单向链表Python |
您所在的位置:网站首页 › python单链表实现 › 单向链表Python |
单向链表Python
|
单向链表
文章目录
单向链表链表结构用python实现单向链表单项链表所具有的操作往链表头部添加一个结点add()返回链表中所有节点的值组成的列表往链表的末尾添加一个结点在指定的位置插入结点删除第一个数据为data的元素修改链表中的某一结点的data查找链表中是否值为data的结点
链表和顺序表的时间复杂度
附件:用python实现链表功能的全部代码附件2:单向链表寻找尾结点
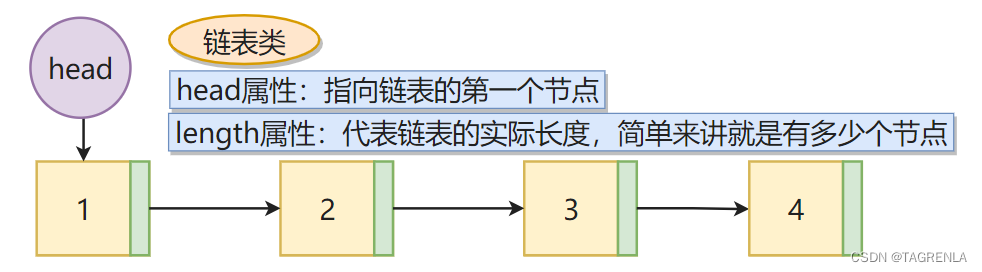
链表结构
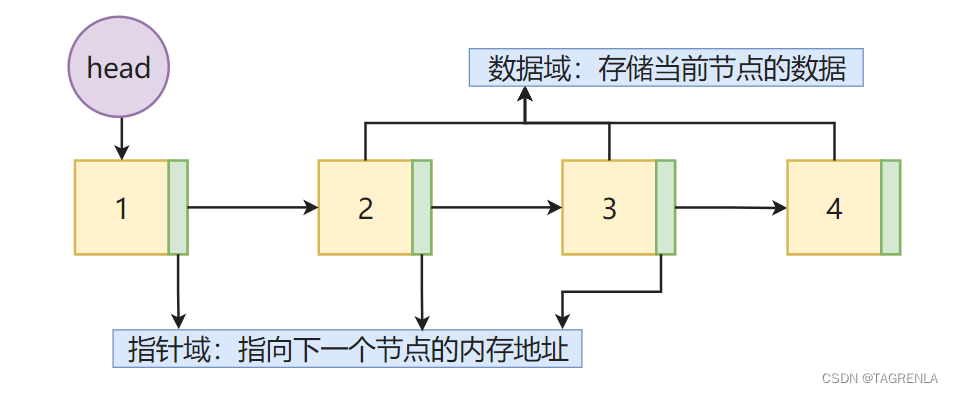
链表是一种物理存储单元上非连续、非顺序的存储结构 数据元素的逻辑顺序通过链表中的指针链接次序实现 链表由一系列结点组成,结点可以在运行时动态生成 每个结点包括两个部分:存储数据元素的数据域、存储下一个节点地址的指针域
用class分别定义结点(Node) 和 链表(linklist) 两个类,添加想要的属性即可!
代码实现如下: class Node: # 结点类 def __init__(self,data,_next = None): self.data = data self._next = _next
实现步骤: 链表为空的时候照样成立 创建一个新的节点将新的节点的next属性指向原来的头部节点,即:self.head将头部节点重新指向创建的新节点链表的长度属性加1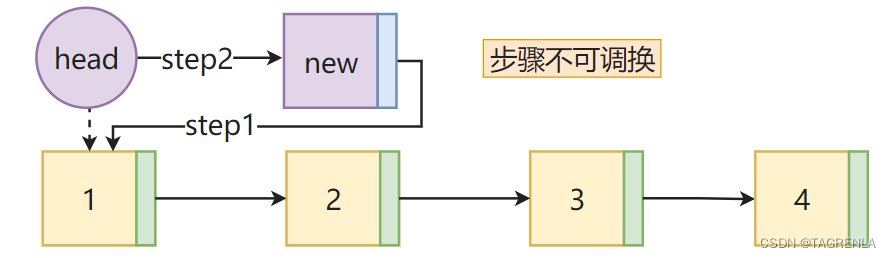
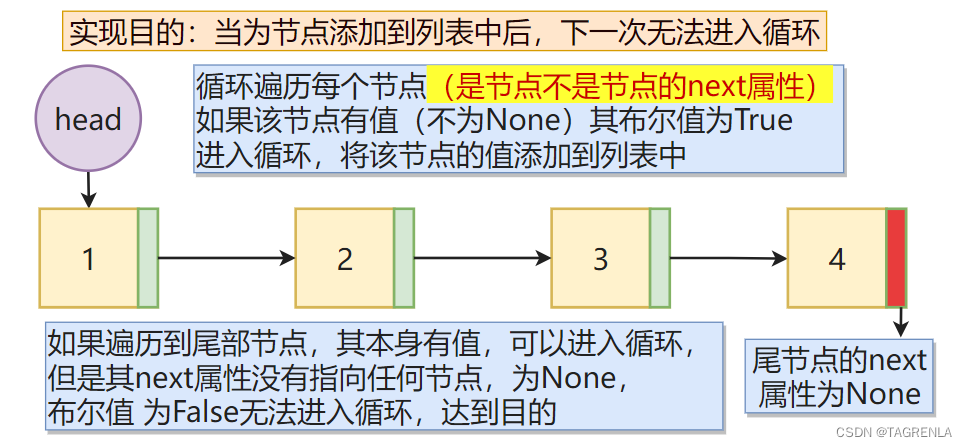
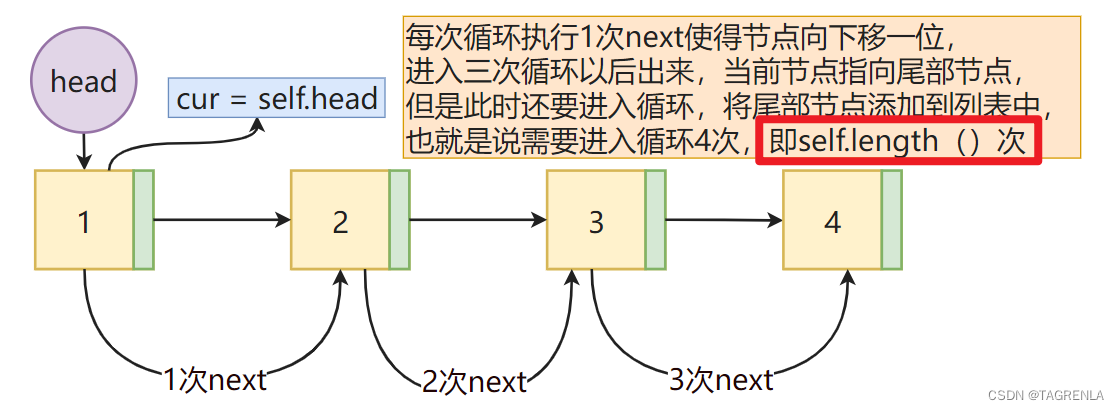
链表为空的情况如下: 代码实现如下: 注意本文def的所有的方法(函数)都需要放到类(class)中才可实现,其是一个类方法 def add(self,data): # 请将我放入类中执行 node = Node(data) node._next = self.head self.head = node # 存储的是一个类对象 而不是对象 类对象中包括对象和下一个类对象的地址 self.lenth += 1 返回链表中所有节点的值组成的列表方法1实现步骤 循环节点法 创建一个新的列表将每个节点的data属性添加到列表中返回列表具体第二步入何进行实现?如何才能遍历每个节点,请看下图: 代码实现如下: def nodes_list(self): res = [] cur = self.head # 第一个结点 while cur: #如果有节点进入循环 res.append(cur.data) #将该节点的数据添加到列表中 cur = cur.next # 并赋值下一节点 如果下一节点为 None 跳出循环返回res return res方法2实现步骤 循环索引法 创建一个列表res循环遍历指定的次数将指定的data值添加到列表中返回res列表具体实现请看下图: 具体的如何精确控制循环的次数? a= 4 # a是多少就循环多少次 while a: print(f'这是第{5-a}次循环') a -= 1这是第1次循环 这是第2次循环 这是第3次循环 这是第4次循环 代码实现如下: def nodes_list(self): res = [] a = self.length() #循环self.length()次 cur = self.head while a: res.append(cur.data) cur = cur.next a -= 1 return res 往链表的末尾添加一个结点实现方法1步骤 循环找到尾节点将尾节点的next属性指向新的节点链表的长度加1 通过next属性是否为None来指向尾部节点详见博主原创文章 ==双向链表python实现==(附件1:双向链表寻找尾结点(同单向))内容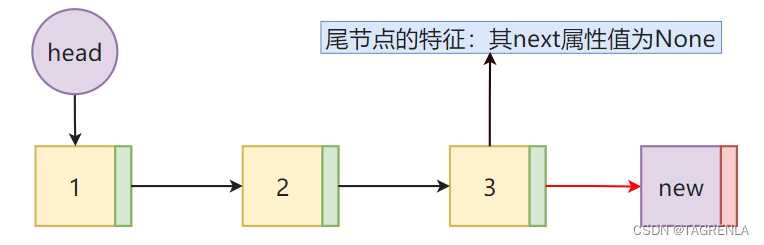 
代码实现如下: def append(self, data): node = Node(data) cur = self.head if cur: # 如果head属性有节点,就证明不是空链表 while cur.next: # 当cur为尾节点的时候 跳出循环 cur = cur.next cur.next = node else: self.head = node self._length += 1实现方法2(通过索引找到指定的节点) 通过索引找到指定的节点的方法详见博主原创文章 ==双向链表python实现==(附件2:通过索引寻找指定的结点)内容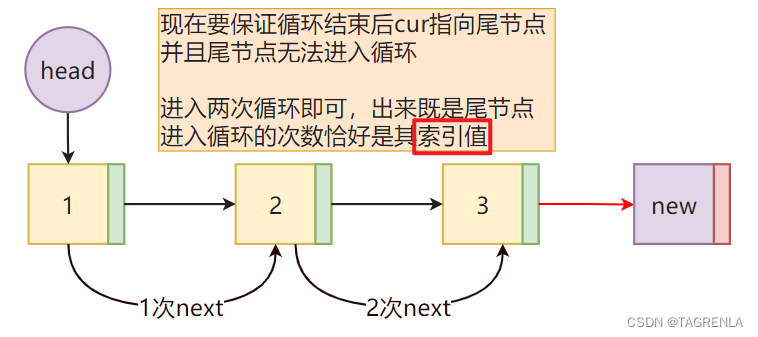 def append_node(self,data):
node = Node(data)
if self.is_empty():
self.head = node # 空链表的执行条件
cur = self.head # 非空链表的执行条件
a = self._length - 1
while a:
cur = cur.next
a -= 1
cur.next = node
self._length += 1
在指定的位置插入结点
def append_node(self,data):
node = Node(data)
if self.is_empty():
self.head = node # 空链表的执行条件
cur = self.head # 非空链表的执行条件
a = self._length - 1
while a:
cur = cur.next
a -= 1
cur.next = node
self._length += 1
在指定的位置插入结点
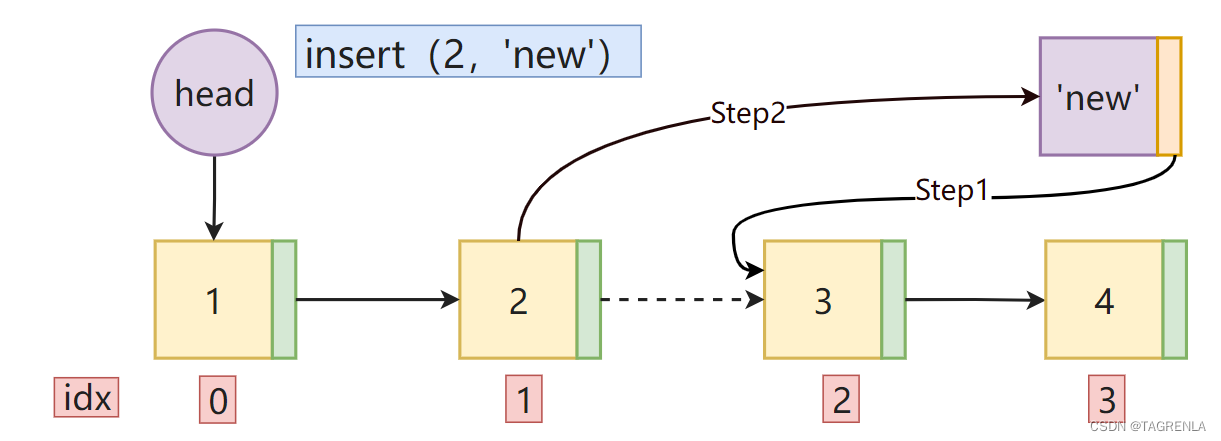
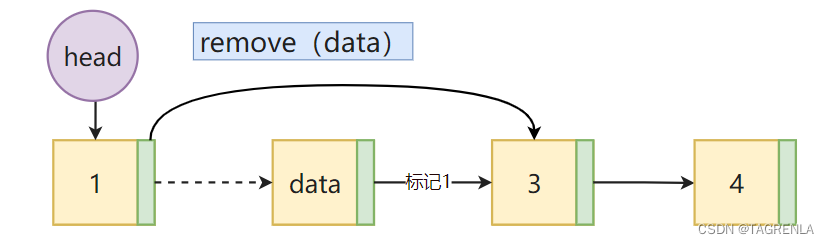
示意图如下: 思考这么一个问题: 就拿上面盖的这个图来说,给索引为2的地方插入一个值,重要的是找索引为1的节点还是索引为2的节点? 显然索引为1的节点才是重要的!!! 首先Step1是将新的节点的next属性指向原来索引为2的节点,也就是索引为1的节点的next属性(就是索引为2的节点)Step2是将索引为1的next属性指向新的节点,如果得到索引为2的节点无法直接完成操作(需要定义一个前驱节点)实现具体步骤 代码实现如下: 创建新的节点node找到索引为pos-1的节点(前面好像说了如何通过索引找到指定的节点呦)将pos-1结点 next属性(原来pos位置上的结点)赋值给新的结点的next属性将新的结点赋值给 pos-1结点的next属性链表长度加1 def insert(self,pos,data): # pos代表插入节点的位置,也就是 第pos+1 个结点 pos是索引 ''' 非正常情况下 如果小于0 默认添加到头部 如果超出范围 默认添加到尾部 ''' if pos self.lenth: # 在此处pos > self.lenth-1也行 只不过 当添加末尾元素的时候 会调用 append()方法 self.append(data) else: node = Node(data) cur = self.head pos -= 1 while pos: # 这里应用的很巧妙 因为没有像传统的循环那样创建一个计数器 直接用现有的pos cur = cur.next pos -= 1 node.next = cur.next cur.next = node self.lenth += 1 删除第一个数据为data的元素
在这里再提供另一种代码的实现方法 但是下面的代码的可变形性不太好,自行使用哈 def remove_(self,data): cur = self.head if cur.data == data: self.head = self.head.next self._length -= 1 return 0 prev = None while cur: if cur.data == data: prev.next = cur.next self._length -=1 return 0 else: prev = cur cur = cur.next return -1 修改链表中的某一结点的data 正常情况: 只用self.head一次 然后 进行pos次循环next 就可以找到相对应的结点 将节点的data属性进行修改即可非正常情况下 输入的 值超出范围的时候代码实现如下(这部分又涉及到了 通过索引找到指定的节点=附件2) def modify(self,pos,data): ''' 修改链表中指定位置的值 ''' if 0 |

 代码实现如下:
代码实现如下: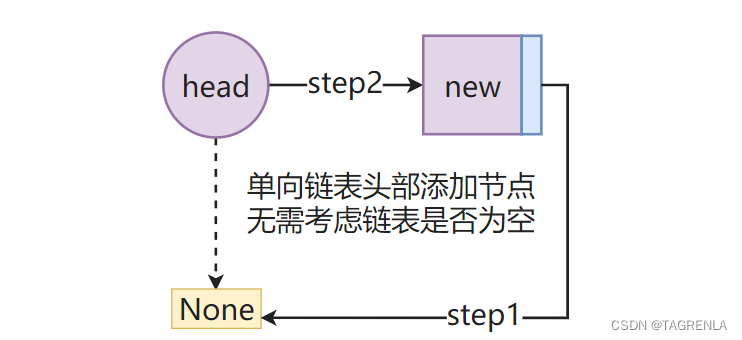
 具体步骤
具体步骤【本文地址】
今日新闻 |
推荐新闻 |