Stata 16 新功能之Lasso系列(二):Lasso Logit,Probit 与 Poisson |
您所在的位置:网站首页 › probit和oprobit › Stata 16 新功能之Lasso系列(二):Lasso Logit,Probit 与 Poisson |
Stata 16 新功能之Lasso系列(二):Lasso Logit,Probit 与 Poisson
|
其中, 为残差平方和(即 OLS 的目标函数), 为调节参数,控制惩罚的力度;而 为参数向量 的1-范数(L1 norm),
, 即回归系数的绝对值之和。 Lasso Probit 对于非线性模型,比如二值选择模型(probit,logit)、泊松回归(Poisson regression),传统上一般使用最大似然估计(MLE),即通过最大化对数似然函数,寻找最优的参数估计量。 以二值选择的 Probit 模型为例,其数据生成过程为
其中, 为标准正态分布的累积分布函数。由于 ,个体 i 的似然函数可紧凑地写为 其对数似然函数为 对所有观测值进行加总,可得整个样本的对数似然函数,即 MLE 的目标函数:
考虑到惩罚函数一般适用于最小化问题,可将 MLE 改写为等价的最小化问题,即最小化对数似然函数之负数:
在此最小化问题的基础上,Lasso Probit 加上了1-范数的惩罚函数:
其中,
为参数向量 的1-范数。依然为调节参数,控制惩罚的力度,一般通过“交叉验证”(Cross-validation)来确定。 Lasso Logit Lasso Logit 与Lasso Probit 类似,只不过将似然函数换为 Logit 模型。Logit 模型的数据生成过程为
其中, 为逻辑分布的累积分布函数,即 。根据类似的推导,Logit 模型的对数似然函数之负数为
相应的 Lasso Logit 的目标函数为
其中, 依然为调节参数,一般通过交叉验证来确定。 Lasso Poisson 泊松回归为“计数”(count data)模型,其被解释变量为非负整数。泊松模型的数据生成过程为
其中,泊松达到率(Possoin arrival rate)为 样本的似然函数可写为
其对数似然函数为
由于上式中的
与 无关,故 Lasso Poisson 的目标函数可写为
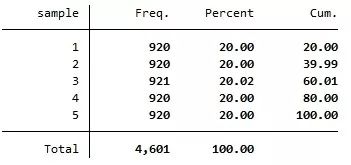
其中, 为调节参数,一般通过交叉验证来确定。 显然,以上非线性 Lasso 模型也可以推广到岭回归与弹性网模型。比如,对于岭回归,只要将1-范数改为2-范数,即可得到相应的Ridge Probit,Ridge Logit 与 Ridge Poisson 模型。 进一步,对于弹性网回归,只要混合使用1-范数与2-范数,即可得到相应的Elastic Net Probit,Elastic Net Logit 与 Elastic Net Poisson 模型,在此不再赘述。 Stata 实例 下面以 UCI Machine Learning Repository 的垃圾邮件(spam)数据集,演示 Lasso Logit 的操作(Lasso Probit与Lasso Poisson的操作类似,从略)。 该数据集包含 4601 封电子邮件的有关数据,被解释变量为 v58(=1 表示垃圾邮件,=0 表示正常邮件),而解释变量为 v1-v57(共57个解释变量),表示某些词汇或字母在邮件中出现的频率等。 首先,从 UCI 网站下载数据集。 . insheet using https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data,clear 由于此数据集较大,进行交叉验证比较费时,为了演示方便,首先将数据集随机地分为 5 等分。为保证结果可重复,首先设定随机数种子。 . set seed 123 其次,使用命令 splitsample 进行样本随机分割: . splitsample, gen(sample) nsplit(5) 其中,选择项“nsplit(5)”表示将样本随机地分为5等分;而选择项“gen(sample)”则表示,生成一个新变量 sample,取值为1-5,分别对应所生成的 5 个子样本。下面考察此变量 sample 的取值分布。 . tab sample
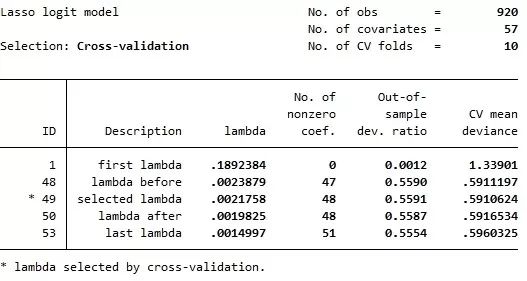
上表显示,变量 sample 的 5 个不同取值,对应于5个大致相等的子样本(但第 3 个子样本多一个观测值,因为样本容量 4601 不能被 5 整除)。 下面,使用命令 lasso logit 对第1个子样本(sample==1)进行回归,其基本格式与 reg 类似: . lasso logit v58 v1-v57 if sample==1, rseed(12345) selection(cv) nolog 其中,选择项“selection(cv)”表示使用交叉验证(默认为10折)选择最优的调节参数 ,而选择项“rseed(12345)”表示在将样本随机分为10折时,使用随机种子12345(可自行指定),便于重复结果。选择项“nolog”表示不显示交叉验证的过程。
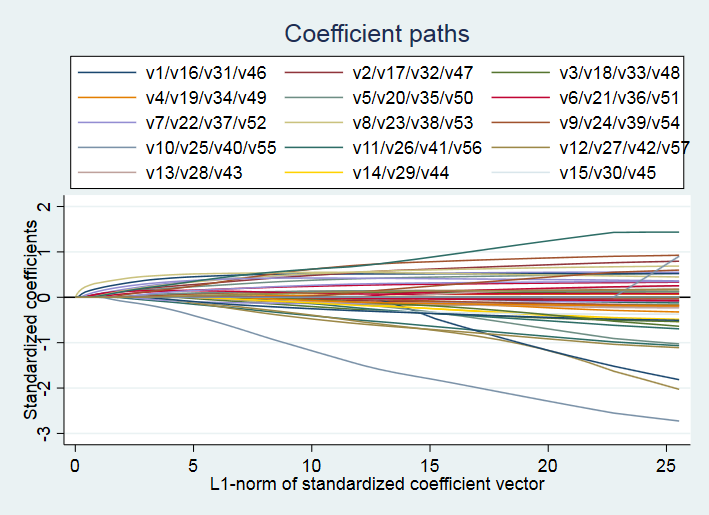
上表结果显示,根据10折交叉验证(No. of CV folds = 10),调节参数 的最优取值为 0.0021758,共有48个非零回归系数(nonzero coef.)。相应的“样本外偏离率”(Out-of-sample deviance ratio)为0.5591。“偏离度”(deviance)的定义为 (-2) 乘以对数似然函数,而偏离率(deviance ratio)则等价于计量经济学中常用的“准 ”(Pseudo R2)。 下面,使用命令 coefpath 来画 lasso logit 的系数路径(coefficient paths): . coefpath, legend(on position(12) cols(3)) 其中,选择项“legend(on position(12) cols(3))”表示将图例(legend)放在 12 点钟的位置(即图像正上方),并以3列(columns)来表示。
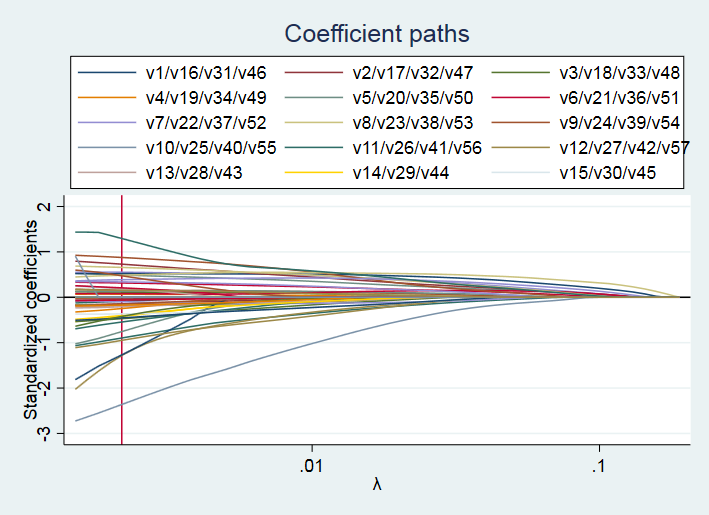
命令 coefpath 默认将 1-范数(L1-norm)作为横轴来画系数路径。显然,当限制参数向量的1-范数为 0 时,则所有系数均为 0;而当1-范数足够大时,则为通常的 Logit 估计(对于低维数据而言)。 如果想以调节参数 (log scale,对数尺度)作为横轴来画系数路径,并在最优值 0.0021758 处画一条直线,可使用如下命令: . coefpath, legend(on position(12) cols(3)) xunits(lnlambda) xline(.0021758)
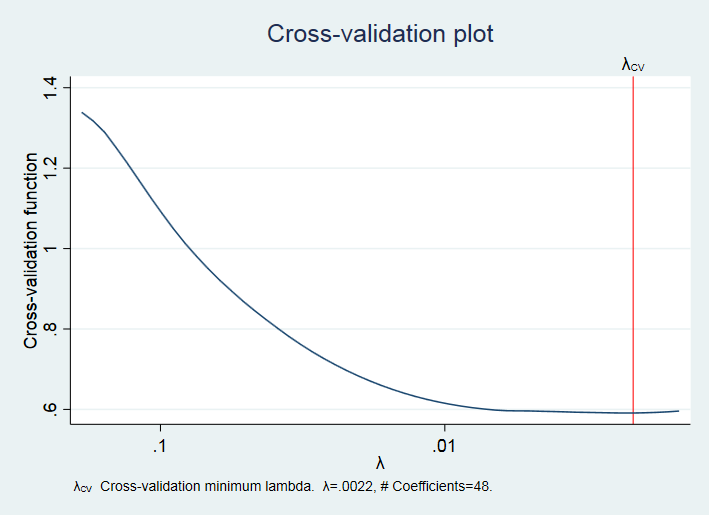
从上图可知,当惩罚力度 = 0 时,即为 Logit 估计;而当 足够大时,惩罚过于严厉以至于所有回归系数均为 0。 进一步,可以画“交叉验证图”(CV Plot)。 . cvplot
上图给出了调节参数 的最优值 ,即使得函数 最小的 值。从上图可知,在最优值 附近,函数 非常平坦,这意味着在最优值附近变化 ,对于模型预测能力的影响很小。 如想显示 lasso logit 的回归系数,可使用命令 . lassocoef, display(coef) sort(coef) 其中,选择项“display(coef)”表示显示回归系数(默认仅显示非零系数的变量名),而选择项“sort(coef)”表示将变量按照系数的绝对值从大到小排列。
以上显示的回归系数事实上为“标准化”(standardized)之后的系数。对于惩罚回归而言,变量的单位或变化幅度对回归结果有本质影响,故一般在进行Lasso 系列的回归之前,须先将所有解释变量进行标准化,即减去样本均值,再除以样本标准差,使得每个变量的均值都为 0,而标准差均为 1。 如果想显示标准化之前的回归系数,可使用命令 . lassocoef, display(coef,penalized) sort(coef,penalized)
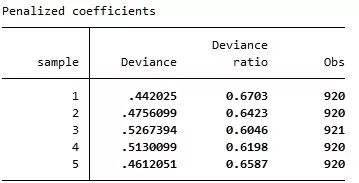
下面考察根据第1个子样本(sample== 1)所估计的Lasso Logit模型对于数据的拟合程度。 . lassogof, over(sample) 其中,“lassogof”表示“lasso goodness of fit”。而选择项“over(sample)”表示根据变量sample 的不同取值,分别评估模型的拟合优度。
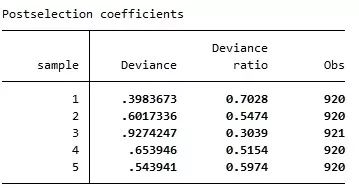
上表结果显示,对于“sample == 1”的子样本,模型的拟合优度最好,Deviance ratio 达到0.6703,因为这是“样本内拟合”(in-sample fit)。而对于其他子样本(sample ==2, 3, 4, 5),则 Deviance ratio 更低些,因为这些是“样本外拟合”(out-of-sample fit),通常更为困难。 也可以考察Post-lasso Logit的拟合优度,即通过Lasso Logit 选出系数非零的变量,然后使用这些选出的变量进行通常的Logit回归所得的拟合优度。 . lassogof, over(sample) postselection 其中,选择项“postselection”表示使用选出的变量再进行 Logit 回归。
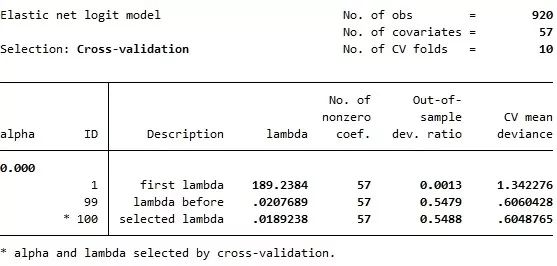
从上表可知,使用“Post-selectioncoefficients”进行预测,虽然可使样本内(第1个子样本)的拟合优度上升,但其样本外(第2-5个子样本)的预测能力反而下降了。 下面进行 Ridge Logit 回归,即在Logit 回归中加入2-范数的惩罚项。由于岭回归相当于 =0 的弹性网估计,故其命令为: . elasticnet logit v58 v1-v57 if sample==1, alpha(0) selection(cv) rseed(12345)
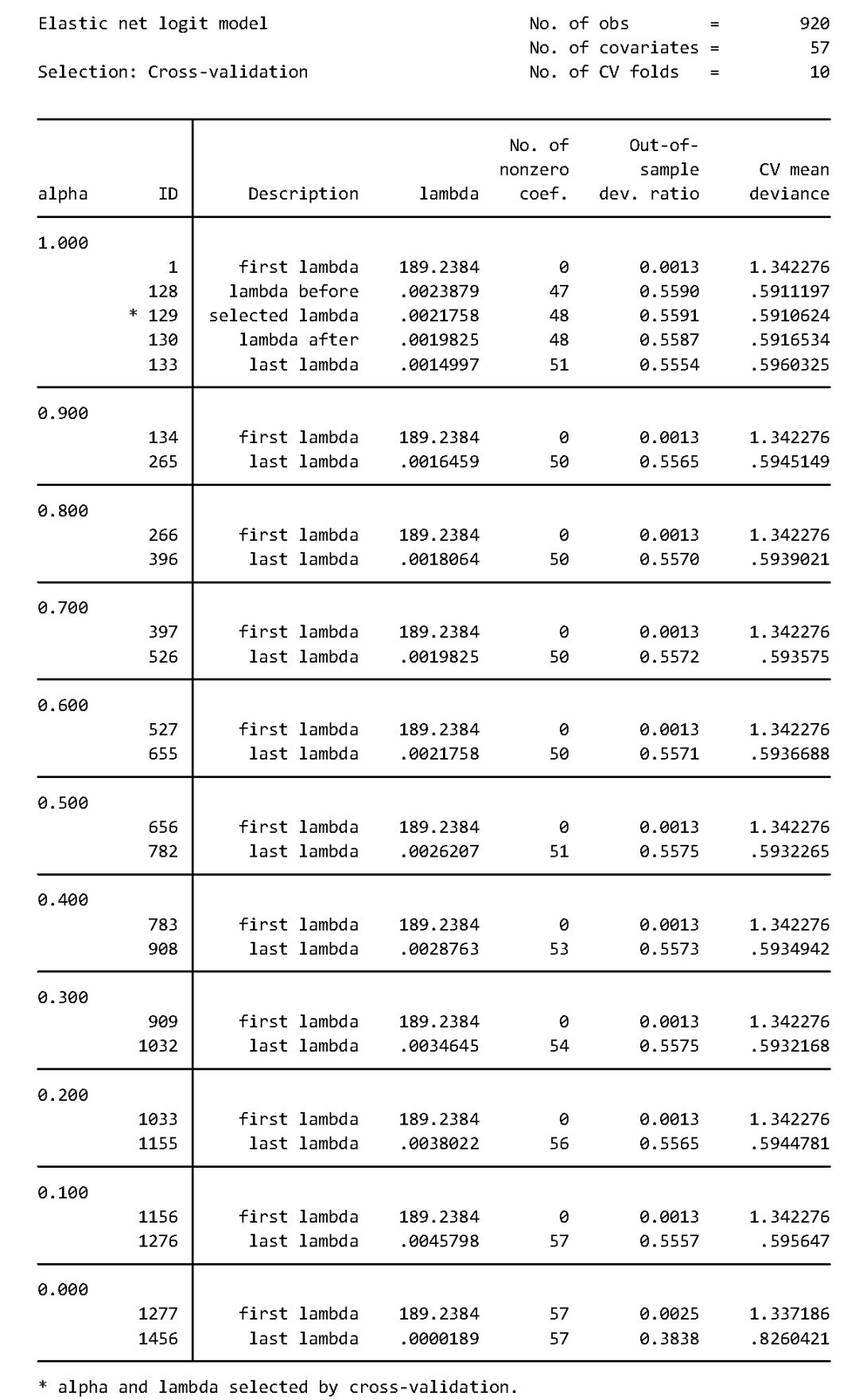
由上表可知,Logit 岭回归选择了全部的57个解释变量,但 out-of-sample deviance ratio(等价于准 R2)比 Lasso Logit 略低,故预测效果不如 Lasso Logit。 下面进行一般的弹性网估计: . elasticnet logit v58 v1-v57 if sample==1,alpha(0(0.1)1) selection(cv) rseed(12345) 其中,选择项“alpha(0(0.1)1)”表示对调节参数 ,以0.1为间隔,从0(对应于 Ridge)到1(对应于 Lasso)进行搜索。
上表结果显示,交叉验证选择了 =1 而 = 0.0021758,故对于这个数据集而言,Lasso Logit 的预测效果最佳。 从以上各种回归结果可以看出,无论使用线性 Lasso,还是非线性 Lasso,均无法给出系数的标准误(Standard Errors)。那么,应该如何进行统计推断呢? 幸运的是,Stata 16 的 Lasso 系列命令在这方面已经走到了学术的最前沿。我们将在下期推文继续介绍有关 Lasso的统计推断,即 Lasso Inference,敬请期待。 备注:本公众号不提供 Stata 16。如需正版 Stata 16,请咨询 Stata 软件官方授权经销商及合作伙伴:北京友万信息科技有限公司(www.uone-tech.cn),Tel/Wechat:18610597626,徐老师。 参考文献 陈强,《高级计量经济学及Stata应用》,第2版,高等教育出版社,2014年 陈强,《计量经济学及Stata应用》,高等教育出版社,2015年(好评如潮的配套教学视频,可在网易云课堂购买) 陈强,《机器学习及R应用》,高等教育出版社,2020年(即将出版) 陈强老师亲授“高级计量经济学与Stata应用”2019年国庆节(10月1-6日)现场班占座开启,详情可点击页底“阅读原文”或请联系(根据缴费顺序安排座位哦): 魏老师 QQ:2881989714 Tel:010-68478566 Mail:[email protected] We chat:13581781541 陈强老师简介
陈强,男,1971年出生,山东大学经济学院教授,数量经济学博士生导师。 分别于1992年、1995年获北京大学经济学学士、硕士学位,后留校任教。2007年获美国Northern Illinois University数学硕士与经济学博士学位。已独立发表论文于Oxford Economic Papers (lead article), Economica, Journal of Comparative Economics,《经济学(季刊)》、《世界经济》等国内外期刊。著有畅销研究生教材《高级计量经济学及Stata应用》与本科教材《计量经济学及Stata应用》,以及好评如潮的本科计量教学视频(网易云课堂)。2010年入选教育部新世纪优秀人才支持计划。 (c) 2019, 陈强,山东大学经济学院 www.econometrics-stata.com 转载请注明作者与出处 Our mission is to make econometrics easy, and facilitate convincing empirical works.返回搜狐,查看更多 |
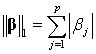
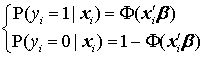
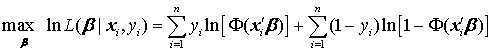
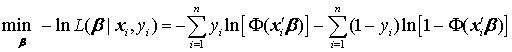
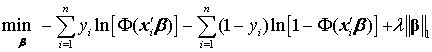
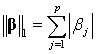
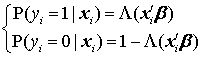
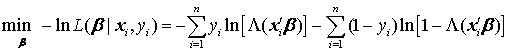
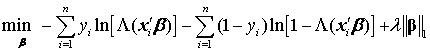
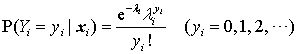
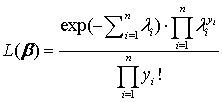
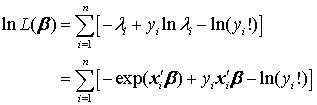
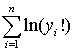
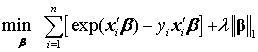



【本文地址】