【Python成长之路】Python爬虫 |
您所在的位置:网站首页 › python爬取网页乱码 › 【Python成长之路】Python爬虫 |
【Python成长之路】Python爬虫
|
【写在前面】 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\xe7\x9),如下图所示:  网上 查找了一些方法,以为是遇到了网站加密处理。后来发现 通过F12还 是能获取网页的元素,那么有什么办法能规避乱码问题呢?答案是:用selenium. 【效果如下】 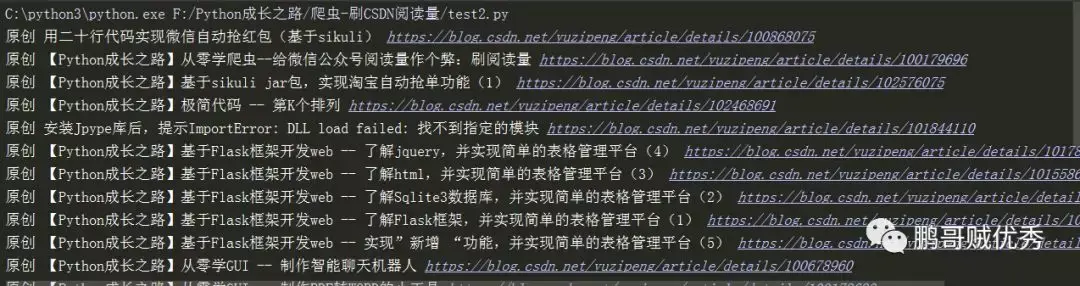 【示例代码】 # coding=utf-8 # @Auther : "鹏哥贼优秀" # @Date : 2019/10/16 # @Software : PyCharm from selenium import webdriver url = 'https://blog.csdn.net/yuzipeng' driver = webdriver.Chrome("F:\\Python成长之路\\chromedriver.exe") driver.get(url) urls = driver.find_elements_by_xpath('//div[@class="article-item-box csdn-tracking-statistics"]') blogurl = ['https://blog.csdn.net/yuzipeng/article/details/' + url.get_attribute('data-articleid') for url in urls] titles = driver.find_elements_by_xpath('//div[@class="article-item-box csdn-tracking-statistics"]/h4/a') blogtitle = [title.text for title in titles] myblog = {k:v for k,v in zip(blogtitle,blogurl)} for k,v in myblog.items(): print(k,v) driver.close()【知识点】 1、selenium使用 基本的selenium安装方法、使用方法(如查找元素的各类函数)可以详见之前的博客《【Python成长之路】从零学爬虫--给微信公众号阅读量作个弊:刷阅读量》 (https://blog.csdn.net/yuzipeng/article/details/100179696) 2、推导式使用 (1)列表推导式:[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件] 类似这样就可以实现将for循环的多行程序浓缩到一句代码 中,如 blogtitle = [title.text for title in titles]而如果用for循环写,则需要这样: blogtitle = [] for title in titles: blogtitle.append(title)(2)字典推导式:{ key表达式: value表达式 for value in collection if condition } 这样的写法,一般用于key和value能相互转换;但是如果key和value是完全不同的列表,那就需要用zip对key/value进行整合。 myblog = {k:v for k,v in zip(blogtitle,blogurl)}如果对zip函数不熟悉,可以用下面的例子来 介绍下。 a = ['a', 'b', 'c'] b = [1, 2, 3] c = {k: v for k, v in zip(a, b)} print(c) 结果是:{'a': 1, 'b': 2, 'c': 3}更多精彩内容,请滑至顶部点击右上角关注小宅哦~  作者:鹏哥贼优秀 |
【本文地址】
今日新闻 |
推荐新闻 |