【爬虫】4.1 Scrapy 框架爬虫简介 |
您所在的位置:网站首页 › python爬虫之scrapy高级全站爬取分布式增量爬虫 › 【爬虫】4.1 Scrapy 框架爬虫简介 |
【爬虫】4.1 Scrapy 框架爬虫简介
|
目录 1. Scrapy 框架介绍 2. 建立 Scrapy 项目 3. 入口函数与入口地址 4. Python 的 yield 语句 5. Scrapy 爬虫的数据类型 1. Scrapy 框架介绍 1.1 Scrapy 的安装pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple/ 1.2 Scrapy爬虫框架结构“5+2”结构,9数据流、3路径、2出入口 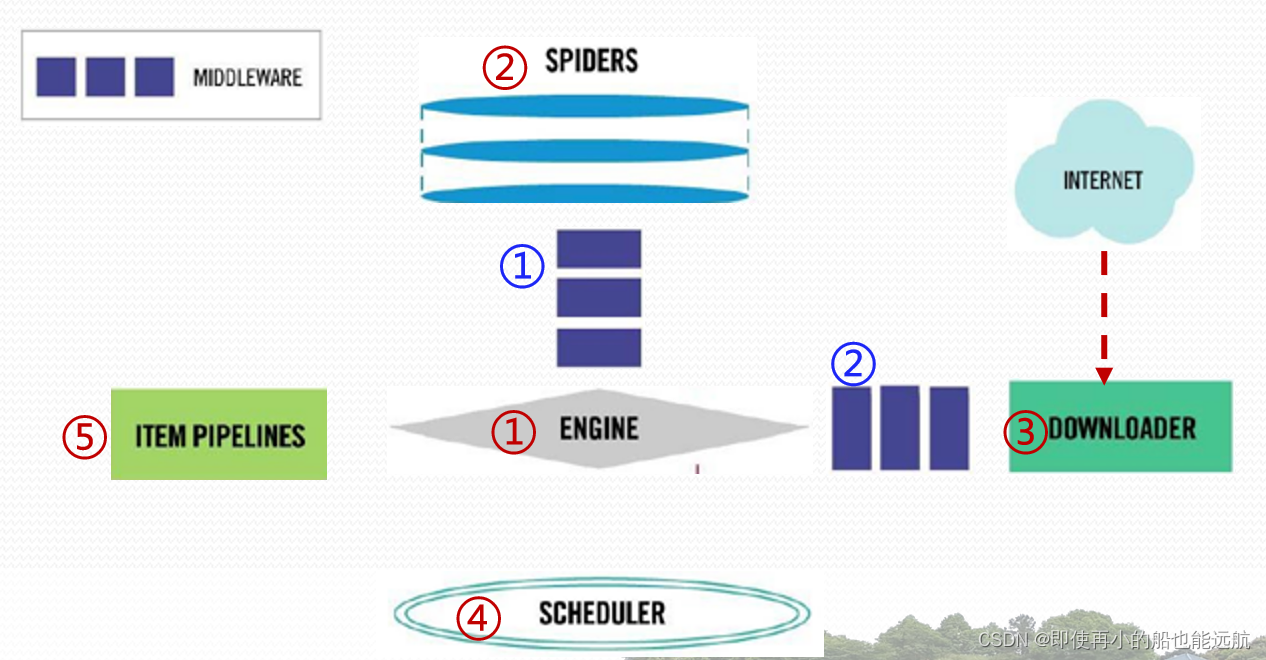 5+2结构(5个功能模块+2个中间件)
5+2结构(5个功能模块+2个中间件)
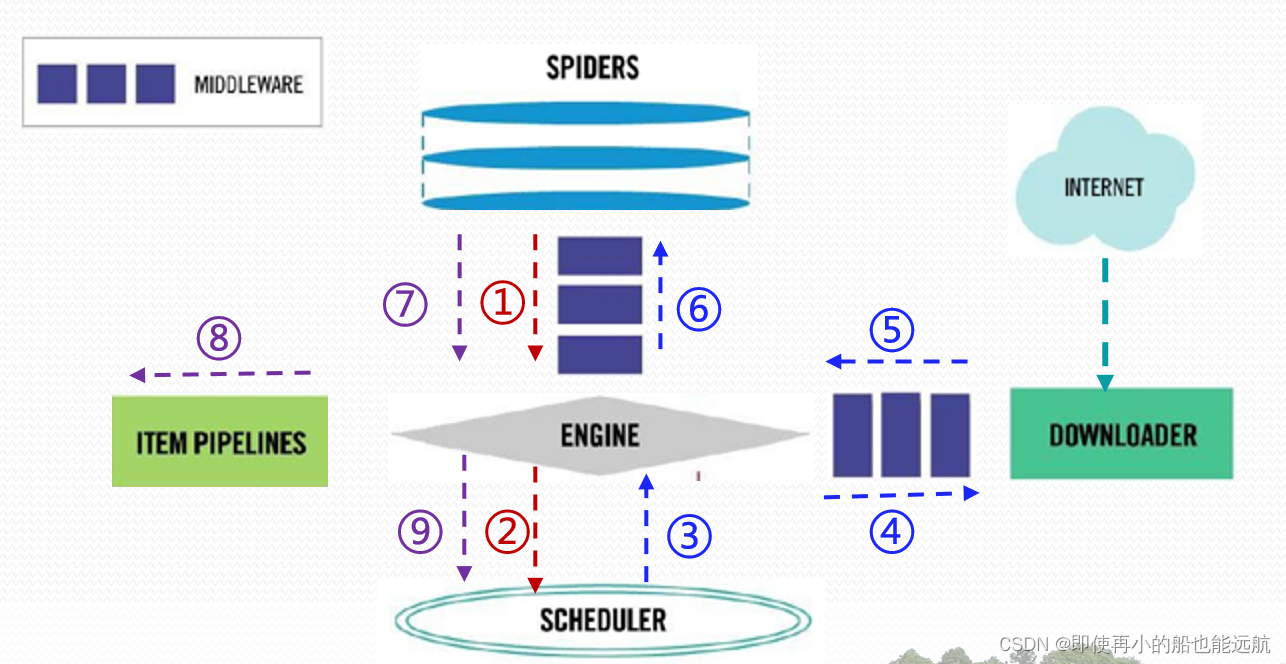 9个数据流
9个数据流
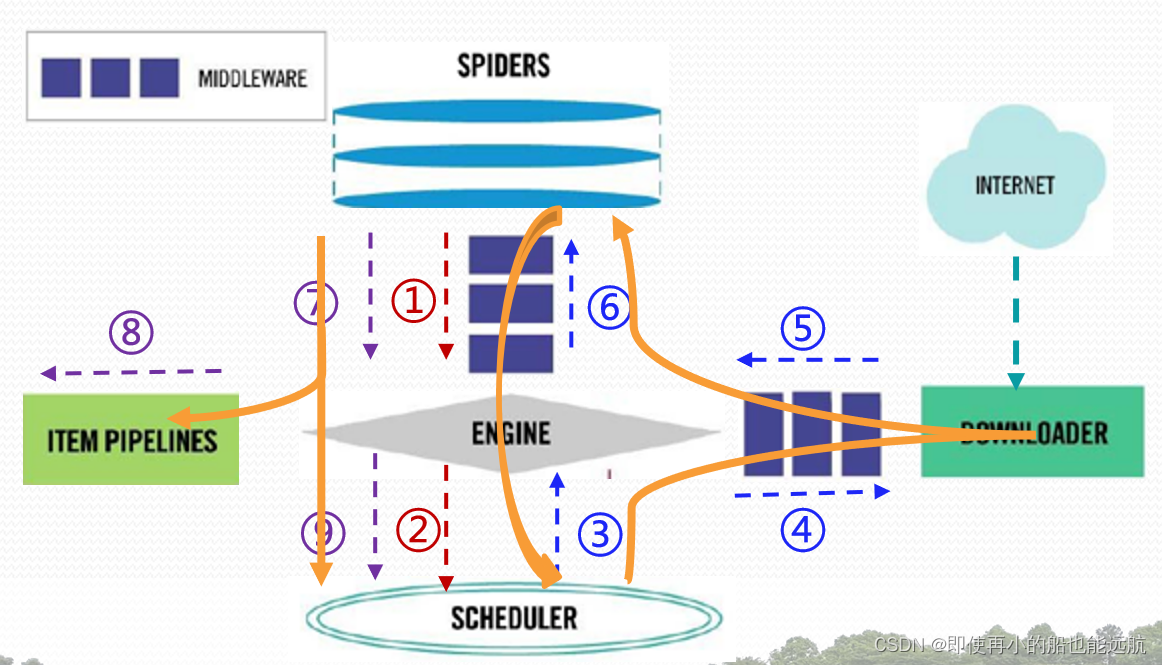 数据流的3个路径
数据流的3个路径
路径1 :① ② ①Engine从Spider处获得爬取请求(Request)。 ②Engine将爬取请求转发给Scheduler,用于调度。 路径2:③④⑤⑥ ③Engine从Scheduler处获得下一个要爬取的请求。 ④Engine将爬取请求通过中间件发送给Downloader 爬取网页后。 ⑤Downloader形成响应(Response) 通过中间件发给Engine。 ⑥Engine将收到的响应通过中间件发送给Spider处理。 路径3:⑦⑧⑨ ⑦ Spider处理响应后产生爬取项(scraped Item) 和新的爬取请求(Requests)给Engine。 ⑧ Engine将爬取项发送给Item Pipeline(框架出口)。 ⑨ Engine将爬取请求发送给Scheduler。 数据流的出入口(2) Engine控制各模块数据流,不间断从Scheduler处获得爬取请求,直至请求为空 。 框架入口:Spider(初始爬取请求) 框架出口:Item Pipeline(爬取结果及处理) 解析5+2结构
Engine (1) 控制所有模块之间的数据流 (2) 根据条件触发事件 不需要用户修改 Downloader 根据请求下载网页 不需要用户修改 Scheduler 对所有爬取请求进行调度管理 不需要用户修改 Spiders (1) 解析Downloader返回的响应(Response) (2) 产生爬取项(scraped item) (3) 产生额外的爬取请求(Request) 需要用户编写配置代码 Item Pipelines (1) 以流水线方式处理Spider产生的爬取项 (2) 由一组操作顺序组成,类似流水线,每个操 作是一个Item Pipeline类型 (3) 可能操作包括:清理、检验和查重爬取项中 的HTML数据、将数据存储到数据库。 需要用户编写配置代码 Downloader Middleware 目的:实施Engine、Scheduler和Downloader 之间进行用户可配置的控制 功能:修改、丢弃、新增请求 或 响应 用户可以编写配置代码 Spider Middleware 目的:对请求和爬取项的再处理 功能:修改、丢弃、新增请求或爬取项 用户可以编写配置代码 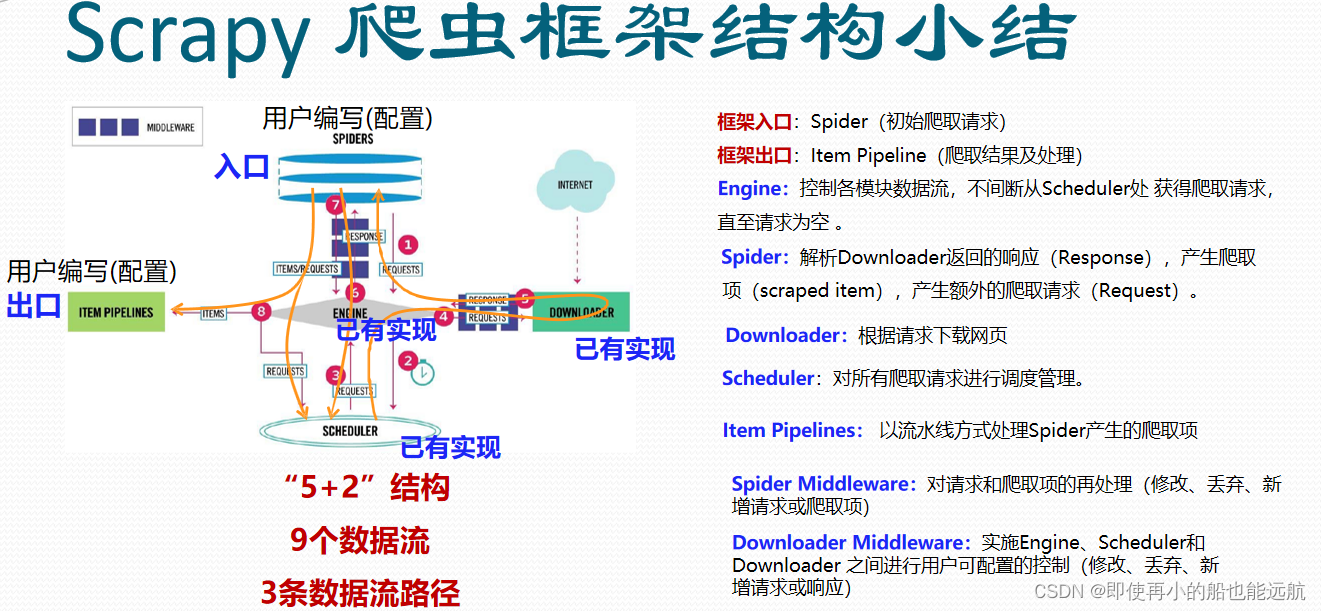 1.3 命令行的使用
1.3 命令行的使用
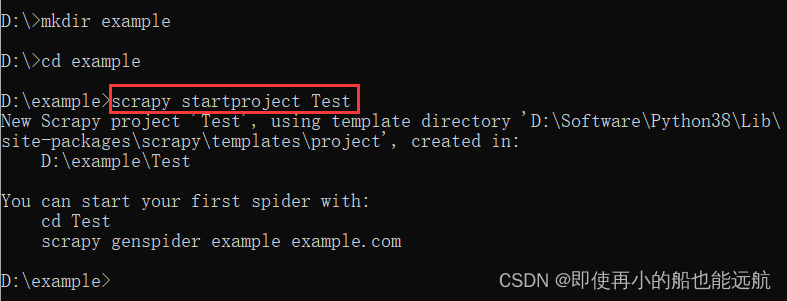
Scrapy命令行格式: >scrapy [options] [args] Scrapy常用命令 命令说明格式startproject创建一个新工程scrapy startproject [dir]genspider创建一个爬虫scrapy genspider [options] settings获得爬虫配置信息scrapy settings [options]crawl运行一个爬虫scrapy crawl list列出工程中所有爬虫scrapy listshell启动URL调试命令行scrapy shell [url] 为什么Scrapy采用命令行创建和运行爬虫?命令行(不是图形界面)更容易自动化,适合脚本控制。 本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。 比较爬虫技术路线Scrapy与 Requests RequestsScrapy相同点1. 实现Python爬虫重要技术路线 2. 可用性都好,文档丰富,入门简单 3.两者都没有处理js、提交表单、应对验证码等功能(可扩展) 不同点页面级爬虫网站级爬虫功能库框架并发性考虑不足,性能较差并发性好,性能较高重点在于页面下载重点在于爬虫结构定制灵活一般定制灵活,深度定制困难上手十分简单入门稍难 选用哪个技术路线开发爬虫呢? 非常小的需求,requests库不太小的需求,Scrapy框架定制程度很高的需求(不考虑规模),自搭框架,requests > Scrapy 2. 建立 Scrapy 项目(1)进入命令行窗体,在D盘中 建立一个文件夹例如example, 进入D:\example然后执行命令: scrapy startproject Test 该命令建立一个名称为 Test的scrapy项目,如下图所示
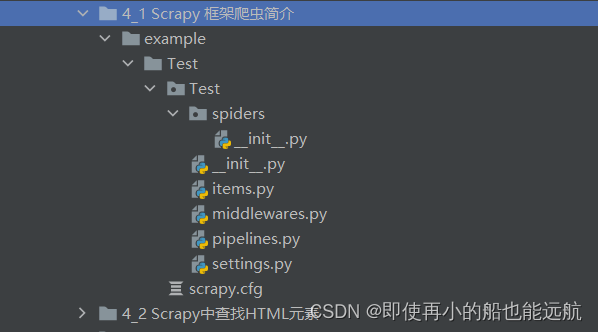
(2)Scrapy项目建立后会在D:\example中建立Test文件夹,同时下面还有另外一个Test子文件夹,如下图所示(将这个项目移到4_1 Scrapy 框架爬虫简介下,用PyCharm打开)
(3)为了测试的这个scrapy项目,首先先建立一个Web网站, 可以在./example中建立一个 server.py程序: import flask app = flask.Flask(__name__) @app.route("/") def index(): return "测试 scrapy" if __name__ == "__main__": app.run()这个程序建立好就可以执行了,建立 http://127.0.0.1:5000 的网站,访问这个网站返回 “测试 scrapy”。 (4)在 example\Test\Test\spider文件夹中 建立一个自己的 python文件,例如MySpider.py,这个程序就是爬虫程序 爬虫程序MySpider.py如下: import scrapy class MySpider(scrapy.Spider): name = "mySpider" def start_requests(self): url = 'http://127.0.0.1:5000' yield scrapy.Request(url=url, callback=self.parse) def parse(self, response, **kwargs): print(response.url) data = response.body.decode() print(data)(5)在 example\Test\Test文件夹中建立一个 执行程序run.py如下: from scrapy import cmdline cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())(6)保存这些程序并启动server.py, 然后允许run.py, 结果如下:
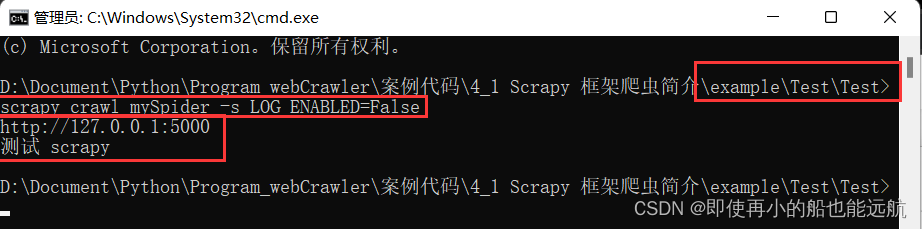
(1) import scrapy 引入scrapy程序包,这个包中有一个请求对象Request与一个响应对象 Response类。(2) class MySpider(scrapy.Spider): name = "mySpider" 任何一个爬虫程序类都继承于scrapy.Spider类,任何一个爬虫程序都 有一个名字,这个名字在整个爬虫项目中是唯一的,我们这个爬虫 名字为"mySpider"。(3) def start_requests(self): url = 'http://127.0.0.1:5000' yield scrapy.Request(url=url, callback=self.parse) 这个地址url是爬虫程序的入口地址,这个start_requests函数是程序的入口函数。程序开始时确定要爬取的网站地址,然后建立一个scrapy.Request请求类,向这个类提供url参数,指明要爬取的网页地址。爬取网页完成后就执行默认的回调函数parse。 值得指出的是scrapy的执行过程是异步进行的,即指定一个url网址开始爬取数据时, 程序不用一直等待这个网站的响应,如果网站迟迟不响应,那么整个程序不是卡死 !scrapy提供一个回调函数机制,爬取网站时同时提供一个回调函数, 当网站响应后就触发执行这个回调函数,网站什么时候响应就什么时候调用这个回调函数,这样对于响应时间很长的网站也不怕了。 yield后面介绍(4) def parse(self, response, **kwargs): print(response.url) data = response.body.decode() print(data) 回调函数parse包含一个scrapy.Response类的对象response,响应的一切信息,其中response.url是网站的网址,response.body是网站响应的二进制数据,即网页的内容。通过decode()解码后变成字符串,就可以print出来了。到目前为止爬虫程序就编写好了,但是这个程序MySpider.py只是一个 类,不能单独执行,要执行这个爬虫程序必须使用scrapy中专门的命令scrapy crawl。在命令行窗体,D:\example\Test\dTest中 执行命令: scrapy crawl mySpider -s LOG_ENABLED=False 那么就可以看到执行的结果如下图所示,其中mySpider就是我们爬虫程序的名称,后面的参数是不显示调试信息。
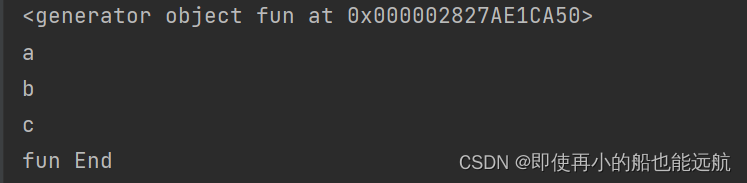
但是这样需要我们从PyCharm与命令行窗体之间来回切换,为了简单起见,专门设计一个Python程序run.py,它包含执行命 令行的语句: from scrapy import cmdline cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())直接运行run.py就可以执行MySpider.py的爬虫程序了,效果与命令行窗体中执行相同,结果还直接显示在 PyCharm中。 3. 入口函数与入口地址程序中使用了入口函数: def start_requests(self): url = 'http://127.0.0.1:5000' yield scrapy.Request(url=url, callback=self.parse)实际上这个函数也可以用start_urls的入口地址来代替: start_urls = ['http://127.0.0.1:5000']入口函数可以有多个,因此start_urls 是一个列表。入口函数与入口地址的作用一样,都是引导函数的开始。 4. Python 的 yield 语句在入口函数中有一条yield语句,yield是一个Python的一种特殊语句, 主要作用:返回一个值等待被取走 def fun(): s = ['a', 'b', 'c'] for x in s: yield x print("fun End") f = fun() print(f) # for e in f: print(e)程序执行结果:
由此可见,fun返回一个 generator 的对象 ,这种对象包含一系列的元素,可以使用 for 循环提取,执行循环的过程如下: for e in f: print(e)第一次 for e in f 循环,f 执行到 yield 语句,就返回一个值 'a', for 循环从 f 抽取的元素是 'a', 然后 e='a' 打印a。fun 中执行到了yield 时会等待 yield 返回的值被抽走,同时 fun 停留在yield 语句,一旦被抽走,再次循环,yield 返回 'b'。直到循环结束。 只要包含 yield 语句的函数都返回一个 generator 的可循环对象,执行到 yield 语句只返回一个值,等待调用循环抽取,一旦调用抽取后,函数又继续进行。这个过程非常类似两个线程的协作过程,当提供数据的一方准备好数据把 yield 提交数据时,就等待另外一方把数据抽取走,如果不抽走,yield 就一直等待, 一旦抽走后,数据提供方继续它的程序,一直等到出现下一处 yield 或者程序结束。 Scrapy 的框架使用的是异步执行的过程,因此大量使用 yield 语句。 yield 生成器 包含yield语句的函数是一个生成器 生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值 生成器是一个不断产生值的函数 return 与 yield 的区别 def gen(n): for i in range(n): yield i ** 2 for i in gen(5): print(i, end=" ") # 0 1 4 9 16 print() # ========================================== def square(n): ls = [i ** 2 for i in range(n)] return ls for i in square(5): print(i, end=" ") # 0 1 4 9 16 print()yield 生成器的优势 更节省存储空间响应更迅速使用更灵活 5. Scrapy 爬虫的数据类型Request 类 class scrapy.http.Request() Request对象表示一个HTTP请求由Spider生成,由Downloader执行 属性或方法说明.urlRequest对应的请求URL地址.method对应的请求方法,'GET' 'POST'等.headers字典类型风格的请求头.body请求内容主体,字符串类型.meta用户添加的扩展信息,在Scrapy内部模块间传递信息使用.copy()复制该请求Response 类 class scrapy.http.Response() Response对象表示一个HTTP响应由Downloader生成,由Spider处理 属性或方法说明.urlResponse对应的URL地址.statusHTTP状态码,默认是200.headersResponse对应的头部信息.bodyResponse对应的内容信息,字符串类型.flags一组标记.request产生Response类型对应的Request对象.copy()复制该响应Item 类 class scrapy.item.Item() Item对象表示一个从HTML页面中提取的信息内容 由Spider生成,由Item Pipeline处理,Item 类似字典类型,可以按照字典类型操作 |


【本文地址】
今日新闻 |
推荐新闻 |