【Python】关于内存问题的简单测试 |
您所在的位置:网站首页 › python中内存管理 › 【Python】关于内存问题的简单测试 |
【Python】关于内存问题的简单测试
|
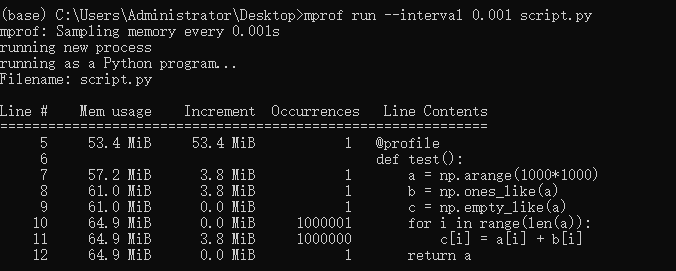
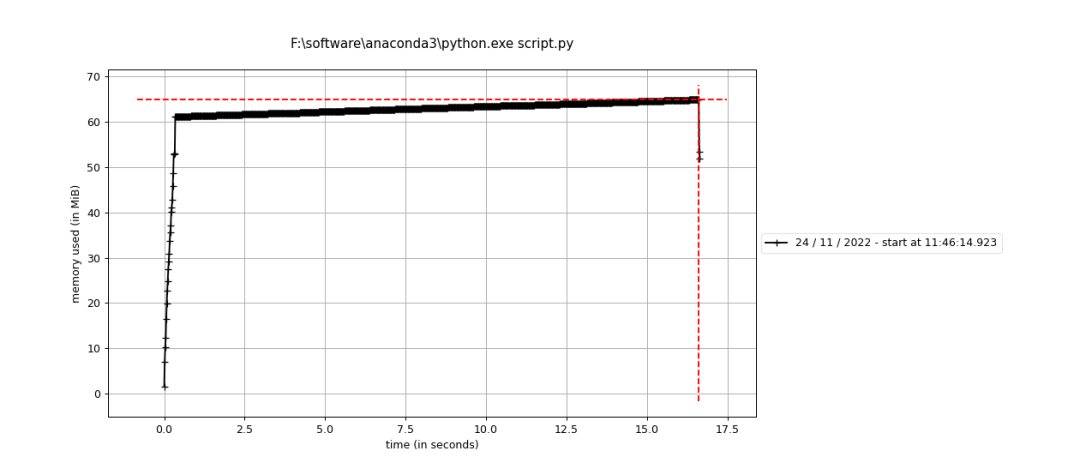
想研究一个东西:如果在使用python计算矩阵运算的时候(比如A和B两个矩阵),我将A和B计算的结果存在B矩阵中,是不是就不需要分配新的内存。这个问题对大佬们来说可能很简单,但困扰了我很久。因为常常会出现unable xxx GiB的报错。 结论先说一下我理解的结论,如有不妥,还请大佬们不吝赐教。 将矩阵A和B运算的结果放在B里面,运算结束后确实不需要分配新的内存(如果数据精度、数组大小都一致的话)。但在运算的过程中,应该是需要给AB运算的结果暂时分配一个新的内存来存放,运算完成后将结果再放回B所占的内存空间中,计算过程中用到的暂时内存随即释放。 如果是向量化的实现,那么计算过程中用到的暂时内存会和等价于一个数组B的内存大小,这样就比较容易出现unable xxxGiB的报错。 但如果是循环计算的话,比如一个格点一个格点计算的话,那暂时内存会很小,也就是一个数据的大小罢了,这样不容易出现unable xxxGiB的报错。但速度比向量化操作慢很多。 三组测试 第一组将a,b两个数组相加的结果存放在新的数组c中,并通过循环每个点实现。 • code import numpy as np from memory_profiler import profile @profile def test(): a = np.arange(1000*1000) b = np.ones_like(a) c = np.empty_like(a) for i in range(len(a)): c[i] = a[i] + b[i] return a if __name__ == "__main__": test()• result
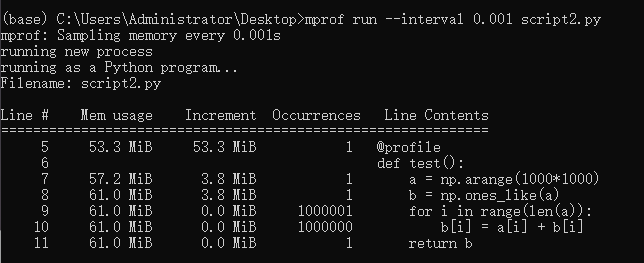
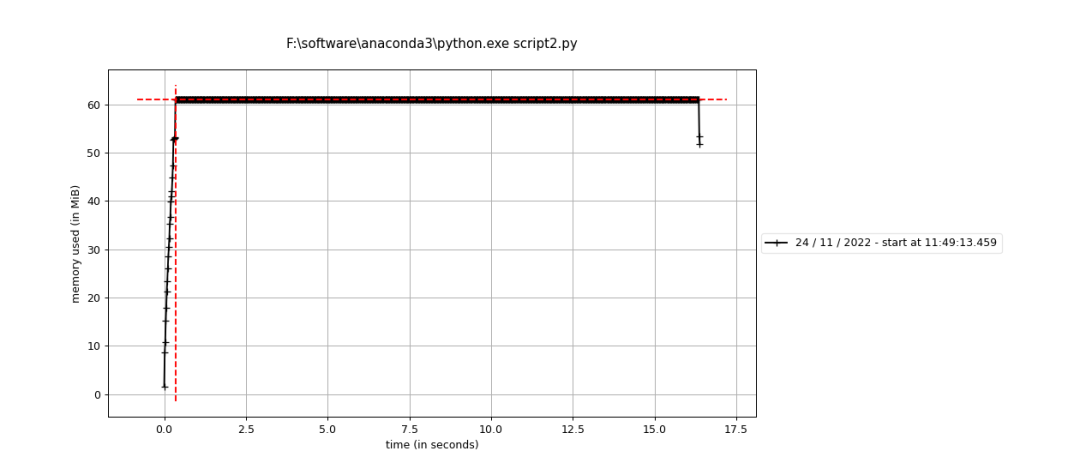
将a,b两个数组相加的结果存放在原有数据b中,并通过循环每个点实现。 • code import numpy as np from memory_profiler import profile @profile def test(): a = np.arange(1000*1000) b = np.ones_like(a) for i in range(len(a)): b[i] = a[i] + b[i] return b if __name__ == "__main__": test()• result
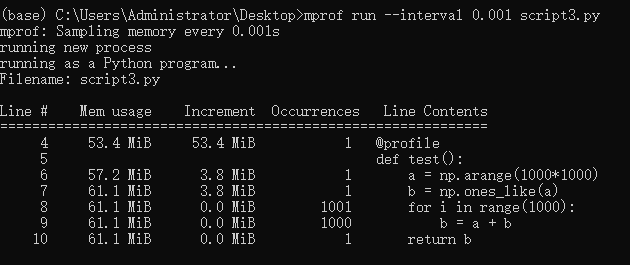
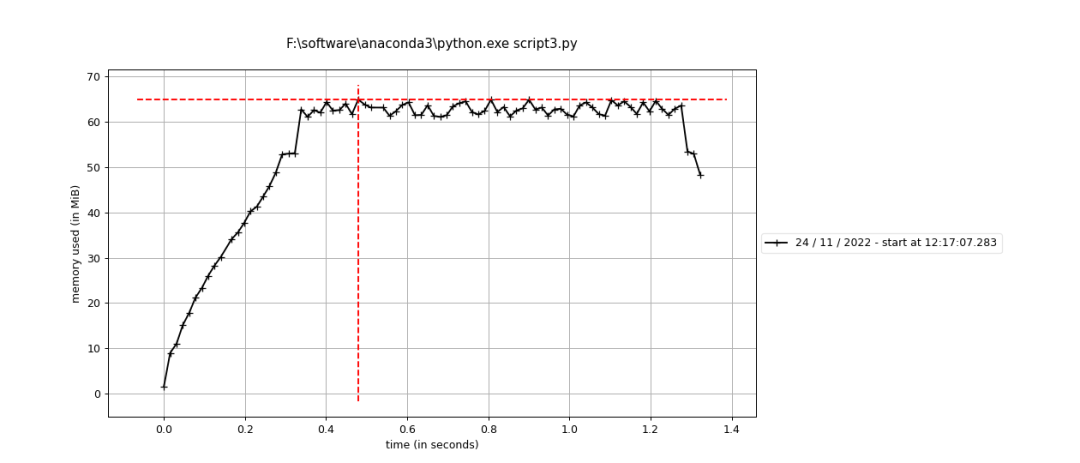
将a,b两个数组相加的结果存放在新的数组c中,并通过向量化实现。这里为了能让interval多记录一些计算过程内存的变化,把同样的计算出重复了1000次。 • code import numpy as np from memory_profiler import profile @profile def test(): a = np.arange(1000*1000) b = np.ones_like(a) for i in range(1000): b = a + b return b if __name__ == "__main__": test()• result
第一、二两组对比可以发现,将矩阵A和B运算的结果放在B里面,运算结束后确实不需要分配新的内存(如果数据精度、数组大小都一致的话)。 且从第二组实验的折线图可以看出,单个点循环的话,中间内存很小,甚至可以忽略不计,因为线很平,没有什么起伏。 第二、三两组对比可以发现,无论是向量化计算还是循环计算,只要最后结果都放在了原有数组B中,整体来说是不需要分配新的内存的。 但比较二、三组的折线图可以看出,第三组向量化计算的过程中由很多起伏,我理解的是向量化每计算一次中间都需要分配一个同B数组等大小的暂时内存用来存放结果(表现为折线上升到最高点),待一次循环中的计算完成后再释放(表现为折线下降到起点)。 参考: https://www.cnblogs.com/kaituorensheng/p/5669861.html
—END—
|


【本文地址】
今日新闻 |
推荐新闻 |