Python笔记(五个常用的序列结构) |
您所在的位置:网站首页 › python序列包括字符串吗 › Python笔记(五个常用的序列结构) |
Python笔记(五个常用的序列结构)
|
什么是序列
序列是用于存放多个值的连续空间,并且按一定的顺序排列,每个值被称为元素,并且给其分配一个数字称其为索引,通俗点说,和C语言,Java中的数组作用一样,但是这里不叫数组了,叫列表,元组,字典,集合和字符串,每种都有它自己的特点。但是这五种都被称为序列。 先介绍两个序列中基本概念: 索引索引这个概念已经不陌生,就是指示元素在序列中的位置,和数组中的一摸一样,在数组中的第一个元素的下标位置都是从 0 开始的,并不是从1开始的,这里很简单理解,同理,这里的索引也是从 0 开始,表示序列中的第一个元素。 非常简单,但是python中的索引更牛逼的是,它可以为负数,从-1开始,-2,-3 -4 … 从上图可以看出当其正数的时候是从左算起,那么当负数的时候,从右边算起。最右边的索引为 -1 ,然后从右往左开始递归。 例: print(verse[2]) // 输出第三个元素 print(verse[-1]) //输出最后一个元素 切片所谓切片,就是将序列中范围内的元素切出来,可以构建成一个新的序列,虽然叫切片,但是原来的序列不会改变。 sname[start:end:step]sname:要切片的序列 start , end:元素的索引,切片的开始位置和结束位置,但是切片包括start自身的位置,不包括end自身的位置,比如0:2那么切出来的就是元素1,元素2 step:步长,默认为1,就是看你切的时候是否跳段,比如设置为 2 的话 0:3:2 ,那么取出来的就是元素1,元素3,就是从第一个元素到第二个算为1步,默认为1,所以不跳,然后设置为2,就是每间隔两步取一个 例: ver=["zhang","wang","li"] print(ver[0:1]) //输出 "zhang",从索引0到1,但是不包括end自身,所以没有 "wang" print(ver[0:2]) //输出"zhang","wang",同理不包括end自身,没有"li" print(ver[0:3:2]) //输出"zhang","li",这里设置了步数,从zhang然后,步数跳转,下一个 "li" print(ver[:]) //表示从头切到尾,将序列中所有都输出在所有序列结构中都有增删改除查找的功能,因为和数组类似,所以下面就是从这几个方面概述 列表列表是序列中的基础,其他结构都是在该结构上做的增强,那么什么是列表? 首先列表和数组差不多,但又比数组强,数组定义的时候必须定义其是什么类型的,只能放一种类型的数据,但是Python强大之处在于可以随便往里面放任何类型的数据,比如你往列表里放 int 和str,显然在C或者Java是行不通,但是这里还可以放字符串,再放一个列表,等等,这里就是其强大之处。 创建列表首先列表创建十分简单,Python的宗旨就是代码简洁高效。 列表名称=[随便类型数据] ,中间加上分割符号 逗号即可(下面都是例子) 名称=直接给数据 listname=["xiaoli",18] //存储两个元素 名称=用list()转换列表函数来转化数据, listname=list(range(0,5)) //将0到4的值赋值给listname,不包括5,可以看range()函数 删除列表所有序列结构删除操作都是一样: del listname //用一个del+删除名称即可一般情况下不需要手动删除,Python会自动销毁长时间不用的列表。 访问列表元素最简单,输出列表中所有的元素,包括其他序列结构都相同,使用print语句即可输出所有元素 print(listname) //输出列表中的所有元素列表和数组相同,比如你想输出某个,那么根据它的索引即可输出: print(listname[0]) //输出列表中的第一个元素 print(listname[2]) //输出列表中单第三个元素如果想遍历列表,用for循环,这里其实使用了迭代器的原理,它会自动按照列表中的元素顺序读取元素的值,然后赋值到参数里 (参数名称都是自定义的哦) for name in listname: //name为参数,listname为列表名称 print(name) //每次循环输出参数 使用enumerate()函数,将list名称放到该函数中,它每次循环的时候会自动返回俩参数,一个元素的索引值,一个元素自身的值 for index,name in enumerate(listname): print(index,name) 增删改除元素每个列表都是对象,和Java中的一样,对象中都有对应的函数方法,然后往列表中添加元素调用了对象中的方法,都是Python列表中已经定义好的函数,直接调用即可 1.添加元素 直接添加,添加到列表的尾部(append函数) listname.append(obj) //例如添加一个名称 listname.append("zhang") 通过索引添加到列表中的指定位置(insert函数) listname.insert(index,obj) //例如往第一个位置插入listname.insert(0,"wang")2.修改元素 修改元素十分简单,直接把要修改的拖出来,重新赋值即可 listname[2]="zhang" //将索引为2位置的元素只修改为"zhang"3.删除元素 用 del 直接根据索引或者元素的值来删除某个元素,十分简单 根据元素索引删除 del listname[2] //删除索引为2的元素 根据元素值来删除(remove函数) listname.remove("zhang") //删除元素值为"zhang"的元素 排序将列表进行排序,但是列表中的值必须为一个类型的数据才可以进行对列表的排序,要么全为 int,要么为 str,int 类型数据根据大小进行排序,自然 str 类型是按照ASCII码来进行大小排序,和其他语言一样 sorted() 函数也是列表对象的内置函数,直接使用列表对象调用即可 这里sort和sorted函数区别就是,sort排序后不改变原值,相当于一个临时的排序列表,sorted调用后直接改变原列表的值 list1=[34,12,55,14,41] list1.sorted() //对list1进行排序,会将list1的值覆盖,就是调用了函数后,列表就已经是排序后的列表了 print(list1) //输出结果为[12, 14, 34, 41, 55]很显然排序结果是升序的,可以在 sort 函数加上参数进行条件排序 sort(key=None,reverse=False) //第一个参数表示从列表元素中提取一个比较键,第二个参数表示排序是否降序,此时都是默认状态下的参数 key=str.lower //表示不按字母大小写排序 reverse=True //表示降序排列,默认是Flase所以默认是升序排列,True为降序 列表推导式比如你想创建一个从1到100的列表,像之前说的那样创建吗?创建列表的时候将1到100打一遍?如下,显然有点傻X,你倔强,可以打出来,那要你创建一个1到10000的列表呢?显然不可能,那么就出现了列表推导式 list1=[1,2,3,4,5,6,7,8,.....,99,100]什么是推导式?就是在创建列表的时候可以快速创建一个列表,根据列表的生成要求来创建列表,就和上面一样,只要一句话,它就会自动创建一个值为1到100的列表,就一句话,就可以创建一个你所需要的列表了,显得十分高逼格 list1=[i for i in range(0,101)]那么推导式语法是什么呢? listname=[Expression for var in range]可以看成两部分,一个前面的表达式Expression和后面的循环表达式,前面表达式就是后面每次循环完返回的参数值然后进行加工,然后返回到列表中成了元素,后面就是for循环的范围,每次循环的值返回到 var 参数里面,主要取决于range函数范围,range函数的使用这里就不细讲了 比如上面那个例子,要创建一个1到100的列表,首先你确定好循环的范围,显然是用 for 循环来获得值,范围为range(1,101),然后循环每次返回到var里面,显然这里不需要对var进行加工,直接使用就可以了,那么后面的循环表达式就为 for i in range(0,101)然后每次返回的参数值,直接使用放到列表中当元素使用就可以了 list1=[i for i in range(0,101)]后面的循环也可以作为你循环的次数,比如创建一个10个随机数的列表: list1=[random.randint(10,100) for i in range(10)]前面的表达式就是创建一个随机值,然后后面就是循环的次数,这里没有对循环的参数进行处理 首先确定好你循环的范围,再来确定前面的表达式如何来满足你的要求,它们总的式子就被称为推导式 元组元组与列表相似,自然也和数组相似,但是它的括号不是用 [ ]了,而是用(),但是不可能就只有这么点差别,否则你弄出个这么个东西干嘛,对吧,元组和列表的最大区别就是它是不可变序列,就是它不能增删改元素,你一旦创建好了元组,那么只能访问其数据,不能改动。 创建元组元组创建和列表一摸一样,元组中的数据类型没有限制 ,直接创建即可,但是元组使用的是 () tuplename=("xiaoli","xiaowang",20) 也可以不用括号,也是元组的创建 tuplename="xiaoli","xiaowang",20 但是如果创建只有一个元素的元组,必须在元素后面加上逗号,否则就成为了 str 类型 tuplename=("xiaowang",) //必须加逗号,此时就为元组类型 tuplename=("xiaowang") //此时就为字符串类型,可以用type()来查看该数据类型 也可以通过tuple()转化元组函数来转化数值 tuplename=tuple(range(0,5)) 删除元组通用 del 删除,Python通常使用 del 就可以删除对应的数据 del tuplename 访问元组元素输出所有元组还是用 print print(tuplename)输出具体某个元素的值: print(tuplename[2]) //尽管元组定义是用(),但是和数组一样,输出某个具体值还是用[],此处根据索引获得值和列表一样,可以遍历获得值 for i in tuplename: print(i)同时可以获得其对应的索引值,使用enumerate( )函数,并将元组放到该函数中做参数,该函数会自动返回俩参数,一个index索引,一个元素值 for index,i in enumerate(tuplename): print(index,i) 修改元组前面都说了,元组每当创建好了,就无法对元组里面的元素改变,没法增删改除,那么为什么这里还要说可以修改元组? 其实是使用了重新赋值的思想来进行修改 tuplename=("zhang","wang") 想添加一个元素 "li" tuplename=("zhang","wang","li") //重新赋值当然这里显得有点傻X,有点麻烦,还得重新赋值,但是如果迫不得已只能这样,一般不会,所以元组和列表相比起来,如果你只提供读取数据的作用,那么元组的效率是极高的 元组推导式元组推导式和列表推导式一样,目的就是快速构建一个元组,操作也是一样的,就只有一点不一样,元组推导式出来的是生成器对象(generator),生成器是迭代器的改进版,这里不细说了,具体原理看下面文章 生成器和迭代器 具体用法和列表的一样,可以看列表的推导式语法,这里举个例子,还是创建一个0到10的元组 tuplename=(i for i in range(11))非常简单,都说了和列表一样,只要把方括号换成圆的即可,但是元组推导式出来的是一个生成器对象,你要直接将该元组输出是不能的,会显示类型为生成器对象,无法输出。
还有一种方法,既然推导式出来的是生成器对象,因为也是一种迭代器,那么使用迭代器的内置函数__next__()来遍历,该函数会返回元组中的值,但是遍历完以后,对应的元素也会消失 tuple1=(i for i in range(11)) //用推导式创建元组 print(tuple1.__next__()) //这里不进行转换,直接对生成器对象直接输出,从第一个开始迭代,输出结果为0,可以试试 //只会迭代一次,迭代完后,元素也会消失,此时是从0开始迭代,迭代完,元素0就会消失了,可以将其转换为元组看看 集合这里集合(Set)和 Java 中的集合类似,存储不重复的数据是其最大特点,就算一直往集合添加重复数据,但正真存储在集合中的只有一个,用 { } 来代表集合的序列结构。 创建集合Python里的数据创建十分简单也比较统一,还是和之前一样,直接用等号赋值,只要是用的 { },它就能识别出来是集合数据类型,还是和之前一样,可以放任何数据类型。 setname={"wang",18} //直接集合名=数据值 setname={2,2,3,4,3} //set集合中不会有重复的值,所以创建好的set就是{2,3,4}序列中的各种结构都可以互相转换,用它们各自的函数,比如想转为列表,那么用 list() ,若想转化为元组,则用 tuple(),同理集合也是 ,用 set(). list1=["zhang","li","wang"] //创建一个列表 set1=set(list1) //将列表转化为集合 print(set1) //那么输出就是集合,输出结果{'zhang', 'li', 'wang'} 删除集合删除还是用del del setname用 clear() 函数也可以清空集合,但是集合还存在,成为了空集合 访问集合输出集合所有内容 print(setname) 增删改数据集合就像一个容器,你往容器里一直塞东西,你再取的时候,你会知道你存放的顺序吗?所以集合是一个没有索引的序列,你根据它的索引去增删改和查找是不行的。 1.添加元素 集合和容器一样,所以你只要往进放就好了,不需要管他放到哪个位置了,不像列表元组那样,有顺序的放。 用 add() 函数 setname.add(element)因为没有索引,所有没有根据索引来添加元素 2.删除元素 都说了没有索引,那你怎么找到它的位置来删除?所以只有根据元素的值来删除了,根据索引删除用 del,根据元素值来删除自然用 remove( ) setname.remove("zhang") //从集合中删除元素值为zhang的元素 也可以用 pop()函数来删除集合中的第一个元素 setname.pop() 集合推导式集合推导式和列表一摸一样,不像元组那样推导出来的是生成器对象,这里直接就可以使用,十分简单,做一个1到10的集合: setname={i for i in range(11)} 集合的交并差集数学中的交集,并集和差集大家都知道,那么同理在这里肯定也不难理解,很简单,记住交集用符号 & 并集 | 差集 -就够了,原理和数学中的完全一样,这里就不详细讲解了。 print(set1&set2) //输出set1和set2集合的交集 print(set1|set2) //输出set1和set2集合的并集 print(set1-set2) //输出set1和set2集合的差集 字典字典顾名思义,大家都懂,那么为什么要把这种序列结构称为字典?肯定和它本身事物脱不了关系,首先,你要用字典查一个字,肯定先找到该字的拼音,然后找这个字的用法,同理,字典序列结构也是如此,它是以set集合为基础的序列结构。 字典相当于Java中的Map,每个元素都是一个key-value键值对,都说是以set为基础的,所以字典也没有索引,而key充当了索引的作用,一个key只能对应一个值,并且键值不能随意改变,可以存放任意对象无序集合。 创建字典那么既然是以set为基础,那么肯定也是用括号 { }了,还是直接用等号赋值,但是每个元素必须是key-value形式,用冒号来表示关系 下面是最直接简单的创建方式 dictionary={‘key1’:'value1','key2':'value2'...} 例如 dictionary={"name":"maoyuanyuan","age":18}也可以用dict()函数去创建字典: dictionary=dict("name"="zheng","age"=18)但是显得麻烦,然后就是用给定的列表或者元组直接一 一对应的关系来创建字典用zip()函数 该函数有俩参数 zip(list1,list2),前面list1可以为列表也可以为元组,作为字典的键值,后面的list2也可以为列表或者元组,作为字典的值,很简单理解,但是该函数返回的是一个zip对象,如果需要元组,则需要转化,若需要的是字典,那么用 dict() 转化。 list1=[1,2,3] //创建列表1,当然这里也可以是元组 list2=["a","b","c"] //创建列表2,当然这里也可以是元组 dict1=dict(zip(list1,list2)) //用zip函数来进行映射关系的创建,前面参数作为key,后面参数作为value,但是返回的是zip对象,不能直接使用 print(dict1) //输出为{1: 'a', 2: 'b', 3: 'c'} 删除字典最简单,直接用del del dictionary 访问字典输出字典所有元素还是直接用 print 即可 print(dictionary)因为字典是key-value形式,key起主导作用,所以查询具体值一般都是查 key 来获得value print(dictionary[key]) //输出该key对应的value但是一般建议用内置函数 get()函数,参数为key,便可直接返回value,后面的参数default表示如果在字典里没有找到该key,那么就会返回后面的default内容 print(dictionary.get(key[,defalut])) 例如 print(dictionary.get("name")) //输出key为name的内容 print(dictionart.get("name","找不到该key")) //如果字典中没有该key,那么就会输出 ”找不到该key“遍历字典,就是获取字典中所有的键值对,直接用内置函数 items()函数即可,用for循环进行递归遍历: for i in dictionary.items(): print(i)就会输出如下结果 当设置for循环的时候如果设置两个参数,那么会自动返回相应的key和value for key,value in dictionary.items(): //这两个参数名称随便定义,这里并不是定死的 print("key为",key,"value为",value)那么会输出下面结果: 如果需要的话,也可以单独只返回字典的所有key,或者所有的value dictionary.keys() dictionary。values() 增删改字典元素1.添加元素 字典是一种可变序列,所以可以直接赋值,就可以添加到字典中了 dictionary[key]=value2.修改元素 和上面的添加元素操作一样,如果已经存在的话,你对他要进行重新修改,那么对该key重新赋值即可,便起到了修改的作用 dictionary[key]=newvalue3.删除元素 因为之前说过对索引删除直接用del,虽然这里没有索引,但是有顶替索引位置的key,所以也用del即可 del dictionary[key] 字典推导式推导式作用就不再说了,那么字典推导式怎么做?还是和之前一样。就是表达式加了一个关系,key和value的关系. 例如创建三个随机数: dictionary={i:random.randint(0,10) for i in range(3)} //前面是键值关系表达式,后面是进行循环 print(dictionary) //输出结果为{0: 5, 1: 3, 2: 6}显然已经创建好了 字符串字符串已经不陌生,字符串在Python里面属于序列结构中的一种,存放一串字符,在C或者Java已经很了解 创建字符串字符串创建十分简单,也是相当于一个变量,就和 age=10,那么age自然为 int 类型数据,那么Python是如何做判断呢,肯定是按照后面的数据类型,如果数据加上 " "或’ '那么自然就将变量识别为了字符串(str),很简单 strname="..." 删除字符串直接用del del strname 输出字符串很简单和之前比较统一,直接输出字符串内容 print(str)若想输出字符串哪个位置的单个值,那么这里就和字符串数组一样了直接输出哪个位置的字符 print(strname[0]) //输出字符串第一个字符当然也可以输出范围内的字符,当然和之前的 start,end,step用法一样,就不多说了 print(strname[:3]) //输出字符串从头开始的三个字符 print(strname[3:]) //从字符串中索引为3的字符开始输出,输出至结尾为止 字符串编码问题1.编码 字符串可以转化为二进制数据,也称为编码,中文常用编码为GBK ,gb2312,UTF-8 用字符串对象中内置函数 encode() 函数进行编码,第一个参数为编码的类型,默认为UTF-8第二个参数为用于指定错误的形式,strict为严格处理,遇到非法字符就返回异常,ignore忽略非法字符,replace用 ?来替代非法字符。两个参数都是可选参数。 str.encode(encoding="GBK"[,errors="strict"]) 若只有encoding一个参数需要写的话,那么参数名可以省略,直接写参数即可 str.encode("GBK")编码和译码都不会改变原来的字符串,只有进行重新赋值才可以。 2.译码 将编码后的内容,再进行译码复原,用 decode( ) 函数,参数和上面的译码一摸一样,这里就不重复讲了 strname.decode(encoding="GBK"[,errors="strict"])Tip:当用GBK或者gb2312来对汉字进行译码的时候,每个汉字为2 ~ 4字节,为什么是一个范围呢?中国汉字有成万个,显然两个字节是不够表示的,比较常用的字都是两个字节,但是有些刁钻,少见的字却是3 ~ 4字节的,而UTF-8则是3个字节来表示一个汉字。 举个例子: str1="我真的很牛逼" //定义一个字符串 str1=str1.encode("GBK") //将该字符串进行编码,因为光调用编码函数并不会改变原值 print(str1) // 输出 b'\xce\xd2\xd5\xe6\xb5\xc4\xba\xdc\xc5\xa3\xb1\xc6',前面的b表示这是二进制的,因为一个汉字由两个字节表示,所以你可以数数是否有12个字节 print(str1.decode("GBk")) //将str1来进行译码输出,但是记住你用什么码编的,就得用什么码来译,否则出错那么最后输出结果肯定明确了,输出: 我真的很牛逼 这就是编码和译码的神奇之处 字符串基操(基本操作)1.拼接字符串 就是将多个字符串合并为一个,非常简单,和Java中的一摸一样,用 + 来合并 str1="我真的" str2="牛逼" str3=str1+str2 //直接用加号来将两个字符串合并 print(str3) //输出我真的牛逼但是需要注意的是,只能字符串与字符串之间相加,如果字符串与其他类型的就不行了,例如 str+int那么肯定不行 2.计算字符串长度 他不是按你换算下来有多少字节来计算的,而是直接几个字符,一个汉字,一个数字字母都是一个字符,还有标点符号,用 len()函数,但是你如果转换成二进制了,那么一个字节就是一个字符,之前已经说了GBK和UTF-8转化规则,就不说了 str1="我真的牛,哈哈" print(len(str1)) //输出结果为7,很容易理解3.截取字符串 这个还是和之前一样,start,end,step三个参数设置即可截取,从start本身开始,到end为止,但是不包括end本身位置的。step设置是否跳跃的截取,默认为1,所以就是不跳。 str[0:3] //截取从索引为0到3的字符,但是不包括3 str[:5] //从头开始截取到索引为5的字符,但是不包括5 str[1:] //截取从索引为1开始到字符串结尾的字符4.分割,合并字符串 什么是分割,合并,就是将字符串分割为列表,分割的含义不就是从中间切开吗?合并就是将列表中的元素合并成一个字符串,这里实现了字符串和列表之间的转换。 1> 分割 将字符串分割为列表,用split()函数,当然不能瞎胡分割对吧,根据字符串中的哪个字符或者字符串进行分割 str.split(sep,maxsplit) //第一个参数为需要以什么为依据分割字符串,第二个参数为要分割几次为止,很容易理解 例如: str1="wo ai ni" str1.split(" ") //以空格为分割依据进行分割 //会自动输出['wo', 'ai', 'ni'] ,显然分割出来的是一个列表了已经 str1.split("ai") //以ai为分割 //会自动输出['wo ', ' ni'] ,同理将该字符串分割开了2>合并 合并就是将列表中的元素合并成一个字符串,但是要确保列表中的元素必须都是字符串类型,如果其中含有int类型,那么合并就会失败报错,用内置函数join(),但是和之前的不一样 strname="需要当做分隔的符号".join(要合并的列表) //记住分割和分隔的含义不一样 假定现在有一个列表: list1=["wo","ai","ni"] str1=" ".join(list) //以空格符号作为合并后的分隔符 print(str1) //输出结果 wo ai ni str1="".join(list) //也可以中间不设置分隔符 print(str1) //输出结果woaini很简单,用一个字符,或者字符串作为分隔符,然后使用该内置函数join合并队列即可 5.检索字符串 含义十分简单,就是要查找字符串中的信息 1>看字符串中有几个字符或字符串,几次重复 str.count(sub) str.count('a') //看字符串中字符‘a’中有几个,出现了几次2>看字符串中首次出现某个字符或字符串的索引 str.find(sub) str.find("a") //字符串中首次出现字符‘a’的索引,如果不存在则返回-16.字母大小写转换 将字符串换为小写 str.lower() //直接调用即可,并不会覆盖原值将字符串换为大写 str.upper() //直接调用即可,并不会覆盖7.去除字符串中指定的字符或者空格 str.strip([chars]) //直接去除指定的字符,这里相当是一个字符串数组,去除数组里面的所有内容以上就是序列结构的基本知识 |

 当然索引只是一个抽象的存在,可正可负,当你按索引查找时候,输入负数它会自动按照第二种情况来反馈元素值,输入正数或0会自动按照第一种来反馈元素值.
当然索引只是一个抽象的存在,可正可负,当你按索引查找时候,输入负数它会自动按照第二种情况来反馈元素值,输入正数或0会自动按照第一种来反馈元素值.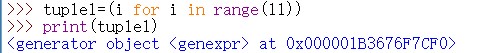 输出为生成器对象,根据索引输出具体的某个元素也不行
输出为生成器对象,根据索引输出具体的某个元素也不行 因为该元组是生成器对象,那么这么输出该元组呢,最简单办法,将该生成器对象用 tuple()函数转化为元组,即可输出元组了:
因为该元组是生成器对象,那么这么输出该元组呢,最简单办法,将该生成器对象用 tuple()函数转化为元组,即可输出元组了: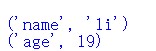 生成好几对键值对,每个键值对都是元组数据类型。
生成好几对键值对,每个键值对都是元组数据类型。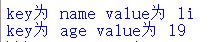
【本文地址】