Python读写文本文件和二进制文件的方法及注意事项 |
您所在的位置:网站首页 › python对文件的读操作方法有哪些read › Python读写文本文件和二进制文件的方法及注意事项 |
Python读写文本文件和二进制文件的方法及注意事项
|
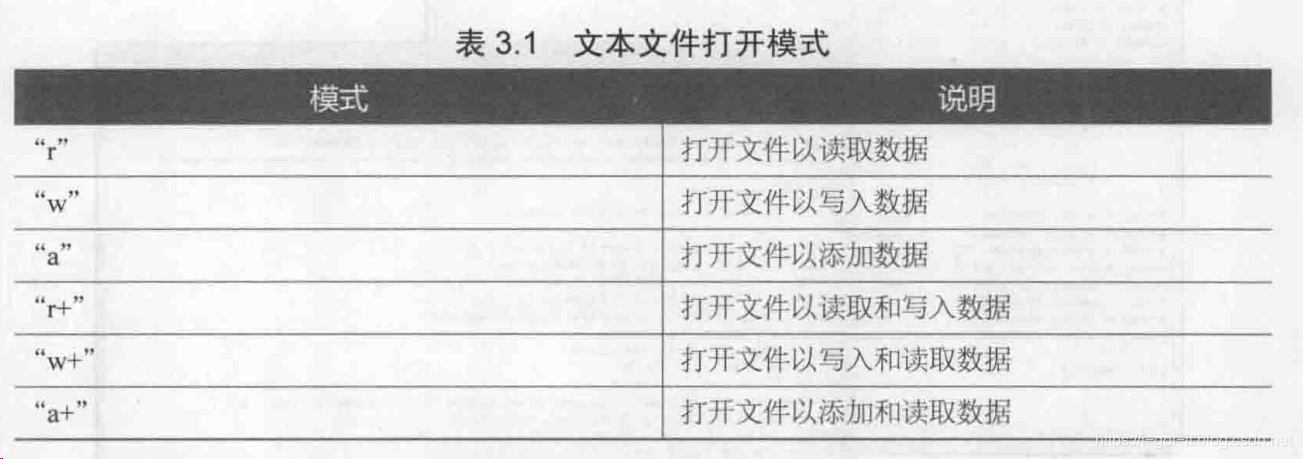
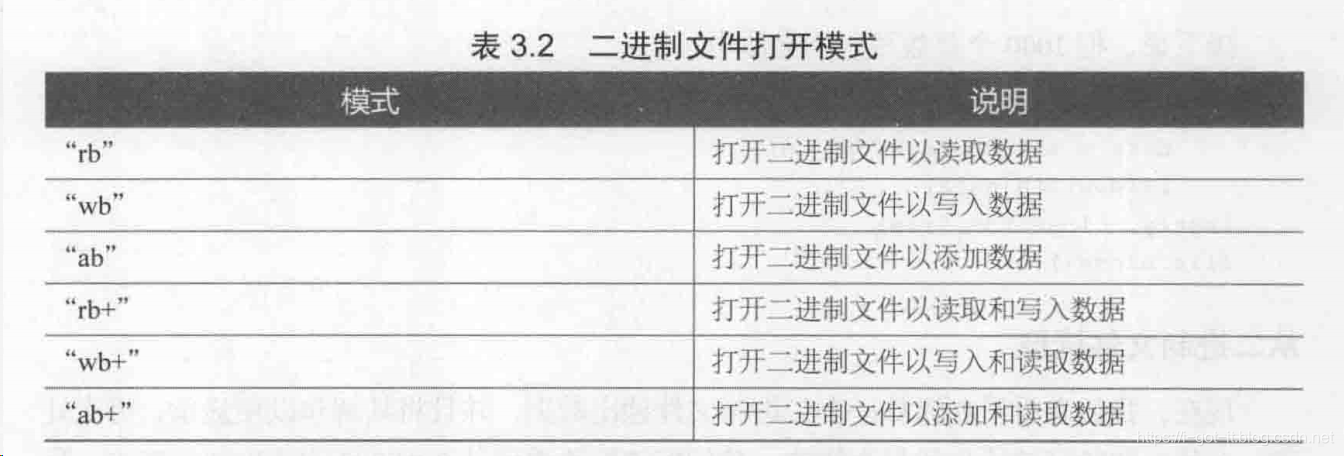
文件有两种,文本文件和二进制文件。读写文本文件比较简单,也在这里简单说一下;读写二进制文件用到了struct库,涉及一些大端小端、字节填充等概念,稍微有点复杂。 文件打开关闭在读写文件之前,需要打开文件,Python不需要导入其他库,直接可以打开关闭文件 file = open('filename.ext', openmod) #打开文件 file.close() #关闭文件操作模式可以分为两种,一种是文本文件模式,另一种为二进制文件模式
文件写入就比较简单了 file.write('string') file.write('string\n') # 换行 file.write('%10s=%10.2f\n' % ('val', 12.3455)) # 格式化字符串write函数只能输出字符串,不能像C语言那样定义输出格式。 如果像这么做,需要先对要输出的内容转换为字符串。可以像上例那样格式化字符串,格式化方法与C中的是一致的,适合学过C语言的同学。 Python也有一个输出多行的函数,同时输出多行 content = ['I have a dream.\n', 'One day, \n', 'former slaves and slave owners will join together,\n', 'as brotherhood.\n'] file.writelines(content)writelines()函数不会为你添加换行符,需要自己添加。 读入文件内容 file.read() # 读取文件所有内容 file.read(n) # 读取前n个字符需要注意的是read(n)。如果文件中有中文,一个中文字表示一个字符,不管其中内部编码是几个字节。读取完之后,光标移动n个字符。 顺便讲一讲如何读取中文。如果要正确读取中文,以下条件要满足 要读的文本文件的编码与打开文件时设置的编码一致。 其实我们在打开文件时,有一个文件编码参数我们没有设置,用的默认的参数,这个参数可以设置。假如我们的文本文件a.txt用的utf-8进行的编码。就可以进行下面设置。 file = open('a.txt', 'r', encoding='utf-8')如果两者没有设置成一致的,在读取时就会出错。 在Windows中, open方法打开的文件好像默认为GBK编码,如果你的文本文件用的utf-8格式,就会错误。 除了上面的读取函数之外,还有一个 line1 = file.readline() str2 = file.readline(n) #读取本行的n个字符注意line1中包含回车符,读取完line1后,读取位置移动到下一行 读取完str2后,读取位置移动n个字符,可能还在本行。 如果n >= 本行的字符数(包含换行符), 最终读取的内容就是本行的字符,读取位置移到下一行; 如果n hif’ 表示数据为大端顺序,h表示一个short类型,也就是2个字节的整数,i表示一个int类型也就是4个字节表示的整数, f表示单精度浮点类型,也是4个字节。 因此这个fmt表示的10个字节的数据。 可以用下面计算fmt代表的字节数 struct.calcsize('>hif')然后是把字节解析为原始数据 struct.unpack('>hif', b1)输出 (65, 123, 3.140000104904175)在fmt的定义中,有3样东西需要注意:字节顺序,数据由几个字节组成,以及字节填充(对齐)。 字节顺序: 是对于多字节的数据,比如一个int类型的数16909060(其十六进制表示为 0x01020304),转换为字节有两种转换方法 大端表示,最高位在前, 0x01, 0x02, 0x03, 0x04 小端表示,最低位在前, 0x04, 0x03, 0x02, 0x01 [hex(i) for i in struct.pack('>i', 16909060)] Out[69]: ['0x1', '0x2', '0x3', '0x4'] [hex(i) for i in struct.pack(' |
【本文地址】
今日新闻 |
推荐新闻 |