基于Python+百度语音的智能语音ChatGPT聊天机器人(机器学习+深度学习+语义识别)含全部工程源码 适合个人二次开发 |
您所在的位置:网站首页 › pycharm百度云资源 › 基于Python+百度语音的智能语音ChatGPT聊天机器人(机器学习+深度学习+语义识别)含全部工程源码 适合个人二次开发 |
基于Python+百度语音的智能语音ChatGPT聊天机器人(机器学习+深度学习+语义识别)含全部工程源码 适合个人二次开发
|
目录
前言总体设计系统整体结构图系统流程图
运行环境Python 环境Pycharm 环境ChatterBot 环境
模块实现1. 模型构建2. 服务器端3. 客户端4. 语音录入5. 接口调用6.模型训练及保存
系统测试1. 模型效果2. 模型应用
源代码下载地址其它资料下载
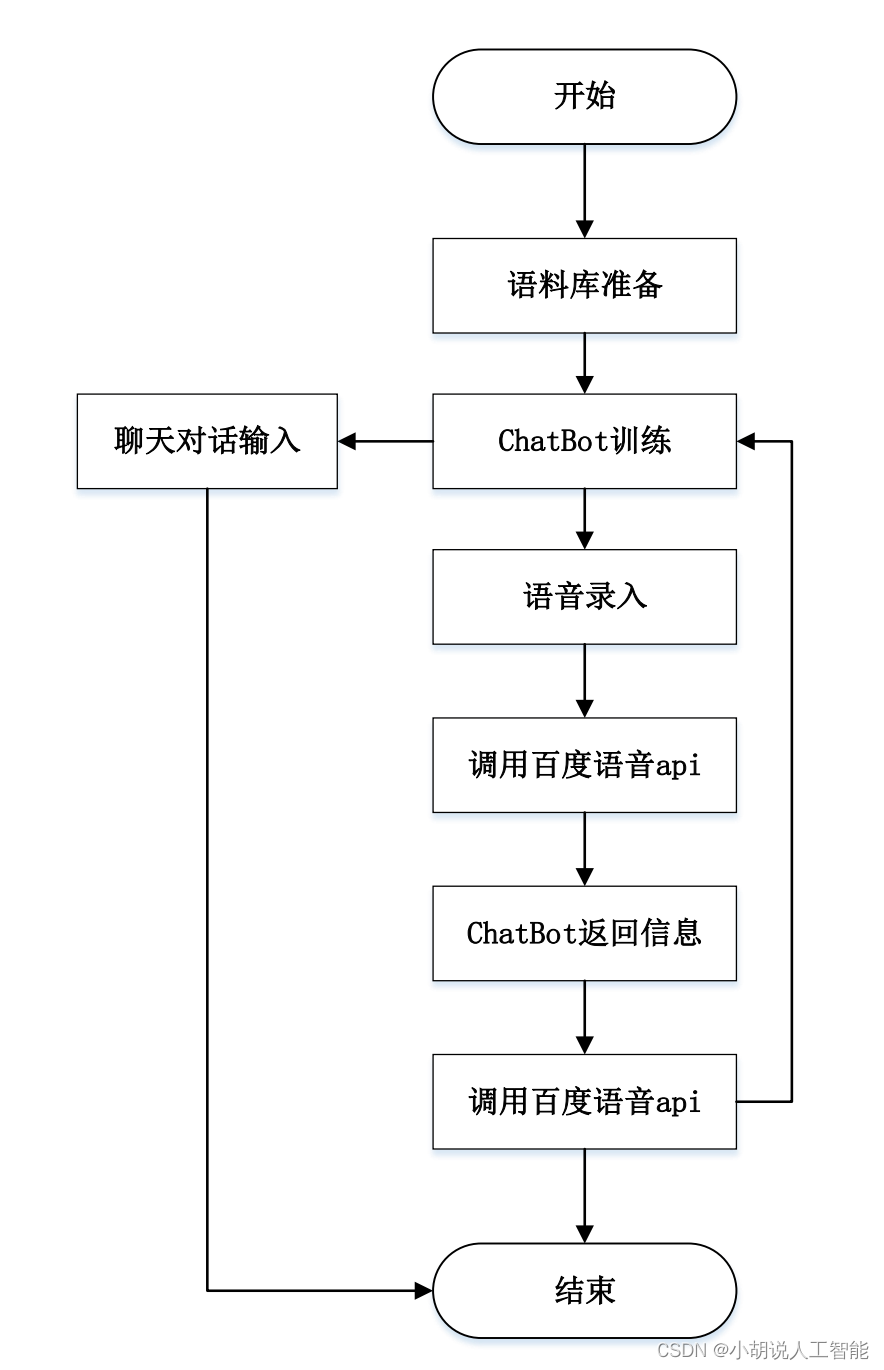
本项目基于机器学习和语义识别技术,让机器人理解文本并进行合适的答复。伙伴们可以通过该工程源码,进行个人二次开发,比如使用语音与机器人交流,实现智能问答、智能音箱及智能机器宠物等等。 当然针对现在最火爆的ChatGPT等通用大语言模型,伙伴们可以直接将其应用在模块实现第6部分,其它详细的接口使用操作,大家可以关注我博客的其它关于ChatGPT接口使用的说明。 总体设计本部分包括系统整体结构图和系统流程图。 系统整体结构图系统整体结构如图所示。
系统流程如图所示。
本部分包括 Python 环境、Pycharm 环境和 ChatterBot 环境。 Python 环境需要 Python 3.6 及以上配置,进入 python 官方网站:www.python.org,选择自己所需版本号,单击 DownLoad,添加环境变量。 Pycharm 环境PyCharm 是 一 款 功 能 强 大 的 Python 编辑器,具有跨平台性 , 下 载 地 址 : http://www.jetbrains.com/pycharm/download/#section=windowsPyCharm ,把 pycharm和 python解释器进行连接。 ChatterBot 环境基于 chatterbot 0.8.7 开发,打开 cmd 进入 python 所在的磁盘,输入: pip install –ignore-installed –upgrade chatterbot0.8.7等待安装即可。 模块实现本项目包括 6 个模块:模型构建、服务器端、客户端、语音录入、接口调用、模型训练 及保存,下面分别给出各模块的功能介绍及相关代码。 1. 模型构建进入百度云官网:https://ai.baidu.com/,进入我的控制台,打开百度语音进入语音应用 管理界面,创建一个新的应用,如图所示。
记录 APPID、API Key 和 Secret Key 三个值。 请求方式和参数网址:https://cloud.baidu.com/doc/SPEECH/s/Qk38y8lrl 通过调用百度语音 API 实现相应的转换功能,在百度云应用管理中心可以看到记录,即为调用成功。
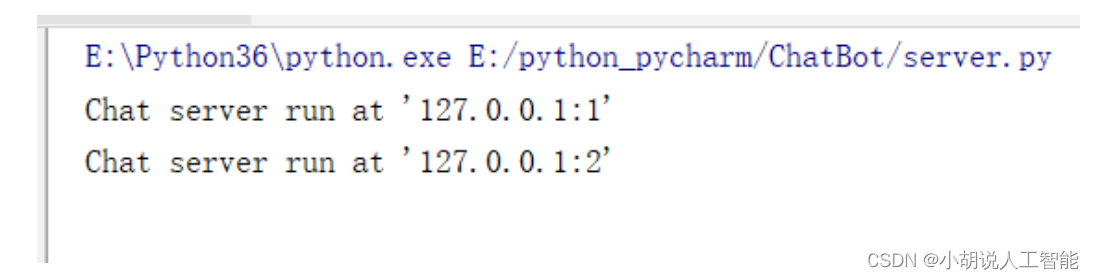
此模块主要处理用户的登录校验,房间的人员消息处理,通过 config.py 中配置的列表PORT 生成几个不同房间,相关代码如下: #导入 port 列表 import asynchat import asyncore from config import PORT class CommandHandler: """ 命令处理类 """ def unknown(self, session, cmd): # 响应未知命令 # 通过 aynchat.async_chat.push 方法发送消息 session.push(('Unknown command {} \n'.format(cmd)).encode("utf-8")) def handle(self, session, line): line = line.decode() # 命令处理 if not line.strip(): return parts = line.split(' ', 1) cmd = parts[0] try: line = parts[1].strip() except IndexError: line = '' # 通过协议代码执行相应的方法 method = getattr(self, 'do_' + cmd, None) try: method(session, line) except TypeError: self.unknown(session, cmd) if __name__ == '__main__': for i in range(len(PORT)): ChatServer(PORT[i]) print("Chat server run at '127.0.0.1:{0}'".format(PORT[i])) try: asyncore.loop() except KeyboardInterrupt: print("Chat server exit")在开启客户端前,运行服务器端,CommandHandler 类拆解 client 客户端发送信息中的命令,并绑定函数。通过 config.py 中配置列表 PORT = range(1, 3)生成两个房间,地址分别是 127.0.0.1:1 和 127.0.0.1:2,如图所示。
该模块提供登录窗口、聊天窗口以及各种响应事件,相关代码如下: 1)登录窗口设计 设计登录窗口的 GUI 界面,添加包括标题、地址栏、用户信息栏和登录退出按钮的几个控件并绑定登录、退出等各种事件。 class LoginFrame(wx.Frame): """ 登录窗口 """ def __init__(self, parent, id, title, size): # 初始化,添加控件并绑定事件 wx.Frame.__init__(self, parent, id, title) self.SetSize(size) self.Center() self.serverAddressLabel = wx.StaticText(self, label="服务地址", pos=(45, 40), size=(120, 25)) self.userNameLabel = wx.StaticText(self, label="用户名", pos=(45, 90), size=(120, 25)) self.serverAddress = wx.TextCtrl(self, value=default_server, pos=(120, 37), size=(150, 25), style=wx.TE_PROCESS_ENTER) self.userName = wx.TextCtrl(self, pos=(120, 87), size=(150, 25), style=wx.TE_PROCESS_ENTER) self.loginButton = wx.Button(self, label='登录', pos=(50, 145), size=(90, 30)) self.exitButton = wx.Button(self, label='退出', pos=(180, 145), size=(90, 30)) # 绑定登录方法 self.loginButton.Bind(wx.EVT_BUTTON, self.login) # 绑定退出方法 self.exitButton.Bind(wx.EVT_BUTTON, self.exit) # 服务器输入框Tab事件 self.serverAddress.SetFocus() self.Bind(wx.EVT_TEXT_ENTER, self.usn_focus, self.serverAddress) # 用户名回车登录 self.Bind(wx.EVT_TEXT_ENTER, self.login, self.userName) self.Show() # 回车调到用户名输入栏 def usn_focus(self, event): self.userName.SetFocus() def login(self, event): # 登录处理 try: serverAddress = self.serverAddress.GetLineText(0).split(':') con.open(serverAddress[0], port=int(serverAddress[1]), timeout=10) response = con.read_some() if response != b'Connect Success': self.showDialog('Error', 'Connect Fail!', (200, 100)) return con.write(('login ' + str(self.userName.GetLineText(0)) + '\n').encode("utf-8")) response = con.read_some() if response == b'UserName Empty': self.showDialog('Error', 'UserName Empty!', (200, 100)) elif response == b'UserName Exist': self.showDialog('Error', 'UserName Exist!', (200, 100)) else: self.Close() ChatFrame(None, 2, title='当前用户:'+str(self.userName.GetLineText(0)), size=(515, 400)) except Exception: self.showDialog('Error', 'Connect Fail!', (95, 20)) def exit(self, event): self.Close() # 显示错误信息对话框 def showDialog(self, title, content, size): dialog = wx.Dialog(self, title=title, size=size) dialog.Center() wx.StaticText(dialog, label=content) dialog.ShowModal()2)聊天窗口设计 设计聊天窗口的 GUI 界面,添加包括当前用户显示、信息输入框、语音输入按钮、发送和关闭按钮等各种控件并绑定发送消息、输入消息等事件。 class ChatFrame(wx.Frame): """ 聊天窗口 """ def __init__(self, parent, id, title, size): # 初始化,添加控件并绑定事件 wx.Frame.__init__(self, parent, id, title, style=wx.SYSTEM_MENU | wx.CAPTION | wx.CLOSE_BOX | wx.DEFAULT_FRAME_STYLE) self.SetSize(size) self.Center() self.chatFrame = wx.TextCtrl(self, pos=(5, 5), size=(490, 310), style=wx.TE_MULTILINE | wx.TE_READONLY) self.sayButton = wx.Button(self, label="语音", pos=(5, 320), size=(58, 25)) self.message = wx.TextCtrl(self, pos=(65, 320), size=(280, 25), style=wx.TE_PROCESS_ENTER) self.sendButton = wx.Button(self, label="发送", pos=(360, 320), size=(58, 25)) # self.usersButton = wx.Button(self, label="Users", pos=(373, 320), size=(58, 25)) self.closeButton = wx.Button(self, label="关闭", pos=(436, 320), size=(58, 25)) self.sendButton.Bind(wx.EVT_BUTTON, self.send) # 发送按钮绑定发送消息方法 self.message.SetFocus() # 输入框回车焦点 self.sayButton.Bind(wx.EVT_LEFT_DOWN, self.sayDown) # SAY按钮按下 self.sayButton.Bind(wx.EVT_LEFT_UP, self.sayUp) # Say按钮弹起 self.Bind(wx.EVT_TEXT_ENTER, self.send, self.message) # 回车发送消息 # self.usersButton.Bind(wx.EVT_BUTTON, self.lookUsers) # Users按钮绑定获取在线用户数量方法 self.closeButton.Bind(wx.EVT_BUTTON, self.close) # 关闭按钮绑定关闭方法 treceive = threading.Thread(target=self.receive) # 接收信息线程 treceive.start() # self.ShowFullScreen(True) # 全屏 self.Show() def sayDown(self, event): trecording = threading.Thread(target=recording) trecording.start() def sayUp(self, event): sayText = getText(r"E:\python_pycharm\ChatBot\voice\voice.wav") self.message.AppendText(str(sayText)) self.send(self) def send(self, event): # 发送消息 message = str(self.message.GetLineText(0)).strip() global bot_use if message != '': if message == "机器人": bot_use = "ChatBot" self.message.Clear() con.write(('noone_say 成功呼叫语音助手!' + '\n').encode("utf-8")) return elif message == "用户聊天": bot_use = "User" self.message.Clear() con.write(('noone_say 语音助手已离开' + '\n').encode("utf-8")) return con.write(('say ' + message + '\n').encode("utf-8")) self.message.Clear() # 机器人回复 if bot_use == "ChatBot": answer = chatbot(message) con.write(('chatbot_say ' + answer + '\n').encode("utf-8")) elif bot_use == "User": return if VOICE_SWITCH: # 写本地音乐文件 baidu_api(answer) # 新建线程播放音乐 tplay_mp3 = threading.Thread(target=play_mp3) tplay_mp3.start() # thread.start_new_thread(play_mp3, ()) return # def lookUsers(self, event): # # 查看当前在线用户 # con.write(b'look\n') def close(self, event): # 关闭窗口 tremove_voice = threading.Thread(target=remove_voice) tremove_voice.start() # thread.start_new_thread(remove_voice, ()) con.write(b'logout\n') con.close() self.Close() def receive(self): # 接受服务器的消息 while True: sleep(1) result = con.read_very_eager() if result != '': self.chatFrame.AppendText(result) def saytime(self): i = 0 while True: self.chatFrame.AppendText('正在录音...' + str(i) + '秒\n') sleep(1) i = i + 1 4. 语音录入该模块提供录音功能并将文件保存在本地, Recorder 的采样率与百度语音转文字的采样率相同,相关代码如下: from pyaudio import PyAudio, paInt16 import numpy as np import wave class Recoder: NUM_SAMPLES = 2000 # py audio内置缓冲大小 SAMPLING_RATE = 16000 # 取样频率 LEVEL = 500 # 声音保存的阈值 COUNT_NUM = 20 # NUM_SAMPLES个取样之内出现COUNT_NUM个大于LEVEL的取样则记录声音 SAVE_LENGTH = 8 # 声音记录的最小长度:SAVE_LENGTH * NUM_SAMPLES 个取样 TIME_COUNT = 20 # 录音时间,单位s Voice_String = [] def savewav(self, filename): wf = wave.open(filename, 'wb') wf.setnchannels(1) wf.setsampwidth(2) wf.setframerate(self.SAMPLING_RATE) wf.writeframes(np.array(self.Voice_String).tostring()) # wf.writeframes(self.Voice_String.decode()) wf.close() def recoder(self): pa = PyAudio() stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True, frames_per_buffer=self.NUM_SAMPLES) save_count = 0 save_buffer = [] time_count = self.TIME_COUNT while True: time_count -= 1 # print time_count # 读入NUM_SAMPLES个取样 string_audio_data = stream.read(self.NUM_SAMPLES) # 将读入的数据转换为数组 audio_data = np.fromstring(string_audio_data, dtype=np.short) # 计算大于LEVEL的取样的个数 large_sample_count = np.sum(audio_data > self.LEVEL) print(np.max(audio_data)) # 如果个数大于COUNT_NUM,则至少保存SAVE_LENGTH个块 if large_sample_count > self.COUNT_NUM: save_count = self.SAVE_LENGTH else: save_count -= 1 if save_count 0: # 将要保存的数据存放到save_buffer中 # print save_count > 0 and time_count >0 save_buffer.append(string_audio_data) else: # print save_buffer # 将save_buffer中的数据写入WAV文件,WAV文件的文件名是保存的时刻 # print "debug" if len(save_buffer) > 0: self.Voice_String = save_buffer save_buffer = [] print("Recode a piece of voice successfully!") return True if time_count == 0: if len(save_buffer) > 0: self.Voice_String = save_buffer save_buffer = [] print("Recode a piece of voice successfully!") return True else: return False def recording(): r = Recoder() r.recoder() r.savewav(r"E:\python_pycharm\ChatBot\voice\voice.wav") # if tsayTime != '': # stop_thread(tsayTime)语音录入时,控制面板输出如图所示。
此时在相应路径中可以看到录制成功的语音文件,格式为.Wav,如图所示。
该模块调用 chatbot 返回文本信息、百度 API 语音识别、百度 API 转文本为语音,相关代码如下: import pygame from chatterbot import ChatBot import requests import json from config import * import time import os import random import urllib.request import base64 # 初始化百度返回的音频文件地址,后面会变为全局变量,随需改变 mp3_url = r'E:\python_pycharm\ChatBot\voice\\voice_du\\voice_ss.mp3' '' # 播放Mp3文件 def play_mp3(): # 接受服务器的消息 pygame.mixer.init() pygame.mixer.music.load(mp3_url) pygame.mixer.music.play() while pygame.mixer.music.get_busy(): time.sleep(1) pygame.mixer.music.stop() pygame.mixer.quit() # 删除声音文件 def remove_voice(): path = r"E:\python_pycharm\ChatBot\voice\voice_du" for i in os.listdir(path): path_file = os.path.join(path, i) try: os.remove(path_file) except: continue # 聊天机器人回复 def chatbot(info): my_bot = ChatBot("", read_only=True, database="./db.sqlite3") res = my_bot.get_response(info) return str(res) # 百度讲文本转为声音文件保存在本地 tts地址,无需token实时认证 def baidu_api(answer): api_url = '{11}?idx={0}&tex={1}&cuid={2}&cod={3}&lan={4}&ctp={5}&pdt={6}&spd={7}&per={8}&vol={9}&pit={10}'\ .format(baidu_api_set["idx"], answer, baidu_api_set["cuid"], baidu_api_set["cod"], baidu_api_set["lan"], baidu_api_set["ctp"], baidu_api_set["pdt"], baidu_api_set["spd"], baidu_api_set["per"], baidu_api_set["vol"], baidu_api_set["pit"], baidu_api_url) res = requests.get(api_url, headers=headers2) # 本地Mp3语音文件保存位置 iname = random.randrange(1, 99999) global mp3_url mp3_url = r'E:\python_pycharm\ChatBot\voice\voice_du\voice_tts' + str(iname) + '.mp3' with open(mp3_url, 'wb') as f: f.write(res.content) # 百度讲文本转为声音文件保存在本地 方法2 tsn地址 def baidu_api2(answer): # 获取access_token token = getToken() get_url = baidu_api_url2 % (urllib.parse.quote(answer), "test", token) voice_data = urllib.request.urlopen(get_url).read() # 本地Mp3语音文件保存位置 name = random.randrange(1, 99999) global mp3_url mp3_url = r'E:\python_pycharm\ChatBot\voice\voice_du\voice_tsn' + str(name) + '.mp3' voice_fp = open(mp3_url, 'wb+') voice_fp.write(voice_data) voice_fp.close() return # 百度语音转文本 def getText(filename): # 获取access_token token = getToken() data = {} data['format'] = 'wav' data['rate'] = 16000 data['channel'] = 1 data['cuid'] = str(random.randrange(123456, 999999)) data['token'] = token wav_fp = open(filename, 'rb') voice_data = wav_fp.read() data['len'] = len(voice_data) data['speech'] = base64.b64encode(voice_data).decode('utf-8') post_data = json.dumps(data) # 语音识别的api url upvoice_url = 'http://vop.baidu.com/server_api' r_data = urllib.request.urlopen(upvoice_url, data=bytes(post_data, encoding="utf-8")).read() print(json.loads(r_data)) err = json.loads(r_data)['err_no'] if err == 0: return json.loads(r_data)['result'][0] else: return json.loads(r_data)['err_msg'] # 获取百度API调用的认证,实时生成,因为有时间限制 def getToken(): # token认证的url api_url = "https://openapi.baidu.com/oauth/2.0/token?" \ "grant_type=client_credentials&client_id=%s&client_secret=%s" token_url = api_url % (BaiDu_API_Key_GetVoi, BaiDu_Secret_Key_GetVoi) r_str = urllib.request.urlopen(token_url).read() token_data = json.loads(r_str) token_str = token_data['access_token'] return token_str 6.模型训练及保存该模块主要训练 chatbot 机器人,保存在本地 sqlite 数据库,提供两种语料训练方法。如果使用ChatGPT的话,可以将此步省略,直接使用其API接口 1) 语句训练 直接写训练语句,也可开启通过聊天时的语句自动,相关代码如下: my_bot.train(["你今年几岁了呀?", "我今年三岁半了!", ]) my_bot.train([ "你吃饭了吗", "我吃饱了", "你叫什么名字呀", "我叫小邮", ])2) 语料库训练 通过自定义语料库训练。 安装chatbot后默认提供的中文语料格式E:\Python36\Lib\sitepackages\chatterbot_corpus\data\Chinese。参照格式,写入自己的语料文件。 #使用自定义语句训练 my_bot.set_trainer(ChatterBotCorpusTrainer) my_bot.train("chatterbot.corpus.chinese") 系统测试本部分包括模型效果和模型应用。 1. 模型效果将所需语料库数据带入模型进行训练,如图所示。 训练结果如图所示。
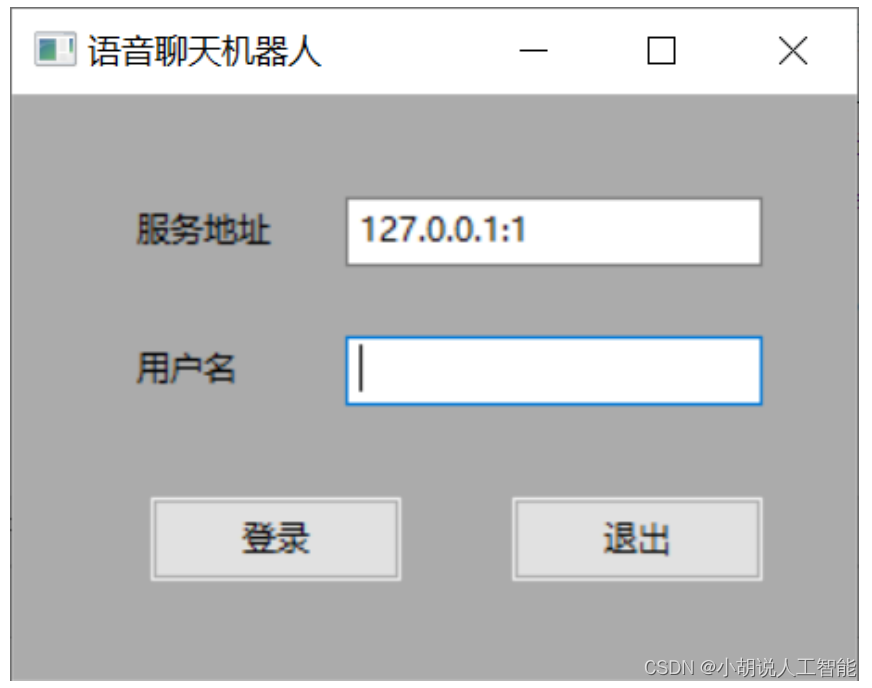
本部分包括程序运行、应用使用说明和程序功能实现。 1) 程序运行 rainChat.py 训练本地 chatbot 机器人(每次更新训练内容,运行一次即可);如果使用ChatGPT的话,可以将此步省略,直接使用其API接口server.py 开启服务器;client.py 运行客户端,每次运行都可登陆一个用户。2) 应用使用说明 运行程序后,用户初始登录界面如图所示。界面从上至下,两个文本框:一个输入服务地址,一个输入用户名;两个按钮:一个用于登录,一个用于项目退出。
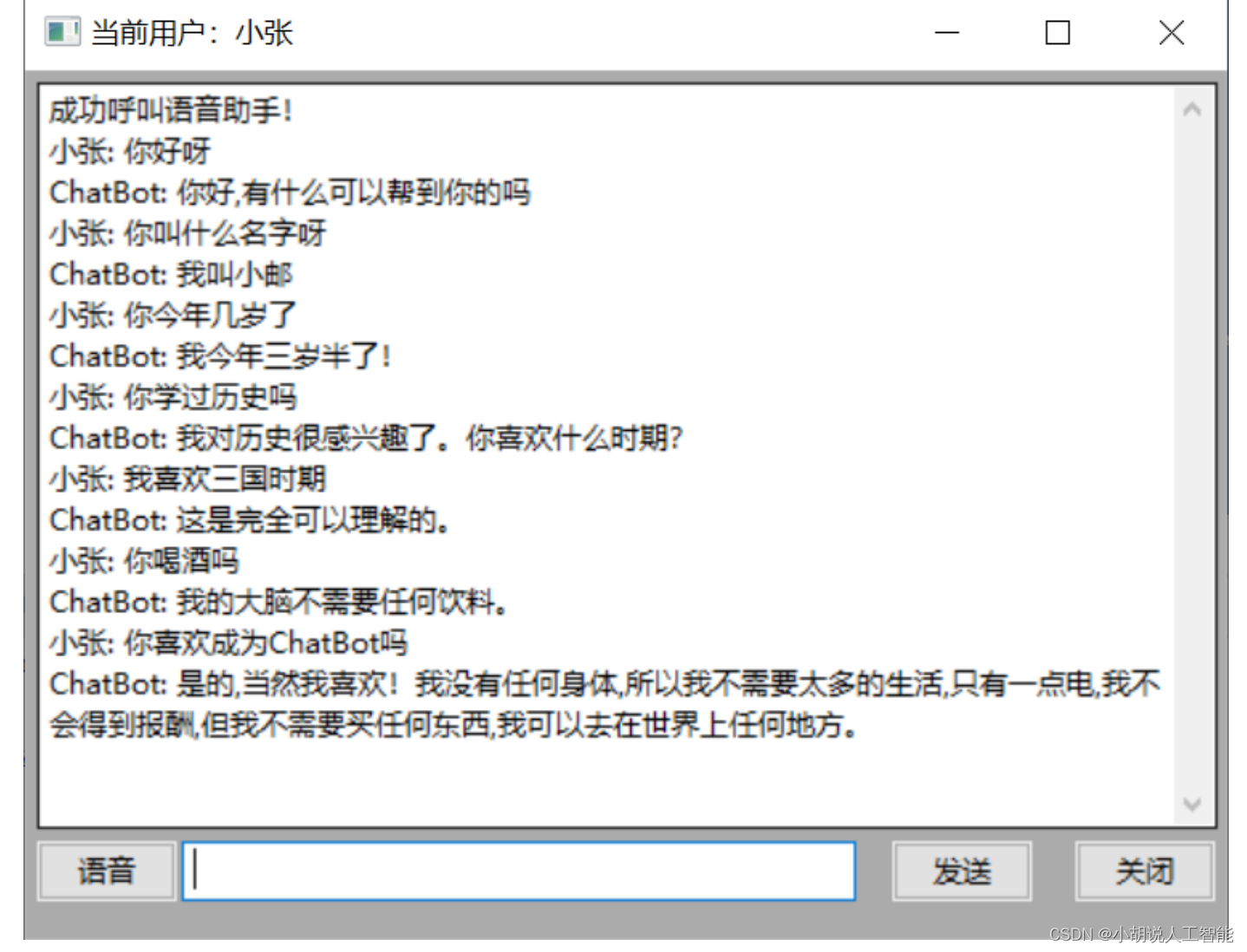
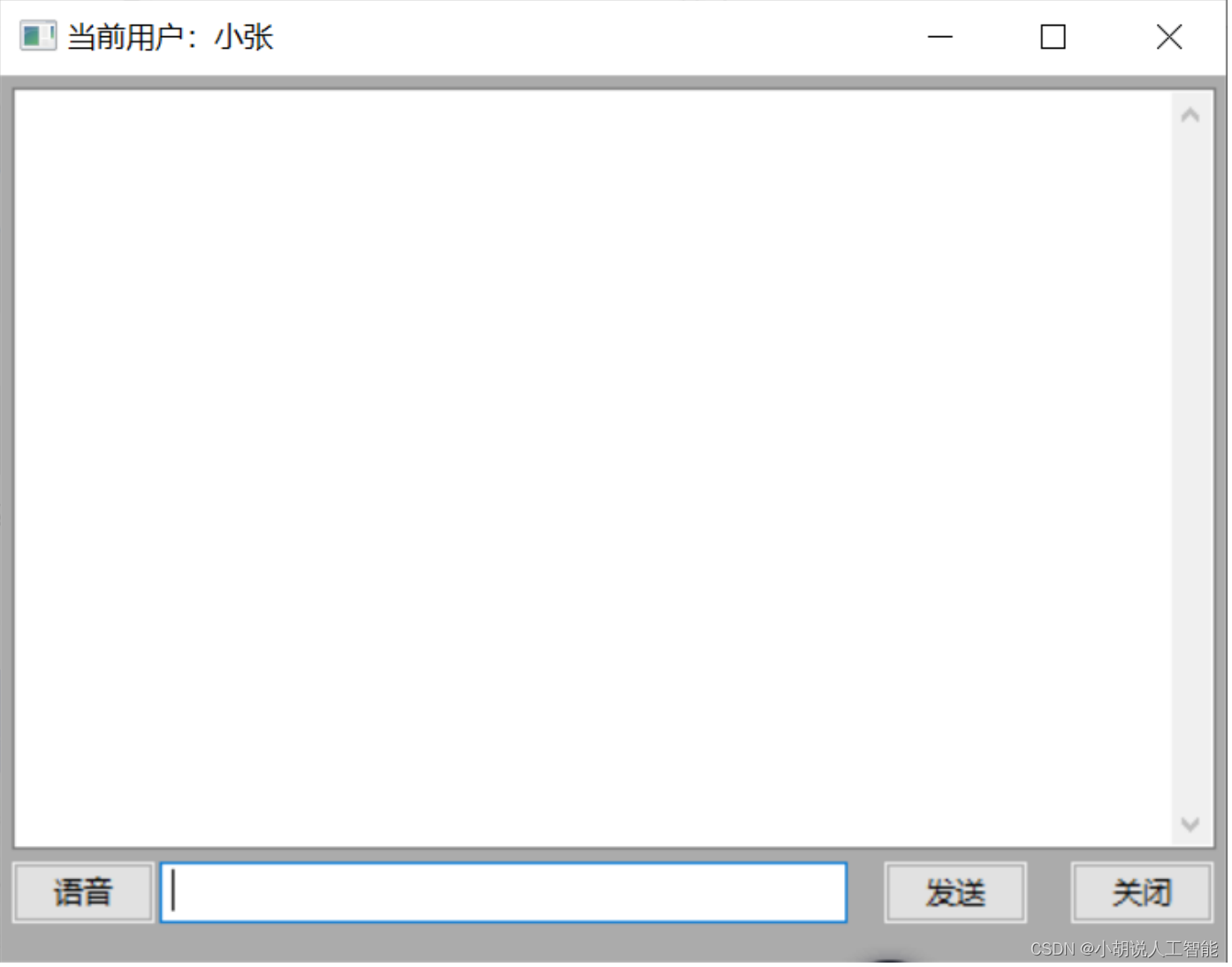
用户输入服务地址和登录后进入聊天界面。主体为聊天展示框,底部从左到右分别有语音输入按钮、文字输入文本框、发送按钮和聊天室关闭按钮,如图所示。
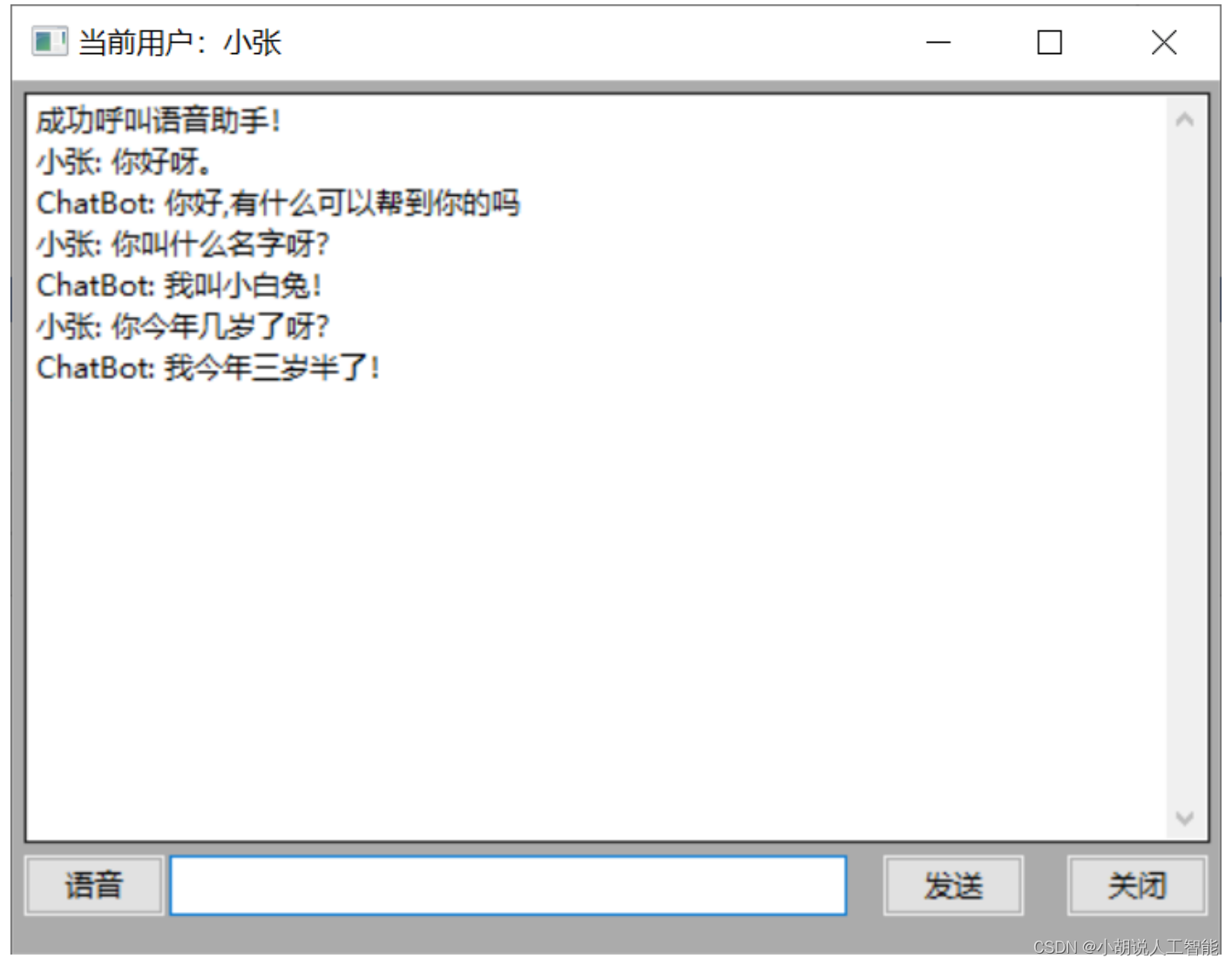
3) 程序功能实现 (1)在聊天框输入“机器人”可以呼叫语音助手,输入“用户聊天”退出语音机器人模式,如图所示。
(2)长按“语音”按钮录入语音与机器人进行对话,如图所示。
(3)退出机器人聊天模式还可实现多人聊天,如图所示。
基于Python+百度语音的智能语音ChatGPT聊天机器人(机器学习+深度学习+语义识别)含全部工程源码 其它资料下载如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》 这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。 |





【本文地址】
今日新闻 |
推荐新闻 |