苹果Vision Pro头显AI助手来袭:会调酒、能打麻将,甚至能开飞机 |
您所在的位置:网站首页 › ptp指令也叫 › 苹果Vision Pro头显AI助手来袭:会调酒、能打麻将,甚至能开飞机 |
苹果Vision Pro头显AI助手来袭:会调酒、能打麻将,甚至能开飞机
|
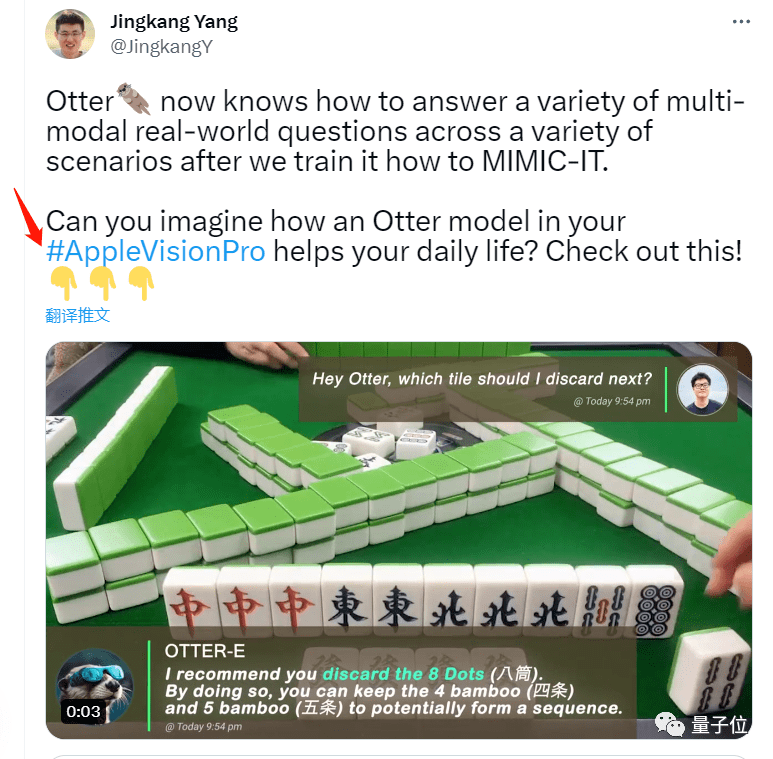
调酒师小哥忘记配方时,也能分分钟化解尴尬。
Otter一共支持八种语言, 中文也包括在内。
训练过程中,团队专门使用了适用于AR头显的第一视角视频,宣传上也明示就是为苹果头显准备的。
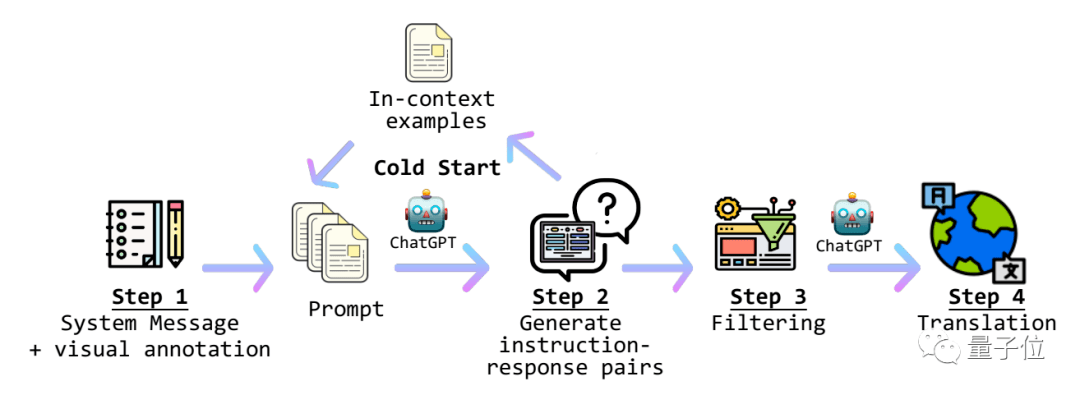
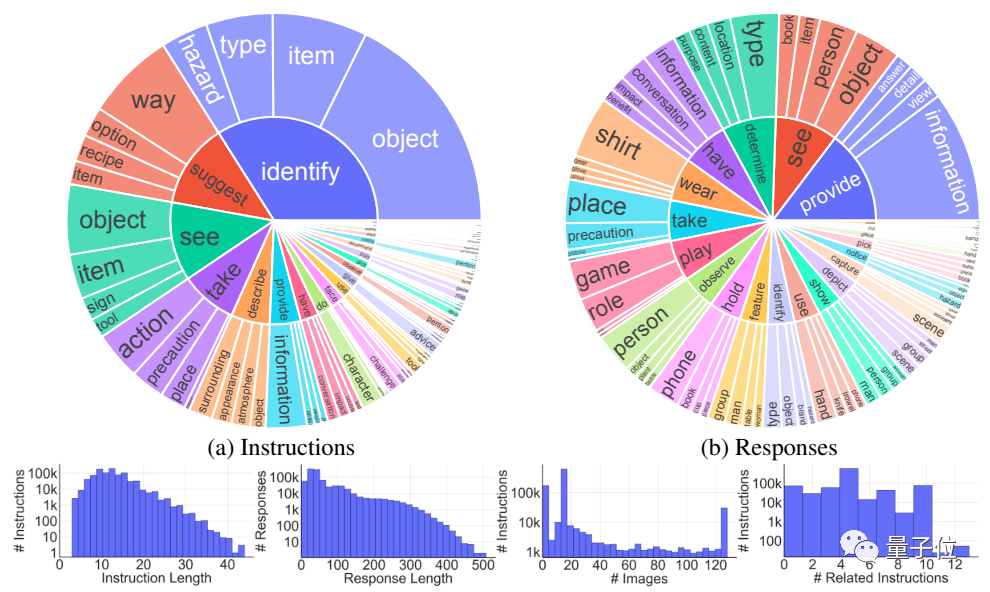
不过也有网友发现了华点。 结果,Otter在各测试项目上的平均成绩比传统的MiniGPT-4、OpenFlamingo等传统模型高出十余个百分点。 如何实现 其中核心的视觉模块是基于改进版本的LLaVA进行训练的。 Otter整体的工作流程大概是这样的: 首先要对视觉信息进行处理,并结合系统信息生成prompt。 生成好的prompt会被传递给ChatGPT,得到指令-回应数据。 这样得到的答案再经过一步筛选器筛选之后,由ChatGPT翻译成用户选择的语言并输出。 在主线流程之外,团队还引入了 冷启动机制,用于发现数据库中可用的情景实例。
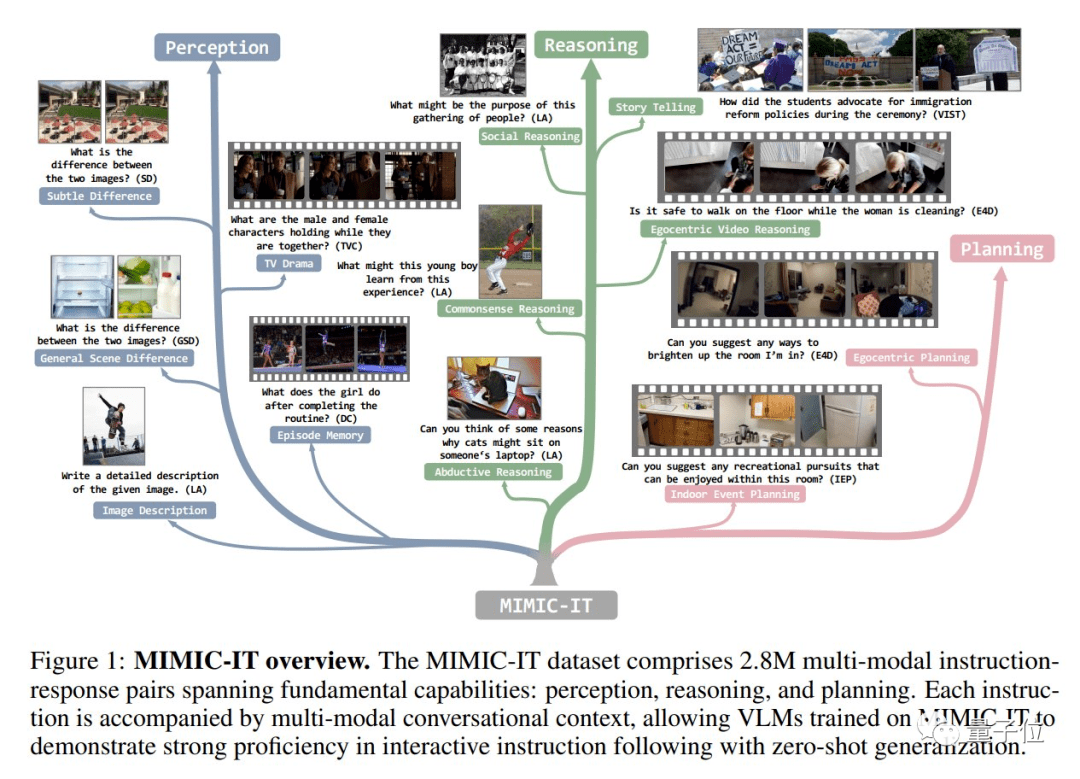
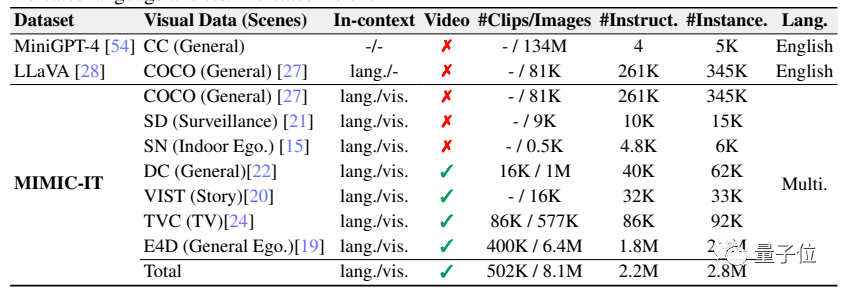
接下来,让我们看一下当中最关键的环节,也就是视觉信息的解释。 为了训练Otter,研究团队专门提出了 Mult I- Modal In- Context Instruction Tuning(多模式场景下的指令调整)数据集。 MIMIC-IT涵盖了大量的现实生活场景,而且不同于传统的LLaVa等只有一张图片和语言描述的数据集,MIMIC-IT包含多种模式。
第一步是对场景化信息的学习,这一部中使用的是经过调整的LLaVA数据集。 对数据集中的每个指令-相应组,团队都基于文字或图片相似性为其检索了是个场景化实例。
为了更好地适应真实世界,下一步的训练主要是让模型发现图像之间的差别。 而这些差别又被分为了一般差别和微小差别两种类型。 对于一般差别,通过prompt让ChatGPT进行图像分析和物体检测生成注释。 而对于微小差别,则使用自然语言描述作为注释。 拥有了发现差别的能力之后,就要让模型尝试着“讲故事”了。 由于图像注释无法直观反映时间线等要素,研究团队让ChatGPT充当观众并回答一系列问题。 每一个场景之中都包含图像和对应的指令-响应组。 为了扩展模型的视野,研究团队还让它学习了包含大量说明的长视频片段。 说明信息包括视频内容、人的动作和行为、事件发生的顺序和因果关系等。 为了增强模型的社交推理能力和对人物复杂动态行为的理解,研究团队最后把电视剧作为了训练材料。
介绍完一般场景,我们再来看看第一人称场景又是如何分析的。 第一人称场景既包括视觉上直观看到的内容,也包括观察者的内心感受。 研究团队从ScanNetv2数据集中搜集了一些场景并进行采样,转化为多个第一人称视角的二维视觉信息。 研究团队还让ChatGPT基于隐式设定的人物性格指导人类的行为,为模型生成训练数据。 作者简介 研究团队的成员主要来自南洋理工大学S实验室,第一作者是该实验室的博士生李博。 2017年,李博获得中国大学生编程比赛银奖。 2018年至今,李博先后在滴滴、英伟达、微软等机构先后从事研究工作。 李博的导师刘子纬助理教授是本文的通讯作者。 此外,微软雷蒙德研究院首席研究员Chunyuan Li也参与了本项目。 Otter的介绍视频在B站也有发布。 在线体验: https://otter.cliangyu.com/ 论文地址: https://arxiv.org/abs/2306.05425 GitHub页面: https://github.com/Luodian/Otter — 完— 「AIGC+垂直领域社群」 招募中! 欢迎关注AIGC的伙伴们加入AIGC+垂直领域社群,一起学习、探索、创新AIGC! 请备注您想加入的垂直领域「教育」或「电商零售」,加入AIGC人才社群请备注「人才」&「姓名-公司-职位」。 点这里 👇关注我,记得标星哦~ 一键三连「分享」、「点赞」和「在看」 科技前沿进展日日相见 ~ 返回搜狐,查看更多 |




【本文地址】
今日新闻 |
推荐新闻 |