|
实现的效果
 可视化界面由于作者的审美有限,所以有点丑,但是还是讲究可以看一下,主要的功能没有改变,博友们也可以根据自己的喜好改变一下。 可视化界面由于作者的审美有限,所以有点丑,但是还是讲究可以看一下,主要的功能没有改变,博友们也可以根据自己的喜好改变一下。
原理
 这里我们使用百度翻译网页,对上面的翻译内容进行爬取,至于音频,我们也可以将其爬取下来,并进行本地保存和播放。 这里我们使用百度翻译网页,对上面的翻译内容进行爬取,至于音频,我们也可以将其爬取下来,并进行本地保存和播放。
一、翻译内容以及播放的音频的爬取
(1)找到目标网页
一、翻译结果 我们先对目标网页进行踩点,我们先使用F12进行检查,打开network,然后随便输入一个词语,观看网页返回信息的变化。当我们在查看XHR里的内容时,发现了我们需要的信息。  点击右侧的preview,在trans_result中看到了我们需要的信息。 点击右侧的preview,在trans_result中看到了我们需要的信息。  所以这个就是我们的目标网页。 二、语言 所以这个就是我们的目标网页。 二、语言  我们在media中找到语言,观看结构,很简单,只需要提供自己所翻译的信息就行了。并没有进行什么加密。 我们在media中找到语言,观看结构,很简单,只需要提供自己所翻译的信息就行了。并没有进行什么加密。 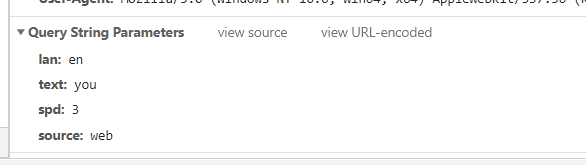 (2)对目标网页的信息进行观测 我们重点观察网页的url,可以发现这个是通过post方法获得信息的,然后我们在看form Data。 (2)对目标网页的信息进行观测 我们重点观察网页的url,可以发现这个是通过post方法获得信息的,然后我们在看form Data。  其中发现sign和token是比较棘手的。 我们在随便输入一个值,翻译看一下form Data有什么变化。 其中发现sign和token是比较棘手的。 我们在随便输入一个值,翻译看一下form Data有什么变化。  明显token没有发生变化,但是sign发生了变化,初步判断该网页使用了加密。 我们进行search。查看资源中是否含有sign的信息。 明显token没有发生变化,但是sign发生了变化,初步判断该网页使用了加密。 我们进行search。查看资源中是否含有sign的信息。   我们发现有很多的assign,很明显不对,我们继续寻找。 终于,我们找到了我们需要的sign,然后对此处进行断点。 我们发现有很多的assign,很明显不对,我们继续寻找。 终于,我们找到了我们需要的sign,然后对此处进行断点。  然后我们按F11,查看f(n)对其进行复制到python进行执行。 然后我们按F11,查看f(n)对其进行复制到python进行执行。 
import execjs
with open("百度翻译.js", "r", encoding="utf-8") as f:
js = execjs.compile(f.read())
sign = js.call("e", "你")
但是很遗憾他报错了,说 i not defind。 我们接下来就是找到i,我们使用watch对i进行监听。  发现他是一个定值,我们直接把i加到最前面。大功告成!!! 再次执行,没有报错。 发现他是一个定值,我们直接把i加到最前面。大功告成!!! 再次执行,没有报错。 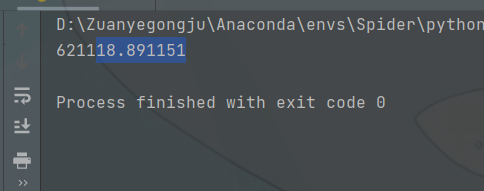 接下来就简单了,直接使用js获得sign关键信息,使用request进行网页的获取,获得翻译结果。 代码如下。 一、js代码 接下来就简单了,直接使用js获得sign关键信息,使用request进行网页的获取,获得翻译结果。 代码如下。 一、js代码
var i = "320305.131321201"
function n(r, o) {
for (var t = 0; t = "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && |