[ICLR '23] The Hidden Uniform Cluster Prior in Self |
您所在的位置:网站首页 › prototype与sample有何区别 › [ICLR '23] The Hidden Uniform Cluster Prior in Self |
[ICLR '23] The Hidden Uniform Cluster Prior in Self
|
The Hidden Uniform Cluster Prior in Self-Supervised Learning 团队:Meta AI (FAIR), McGill University, Mila (Quebec AI Institute)会议:ICLR '23无源码现在有很多与类别不平衡数据(class-imbalanced data)相关的研究。但在自监督领域,研究类别不平衡数据处理方法的工作不算常见。这篇文章建设性地给出了自监督学习方法中隐含的一个妨碍自监督模型在现实数据集上精度的先验,称为均匀聚类先验(uniform cluster prior)。 1 Introduction平凡解是自监督领域一个老大难的问题。没有针对性设计的对比学习会陷入表示坍塌(representation collapse)的怪圈:编码器无视输入,永远输出一个常向量,因为两个常向量之间的相似程度永远是最大的。一众对比学习采用的方案大体分为两派:负样本派(MoCo,SimCLR)和非对比派(BYOL)。另一类视觉自监督学习方法(Barlow Twins, VICReg, MSN)也使用孪生神经网络的架构(但它们不会称自己为对比学习),它们通过在损失函数上添加正则项来避免坍塌。本文中,这些避免坍塌的方法统称为体积最大化(volume maximization),因为它们拓宽了表示空间,使得 encoder 输出的表示不再聚焦于一个点。 在对比学习的一篇著名的解释性文章 [1] 中,对比损失的功效被理解为 alignment + uniformity:前者表示语义相似的样本在表示空间中的距离应该相近,后者表示每个类别的表示应该在表示空间中均匀分布。这个“uniformity”就是一种体积最大化的解释。表示坍塌没有了,但这样的表示并不鲁棒。视觉自监督学习的性能大多是在 ImageNet-1K 这样的类别平衡的优质数据集上验证的,但现实数据集往往是类别不平衡的,比如服从长尾幂律分布的。另一方面,就算数据集是类别平衡的,在模型训练中,每一个 mini-batch 包含的类别很可能也不是平衡的。在这种情况下,模型学出来的表示依旧存在偏差。 为什么自监督学习方法不能自然胜任类别不平衡的数据?本文作者发现,原来一些体积最大化方法导致了一个潜在的问题:自监督方法学习的表示会暗地里把数据聚成大小相同的类,不这样做的表示会被惩罚(尽管这些表示是精确的)。问题有了,如何去解决它,是这篇文章的主要工作。 2 Contrastive Learning & K-means为解释现有对比学习方法存在的均匀聚类先验,我们需要先说明这些方法与 K-means 聚类之间存在的关联。K-means 被分为两类:显式的 K-means 划分 K 个 cluster 并定义 K 个质心,然后通过最小化第 k 个 cluster 中每个样本点到质心 \mu_k 的半径距离之和来移动这些质心到它们该去的位置: \min\limits_{\{\mathbb{X}_k\}_{k=1}^K} \sum\limits_{k=1}^K \sum\limits_{\boldsymbol{x} \in \mathbb{X}_k} \|\boldsymbol{x}-\mu_k\|^2_2 \tag{1} 原文中的 \mathbb{X} 符号来自 bbold 宏包。而隐式的 K-means 是不设置质心,而是通过计算每个 cluster 中每两个点之间的距离来代替: \sum\limits_{k=1}^K \sum\limits_{\boldsymbol{x} \in\mathbb{X}_k} \lVert\boldsymbol{x}-\mu_k\rVert^2_2 = \sum\limits_{k=1}^K \frac{1}{2\lvert\mathbb{X}_k\rvert} \sum\limits_{\boldsymbol{x}, \boldsymbol{x}^\prime \in \mathbb{X}_k} \lVert\boldsymbol{x}-\boldsymbol{x}'\rVert^2_2 \tag{2} 这两种方式本质上会优化到同一个最优的划分。之所以要提 K-means,是因为现在的自监督学习优化的 loss 在本质上都是 K-means,无论这些 loss 是明着聚类还是看上去和 K-means 一点关系都没有。 2.1 VICReg 和 SimCLR 是隐式的 K-means我们要先简单地介绍一下本文所涉及的一些前人的工作。 VICReg [2] 是一种针对表示坍塌而专门设计的联合嵌入对比学习方法,它的 loss 由 variance、covariance 和 invariance 三项组成:1. variance 表示为最小化一个 batch 的数据经 encoder 得到的表示在每一维 j=1,\cdots,d 上的值向量 z^j 的标准差S(这样可以使得一个 batch 中的表示互不相同):v(Z) = \displaystyle\frac{1}{d}\sum_{j=1}^{d}{\max(0, \gamma - S(z^j,\epsilon))} \tag{3}2. covariance 表示为最小化表示向量的平均协方差矩阵 C(Z) 的非对角线值的和(这样可以使得不同样本的表示之间的相关度最小):\begin{align} C(Z)&=\displaystyle\frac{1}{n-1}\sum_{i=1}^{n}{\left(z_i-\displaystyle\frac{1}{n}\sum_{i=1}^{n}{z_i}\right)\left(z_i-\displaystyle\frac{1}{n}\sum_{i=1}^{n}{z_i}\right)^\top}\tag{4} \\ c(Z) &= \displaystyle\frac{1}{d}\sum_{i \ne j}{(C(Z))^2_{i,j}}\tag{5} \end{align} 3. invariance 表示为最小化每两个表示向量之间的欧氏距离:s(Z,Z') =\displaystyle\frac{1}{n}\sum_{i=1}^{n}{\| z_i-z_i'\|^2_2}\tag{6}最终的 loss 就是上面三项的加权和。\ell(Z,Z') = \lambda s(Z,Z')+\mu(v(Z) + v(Z')) + \nu (c(Z) + c(Z'))\tag{7}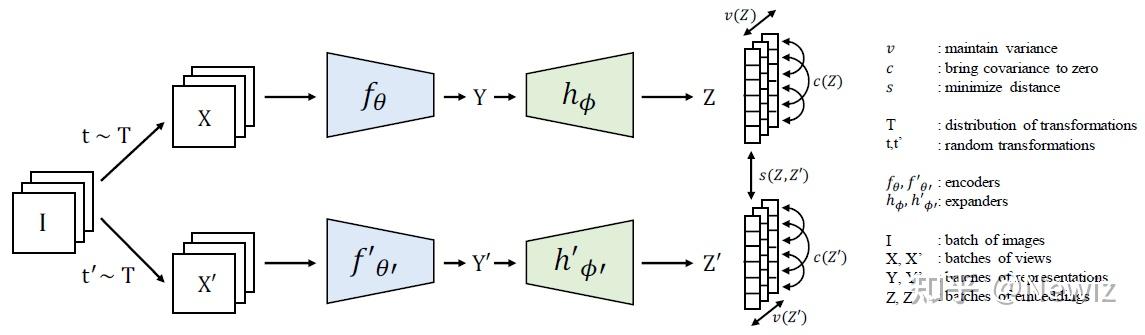 VICReg [2]SimCLR 应该不用介绍了吧。 VICReg [2]SimCLR 应该不用介绍了吧。VICReg 使用的 loss (7) 可以被写成这样(原文说将 variance 和 covariance 弄成一项,但我觉得是将 variance 直接扔掉了):\mathcal{L}_\text{VICReg}=\alpha \|\text{Cov}(\boldsymbol{Z}) - \boldsymbol{I} \|_F^2 +\frac{\gamma}{N} \sum_{i,j=1}^{N}(\boldsymbol{G})_{i,j}\|\boldsymbol{z}_{i}-\boldsymbol{z}_{j}\|_2^2 \tag{8}(\boldsymbol{G})_{i,j} 用来指示 (\boldsymbol{z}_{i}, \boldsymbol{z}_{j}) 是正样本对还是负样本对, \alpha 和 \gamma 是两个权重参数。通过类比公式 (8) 和 (2),我们发现,如果把正样本和负样本看作两个 cluster,那么和式 (8) 右边的一项(即 invariance)去掉 \gamma 后和 (2) 是完全等价的。这说明,VICReg 中的 invariance 设置就是在做隐式的 K-means 聚类。并且,VICReg 为强调增强的不变性常设置 \gamma \gg \alpha ,这说明这一聚类先验在 VICReg 的架构中起到了核心的作用。 Yann LeCun 在一个新的对比学习解释工作 [3] 中提到,SimCLR 等对比框架(称为 sample-contrastive)与 VICReg 等对比框架(称为 dimension-contrastive)的优化目标是等价的。详见该文的 Proposition 3.2 和 Theorem 3.3。因此,SimCLR 与 VICReg 类似,也属于隐式的 K-means。 2.2 MSN 和 SwAV 是显式的 K-means之前我们提到的 K-means 都可以视作 hard K-means,即每个点最终只能确定地属于一个 cluster。如果是隐式 K-means,则可以形式化为学习一个 cluster membership 矩阵 \mathbf{P} \in {0,1}^{N\times K},指示一个样本点属于哪个 cluster。这一节我们考虑 soft K-means,其中每个点可以以不同的概率属于多个 cluster。如果是隐式 K-means,则 cluster membership 矩阵的形式为 \mathbf{P} \in [0,1]^{N\times K}。  MSN(左)与 SwAV(右)MSN [4] 是一种基于掩码策略和聚类的自监督学习方法。对每一张输入图片,MSN 都通过一批增强生成一个 target view \boldsymbol{x}_i^+和 M 个 anchor view \boldsymbol{x}_{i,m},将 anchor views 分块并进行掩码,把 target view 和掩码后的 anchor views 送入编码器得到表示 z_i^+ 和 z_{i,m}。另外,MSN 设置了一批可学习的原型表示(prototype),通过计算 target view 或 anchor view 与原型表示的相似度,得到类别预测的后验概率: p_{i,m}=\text{softmax}\left(\displaystyle\frac{z_{i,m}\cdot\boldsymbol{q}}{\tau}\right) \tag{9}target view 对应的温度 \tau^+ 一般远小于 anchor view 对应的温度 \tau,使得 target prediction 熵值更小,置信度更高,更适于指导 anchor prediction 的学习。MSN 的优化目标是 anchor prediction 和 target prediction 的分布距离: \begin{align}\notag \mathcal{L}_\text{MSN} &= D_{KL}[p\|p^+] \\\notag &= \displaystyle\frac{1}{MB}\sum_{\substack{i&=1\\m&=1}}^{B,M}{H(p_{i,m},p_i^+)} - \lambda H \left(\displaystyle\frac{1}{MB}\sum_{\substack{i&=1\\m&=1}}^{B,M}{p_{i,m}}\right) \end{align} \tag{10} MSN(左)与 SwAV(右)MSN [4] 是一种基于掩码策略和聚类的自监督学习方法。对每一张输入图片,MSN 都通过一批增强生成一个 target view \boldsymbol{x}_i^+和 M 个 anchor view \boldsymbol{x}_{i,m},将 anchor views 分块并进行掩码,把 target view 和掩码后的 anchor views 送入编码器得到表示 z_i^+ 和 z_{i,m}。另外,MSN 设置了一批可学习的原型表示(prototype),通过计算 target view 或 anchor view 与原型表示的相似度,得到类别预测的后验概率: p_{i,m}=\text{softmax}\left(\displaystyle\frac{z_{i,m}\cdot\boldsymbol{q}}{\tau}\right) \tag{9}target view 对应的温度 \tau^+ 一般远小于 anchor view 对应的温度 \tau,使得 target prediction 熵值更小,置信度更高,更适于指导 anchor prediction 的学习。MSN 的优化目标是 anchor prediction 和 target prediction 的分布距离: \begin{align}\notag \mathcal{L}_\text{MSN} &= D_{KL}[p\|p^+] \\\notag &= \displaystyle\frac{1}{MB}\sum_{\substack{i&=1\\m&=1}}^{B,M}{H(p_{i,m},p_i^+)} - \lambda H \left(\displaystyle\frac{1}{MB}\sum_{\substack{i&=1\\m&=1}}^{B,M}{p_{i,m}}\right) \end{align} \tag{10}设聚类先验分布为 \pi ,则考虑聚类先验时,MSN 的优化目标可以写作(证明详见原文 C.3 节) \mathcal{L}_\text{MSN} = \sum_{k=1}^{N}\sum_{\boldsymbol{x} \in \mathbb{X}_k}\|\boldsymbol{x}-\mu_k\|_2^2 +\lambda D_{KL}[p(x)\|\pi] \tag{11}因此,MSN 使用的损失可以被看作一个高斯混合模型(Gaussian Mixture Model, GMM),而 GMM 又可以看作是 soft K-means,因为 GMM 估计的似然函数可以被写作\small{\begin{align}\notag \min\mathcal{L}_\text{GMM} &= \min_{\{\mu_k,\Sigma_k\}_{k=1}^K}\underbrace{\sum_{\boldsymbol{x} \in \mathbb{X}}\sum_{k=1}^{K} \frac{[p(\boldsymbol{x})]_k}{2}\|\boldsymbol{x}-\mu_k\|^2_2}_\text{soft K-means} +\underbrace{N\sum_{k=1}^{K}\log\det(\Sigma_k)}_\text{cluster dispersion} +\underbrace{\sum_{\boldsymbol{x} \in \mathbb{X}}D_{\text{KL}}[p(\boldsymbol{x}) \| \pi]}_\text{cluster prior} \\ \end{align}} \tag{12}其中后验概率分布 [p(x)]_k 表示观测数据 \boldsymbol{x} 属于第 k 个 cluster 的概率。当我们设置聚类先验为均匀分布时([\pi]_k=1/k),因为每个类都是大小均匀的,所以每个类中的点与聚类中心的差的期望可以看作是一样的,故协方差矩阵对角线上每个值都变成了 \sigma ,GMM 的协方差矩阵满足 \Sigma_k=\sigma\boldsymbol{I} (这被称为各向同性)。因此,式 (12) 中间的一项成为常值,不会随样本的聚类划分而变化。此时,我们将式 (12) 与式 (1) 进行对比,可以发现式 (12) 就是包含聚类先验的显式 K-means。 再观察式 (12) 和 MSN loss (11) 的等价性,我们不难得出,MSN 的优化目标可以视作显式 K-means。 SwAV [5] 的架构与 MSN 十分类似,也是通过将 encoder 学习到的表示分配到原型表示上,并计算两者之间的相似度。不同于传统对比学习的是,SwAV 将两个 view 分配的原型向量交换,用对方分配的原型和自己的特征计算交叉熵。另外,SwAV 在对一个 batch 中的实例进行聚类时,显式地设定了聚类大小的约束,即每个 cluster 需要有相同的大小。SwAV 的情况和 MSN 类似,都是显式地使用了聚类中心(原型)进行相似度学习的方法。而 SwAV 要求学习出的预测需要均分到每个原型向量: \small\mathcal{L}_\text{SwAV} = \frac{1}{N} \sum^N_{n=1} H(\boldsymbol{p}_{n}^+, \boldsymbol{p}_n) \quad s.t. \quad [\boldsymbol{p}^+_1, \ldots, \boldsymbol{p}^+_n] \mathbf{1}_N = \frac{N}{K} \mathbf{1}_K, \quad [\boldsymbol{p}^+_1, \ldots, \boldsymbol{p}^+_n]^\top \mathbf{1}_K = \mathbf{1}_N \tag{13} 上式中的条件表明,每个 \boldsymbol{p} 的值都等于 N/K 。这也正是本文提出的显式的均匀聚类先验。 3 Uniform Cluster Prior我们设置聚类先验为均匀分布为什么合理?因为 K-means 算法本身就是具有均匀聚类先验的。在上一节我们提到,K-means 的优化目标式 (1)(2) 本质上是在求解协方差矩阵为单位阵时的 GMM。而只有当聚类先验是均匀分布时,协方差矩阵才能被写作 \Sigma_k=\sigma\boldsymbol{I} 的形式。所以,我们在实际应用 K-means 的时候可以观察到,当几个簇的数据点重叠在一起的时候,K-means 的划分基本上保证了每个 cluster 的大小都差不多:  在类别平衡和不平衡状态下 K-means 给出的划分,黑色虚线划分出了样本的实际类别 在类别平衡和不平衡状态下 K-means 给出的划分,黑色虚线划分出了样本的实际类别所以,在均匀聚类先验下,K-means 对类别不平衡数据的划分是存在偏差的。而基于体积最大化的自监督模型可以被视作隐式的或显式的 K-means,故它们也是存在均匀聚类先验的,因此不擅于处理类别不平衡数据的情况。 为验证上述理论,作者设置了两套数据采样机制,以用实验说明类别不平衡的情况下基于体积最大化的自监督模型性能会显著下降。其中,类别平衡采样从 ImageNet-1K 中随机选取 960 个类别,并从每一类中采样相同数目的样本用于划分 mini-batch 并进行训练;类别不平衡采样仅随机选取个位数个类别,并从每一类中采样相同数目的样本(两种策略采样得到的样本总数是一致的)。笔者不熟悉类别不平衡领域,觉得这里的设置很奇怪,因为类别不平衡应该是指每个类别在每个 mini-batch 中的样本量差异很大,而不是总体类别数差异很大。暂且接受原文的设置,在 SimCLR、MSN、VICReg 三套框架上,类别不平衡采样的模型均显著地低于类别平衡采样的模型,而不使用体积最大化的 MAE 和 data2vec 模型则未受到很大影响: 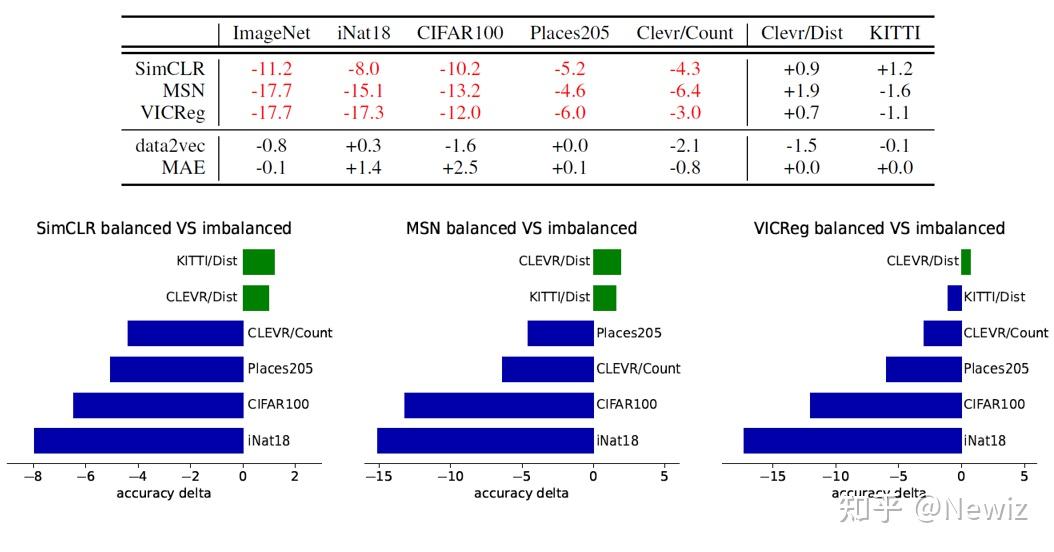 表中的数值以及下面柱状图的坐标表示【类别不平衡设置下的模型性能与平衡设置下模型性能的差】这里用到了几个特殊的数据集,其中 iNat18 和 ImageNet 一样是用于图像分类的,但其类别标签粒度更细,分布更加趋于长尾。Clevr 是用于视觉推理任务的,这里使用 Clevr/Count 进行目标计数。Clevr / Dist 和 KITTI 数据集被用于自动驾驶场景中的深度检测。深度检测任务仅需要浅层的表征,因此均匀聚类先验模型在这个任务上的表现没有受到太大影响。MAE 是 FAIR 何恺明团队提出的掩蔽自编码器(Masked Auto-Encoder),而 data2vec 是 Meta AI(没错又双叒是他们,说 Facebook 的 AI 团队占了自监督领域发展的半壁江山都不为过)基于学生-教师模型的多模态掩码自监督模型。这两种方式的优化目标都没有显式使用任何体积最大化策略。 表中的数值以及下面柱状图的坐标表示【类别不平衡设置下的模型性能与平衡设置下模型性能的差】这里用到了几个特殊的数据集,其中 iNat18 和 ImageNet 一样是用于图像分类的,但其类别标签粒度更细,分布更加趋于长尾。Clevr 是用于视觉推理任务的,这里使用 Clevr/Count 进行目标计数。Clevr / Dist 和 KITTI 数据集被用于自动驾驶场景中的深度检测。深度检测任务仅需要浅层的表征,因此均匀聚类先验模型在这个任务上的表现没有受到太大影响。MAE 是 FAIR 何恺明团队提出的掩蔽自编码器(Masked Auto-Encoder),而 data2vec 是 Meta AI(没错又双叒是他们,说 Facebook 的 AI 团队占了自监督领域发展的半壁江山都不为过)基于学生-教师模型的多模态掩码自监督模型。这两种方式的优化目标都没有显式使用任何体积最大化策略。另外,论文使用可视化方法 RCDM(一种新的基于扩散模型的特征可视化方法,通过给定的表示来生成图像,以解释并评估视觉自监督学习模型所学到的内容,详见原文 [6],也是 Meta AI 的工作但是被 ICLR 2022 无情地拒了)查看 MSN 在两种采样设置下从 ImageNet-1K 学到表示的情况。图中每一行图片来自同一个原型表示。通过对比,我们发现,在类别平衡的设置下(左 (a)),每一行所表示的类别更加统一,例如很容易看出第一行是船,第二行是袋鼠,第三四行是狗子。但是在类别不平衡的设置下(右 (b)),就很难说明每一行都是什么类别了,有的图像生成得乱七八糟,但也能看出每行图像中存在的一些形状、纹理上的共性。  用 MSN 原型可视化得到的生成图像 用 MSN 原型可视化得到的生成图像综上所述,基于体积最大化的自监督模型确实不擅于处理类别不平衡的数据集。 但是,上述实验并未说明模型性能的下降与均匀聚类先验之间有何关联。为说明均匀聚类先验是如何干扰编码器的,作者设计了一个很特别的实验。他们给服从均匀分布的 CIFAR10 数据集中每一张图像都配备了一个 MNIST 数字图,它被贴在每张 CIFAR10 图像的左上角。这些 MNIST 数字与 CIFAR10 图像的类别无关,但不同于 CIFAR10,这些 MNIST 数字图整体符合指数为 0.5 的幂律分布。这样的带数字 CIFAR10 数据集被输入 MSN 模型以获得表示。对模型输出的表示进行聚类,结果发现在均匀聚类先验和幂律聚类先验两种设置下,模型输出的最近邻表示具有很大差异:幂律聚类先验模型(左 (b))给出的 top-6 最近邻图全部包含与聚类中心相同的 MNIST 数字(第一行图像的数字均为 8,第二行图像的数字均为 9,……);而均匀聚类先验模型(右 (c))给出的 top-6 最近邻图则专注于图像本身的类别,而 MNIST 数字特征不再匹配。这说明,均匀聚类先验模型会抑制不服从均匀分布的样本特征。  幂律聚类先验模型与均匀聚类先验模型保留的特征是不同的 幂律聚类先验模型与均匀聚类先验模型保留的特征是不同的这一实验设计得巧妙,但并不严谨。实验的设计初衷是将服从均匀分布和幂律分布的部分(分别是 CIFAR10 图像和 MNIST 数字)显式地定义出来并融合到一个数据集中,观察模型对这两部分的态度,以说明先验对模型编码特征的潜在影响。但是,这两部分的融合方法本身就是不公平的,因为服从均匀分布的部分,即 CIFAR10 图像本身,仍然是整个数据集的主体,很难说明模型在编码时不会对图像本身的语义信息产生偏向性。这样的话,上图的结果不见得能说明是均匀聚类先验导致每一行的数字不统一的。 另外,论文作者在回应审稿人时进行了混合先验分布的实验,即使用两个 head 分别在两种先验上训练,结果是模型同时保留了 CIFAR10 的图像信息和 MNIST 的数字信息。 4 MSN with Prior Matching鉴于均匀聚类先验在现实的类别不均衡数据集上造成的负面影响,本文作者改进了 MSN 模型使其考虑数据的幂律分布,这一新模型被命名为 Prior Matching for Siamese Networks(PMSN)。它与 MSN 的唯一区别,在于把之前分析的 cluster prior 一项考虑进了 MSN 的损失: \mathcal{L}_\text{PMSN} = \frac{1}{N} \sum^N_{i=1} H(\boldsymbol{p}_{i}^+, \boldsymbol{p}_i) + \underbrace{\lambda D_{\text{KL}}\left( \bar{\boldsymbol{p}} \| \boldsymbol{p}_{\text{PL}(\tau)}\right)}_\text{cluster prior} \tag{14}其中 \tau 是幂律分布的指数项。第三节的 MNIST 实验也是使用 MSN 和 PMSN 两个模型进行的。 考虑幂律分布的 PMSN 效果如何,还是通过上一节使用的下游任务和数据集来评估。使用 ViT-S/16 为编码器,PMSN 在所有服从幂律分布的数据集上的预测精度都有了一定提升:  在已知类别分布(左)和未知类别分布(右)的情况下考虑不同分布,因为数据集的类别分布在实际情况下是不知道的,所以右表是使用统一的幂律分布(τ = 0.25)作为聚类先验时模型的效果 在已知类别分布(左)和未知类别分布(右)的情况下考虑不同分布,因为数据集的类别分布在实际情况下是不知道的,所以右表是使用统一的幂律分布(τ = 0.25)作为聚类先验时模型的效果可以发现 PMSN 在类别平衡的 ImageNet1K 上效果降了许多,这也从反面证明了模型性能确实在很大程度上取决于模型的聚类分布先验与数据集分布的匹配程度。 最后,来看一下 RCDM 给出的可视化原型表示的差异:  幂律聚类先验模型(左)比均匀聚类先验模型(右)从原型中学到了更精确的类别表示 幂律聚类先验模型(左)比均匀聚类先验模型(右)从原型中学到了更精确的类别表示另外,论文作者在回应审稿人时将这一先验同时移植到了 SwAV 上,得到了同样的结论。 5 Uniform Cluster Prior & InfoMax鲁迅曾经说过,永远不要忽略一篇顶会论文的附录。本文的附录中就有一段精彩的思考:现今自监督方法奉为圭臬的互信息最大化原则是否真的合理。自监督学习模型的优化目标可以看作一个最大化互信息 I(Z;X) 的项和一个简约项(原文 parsimony principle)组成:前者是自监督模型的标配(自编码器从 encoder 输出的表示重构原数据的过程是在光明正大地最大化 I(Z;X) ;SimCLR 等大量对比学习模型使用的 InfoNCE 正是在最大化互信息的下界),而简约项则鼓励 encoder 给出低维、稀疏、维度之间具有统计独立性的表示(也就是希望 encoder 尽可能地从输入中提炼出精华的语义表示,避免平凡解,因此简约项可以理解为正文中所说的体积最大化)。文献 [1] 中给出的对对比损失的 alignment + uniformity 的解释,其实就是这一说法的体现。 但是,最大化互信息本质上是在最大化边缘熵 H(Z) ,因为 I(Z;X)=H(Z)-H(Z|X)\\当 Z 的分布为均匀分布时,其边缘熵最大(想一下交叉熵损失在什么情况下最大就理解了),因此最大化互信息的操作就已经包含了均匀聚类先验。而 PMSN 使用幂律分布作为先验,本质上调整了互信息最大化的策略,在现实数据集上获得了更好的效果。这对于研究在类别不平衡数据集上做自监督学习的研究者们是一个十分有意义的启发。 6 Conclusion这篇文章最精华的部分不能说是 PMSN,而是把已有的许多对比学习工作与 K-means 关联起来的过程。因为在这一部分,作者深入剖析了这些方法的优化目标,并给出了这些 loss 在本质上的相同点。这对于对比学习方法的改进是十分具有启发性的。总体而言,这篇文章发现了对比式的自监督学习中存在的偏爱类别平衡数据的先验,并给出了一些理论分析以及这一问题可行的初步解。 另外,这篇文章的参考文献数量达到了恐怖的 79 篇,快赶上一份小综述了。不得不感叹知名 AI 研究所的研究人员阅读和关联已有领域工作的能力。 References[1] Tongzhou Wang, et al. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In ICML, 2020: 9929-9939. [2] Adrien Bardes, et al. VICReg: Variance-invariance-covariance regularization for self-supervised learning. In ICLR, 2022. [3] Quentin Garrido, et al. On the duality between contrastive and non-contrastive self-supervised learning. In ICLR, 2023. [4] Mahmoud Assran, et al. Masked siamese networks for label-efficient learning. In ECCV, 2022: 456-473. [5] Mathilde Caron, et al. Unsupervised learning of visual features by contrasting cluster assignments. In NeurIPS, 2020: 9912-9924. [6] Florian Bordes, et al. High fidelity visualization of what your self-supervised representation knows about. TMLR, 2022. |
【本文地址】
今日新闻 |
推荐新闻 |