Python Spark的介绍与安装 |
您所在的位置:网站首页 › python安装spark › Python Spark的介绍与安装 |
Python Spark的介绍与安装
|
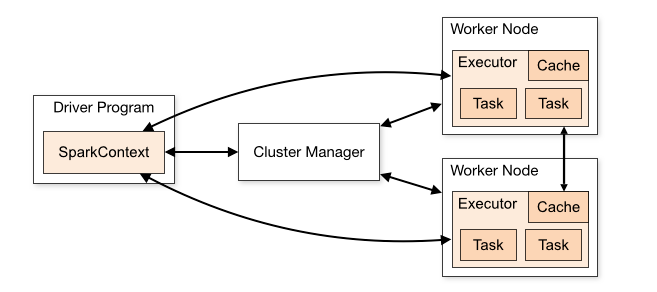
Spark的Cluster模式架构图
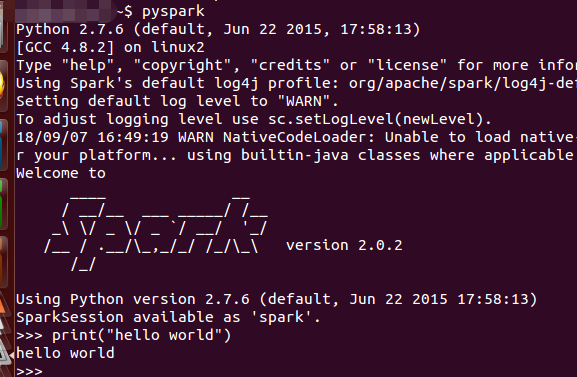
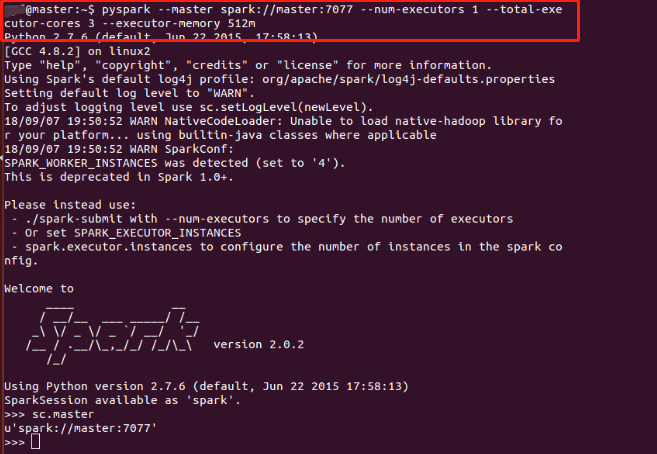
摘自Apache官网: 其中 DriverProgram为设计的Spark程序,在Spark程序中必须定义SparkContext(开发Spark应用程序的入口)。SparkContext通过Cluster Manager管理整个集群,集群中包含多个Worker Node,在每个Worker Node中都有Executor负责执行任务SparkContext通过Cluster Manager 管理整个集群Cluster,使得Spark程序可以在不同的Cluster模式下运行: 本地模式:只需在程序中import Spark的链接库就可以实现。Spark Standalone Cluster:由Spark提供的Cluster管理模式,若没有架设hadoop multi Node Cluster,可单独架设Spark Standalone Cluster,实现多台计算机并行计算。该模式下,仍然可以直接存取Local Disk 或HDFSHadoop YARN:Spark可以在YARN上运行,让YARN帮助它进行多台机器的资源管理。在云端运行 安装ScalaSpark基于Scala开发,安装Spark必须先安装Scala。 终端输入命令 wget https://www.scala-lang.org/files/archive/scala-2.11.6.tgz tar xvf scala-2.11.6.tgz sudo mv scala-2.11.6 /usr/local/scala sudo gedit ~/.bashrc export SCALA_HOME=/usr/local/scala(文本输入) export PATH=$PATH:$SCALA_HOME/bin(文本输入) source ~/.bashrc 安装Spark下载Spark网址,注意Spark与Hadoop版本必须互相配合。 终端输入命令: wget https://archive.apache.org/dist/spark/spark-2.0.2/spark-2.0.2-bin-hadoop2.6.tgz tar zvxf spark-2.0.2-bin-hadoop2.6.tgz sudo mv spark-2.0.2-bin-hadoop2.6 /usr/local/spark/ sudo gedit ~/.bashrc export SPARK_HOME=/usr/local/spark (文本输入) export PATH=$PATH:$SPARK_HOME/bin(文本输入) source ~/.bashrc 启动pyspark命令行输入pyspark启动pyspark exit()退出 在Hadoop YARN中运行pyspark终端输入命令: HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark --master yarn --deploy-mode client 构建Spark Standalone Cluster运行环境复制模板文件创建spark-env.sh cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh sudo gedit /usr/local/spark/conf/spark-env.sh 文本输入: export SPARK_MASTER_TP=master export SPARK_WORKER_CORES=1 ## 设置每个Worker使用的CPU核心数 export SPARK_WORKER_MEMORY=512m ## 设置每个Worker使用的内存 export SPARK_WORKER_INSTANCES=4 ## 设置实例数将master的spark程序复制到slaves中,以hadoop1为例: ssh hadoop1 sudo mkdir /usr/local/spark sudo chwon 更改的目录所有者:更改的目录所有者 /usr/local/spark exit 使用scp将master的spark程序复制到hadoop1 sudo scp -r /usr/local/spark/ hadoop1的用户名@hadoop1: /usr/local 编辑slaves文件,设置Spark Standalone Cluster 的服务器 sudo gedit /usr/local/spark/conf/slaves 文本输入,例如3个slaves hadoop1 hadoop2 hadoop3 在Spark Standalone运行pyspark启动Spark Standalone Cluster /usr/local/spark/sbin/start-all.sh 或者分别启动master与slaves /usr/local/spark/sbin/start-master.sh /usr/local/spark/sbin/start-slaves.sh 在Spark Standalone 中运行pyspark pyspark --master spark://master:7077 --num-executors 1 --total-executor-cores 3 --executor-memory 512m 停止Spark Standalone Cluster /usr/local/spark/sbin/stop-all.sh Spark Web UI 界面启动Spark Standalone Web UI 界面,http://master:8080/ |
【本文地址】
今日新闻 |
推荐新闻 |