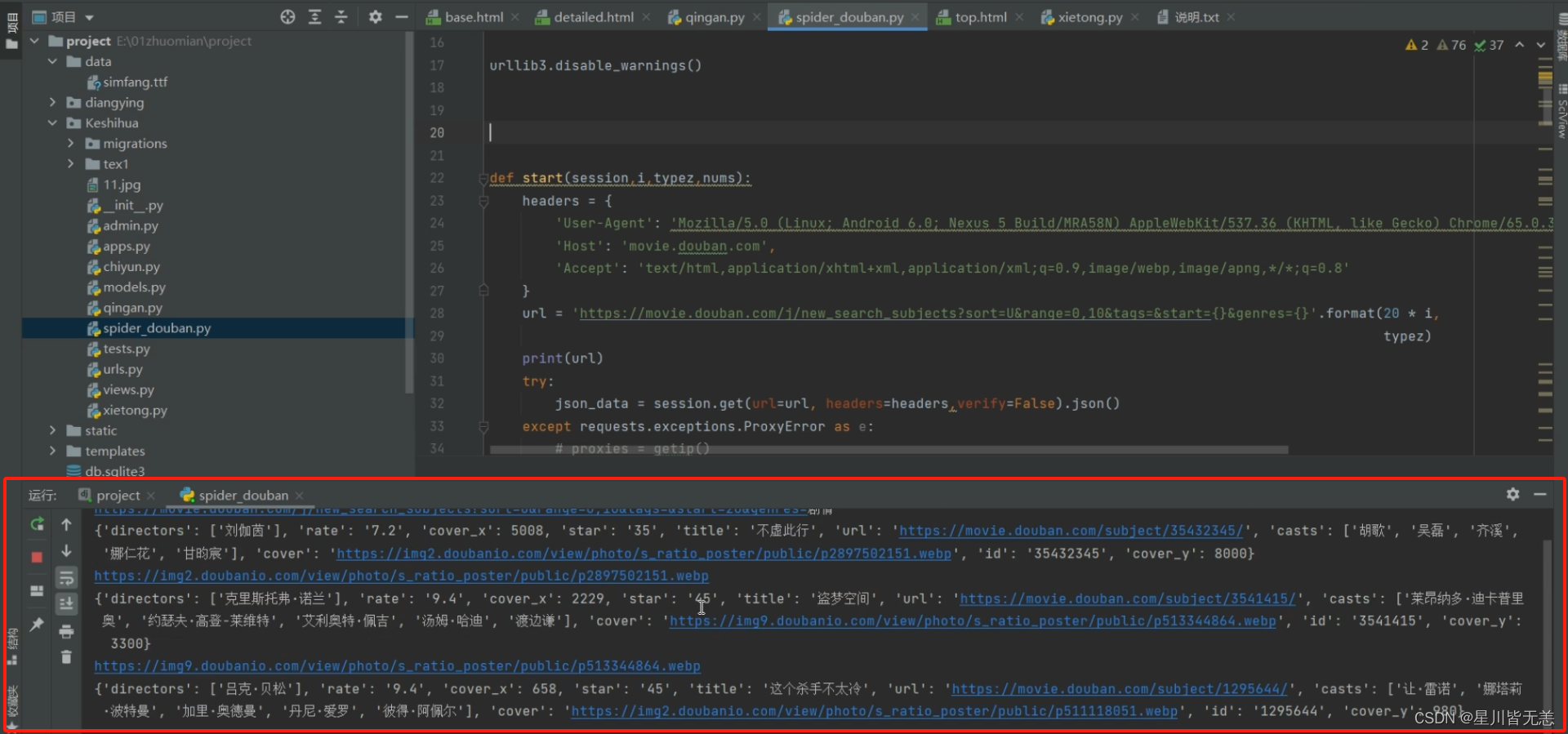
摘要:本文介绍了一个基于大数据可视化的电影评论分析推荐系统,采用Python和Django构建。通过爬取豆瓣电影评论数据,利用数据清洗和处理技术,建立了一个全面的电影信息数据库。使用Python中强大的数据处理库进行统计分析,常见的一些库pandas/numpy/pyecharts/matplotlib/echarts等数据分析可视化工具,将结果以直观的可视化图表展示,深入挖掘用户对电影的评价与趋势。基于分析结果,我们设计了推荐算法,通过Django搭建的Web界面向用户推荐个性化的电影选择。该项目结合了大数据、数据可视化和机器学习推荐算法的技术,为电影爱好者提供了更智能、直观的电影推荐体验,展示了Python在构建复杂系统中的强大应用能力。 一、 选题背景随着大数据技术的不断发展和普及,人们在日常生活中产生的数据量呈爆炸性增长。电影评论数据作为一种丰富的信息源,包含了观众对电影的各种评价和喜好。在这个信息爆炸的时代,如何从海量的电影评论中提炼有价值的信息,为用户提供更智能、个性化的电影推荐服务成为一个备受关注的问题。 本项目选取豆瓣作为数据源,结合Python和Django等先进技术,构建了一个综合性的豆瓣电影评论可视化分析推荐系统。通过对大规模评论数据的采集和处理,我们能够深入挖掘用户的观影趋势、口碑评价等信息。在这个基础上,利用数据可视化技术,以直观的图表和图形展示用户的观影偏好,为用户提供了更深入的电影分析服务。 该项目旨在结合大数据、可视化和推荐系统的技术优势,为电影爱好者提供一种全新的电影探索和选择方式,提升用户体验。通过对豆瓣电影评论数据的深度挖掘,我们能够更好地理解用户的需求,为他们提供更精准、个性化的电影推荐,推动了电影推荐系统的发展和创新。同时,项目的实施也展示了Python/Django等技术在构建复杂大数据系统中的卓越应用,为相关领域的研究和应用提供了有益的经验。 二、研究目的1.深入挖掘电影评论数据: 通过构建基于Python/Django的豆瓣电影评论可视化分析推荐系统,旨在深入挖掘电影评论数据中蕴含的用户偏好、口碑评价等信息。通过对评论数据的系统性分析,揭示用户对电影的喜好和趋势。 2.构建全面的电影信息数据库: 通过爬取豆瓣电影评论数据,进行数据清洗和处理,构建一个全面而准确的电影信息数据库。该数据库将包含丰富的电影元数据,为系统提供充足的信息基础,支持后续的分析和推荐。 3.实现数据可视化展示: 利用Python中强大的数据处理和可视化库,将分析结果以直观的图表、图形展示给用户。通过直观的可视化展示,使用户更容易理解电影数据背后的信息,为用户提供更深入的电影分析服务。 4.设计智能化的电影推荐算法: 基于对电影评论数据的深度分析,设计智能化的推荐算法。通过考虑用户的历史喜好、观影习惯等因素,为用户提供个性化、精准的电影推荐服务,提升用户体验。 5.展示Python/Django在大数据应用中的优越性: 通过该项目的实施,展示Python和Django等先进技术在大数据应用中的卓越性能。强调这些技术在构建复杂系统、处理大规模数据时的高效性和可扩展性,为相关领域的研究和应用提供实用经验。 总体而言,研究旨在通过构建综合性的电影评论可视化分析推荐系统,挖掘电影评论数据的潜在价值,提升用户对电影的选择和理解体验,同时突显Python/Django等技术在大数据领域的应用前景。 三、开发技术介绍 1、Django框架Django(发音为"jan-go")是一个高级的Python web框架,它鼓励快速开发和干净、可重用的设计。以下是Django框架的一些详细介绍: MVC 架构: Django 遵循经典的 Model-View-Controller(MVC)软件设计模式,但采用了稍微不同的结构。在Django中,这个模式被称为Model-View-Template(MVT)。Model(模型): 负责数据存储和检索。定义数据模型,通过对象关系映射(ORM)将数据模型映射到数据库表。View(视图): 处理用户请求,从模型中检索数据,并将数据传递给模板进行渲染。Template(模板): 定义如何呈现数据。Django模板系统使得在HTML中嵌套Python代码变得简单,支持动态生成内容。 ORM(对象关系映射): Django的ORM系统允许使用Python代码而不是SQL语句来定义和查询数据库模型。模型类(Model)是Django ORM的核心。通过定义模型类,可以在数据库中创建表,并通过模型类实例来执行数据库操作,而无需直接编写SQL语句。 自动化 Admin 界面: Django自带一个强大的自动生成管理后台的功能。通过简单地定义模型,可以得到一个功能齐全的管理界面,用于添加、编辑和删除数据库中的记录。这减少了开发人员为管理任务编写额外代码的需要,提高了开发效率。 表单处理: Django提供了用于处理表单的内置模块。这些表单可以用于在网站上收集用户输入,并在服务器端进行验证和处理。表单处理是构建用户交互的重要组成部分,而Django的表单系统使其变得简单而强大。 URL 映射: Django使用URL模式将URL映射到相应的视图函数。这使得URL的定义变得清晰,易于维护。URL映射是通过在项目的urls.py文件中定义URL模式来完成的,这样使得项目具有清晰的URL结构。 中间件: 中间件是Django处理请求和响应的钩子。它可以在请求到达视图之前或离开视图之后执行一些操作。例如,中间件可以用于身份验证、缓存、安全性等方面的处理,以便更好地组织和维护项目。 安全性: Django具有内置的安全功能,包括防止跨站脚本攻击(XSS)、跨站请求伪造(CSRF)和点击劫持等安全漏洞。框架通过提供安全性相关的库和设置,帮助开发者编写更安全的Web应用。 模块化: Django是一个模块化的框架,允许开发者使用或不使用框架的特定组件。这使得Django可以根据项目的需要灵活扩展和定制。总体而言,Django是一个全功能的、高度可定制的Web框架,适用于各种规模的项目。它提供了一系列工具和功能,帮助开发者快速构建稳健、可扩展的Web应用程序。 2、LDALatent Dirichlet Allocation(LDA)是一种用于主题建模的概率图模型。它是由David Blei、Andrew Ng和Michael Jordan在2003年提出的。LDA假设文档是由多个主题的混合生成的,而每个主题又是由多个单词的混合生成的。在LDA中,文档和主题都被看作潜在(latent)的变量,通过观察到的单词来推断它们的分布。 LDA模型的主要概念: 文档(Documents): LDA假设每个文档都是由多个主题的混合生成的。文档中的每个单词都是从某个主题中抽取得到的。主题(Topics): 主题是单词的分布。每个主题都可以被看作是一个概念或主题类别,它包含了文档中的一些单词。单词(Words): 文档中的每个单词都由某个主题生成的概率分布和在该主题下选择某个词的概率共同决定。Dirichlet分布: LDA使用了Dirichlet分布来建模文档-主题和主题-单词的分布。Dirichlet分布是一个多变量概率分布,常被用来建模多项分布的参数。LDA模型生成文档的过程可以用以下步骤表示: 对于每个文档,从主题分布中抽取一个主题的概率分布。对于文档中的每个单词: 从上面抽取的主题分布中抽取一个主题。从该主题的单词分布中抽取一个单词。LDA的学习过程通常使用EM算法或变分推断等方法,通过最大化似然函数来估计模型参数。 在实际应用中,LDA经常被用于文本数据的主题建模,例如在文档集中发现主题结构,或者对文档进行主题分类。 LDA的一个关键优势是它的概率性质,可以提供主题分布的不确定性信息。 LDA是一个强大的工具,适用于从文本数据中发现潜在主题结构的问题。 在情感分析中,一种常见的方法是使用情感词典或机器学习模型来判别文本中的情感倾向,通常分为正向、负向和中性。与LDA结合的方式可能包括以下几个方面: 主题-情感模型: 在LDA生成主题的基础上,可以为每个主题关联一个情感。这就意味着每个主题不仅包含一组单词,还包含一个情感倾向。这种方式可能需要一个情感词典或者标注好的训练数据来学习主题与情感之间的关系。文档级情感分析: 对于LDA生成的文档-主题分布,可以进一步在文档级别进行情感分析。例如,通过综合每个主题的情感信息,得出整个文档的情感倾向。词级情感分析: 对于LDA生成的主题-单词分布,可以考虑对每个单词关联一个情感分数。这样,当对文本进行分析时,可以考虑每个单词的情感信息,而不仅仅是主题信息。 3、机器学习推荐算法推荐算法是机器学习领域中的一个重要应用方向,用于根据用户的行为、兴趣和偏好为其提供个性化的推荐内容。以下是一些常见的推荐算法及其详细介绍: 协同过滤(Collaborative Filtering): 协同过滤是一种基于用户行为或项目之间的相似性进行推荐的方法。它分为两类: 用户协同过滤(User-Based Collaborative Filtering): 根据用户的历史行为找到相似用户,然后将那些相似用户喜欢的物品推荐给目标用户。物品协同过滤(Item-Based Collaborative Filtering): 根据物品之间的相似性,推荐目标用户喜欢过的相似物品。 基于内容的推荐(Content-Based Recommendation): 基于内容的推荐算法使用物品的属性信息和用户的历史行为,通过计算它们之间的相似性来进行推荐。例如,通过分析电影的类型、演员等属性,向用户推荐相似类型的电影。 矩阵分解(Matrix Factorization): 矩阵分解通过将用户-物品交互矩阵分解为两个低维矩阵的乘积,学习用户和物品的隐含特征向量。这些特征向量捕捉了用户和物品之间的关系,从而进行推荐。 深度学习推荐算法(Deep Learning Recommendation): 利用深度学习模型来学习用户和物品之间的复杂关系。神经网络结构如多层感知机(MLP)、卷积神经网络(CNN)和循环神经网络(RNN)等被用于捕捉更高阶的特征表示。 多臂老虎机算法(Multi-Armed Bandits): 这种算法通过在不同的推荐选择中进行权衡探索(尝试新事物)和利用(选择已知的好事物),以优化推荐的效果。 混合推荐算法(Hybrid Recommendation): 结合多个推荐算法,利用它们的优势来提高推荐的准确性。例如,将协同过滤和基于内容的方法结合,以弥补各自算法的缺陷。 时序推荐算法(Sequential Recommendation): 针对用户在时间上的变化,考虑用户行为的时序信息,使得推荐更加具有时效性。 因子分解机(Factorization Machines): 类似于矩阵分解,但更加灵活,可以处理稀疏数据和高维特征。 群体推荐算法(Community-Based Recommendation): 考虑用户之间的社交网络关系,通过社交网络信息进行推荐。实际应用中常常结合多个算法,形成混合推荐系统,以提高推荐的准确性和覆盖度。选择合适的算法取决于数据的性质、问题的要求以及系统的特定场景。 4、大数据爬虫当谈到大数据爬虫技术时,我们通常指的是使用自动化工具或技术从互联网上收集大量数据的过程。以下是对大数据爬虫技术的讲解: 什么是爬虫: 爬虫是一种自动化程序,可以模拟人类用户在网页上的行为,通过HTTP请求和解析HTML来从网页中提取数据。爬虫可以自动访问网页、抓取数据以及存储数据。大数据爬虫的目的: 大数据爬虫旨在从大量来源中收集数据,这些来源可以是互联网上的网页、社交媒体平台、在线论坛、新闻网站等。它们被用于数据挖掘、情报搜集、市场研究、信息聚合等领域。大数据爬虫的工作流程: 在使用大数据爬虫时,通常遵循以下步骤: 确定目标:明确需要收集数据的来源和具体的信息需求。构建爬虫:编写爬虫程序,使用合适的编程语言和工具,设置爬取规则和网页解析方法。发送请求:爬虫程序向目标网站发送HTTP请求,获取网页内容。解析数据:对获取的网页内容进行解析,提取所需的数据。存储数据:将解析得到的数据存储到数据库、文件系统或其他存储介质中。处理数据:对收集的大量数据进行清洗、转换和分析。可视化和应用:可视化处理后的数据,并将其应用于各种领域,如商业决策、产品开发、研究报告等。 大数据爬虫技术的关键要素: URL管理:控制要爬取的网页URL列表,并管理爬虫的爬取策略,包括广度优先、深度优先等。网页解析:使用HTML解析器或XPath解析器来解析网页内容,提取所需的数据。数据存储:选择合适的数据库或文件系统来存储爬取的数据,如MySQL、Hadoop、Elasticsearch等。反爬虫机制应对:处理网站的反爬虫机制,如设置合理的请求频率、使用代理IP、处理验证码等。分布式爬取:如果需要处理大量的数据,可以使用分布式爬虫系统来提高效率和容错性。这里给大家分享一些爬虫实战源码: 干货链接:https://pan.baidu.com/s/1SEAwAz54aDmFhvdBoAueAQ?pwd=2023 5、大数据Echarts可视化ECharts(Enterprise Charts)是一个由百度开发的开源JavaScript图表库,用于构建各种交互式和可视化的图表。它提供了丰富的图表类型和灵活的配置选项,使得用户可以轻松地创建各种复杂的图表,包括折线图、柱状图、饼图、散点图等。 Echarts官方文档:Apache ECharts 四、系统设计思想 数据采集与处理: 数据爬取: 利用爬虫技术从豆瓣网站获取电影评论数据,包括用户评论、评分、电影信息等。数据清洗: 对采集到的数据进行清洗,去除重复、缺失或异常数据,确保数据的质量和准确性。数据存储: 将清洗后的数据存储到数据库中,构建一个稳定、高效的电影信息数据库。 系统架构设计: 前端设计: 使用Django框架构建用户界面,采用HTML、CSS、JavaScript等前端技术实现用户友好的交互和可视化效果。后端设计: 利用Django的模型-视图-控制器(MVC)架构设计后端逻辑,处理用户请求、调用推荐算法和访问数据库。数据库设计: 设计数据库表结构,包括用户信息、电影信息、评论数据等表,保证数据存储的规范性和一致性。 数据可视化与分析: 可视化工具选择: 使用Python中的数据可视化库(如Matplotlib、Seaborn、Plotly)进行图表绘制,展示电影数据的统计信息、趋势和分布。用户交互设计: 在前端设计中,通过图表和用户界面实现用户对电影数据的灵活查询和交互,提升用户体验。 推荐算法设计: 协同过滤算法: 基于用户的历史行为和兴趣,设计协同过滤算法,为用户推荐类似兴趣的电影。内容过滤算法: 考虑电影的内容特征,设计内容过滤算法,提供与用户过去喜好相符的电影推荐。混合推荐策略: 结合不同推荐算法,采用混合策略提高推荐系统的准确性和个性化程度。 系统性能优化: 缓存机制: 利用缓存技术提高系统性能,减少重复计算,加速数据访问。分布式处理: 如有必要,考虑引入分布式计算和存储,处理大规模数据,提高系统的可扩展性。 安全性与隐私保护: 用户身份验证: 在系统中引入用户身份验证机制,保护用户数据安全。隐私保护: 对于敏感用户信息,采用加密等手段保护用户隐私。 系统测试与优化: 单元测试: 对系统的各个组件进行单元测试,确保每个部分的功能正常。性能测试: 对系统进行性能测试,发现并解决潜在的性能瓶颈,确保系统在大数据量下依然高效稳定。通过以上设计思想,系统可以从数据采集、存储、处理,到用户界面设计、推荐算法实现,全方位满足用户对电影数据的需求,提供高效、可靠的服务。同时,注重系统性能和安全性的优化,为用户提供更好的体验。 五、部分代码讲解spider_douban.py脚本,从豆瓣电影网站爬取电影信息。 部分源码: 导入模块: pythonimport requests from concurrent.futures import ThreadPoolExecutor使用requests库发送HTTP请求,以及ThreadPoolExecutor`来实现多线程执行。 函数定义: pythondef fenlei(nums=0, itype=''):定义名为fenlei的函数,接受两个参数nums和itype,并给它们设置了默认值0和空字符串。 异常处理: pythontry: # ... except Exception as e: print(e)将代码包装在一个try-except块中,以捕获任何可能发生的异常,并打印异常信息。 设置请求头: pythonheaders = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Mobile Safari/537.36', 'Host': 'movie.douban.com', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8' }定义了HTTP请求头,模拟了一个移动设备的用户代理。 发送请求: pythonhtml = session.get('https://movie.douban.com/', headers=headers, verify=False)使用requests库发送GET请求,获取豆瓣电影网站的主页内容,并禁用了SSL证书验证(verify=False)。 电影类型列表: pythontypes = ['剧情','喜剧','动作',...,'武侠','情色']定义电影类型。 计算页数: pythonpage = nums pages = page // 20根据输入的nums计算需要爬取的页数,每页20个电影。 多线程爬取: pythonwith ThreadPoolExecutor(1) as executor: for typez in types: for i in range(1, pages+1): executor.submit(start, session, i, typez, nums)使用ThreadPoolExecutor创建一个线程池,遍历电影类型和页数,通过executor.submit提交任务,调用start函数进行爬取。 异常处理输出: pythonexcept Exception as e: print(e)如果在try块中发生异常,将异常信息打印出来。
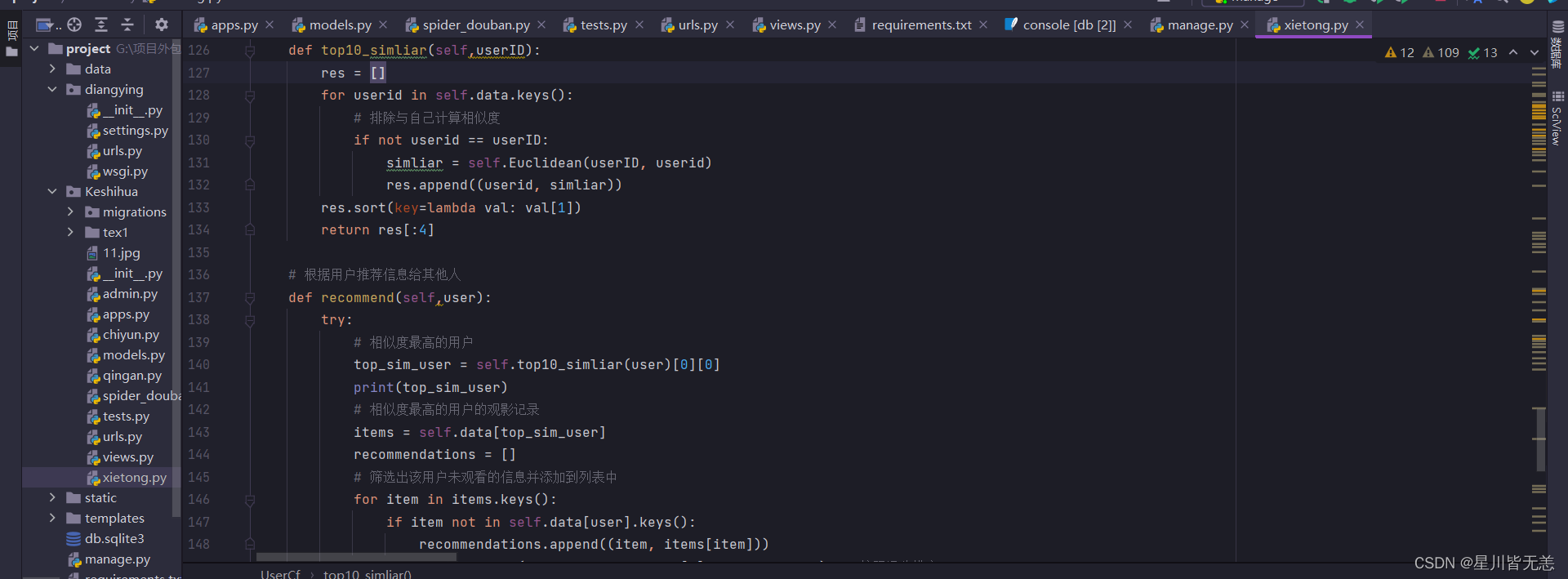
基于用户之间的欧氏距离来计算相似度,通过指定用户的相似用户的观影记录,然后根据相似用户的评分信息为指定用户推荐电影,为指定用户推荐未观看过且评分较高的电影。 部分算法源码: # 根据用户推荐信息给其他人 def recommend(self,user): try: # 相似度最高的用户 top_sim_user = self.top10_simliar(user)[0][0] print(top_sim_user) # 相似度最高的用户的观影记录 items = self.data[top_sim_user] recommendations = [] # 筛选出该用户未观看的信息并添加到列表中 for item in items.keys(): if item not in self.data[user].keys(): recommendations.append((item, items[item])) recommendations.sort(key=lambda val: val[1], reverse=True) # 按照评分排序 # 返回评分最高的10部信息 if len(recommendations) == 1: recommendations = [] lists = [] for key,value in self.data.items(): for keys,values in value.items(): lists.append((keys,values)) for i in range(4): recommendations.append(random.choice(lists)) recommendations = list(set(recommendations)) return recommendations[:10] except: return '' recommend 方法: 参数 user: 要为其进行推荐的用户ID。 功能 调用 top10_similar 方法找到与指定用户最相似的前4个用户中的第一个用户(相似度最高的用户)。获取相似用户的观影记录(items),即该用户已经观看过的电影及其评分。筛选出指定用户未观看的电影,并将这些电影及其评分添加到 recommendations 列表中。对 recommendations 列表按照评分进行降序排序。如果推荐列表长度为1,说明相似用户与指定用户没有共同的观看历史,此时通过随机选择其他用户的电影进行推荐。首先,将所有用户的观影记录放入 lists 列表中,然后随机选择4部电影添加到 recommendations 中,并去重。返回评分最高的前10部电影作为推荐。
|
 基于情感词典和程度词典的情感分析,使用了LDA模型进行主题建模。 部分代码
基于情感词典和程度词典的情感分析,使用了LDA模型进行主题建模。 部分代码【本文地址】
今日新闻 |
推荐新闻 |