新手程序员进阶必学,Python常用模块及用法汇总,干货建议收藏 |
您所在的位置:网站首页 › python常用库和模块 › 新手程序员进阶必学,Python常用模块及用法汇总,干货建议收藏 |
新手程序员进阶必学,Python常用模块及用法汇总,干货建议收藏
|
前言
1、Os模块;OS模块 提供方便的使用操作系统函数的方法 OS部分常用方法: (文末送读者福利) os.remove() 删除文件 os.unlink() 删除文件 os.rename() 重命名文件 os.listdir() 列出指定目录下所有文件 os.getcwd() 获取当前文件路径 os.mkdir() 新建目录 os.rmdir() 删除空目录(删除非空目录, 使用shutil.rmtree()) os.makedirs() 创建多级目录 os.system() 执行操作系统命令 os.execvp() 启动一个新进程 os.execvp() 执行外部程序脚本(Uinx)2、Sys模块;SYS 模块 提供可供访问由解释器使用或维护的变量和与解释器进行交互的函数。 简单来说os负责程序与操作系统的交互,提供程序访问操作系统底层的接口;sys主要负责程序与python解析器的交换,提供一系列函数与变量,用于操控pyhton的运行环境。(文末送读者福利) Sys常用方法: sys.argv 命令行参数List,第一个元素是程序本身路径 sys.modules.keys() 返回所有已经导入的模块列表 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.platform 返回操作系统平台名称 sys.stdout 标准输出 sys.stdout.writelines() 无换行输出 sys.stdin 标准输入 sys.stdin.read() 输入一行 sys.stderr 错误输出 sys.executable Python解释程序路径 sys.getwindowsversion() 获取Windows的版本3、Xpath模块 XPath 是一门在 XML 文档中查找信息的语言,它包含一个标准函数库。简而言之,xpath是在xml文档中,根据路径查找元素的语法。 xpath常用术语: 元素:文档树中的标签就是一个元素。 节点:表示xml文档树的某一个位置,例如 / 代表根节点,代表文档树起始位置,元素也可以看成某一位置上的节点。 属性:Harry Potter中 lang就是某一个节点的属性。 文本:Harry Potter中Harry Potter就是文本。4、re模块;正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本,简而言之,正则就是使用特殊字符来匹配特定文本达到提取数据的目的。 Re正则表达式常用语法: '^' 匹配字符串开头 ‘$’ 匹配结尾 '\d' 匹配数字,等于[0-9] re.findall('\d','电话:10086')结果['1', '0', '0', '8', '6'] '\D' 匹配非数字,等于[^0-9] re.findall('\D','电话:10086')结果['电', '话', ':'] '\w' 匹配字母和数字,等于[A-Za-z0-9] re.findall('\w','alex123,./;;;')结果['a', 'l', 'e', 'x', '1', '2', '3'] '\s' 匹配空白字符 re.findall('\s','3*ds \t\n')结果[' ', '\t', '\n'] '\S' 匹配非空白字符 re.findall('\s','3*ds \t\n')结果['3', '*', 'd', 's'] '\A' 匹配字符串开头 '\Z' 匹配字符串结尾 '\b' 匹配单词的词首和词尾,单词被定义为一个字母数字序列,因此词尾是用空白符或非字母数字符来表示的 '\B' 与\b相反,只在当前位置不在单词边界时匹配5、Parsel模块;parsel模块众所周知是一个python的第三方库,其作用和功能等价于css选择器,xpath和re的集合版。和其他解析模块相比,例如BeautifulSoup,xpath等,parsel效率更高,使用更简单。 import requests import parsel response = requests.get(url) sel = parsel.Selector(response.text) #注意这里的S要大写 # re正则 # print(sel.re('正则匹配格式')) # xpath # print(sel.xpath('xpath').getall()) #getall获取所有 # css选择器 # print(sel.css('css选择器 ::text').extract_first())#获取第一个6、Urlparse模块;urlparse模块主要是用于解析url中的参数,对url按照一定格式进行拆分或拼接。urlparse 这个模块在 python 3.0 中 已经改名为 urllib.parse。 Urlparse这个第三方模块中包含的函数有urljoin、urlsplit、urlunsplit、urlparse等。 如,urlparse.urlparse: 将URL分解为6个片段,返回一个元组,包括协议、基地址、相对地址等等 import urlparse url = urlparse.urlparse('http://blog.csdn.net/?ref=toolbar') print url输出结果为: ParseResult(scheme='http', netloc='blog.csdn.net', path='/', params='', query='ref=toolbar', fragment='')scheme是协议,netloc是服务器地址,path是相对路径,params是参数,query是查询的条件。 如果知道服务器的地址的话,可以以服务器的地址为基地址,拼接其他的相对路径,组成新的URL。 7、Soket模块 socket也称作‘套接字,用于描述IP地址和端口,是一个通信的终点。 socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,对于文件用【打开】【读写】【关闭】模式来操作。socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭) socket和file的区别: file模块是针对某个指定文件进行【打开】【读写】【关闭】 socket模块是针对 服务器端 和 客户端Socket 进行【打开】【读写】【关闭】 该模块在较低级别thread模块之上构建更高级别的线程接口。另请参见mutex和Queue模块。 hreading提供了一个比thread模块更高层的API来提供线程的并发性。这些线程并发运行并共享内存。 下面来看threading模块的具体用法: 一、Thread的使用,目标函数可以实例化一个Thread对象,每个Thread对象代表着一个线程,可以通过start()方法,开始运行。 这里对使用多线程并发,和不适用多线程并发做了一个比较: 首先是不使用多线程的操作: 代码如下: #!/usr/bin/python #compare for multi threads import time def worker(): print "worker" time.sleep(1) return if __name__ == "__main__": for i in xrange(5): worker()下面是使用多线程并发的操作: 代码如下: #!/usr/bin/python import threading import time def worker(): print "worker" time.sleep(1) return for i in xrange(5): t = threading.Thread(target=worker) t.start()可以明显看出使用了多线程并发的操作,花费时间要短的很多。 9、Types模块: types是什么: types模块中包含python中各种常见的数据类型,如IntType(整型),FloatType(浮点型)等等。 types常见用法: # 100是整型吗? >>> isinstance(100, types.IntType) True >>>type(100) int # 看下types的源码就会发现types.IntType就是int >>> types.IntType is int True但有些类型并不是int这样简单的数据类型: class Foo: def run(self): return None def bark(self): print('barking') a = Foo() print(type(1)) print(type(Foo)) print(type(Foo.run)) print(type(Foo().run)) print(type(bark))输出结果: 10、selenium模块 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 from selenium import webdriver browser=webdriver.Chrome() browser=webdriver.Firefox() browser=webdriver.PhantomJS() browser=webdriver.Safari() browser=webdriver.Edge() from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys #键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() try: browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw') input_tag.send_keys('美女') #python2中输入中文错误,字符串前加个u input_tag.send_keys(Keys.ENTER) #输入回车 wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) #等到id为content_left的元素加载完毕,最多等10秒 print(browser.page_source) print(browser.current_url) print(browser.get_cookies()) finally: browser.close()11、Pygame模块;是一个简单的游戏开发功能库 在python中开发游戏,通常会用到pygame这个模块。 pygame模块总览: NumPy(Numerical Python) 是 Python 的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。Nupmy可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。据说NumPy将Python相当于变成一种免费的更强大的MatLab系统。 NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含: 一个强大的 N 维数组对象 ndarray 广播功能函数 整合 C/C++/Fortran 代码的工具 线性代数、傅里叶变换、随机数生成等功能 NumPy 最重要的一个对象是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,可以使用基于 0 的索引访问集合中的项目。 ndarray 对象是用于存放同类型元素的多维数组。ndarray中的每个元素在内存中使用相同大小的块。 ndarray中的每个元素是数据类型对象的对象(称为 dtype) numpy.array( object , dtype = None , ndmin = 0 ,copy = True , order = None , subok = False )一般只有 object、dtype和 ndmin 参数常用,其他参数不常用
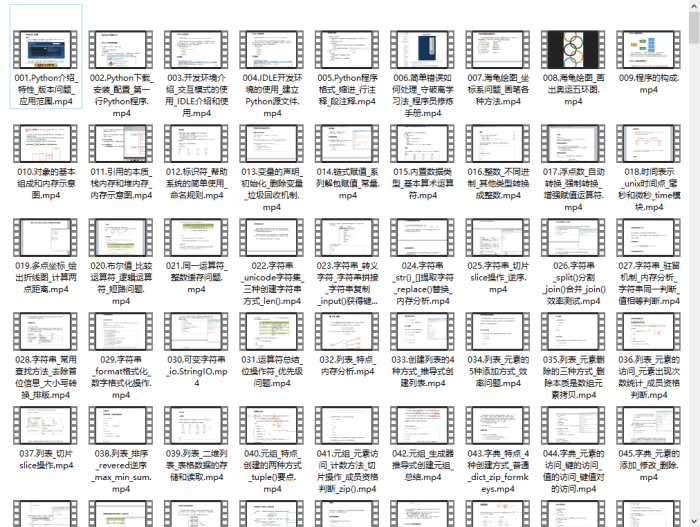
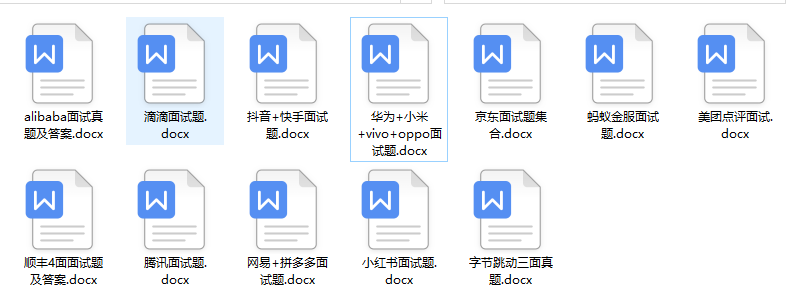
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。 常见的数据类型: 一维: Series(一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。) 二维: DataFrame(二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。) 三维: Panel (三维的数组,可以理解为DataFrame的容器。) … 四维: Panel4D … N维: PanelND … 14、Requests requests是使用Apache2 licensed 许可证的HTTP库。用python编写,比urllib2模块更简洁。 Request支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码。 在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作,是爬虫常用模块! 对应http的不同请求类型,requests库有不同的方法: 1.requests.get(): 获取HTML网页的主要方法,对应于HTTP的GET 2.requests.post(): 向HTML网页提交POST请求的方法,对应于HTTP的POST 3.requests.head(): 获取HTML网页头信息的方法,对应于HTTP的HEAD 4.requests.put(): 向HTML网页提交PUT请求,对应于HTTP的PUT 5.requests.patch(): 向HTML网页提交局部修改请求,对应于HTTP的PATCH 6.requests.delete(): 向HTML页面提交删除请求,对应于HTTP的DELETE15、BeautifulSoup HTML和XML的解析库,BeautifulSoup 是Python的一个库,最主要的功能就是从网页爬取我们需要的数据。BeautifulSoup将 html 解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。 基本用法: from bs4 import BeautifulSoup import requests, re req_obj = requests.get('https://www.baidu.com') soup = BeautifulSoup(req_obj.text, 'lxml') '''标签查找''' print(soup.title) # 只是查找出第一个 print(soup.find('title')) # 效果和上面一样 print(soup.find_all('div')) # 查出所有的div标签 '''获取标签里的属性''' tag = soup.div print(tag['class']) # 多属性的话,会返回一个列表 print(tag['id']) # 查找标签的id属性 print(tag.attrs) # 查找标签所有的属性,返回一个字典(属性名:属性值) '''标签包的字符串''' tag = soup.title print(tag.string) # 获取标签里的字符串 tag.string.replace_with("哈哈") # 字符串不能直接编辑,可以替换 '''子节点的操作''' tag = soup.head print(tag.title) # 获取head标签后再获取它包含的子标签 '''contents 和 .children''' tag = soup.body print(tag.contents) # 将标签的子节点以列表返回 print([child for child in tag.children]) # 输出和上面一样 '''descendants''' tag = soup.body [print(child_tag) for child_tag in tag.descendants] # 获取所有子节点和子子节点 '''strings和.stripped_strings''' tag = soup.body [print(str) for str in tag.strings] # 输出所有所有文本内容 [print(str) for str in tag.stripped_strings] # 输出所有所有文本内容,去除空格或空行 '''.parent和.parents''' tag = soup.title print(tag.parent) # 输出便签的父标签 [print(parent) for parent in tag.parents] # 输出所有的父标签 '''.next_siblings 和 .previous_siblings 查出所有的兄弟节点 ''' '''.next_element 和 .previous_element 下一个兄弟节点 ''' '''find_all的keyword 参数''' soup.find_all(id='link2') # 查找所有包含 id 属性的标签 soup.find_all(href=re.compile("elsie")) # href 参数,Beautiful Soup会搜索每个标签的href属性: soup.find_all(id=True) # 找出所有的有id属性的标签 soup.find_all(href=re.compile("elsie"), id='link1') # 也可以组合查找 soup.find_all(attrs={"属性名": "属性值"}) # 也可以通过字典的方式查找今天的python常用模块汇总就到这里啦,如果觉得这篇文章对你有用的话,点赞评论一下哦!想要获取更多Python知识,小技巧和干货资源,文末领取哦 Python入门教程如果你现在还是不会Python也没关系,下面我会给大家免费分享一份Python全套学习资料, 包含视频、源码、课件,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,可以和我一起来学习交流。 ① Python所有方向的学习路线图,清楚各个方向要学什么东西 ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析 ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论 ④ 20款主流手游迫解 爬虫手游逆行迫解教程包 ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解 ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解 ⑦ 超300本Python电子好书,从入门到高阶应有尽有 ⑧ 华为出品独家Python漫画教程,手机也能学习 ⑨ 历年互联网企业Python面试真题,复习时非常方便
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。 检查学习结果。
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取
了解python的前景:https://blog.csdn.net/weixin_49891576/article/details/127187029 了解python的兼职:https://blog.csdn.net/weixin_49891576/article/details/127125308 |
 8、Threading模块
8、Threading模块 12、numpy
12、numpy 13、pandas
13、pandas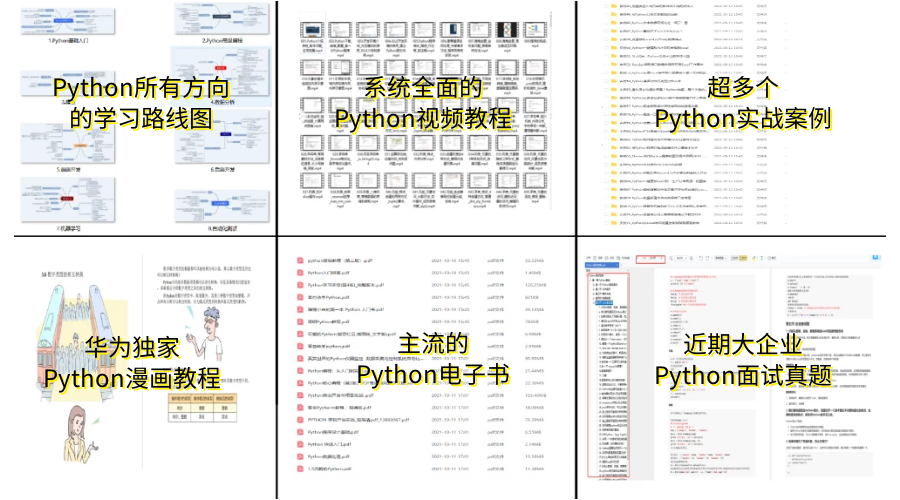




【本文地址】
今日新闻 |
推荐新闻 |