|
一、爬取界面分析
爬取网站:https://www.shicimingju.com/book/sanguoyanyi.html
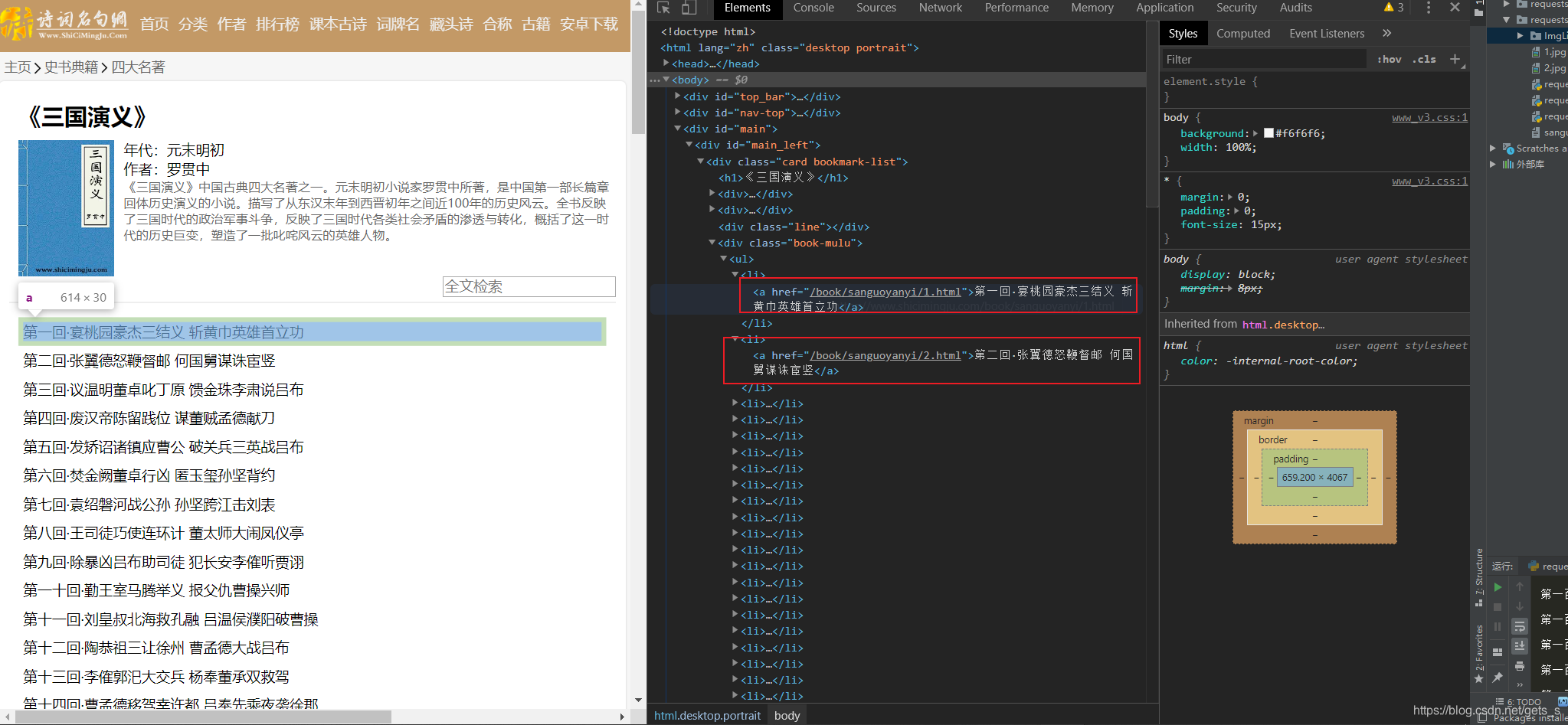 通过分析,该界面采用静态加载的方式呈现数据,即获取网页源代码可获取相应的数据,在本界面中获取的数据有章节的标题,以及章节内容的链接。 通过分析,该界面采用静态加载的方式呈现数据,即获取网页源代码可获取相应的数据,在本界面中获取的数据有章节的标题,以及章节内容的链接。 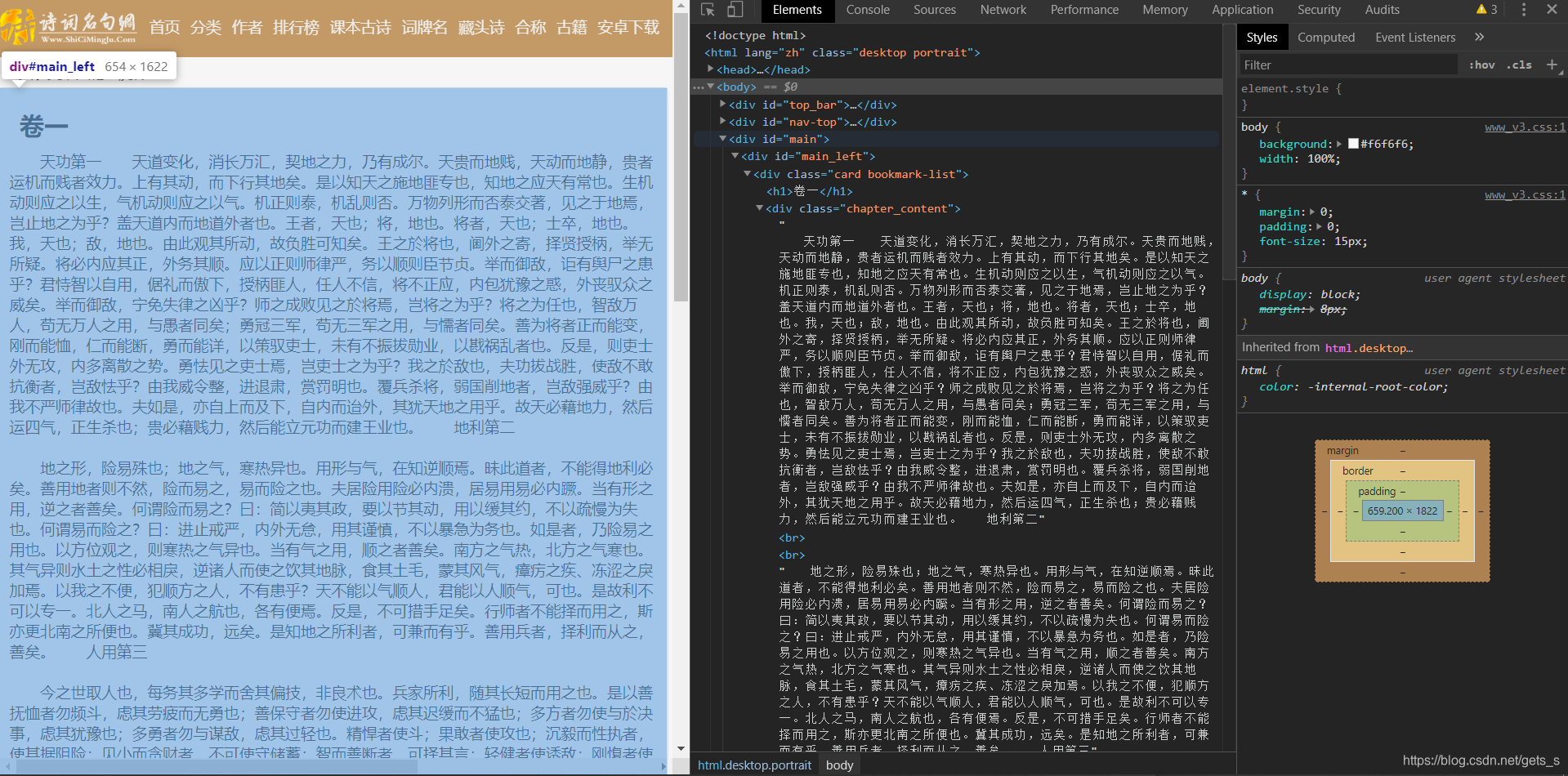 在章节内容界面,同样时采用静态加载数据的方式。 在章节内容界面,同样时采用静态加载数据的方式。
二、程序源代码
import requests
from bs4 import BeautifulSoup
fp = open('./sanguo.txt','w',encoding='utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
main_url = "https://www.shicimingju.com/book/sanguoyanyi.html"
page_text = requests.get(url = main_url,headers = headers)
page_text.encoding = page_text.apparent_encoding
page_text = page_text.text
soup = BeautifulSoup(page_text,'lxml')
a_list = soup.select('.book-mulu > ul > li > a')
for a in a_list:
title = a.string
detail_url = 'https://www.shicimingju.com' + a['href']
page_text_detail = requests.get(detail_url,headers = headers)
page_text_detail.encoding = page_text_detail.apparent_encoding
page_text_detail = page_text_detail.text
soup = BeautifulSoup(page_text_detail,'lxml')
div_tag = soup.find('div',class_ = 'chapter_content')
content = div_tag.text
fp.write(title + ':' + content + '\n')
print(title,'保存成功!!!')
fp.close()
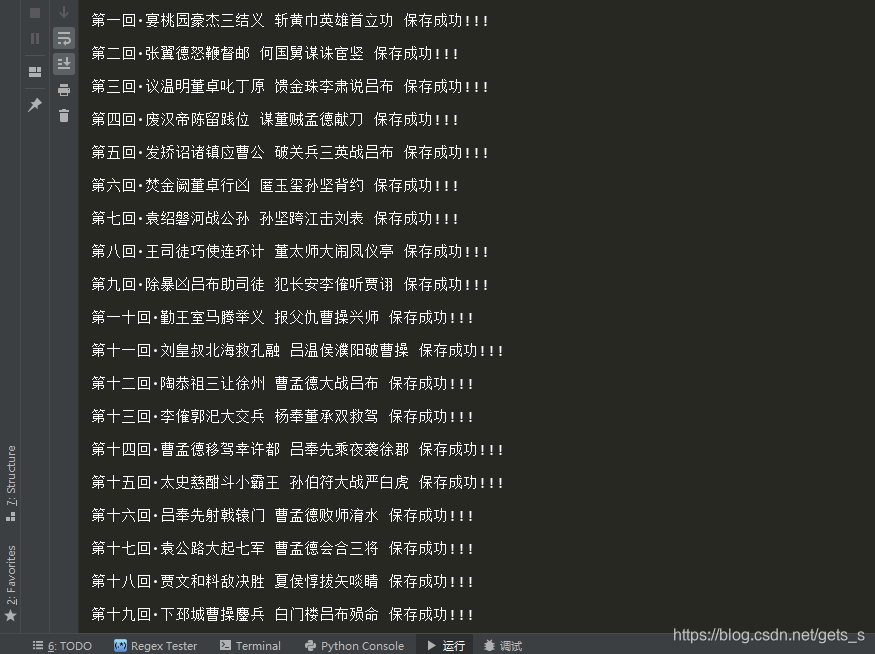
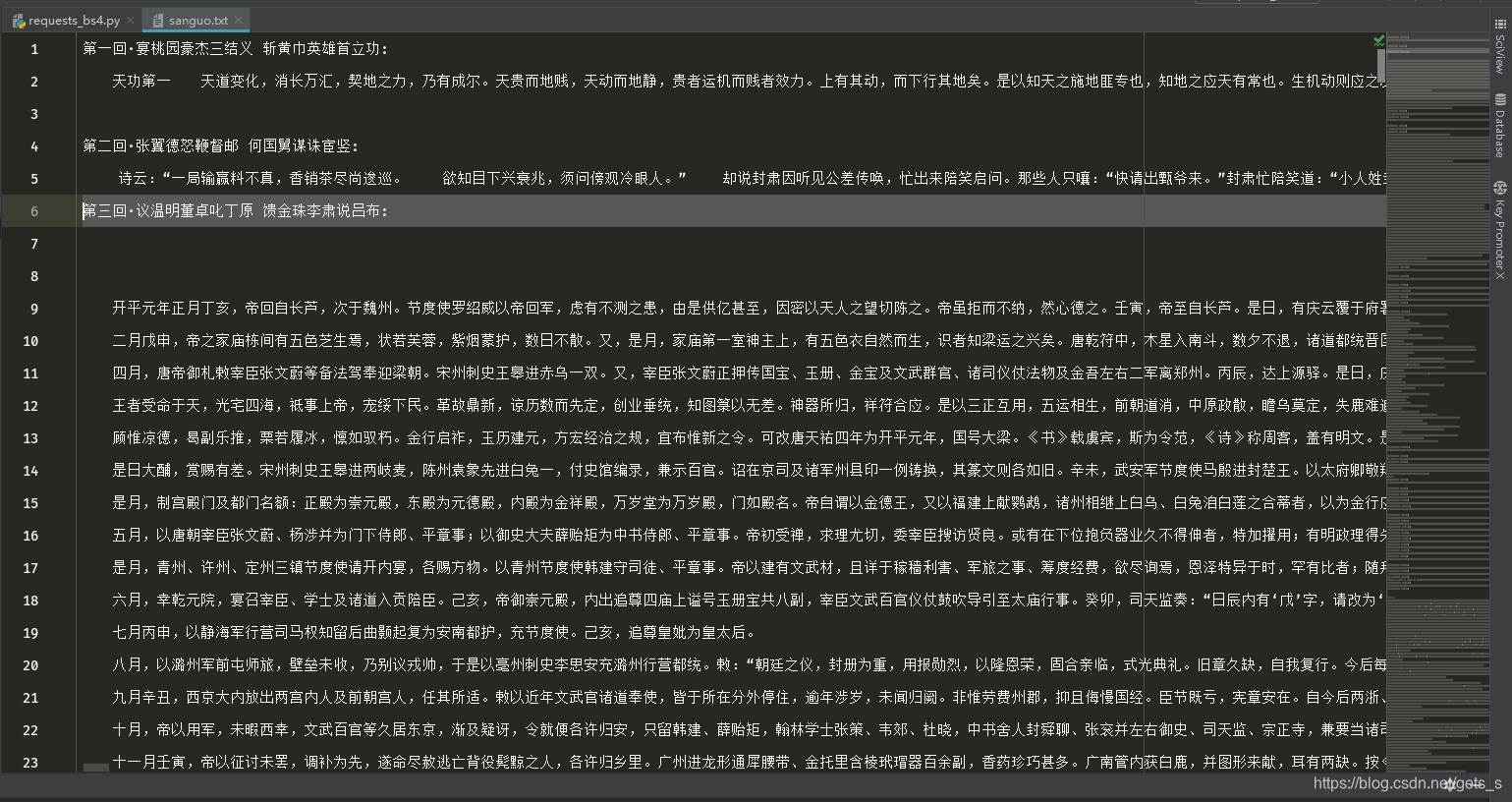
三、程序运行结果
|