09 |
您所在的位置:网站首页 › profiling工具 › 09 |
09
|
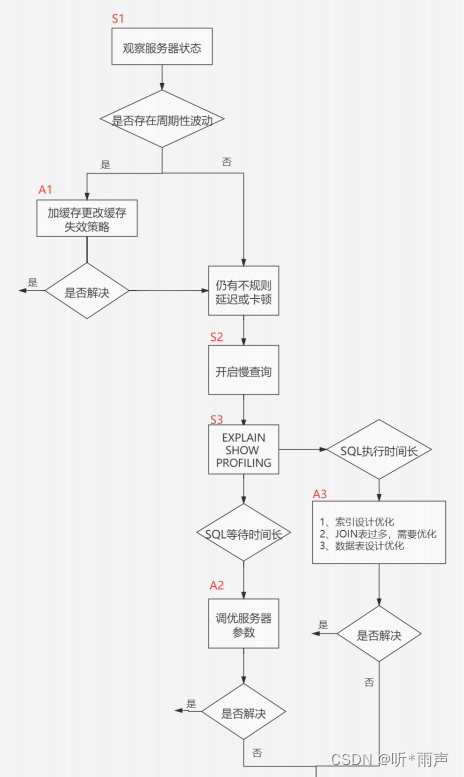
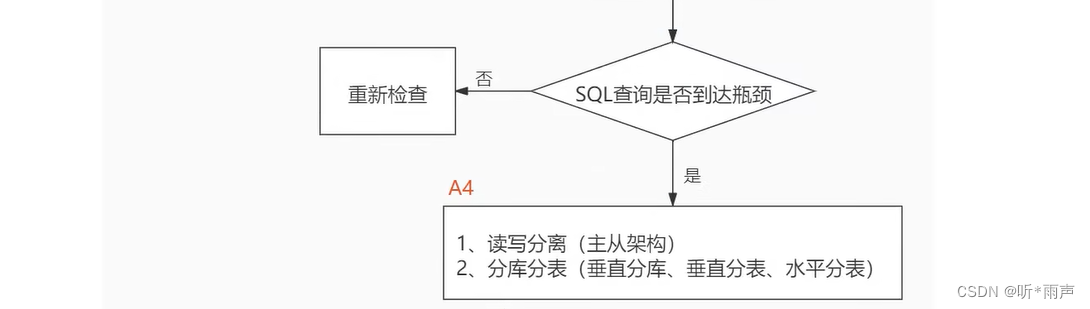
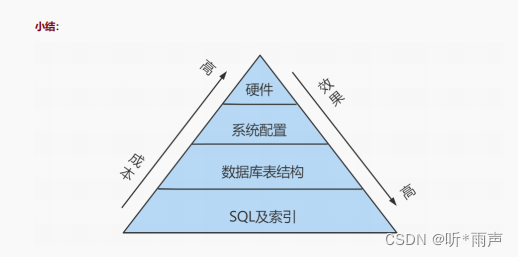
在数据库调优中,我们的目标就是响应时间更快,吞吐量更大。利用宏观的监控工具和微观的日志分析可以帮我们快速找到调优的思路和方式。 实际生产中SQL执行比较慢,是索引设计的问题,服务器参数配置的问题,还是需要增加缓存的问题 1. 数据库服务器的优化步骤当我们遇到数据库调优问题的时候,该如何思考呢?这里把思考的流程整理成下面这张图。 整个流程划分成了 观察(Show status) 和 行动(Action) 两个部分。字母 S 的部分代表观察(会使用相应的分析工具),字母 A 代表的部分是行动(对应分析可以采取的行动)。
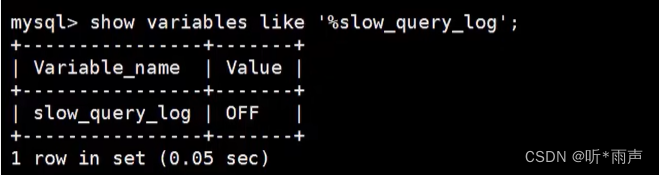
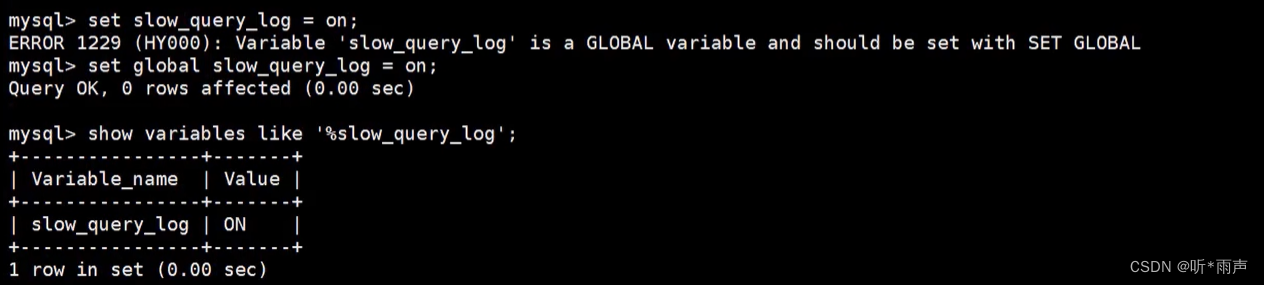
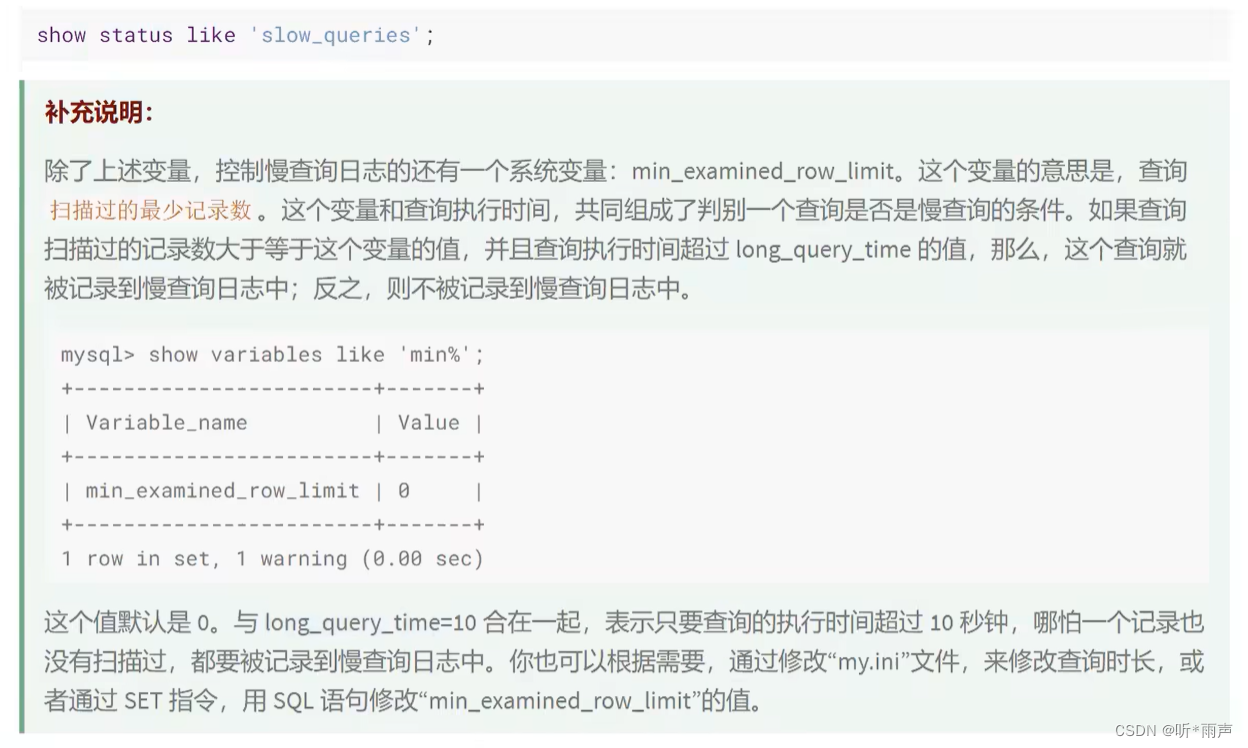
使用场景:它对于比较开销是非常有用的,特别是我们有好几种查询方式可选的时候。 SQL 查询是一个动态的过程,从页加载的角度来看,我们可以得到以下两点结论: 位置决定效率。如果页就在数据库缓冲池中,那么效率是最高的,否则还需要从内存或者磁盘中进行读取,当然针对单个页的读取来说,如果页存在于内存中,会比在磁盘中读取效率高很多。批量决定效率。如果我们从磁盘中对单一页进行随机读,那么效率是很低的(差不多10ms),而采用顺序读取的方式,批量对页进行读取,平均一页的读取效率就会提升很多,甚至要快于单个页面在内存中的随机读取。所以说,遇到I/O并不用担心,方法找对了,效率还是很高的。我们首先要考虑数据存放的位置,如果是经常使用的数据就要尽量放到缓冲池中,其次我们可以充分利用磁盘的吞吐能力,一次性批量读取数据,这样单个页的读取效率也就得到了提升。 4. 定位执行慢的SQL:慢查询日志MySQL的慢查询日志,用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过long_query_time的值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上(不含10秒)的语句,认为是超出了我们的最大忍耐时间值。 它的主要作用是,帮助我们发现那些执行时间特别长的SQL查询,并且有针对性地进行优化, 从而提高系统的整体效率。当我们的数据库服务器发生阻塞、运行变慢的时候,检查一下慢查询日志,找到那些慢查询,对解决问题很有帮助。比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合explain进行全面分析。 默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。 4.1 开启慢查询日志参数1. 开启slow_query_log set global slow_query_log='ON';
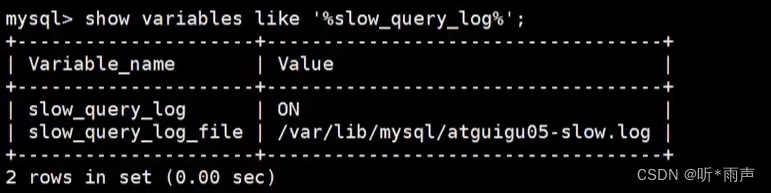
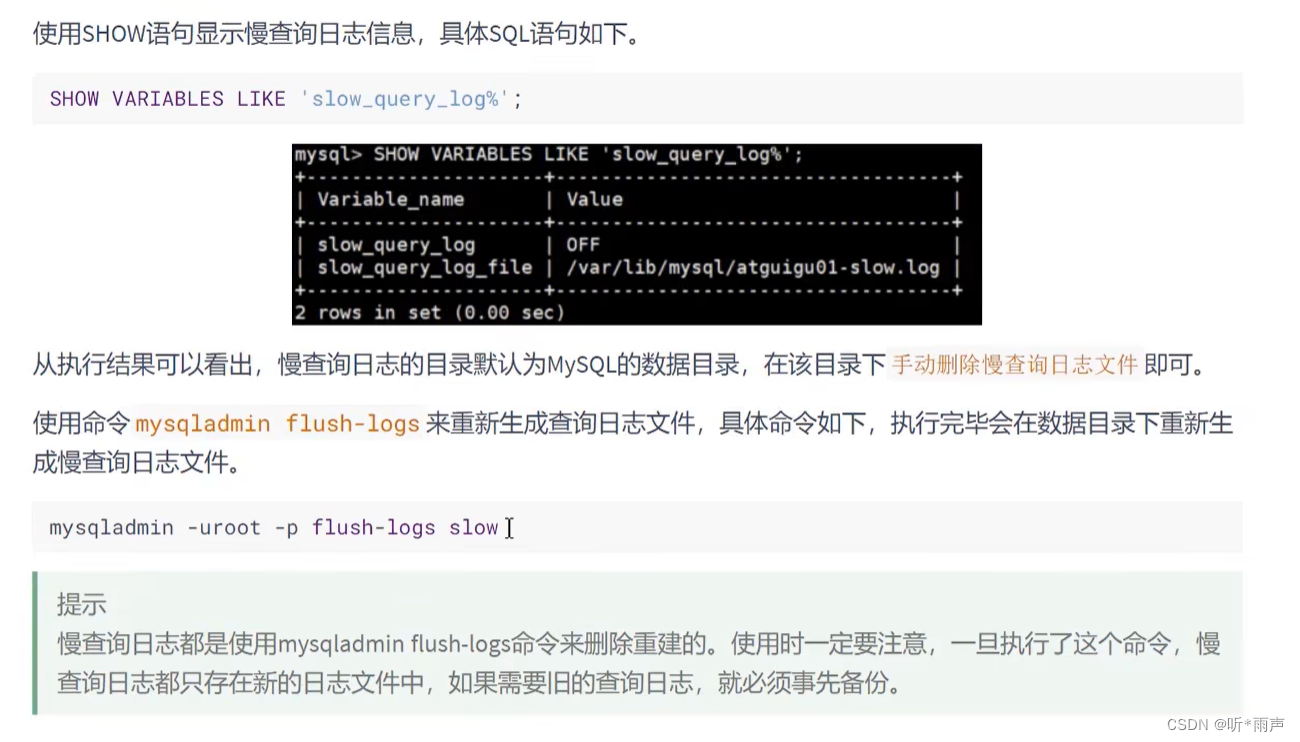
查看下慢查询日志是否开启,以及慢查询日志文件的位置: show variables like `%slow_query_log%`;
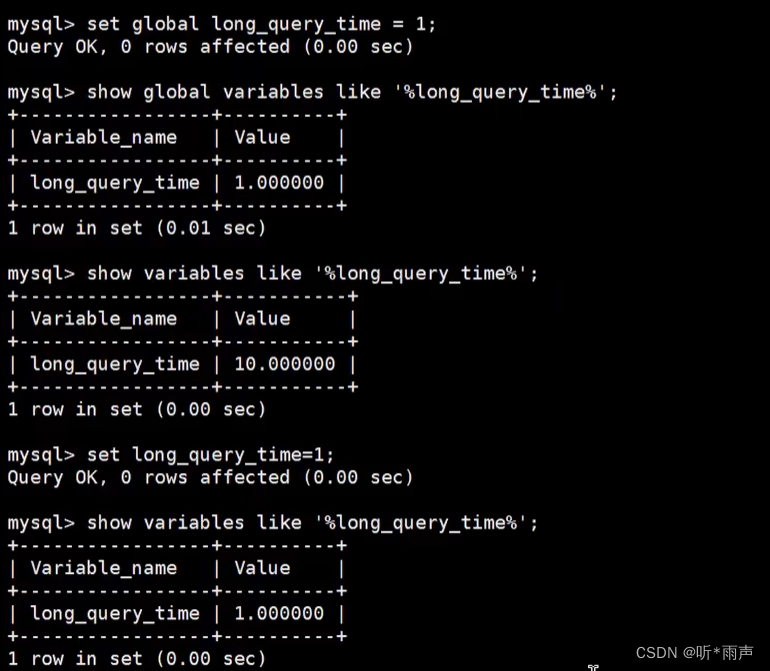
2. 修改long_query_time阈值 show variables like '%long_query_time%';
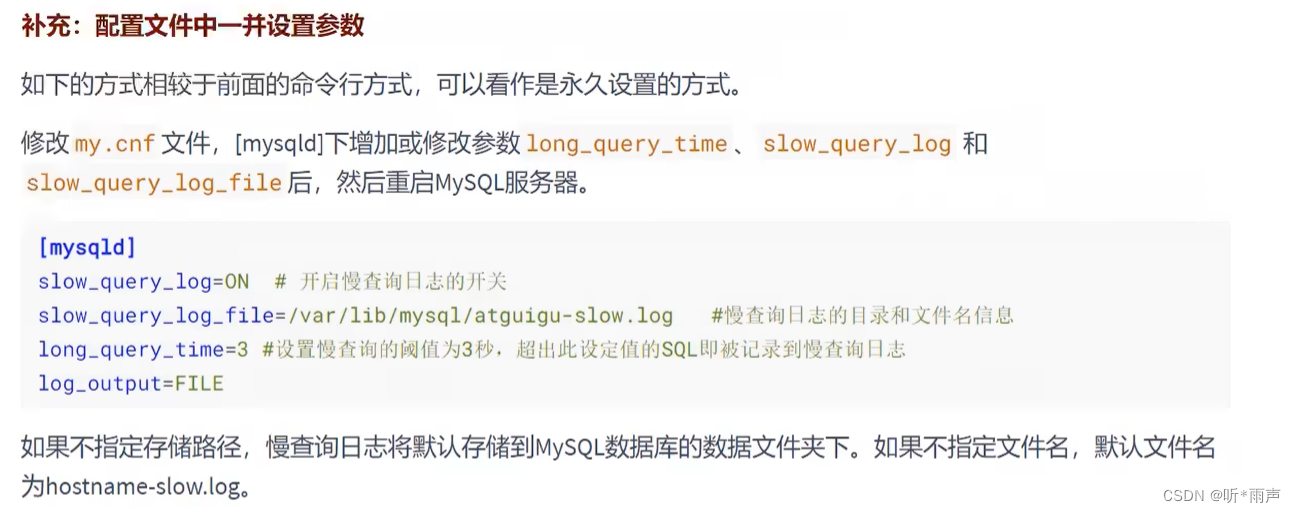
方式1:永久性方式 [mysqld] slow_query_log=OFF #或 [mysqld] #slow_query_log =OFF方式2:临时性方式 SET GLOBAL slow_query_log=off; 4.5 删除慢查询日志
EXPLAIN 或 DESCRIBE语句的语法形式如下: EXPLAIN SELECT select_options #或者 DESCRIBE SELECT select_options
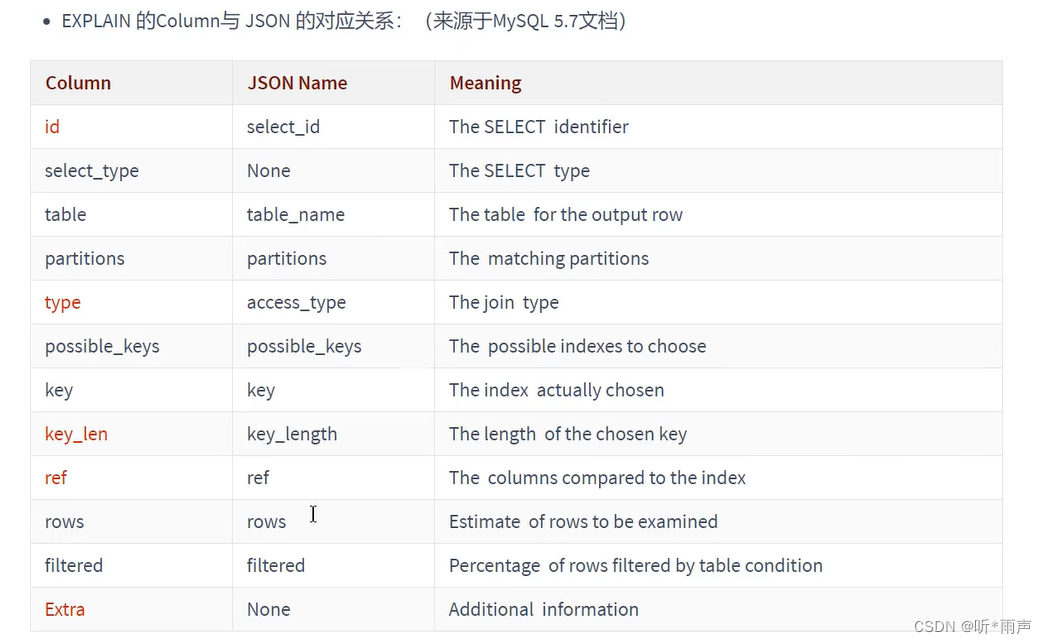
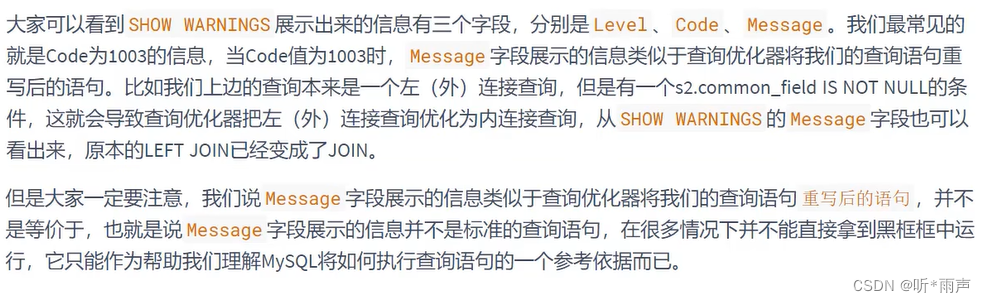
EXPLAIN 语句输出的各个列的作用如下: 列名描述id在一个大的查询语句中每个SELECT关键字都对应一个唯一的idselect_typeSELECT关键字对应的那个查询的类型table表名partitions匹配的分区信息type针对单表的访问方法possible_keys可能用到的索引key实际上使用的索引key_len实际使用到的索引长度ref当使用索引列等值查询时,与索引列进行等值匹配的对象信息rows预估的需要读取的记录条数filtered某个表经过搜索条件过滤后剩余记录条数的百分比Extra一些额外的信息 6.2 EXPLAIN各列作用1. table 不论我们的查询语句有多复杂,包含了多少个表 ,到最后也是需要对每个表进行单表访问的,所以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。 2. id id如果相同,可以认为是一组,从上往下顺序执行在所有组中,id值越大,优先级越高,越先执行关注点:id号每个号码,表示一趟独立的查询,一个sql的查询趟数越少越好3. select_type 4. partitions 5. type(重点) SQL性能优化的目标:至少要达到 range级别,要求是ref级别,最好是consts级别。(阿里巴巴开发手册要求) 6. possible_keys和key 7. key_len(重点) key_len的长度计算公式: varchar(10)变长字段且允许NULL = 10 * ( character set: utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段) varchar(10)变长字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段) char(10)固定字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL) char(10)固定字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)8. ref 当使用索引列等值查询时,与索引列进行等值匹配的对象信息。 比如只是一个常数或者是某个列。 9. rows(重点) 预估的需要读取的记录条数 值越小越好 10. filtered 11. Extra 这里谈谈EXPLAIN的输出格式。EXPLAIN可以输出四种格式:传统格式,JSON格式,TREE格式以及可视化输出。用户可以根据需要选择适用于自己的格式。 1. 传统格式
JSON格式:在EXPLAIN单词和真正的查询语句中间加上FORMAT=JSON。用于查看执行成本cost_info
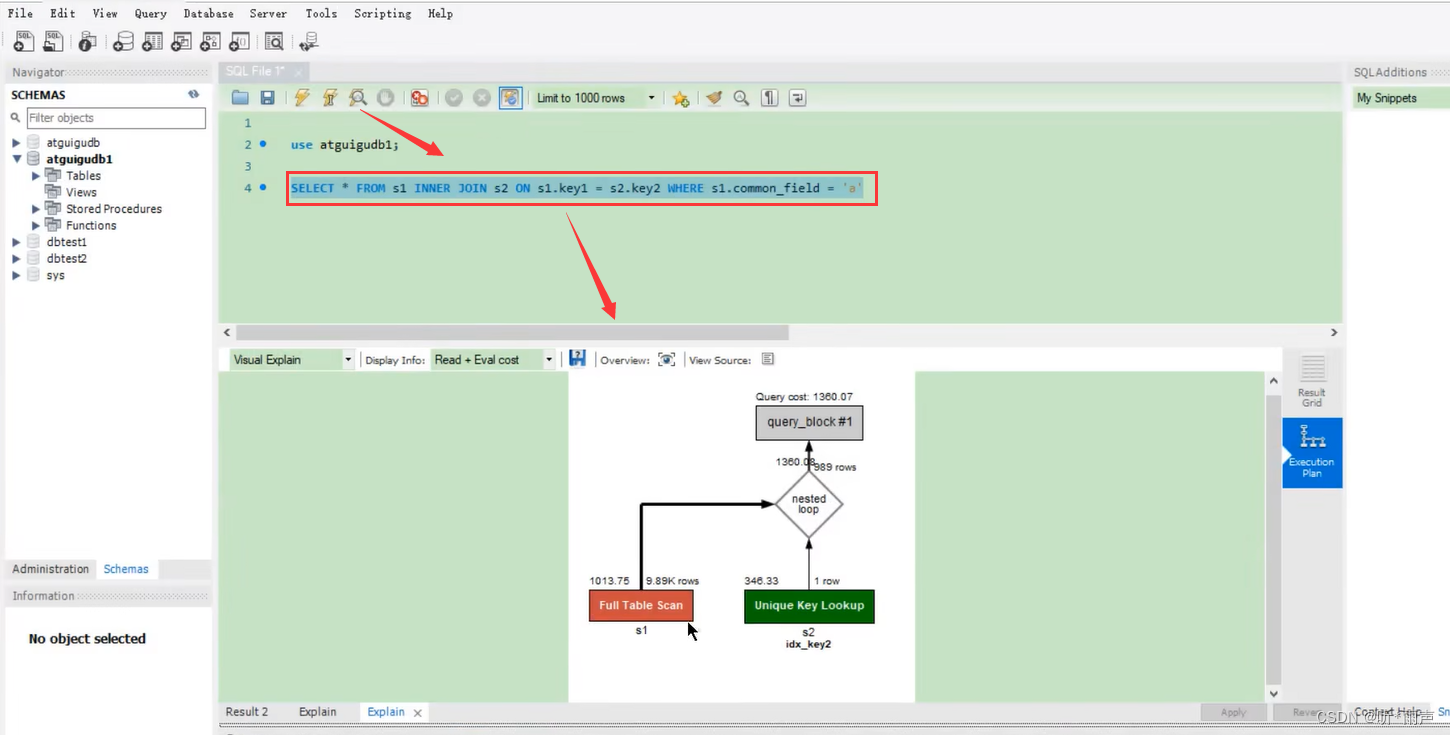
TREE格式是8.0.16版本之后引入的新格式,主要根据查询的各个部分之间的关系和各部分的执行顺序来描述如何查询。 4. 可视化输出可视化输出,可以通过MySQL Workbench可视化查看MySQL的执行计划。
IO相关 #1. 查看消耗磁盘IO的文件 select file,avg_read,avg_write,avg_read+avg_write as avg_io from sys.io_global_by_file_by_bytes order by avg_read limit 10;Innodb 相关 #1. 行锁阻塞情况 select * from sys.innodb_lock_waits;
|







 结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
























【本文地址】
今日新闻 |
推荐新闻 |