玩手机行为检测(分类+检测) |
您所在的位置:网站首页 › python接电话 › 玩手机行为检测(分类+检测) |
玩手机行为检测(分类+检测)
|
向AI转型的程序员都关注了这个号👇👇👇 项目背景
因此在工业上,对于手机行为的检测需求日益增多,目前主要采用检测进行手机的定位辅助分析。 本项目针对这一特点,实现思路如下: 利用PaddleX快速训练轻量化检测模型PP-YOLO Tiny,并通过一个识别模型MobileNet进行检测矫正。- 保证实时性的同时,也保证较高的精确度。 代码地址: 关注微信公众号 datayx 然后回复 玩手机 即可获取。 一、数据样式(数据说明)本项目的数据分为 检测数据(8000张) 与 识别数据(16683张) 两类: 1.检测数据检测数据位于数据集: 违规使用手机识别.zip data/data105315/违规使用手机识别.zip 解压后,数据包含在train.zip中,还需再次解压数据,最后解压完成后,数据如下:
最终用于训练的检测数据位于0_phone中,检测数据格式为VOC格式——可直接使用PaddleX进行数据划分,并直接用于PPYOLO-Tiny模型的训练。 用于检测的数据在当前项目中仅仅包含0_phone下的数据,该数据均为包含手机的图片,因此,后期项目训练过程中,可以适当的添加1_no_phone中的图片作为背景图片加入到模型的训练数据中。
识别数据位于数据集: recognize_phonedata.zip data/data105315/recognize_phonedata.zip 解压后,数据如下:
其中, 0_recognize_phone文件夹中包含手机的识别图片,1_recognize_nophone中包含非手机的识别图片。 识别数据中的0_recognize_phone文件夹图片均来自检测数据中0_phone中标注的手机(裁剪)数据,而1_recognize_nophone文件夹图片均来自1_no_phone中随机裁剪的数据作为非手机的类别。
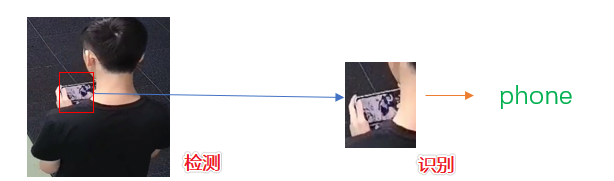
本项目中的非手机图片数据集由随机裁剪获得,受限于原始1_no_phone中存在一些大小不均匀的图片,因此固定大小尺寸进行裁剪后,有的非手机图片为人或者衣服等。 但按照该识别数据集,对于该任务已经有了一个不错的提高——后期通过完善识别模型的数据以及泛化精度的提高,将更好的提升该串联方案的效果。 二、模型选择(应用场景考虑)考虑到工业应用上,通常要求实时性与部署成本的问题,选择轻量化化检测模型PP-YOLO Tiny作为检测模型——同时,为了保证一个手机识别的较高准确率,训练一个识别是否为手机的识别模型,对检测后的目标进行二次识别,保证检测的准确性。 因此,模型的架构为: PP-YOLO Tiny(目标检测) + MobileNet(图像识别)
之所以外加MobileNet作为精度提升的一个组件,是因为PP-YOLO Tiny在追求轻量化时,骨干网络相对较弱,在识别精度上有一定的错误率(可能来源骨干网络识别能力不够,也可能因为定位能力不够导致识别受影响); 三、模型训练首先下载PaddleX2.0用于后期的项目开发。 pycocotools: 是为了提供COCO数据集的加载功能——以辅助Paddlex实现数据的自动划分、数据格式转换等
数据预处理方法: https://github.com/PaddlePaddle/PaddleX/blob/release/2.0.0/docs/apis/transforms/transforms.md train_transform:
VOC格式数据自动加载接口
由于不同的数据集的应用场景等不同,因此模型在使用时,往往针对特定数据进行anchor的聚类生成会更容易拟合数据集。 一般来说,聚类后的anchors仅适用于训练时特定的大小,部署时不宜改动,否则精度损失较大
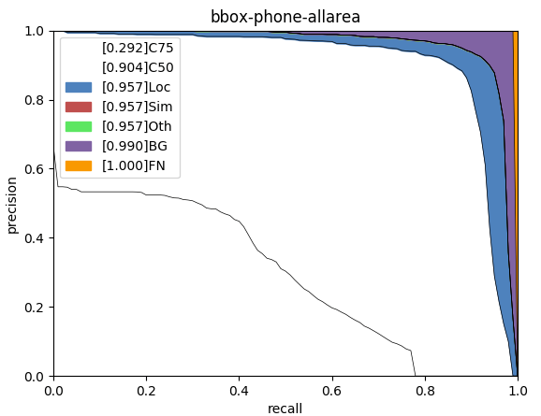
如果直接运行coco_error_analysis失效(及以下代码),可手动重新生成json再进行分析(后续代码)
用于展示模型检测效果
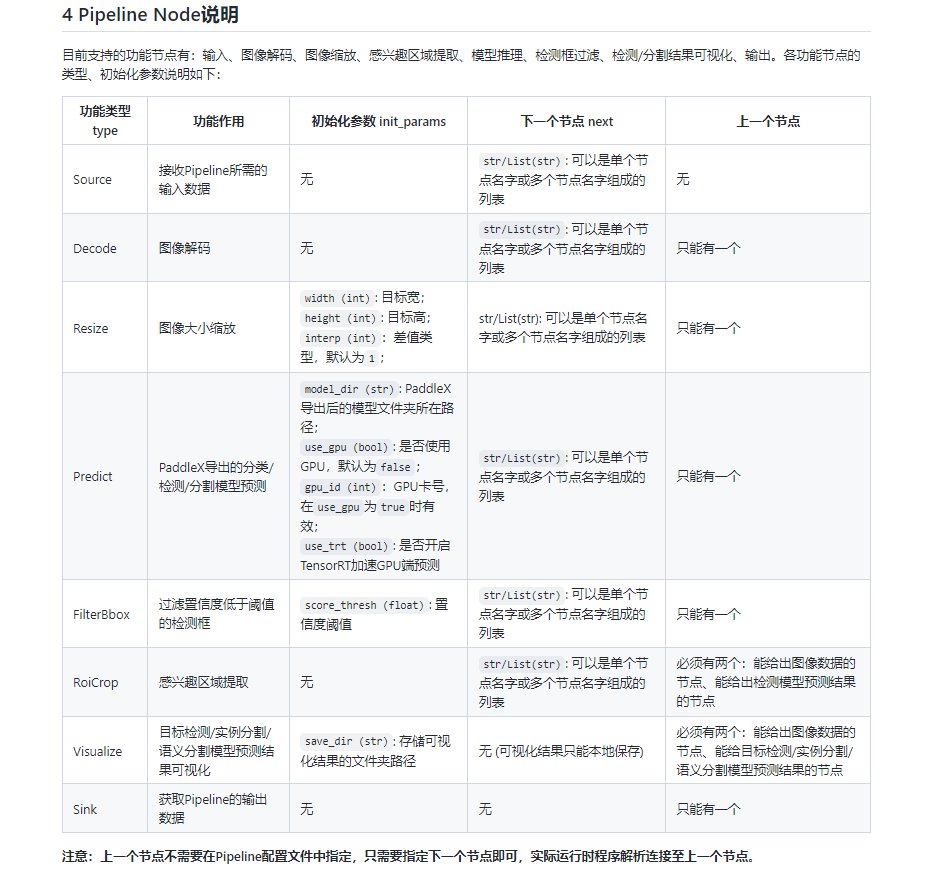
SDK是指: PaddleX Manufacture基于PaddleX-Deploy的端到端高性能部署能力,将应用深度学习模型的业务逻辑抽象成Pipeline,而接入深度学习模型前的数据前处理、模型预测、模型串联时的中间结果处理等操作都对应于Pipeline中的节点PipelineNode,用户只需在Pipeline配置文件中编排好各节点的前后关系,就可以给Pipeline发送数据并快速地获取相应的推理结果。
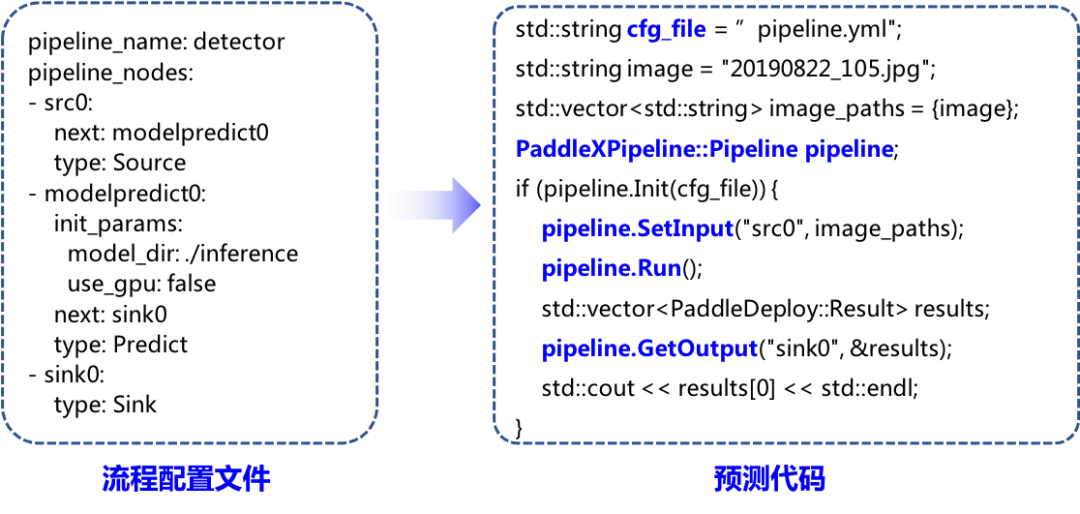
PaddleX Pipeline:完成业务逻辑的推理预测,同时提供向其发送数据和获取结果的接口。 PaddleX Config: 定义Pipeline的节点类型和前后关系。 PaddleX Node:功能节点,例如图像解码节点、图像缩放节点、兴趣区域提取节点、模型推理节点。 PaddleX Deploy:高性能模型推理能力。 以PaddleX导出后的单一检测模型(无数据前处理、无中间结果处理)为例,配置好流程配置文件后使用简单几行代码就可以完成预测:
而对于本项目的SDK部署不再采用单模型的Pipeline,而是通过SDK实现更便捷的模型串联——即多模型Pipeline。 检测+识别的模型部署串联Pipeline
在测试时,请注意使用存在目标的图片进行串联测试——因为当前SDK版本下,检测与识别串联时,如果检测无目标,在传入识别模型时会报错终止。 检测与分割串联时,如检测无目标,传入分割模型不会报错终止! 节点相关内容可参考下图 2.节点表
|

























【本文地址】
今日新闻 |
推荐新闻 |