Python中怎么抓取并存储网页数据 |
您所在的位置:网站首页 › python保存网页内容 › Python中怎么抓取并存储网页数据 |
Python中怎么抓取并存储网页数据
|
Python中怎么抓取并存储网页数据
发布时间:2021-07-05 17:57:55
来源:亿速云
阅读:83
作者:Leah
栏目:编程语言
本篇文章为大家展示了Python中怎么抓取并存储网页数据,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。 第一步:尝试请求 首先进入b站首页,点击排行榜并复制链接 https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3现在启动Jupyter notebook,并运行以下代码 import requests url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' res = requests.get('url') print(res.status_code) #200在上面的代码中,我们完成了下面三件事 导入requests 使用get方法构造请求 使用status_code获取网页状态码 可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。 第二步:解析页面 在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容
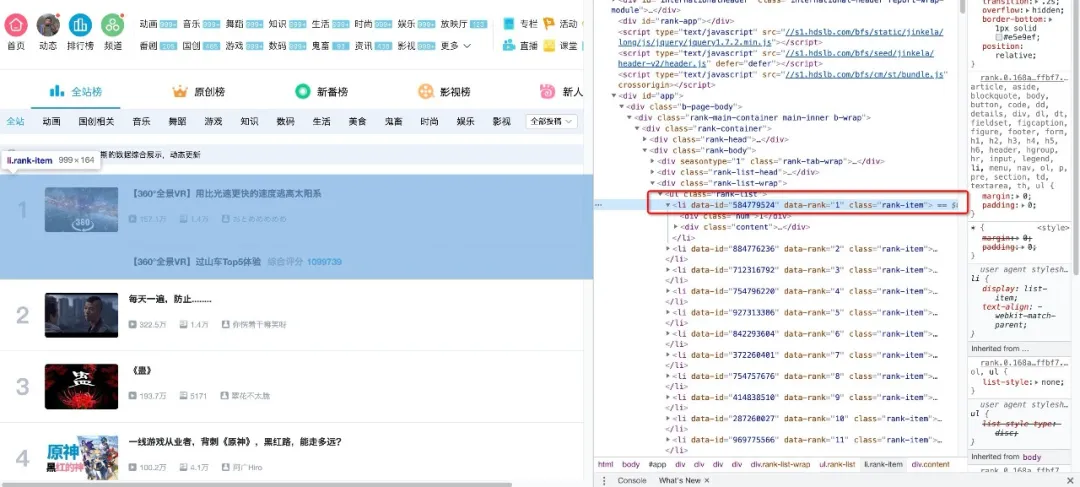
可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。 在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解. Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的 from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。 接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。 第三步:提取内容 在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。 在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。 现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写 all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url })在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。 可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。 第四步:存储数据 通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。 如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题 import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成 import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
上述内容就是Python中怎么抓取并存储网页数据,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。 推荐内容:使用aardio抓取网页数据 免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:[email protected]进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。 python 上一篇新闻:zookeeper是什么意思 下一篇新闻:Python中怎么实现模块重载 猜你喜欢 Python中assert函数怎么用 vue前端UI框架有什么 vue.js如何引入到HTML中 vue.js中的4个级别作用域分别是什么 yii手动生成错误日志的方法 将一个外部项目导入Thinkphp环境中的方法 如何提高laravel应用速度 laravel中路由命名及路由分组的示例分析 laravel中路由参数全局约束、路由重定向及路由视图绑定的示例分析 swoole的示例分析 |

【本文地址】
今日新闻 |
推荐新闻 |