数据挖掘算法原理与实践第一关:标准化 |
您所在的位置:网站首页 › python数据标准化处理方法 › 数据挖掘算法原理与实践第一关:标准化 |
数据挖掘算法原理与实践第一关:标准化
|
本关任务:利用sklearn对数据进行标准化。 为什么要进行标准化在机器学习中常忽略数据的分布,仅仅对数值做零均值、单位标准差的处理。在一个机器学习算法的目标函数里的很多元素所有特征都近似零均值,方差具有相同的阶。如果某个特征的方差的数量级大于其它的特征,那么,这个特征可能在目标函数中占主导地位,这使得模型不能从其它特征有效地学习。 三种标准化方式 Z-score标准化公式: 代码实现: from sklearn import preprocessing import numpy as np X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) X_scaled = preprocessing.scale(X_train) Min-max标准化公式: 代码实现: X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) min_max_scaler = preprocessing.MinMaxScaler() X_train_minmax = min_max_scaler.fit_transform(X_train) MaxAbs标准化公式: 代码实现: X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) max_abs_scaler = preprocessing.MaxAbsScaler() X_train_maxabs = max_abs_scaler.fit_transform(X_train) 编程要求在右侧编辑器Begin-End处补充Python代码,实现数据标准化方法,我们会使用实现好的方法对数据进行处理。 测试说明 我们会调用你实现的方法对数据进行处理,如使用Z-score方法,则处理后数据均值为0方差为1,如使用minmax方法,则处理后数据最小值为0,最大值为1,如使用maxabs方法,则处理后数据最大值为1。我们会对结果进行检测,完全正确则视为通关。 # -*- coding: utf-8 -*- from sklearn.preprocessing import scale,MaxAbsScaler,MinMaxScaler #实现数据预处理方法 def Preprocessing(x,y): ''' x(ndarray):处理 数据 y(str):y等于'z_score'使用z_score方法 y等于'minmax'使用MinMaxScaler方法 y等于'maxabs'使用MaxAbsScaler方法 ''' #********* Begin *********# if y == 'z_score': x = scale(x) return x elif y == 'minmax': min_max_scaler = MinMaxScaler() x = min_max_scaler.fit_transform(x) return x elif y == 'maxabs': maxabs = MaxAbsScaler() x = maxabs.fit_transform(x) return x #********* End *********# |
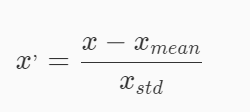 结果: 对每个特征/每列来说所有数据都聚集在0附近,方差值为1。
结果: 对每个特征/每列来说所有数据都聚集在0附近,方差值为1。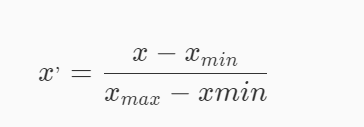 结果: 将原始值x通过min-max标准化映射成在区间[0,1]中的值x’
结果: 将原始值x通过min-max标准化映射成在区间[0,1]中的值x’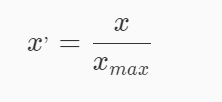 结果: 通过除以每个特征的最大值将训练数据特征缩放至 [-1, 1] 范围内
结果: 通过除以每个特征的最大值将训练数据特征缩放至 [-1, 1] 范围内【本文地址】
今日新闻 |
推荐新闻 |