Pregel:一个大规模图计算系统 |
您所在的位置:网站首页 › pregel怎么读音 › Pregel:一个大规模图计算系统 |
Pregel:一个大规模图计算系统
|
本文不是原文翻译,但是包含所有重点的内容。查看原论文请点击此链接 1.简介 1.1 为什么开发 Pregel 为每一种图算法都定制开发一个分布式程序需要非常大的工作。现有的分布式计算平台不能满足图计算的需求。像 MapReduce 可以处理非常大的数据量,但是处理图计算的性能稍差。用单机版本的图算法限制了能处理的图的规模。现有的并行图计算系统没有容错能力。容错能力对大数据系统非常重要。块同步并行 (Bulk Synchronous Parallel) 模型的启发 Pregel 的框架组织。 Pregel 的计算由一系列的迭代组成,每步迭代叫一个超级步(superstep)。在一个超级步中,框架为每一个顶点并行执行用户的自定义函数。函数有顶点信息 V 和超级步 S 信息,可以读取 S-1 步发送过来的信息,并且可以发送信息给其他顶点,这些信息会在 S+1 步收到。 2. 计算模型在 Pregel 计算中,输入是一个有向图。每一个顶点都有一个唯一标识,标识的类型是字符串。每一个顶点都包含一个用户定义的,可以修改的对象,代表顶点的值(value)。 有向边和边的起始顶点在一起。每个边也有一个用户定义的值,和目的顶点的标识符。 一个典型的 Pregel 计算过程包括(1)当图被初始化时的图数据输入。(2)一些被全局同步点分割开的超级步,这些超级步执行迭代计算,直到计算结束。(3)计算结束时的结果输出。 计算是否结束是根据每个顶点的投票。在超级步 0,每个顶点都是活动状态。活动状态的顶点参加本超级步的计算。一个顶点可以通过投票停止计算来使自己变成不活动状态。在以后的超级步计算中,这个顶点就不在参加计算,除非它收到信息后,又变成活动状态。 再次变成活动状态后,需要投票使自己变成不活动状态。整个计算在所有顶点都处于非活动状态时才停止。 我们不用远程读,也不使用共享内存。第一、因为信息传递模式足够了,不需要远程读。我们没有发现哪个图的算法,用信息传递的方式不能满足。第二、在集群环境中,从远程服务器中读取数据有非常大的延迟。我们通过异步的批量传递信息的方式来减少整体延迟。 图计算可以用一系列的 MapReduce 来计算。因为可用性和性能的原因,我们不选用。Pregel 在整个计算过程中,把顶点和边一直保存在服务器内存中。MapReduce 需要在每个 MapReduce 任务中重新构建顶点和边。这样需要传递更多的数据。 3. 计算API 3.1信息传输用户需要实现 compute() 方法,框架会为每个活动的顶点调用 compute 方法。在此方法内,用户可以用 getValue 得到此顶点的值,setValue 来给顶点重新赋值。 // T: vertex value type // M: Message type send to target vertex. class Vertex { public void compute(MessageIterator messages); String getVertexID(); int getCurrentSuperStep(); T getValue(); void setValue(T newValue); OutEdgeIterator getOutEdgeIterator(); void sendMessageTo(String descVertex, M messageValue); }通常一个顶点会遍历以它为源顶点的边,发送信息给边上的目标顶点。但是在 sendMessageTo 信息时,=descVertex 不一定非的是这个顶点的邻居。 当信息传递的目的顶点不存在时,我们执行用户定义的 handler。这个 handler 可以创建没有的顶点,也可以把起始顶点中,没有目标顶点的边删除。 3.2 Combiners可以通过 Combiners 减少发送数据和缓存数据的代价。假设发送的数据是数值型,到达目标顶点后会被加在一起。那么可以把这些值合并成一个值,然后再发送或者保存。Combiner 不是必须的,如果实现 Combiner,需要满足交换律和结合律,因为不能保证 Combiner 的调用这些值的顺序。 可以发现在最短路径中,用 Combiner 后,发送的数据量只有不用 Combiner 的四分之一。 3.3 AggregatorsAggregators 用来做全局通信。每个顶点可以在超级步S中提供一个值给Aggregator。系统会把这些值合并计算成一个结果值。这个值会让所有顶点在S+1步看到。Pregel提供了一些内置的 Aggregator,如 min, max, sum. Aggregators 可以用来做统计。如用 sum aggregator,每个顶点都输出它的出度。在 S+1 步,可以得到图中所有边的个数。 Aggregators 可以用来做全局协调。如当 aggregator 中计算出所有顶点满足一定条件时,在 Compute 方法里执行另一段逻辑。 定义一个新的 Aggregator,需要继承 Aggregator类,并且计算要满足交换律和结合律。 默认情况下,Aggregator 的值只能在下一个超级步可以看到。用户也可以定义粘(sticky)的 Aggregator。粘(sticky)的 Aggregator 的值可以在所有超级步里得到。 如顶点和边的数量可以定义为粘(sticky)的Aggregator. Aggregator 有更高级的用法。如可以用来实现分布式的优先级队列。在超级步中,每个顶点输出 minimum 距离。合并后的 minimum 会在下一个超级步被广播到所有的服务器。 3.4 修改图的拓扑结构一些图算法需要修改图的拓扑。一个聚类算法,可能用一个顶点来代表一个类别。最小生成树算法只保留树的边,其他的边都删除。 在一个超级步中,多个顶点可能发起有冲突的请求。如两个请求增加顶点V,每个请求的值不相同。我们用两种机制:偏序和 handlers。 和消息传递一样,修改图的拓扑结构也在请求发出后的下一个超级步生效。在超级步里,先做删除操作。做删除操作时,先删除边,再删除顶点,因为删除顶点隐含了把它所有的出边都删除。删除做完再做增加操作,先增加顶点,再增加边。所有图的修改操作在调用 compute() 之前, 偏序解决了大部分的冲突问题。 剩余的冲突问题通过用户定义的 handlers 解决。比如在一个超级步里,有数个创建相同的顶点的请求。默认情况下,系统会随机选一个。用户可以在 handler 里,接收所有的相同顶点的请求,然后进行处理。增加边和删除边也是同样的道理。为了保持 Vertex 的代码简单, handlers 的定义不和Vertex在一起。 Pregel 也支持纯本地修改。如一个顶点增加或者删除以它为源顶点的边。本地计算不会有冲突问题,所以本地修改立即生效。 3.5 输入和输出存储图的格式有很多种。Pregel 为一些常见文件提供了readers 和 writers。如果不能满足需求,用户可以继承 Reader 和 Writer 类,自己实现图的读写程序。 4实现Pregel 在 Google 的集群上运行,文件存储在 GFS 上或者在 BigTable 里。 4.1基础架构Pregel 把图分成若干分区,每个分区有一些顶点和以这些顶点为源顶点的所有边。 仅用顶点的 ID 来决定该顶点属于哪个分区。默认用 hash(ID) mod N 的方法,N 是分区的数量。用户可以使用自定义的分区策略,如 Web 图把相同的站点的页面放在同一个分区里,可以减少远程发送的信息量。 在不考虑故障恢复的情况下,Pregel 程序的执行包含以下几个步骤: 多个用户程序开始在集群上并行执行。 其中一个用户程序作为 Master 的角色。Master 不处理任何图数据,仅仅是协调工作。Workers 负责真正图的计算。Master 决定图有多少个分区,并且决定每个 worker 处理那些分区。一个 worker 处理多个分区可以更好的负载均衡,并且会提高性能。每个 Worker 负责维护它负责的这部分图的状态,执行用户的compute方法,并且管理 Workers 之间的消息传递。在数据加载过程中,Master 为每个 worker 分配一部分用户的输入数据。这部分数据和在超级步里处理的数据没有关系。是从GFS或其他地方分布式加载的数据。依次读取数据,如果数据属于本 Worker 处理,就更新相关数据。如果数据属于其他 Worker 处理,则通过异步批量的方式发送给其他 Worker。Master给每个 Worker 发送执行超级步的指令。Worker 为每个分区分配一个线程。在此线程里,查找活动的顶点,然后调用 compute 方法,并且提供上个超级步里发送给该顶点的信息。信息是异步发送的,可以平衡计算和发送数据,但是在本超级步结束之前,要把数据都发送完。每个超级步执行后,都向Master汇报还有多少个顶点处于活动状态。当计算全部结束时,Master可能给每个 Worker 发送指令,保存结果。 4.2 故障恢复故障恢复是通过检查点实现的。在一个超级步执行之前,Master 给 Workers 发送指令,来保存他们的分区到持久存储上。包含顶点值,边的值,和顶点的输入信息(上一个超级步输出的)。Master存储Aggregator 信息。 Worker 的失效通过周期性的心跳来解决。如果 Worker 超过一定时间没有收到来自Master的心跳信息,Worker 就结束自己的进程。如果Master超过一定时间没有收到来自 Worker 的心跳信息,Master认为该 Worker 失败。 当一个或者多个 Worker 失效时,分配给这些 Workers 的分区信息丢失。Master 从最后的检查点重新分配图分区信息到存活的 Workers。假设最后的检查点在 S’ 步,现在执行到 S 步。S’ 可能比S早好几个超级步。我们根据平均失败模型来选择执行检查点的频率,平衡执行检查点的代价和恢复的代价。 细力度的恢复正在开发中。在细力度的恢复中,除了基本的检查点外,Workers 也保存所有的输出信息到本地磁盘。这些输出信息包括在加载图时向其他 Workers 输出的信息,和在每个超级步时输出到其他 Workers 的信息。系统可以重新计算到超级步S’。 保存输出信息增加了开销,但是一般服务器上都有足够的磁盘带宽,保证 IO 不会成为瓶颈。本方法只用计算丢失的分区。 细力度的恢复需要用户程序的输出是确定性的。如果程序中用到了随机化,那么可以用超级步编号和分区作为Key来生成随机数。非确定性的算法可以禁用细粒度的恢复,仅使用基本的基于检查点的恢复。 4.3 Worker 的实现Worker 在内存中保存它的这一部分图的数据。数据包含顶点ID到顶点状态的映射。顶点状态包含它的当前值,出边的列表,包含输入信息的队列和确定顶点是否处于活动状态的标识。出边的列表中每个元素包含目的顶点和边的值。当 Worker 执行超级步时,它依次为每个活动顶点执行 compute 方法,传递相关信息。 因为性能的原因,活动顶点的标识和输入信息队列分开存储。并且,仅存储一份顶点和边的信息。存储两份活动顶点信息和输入信息队列。一份是给当前超级步用,一份为下一超级步用。如果节点V收到信息,那么V会变成活动的,当前状态可能不是活动的。(注:当前超级步执行时,会收到下一超级步用到的信息。一个超级步执行结束前,信息会发送结束。所以本次超级步执行的时候,本超级步需要的信息已经到达。本次超级步执行的时候,会收到下一超级步需要的信息)。 当 compute() 请求给其他顶点发送信息时,先判断目标顶点是否是在同一个Worker里。如果是,则直接放到目标顶点的输入信息队列里。如果是远程Worker,则放到一个缓冲区里,如果缓冲区写入的数据达到一定阈值,则异步的写到远程Worker里。 当定义Combiner时,会在放到本地目标顶点的输入信息队列时调用,或者远程Worker接收到这些数据时调用。虽然不能减少网络发送的数据量,但是可以减少内存开销。 4.4 Master的实现Master主要负责协调 Workers 的活动。每个 Worker 在向 Master 注册时,分配一个唯一的标识。Master 维护一个活动的 Workers 列表。包含 Worker 的标识,它的地址信息,负责哪一部分图计算信息。 Master 的数据量和分区的数量相关,和顶点和边的数量无关,所以 Master 可以为很大的图做协调计算。 大部分Master操作,包括输入,输出,计算,保存检查点,从检查点恢复,都在栅栏(barriers)处结束。Master发送同样的请求到各 Worker ,并且等待 Worker 响应。如果 Worker 失败,Master 进入 4.2 节描述的恢复模式。如果栅栏同步成功,Master进入下一个阶段,例如在计算过程中,Master 会增加全局超级步编号,并且进入下一超级步。 Master 还保存关于计算过程的统计信息,和图的状态信息,如图的大小,顶点的出度分布,活动顶点的数量,最近超级步的运行时间和发送的信息量。为了用户监控,Master 运行一个 HTTP 服务用于显示这些信息。 4.5 AggregatorsAggregator 通过计算汇聚函数,把用户函数输出的值,合并为一个全局的值。每一个 Worker 有 Aggregator 实例的集合,Aggregator 实例用它的类型名和实例名标识。当 Worker 在执行一个超级步时,会合并 Aggregators 的所有数据为一个本地数据。在超级步计算结束时,把本地数据发给Master,然后合并成一个全局数据。Master 在下一个超级步开始前,把全局数据发送给所有 Worker。 5. 应用 5.1 PageRank以 PageRank 为例,探讨下 Pregel 的实现方法。首先,我们实现PageRankVertex 类,继承 Vertex. 顶点用一个 double 来存储当前的PageRank 值。因为边不存储数据,边的类型是 void。我们设置 Graph 在超级步 0 初始化,每个顶点的值是1/NumVertices()。 class PageRankVertex : public Vertex public void Compute(MessageIterator msgs) { if (superstep() >= 1) { double sum = 0; for (Message msg : msgs) { sum += msg.getValue(); } this.value =0.15 / getNumOfVertices() + 0.85 * sum; } if (superstep() < 30) { int outSize = getOutEdgerIterator().getSize(); sendMessageToAllNeighbors(this.value / n); } else { voteToHalt(); } }从超级步1开始,每个顶点把发送过来的值都加到 sum 里。并且设置临时的 PageRank 值为 0.15 / getNumOfVertices() + 0.85 * sum。到达超级步 30 后,不再发送信息,并且投票结束。实际运行中,PageRank 算法可能会一直计算到收敛。 5.2 最短路径为了简单明了,我们主要关注单源最短路径,即从一个顶点出发,到所有其他顶点的最短路径。 class ShortestPathVertex extends Vertex { public void Compute(MessageIterator msgs) { int mindist = isSource(this.getVertexID()) ? 0 : Integer.MAX_VALUE; for (Message msg : msgs) { mindist = Math.min(mindist, msg.getValue()); } if (mindist < this.getValue()) { this.setValue(mindist); } OutEdgeIterator iter = this.getOutEdgeIterator(); for (OutEdge outEdge: iter) { sendMessageTo(outEdge.getTarget(), mindist + outEdge.getValue()); } voteToHalt(); } } class MinIntCombiner extends Combiner { public void combine(MessageIterator msgs) { int mindist = Integer.MAX_VALUE; for (Message msg : msgs) { mindist = Math.min(mindist, msg.getValue()); } output("combined_source", mindist); } }在这个程序里,我们把每个顶点的初始距离都是 Integer.MAX_VALUE。在每一超级步,每个顶点先接收从上游邻接顶点发过来的信息。用最小的值更新当前的值,然后更新它的下游邻接顶点。依次类推,此算法会在没有更新时结束。 本算法有一个 Combiner 来减少 Worker 之间传输的数据量。 6. 实验我们进行了各种最短路径的测试,这些测试运行在由 300 台多核通用服务器组成的集群上。我们报告了二叉树的运行时间(研究可扩展的特性),和用不同图大小的对数正态分布的随机图,对数正态分布的随机图的所有边的权重都设置为 1。 初始化集群时间、在内存中生成测试图的时间、和验证结果的时间是不包括在度量信息里。因为这些实验都运行相对较短的时间,失败的可能性很低,所以我们禁用检查点。 作为Pregel和计算任务数量之间的可扩展性的一个指示图,图7显示计算由10亿顶点二叉树组成的最短路径的运行时间。Pregel 的计算任务的数量从 50 提高到 800,运行时间从 174 秒减少到 17.3 秒。用了 16 倍的计算任务,性能提升差不多 10 倍。 为了展示 Pregel 和图大小之间的可扩展性。图8展示了从 10 亿顶点到 500 亿顶点等不同大小组成的二叉树的最短路径的运行时间。这些测试固定用 800 个计算任务,运行在由 300 台多核服务器组成的集群上。运行时间从 17.3 秒到 702 秒显示了低出度图的运行时间和图大小成比例。 Pregel 是一个分布式的编程框架,关注于为用户提供一个自然的图计算 API,并且隐藏分布式的一些细节,如信息传输和故障恢复。在概念上,它和 MapReduce 很相似,但是提供了更加自然的图 API, 对图的迭代计算更高效。Pregel 和 Sawzall[41]、Pig Latin[40]、Dryad[27, 47] 不同,因为Pregel 隐藏了数据的分布细节。 Pregel 还有一点不一样,因为它实现了一个有状态的模型,它用一个长驻进程来实现计算、交换信息、修改本地状态,而不是用一个数据流模型。数据流模型只做基于输入的计算,然后产生输出数据。输出的数据被其他任务接着计算。 8. 总结和下一步工作本论文贡献了一个大规模图计算的模型,并且表示了它的产品特性、扩展性、故障恢复的实现。 基于我们用户的反映,我们认为此模型非常有用并且方便易用。已经部署了数十个 Pregel 应用程序,更多的正在设计、实现和调优。用户反映一旦转换为“像顶点一样思考”的编程模式,这些 API 变得直观、灵活、并且易于使用。我们和最初的使用者密切合作,这些最初的使用者会影响 API 的设计,这一点不奇怪。例如,增加 Aggregators 来减少一些早期 Pregel 的一些限制。 Pregel 的性能、可扩展性和故障恢复已经可以满足数十亿顶点的图计算。我们正在研究可以扩展到更大规模的图计算技术,像降低模型的同步,避免运行速度快的任务必须在超级步间的同步点经常等待的问题。 当前全部的计算状态保存在内存中。 我们已经溢写一些数据到磁盘,并且将继续沿着这个方向进行开发,目的是在未来能使在没有数 T 的内存的情况下仍可以进行大图的计算。 为服务器分配顶点并且最小化服务器之间的信息传输是一个挑战。当拓扑能和信息流对应时,基于拓扑对输入数据进行分区也许足够,但是并不总是这样。我们想设计动态重新分区的机制。 Pregel 是为稀疏图设计的,主要是沿着边进行通信。尽管已经非常谨慎的支持高扇出、高扇入的信息流,但是当绝大部分顶点都和其他的大部分顶点进行通信时,性能会下降。一些类似的算法可以用 Combiners、Aggregators、或者修改图来编写Pregel友好的算法。当然类似的计算对于任何的高度分布式的计算都困难。 一个比较实际的担心是Pregel正在变为生产环境中基础架构的一部分。我们不能随意的改变 API,我们需要考虑兼容性。尽管如此,我们认为我们设计的编程接口足够抽象和灵活,对未来底层系统有较好的适应能力。 9. 声明我们特别感谢 Pregel 的早期使用者,我们还感谢 Pregel 的所有使用者对 Pregel 的反馈和提出的建议。 10. 参考文献[1] Thomas Anderson, Susan Owicki, James Saxe, and Charles Thacker, High-Speed Switch Scheduling for Local-Area Networks. ACM Trans. Comp. Syst. 11(4), 1993, 319-352. [2] David A. Bader and Kamesh Madduri, Designing multithreaded algorithms for breadth- rst search and st-connectivity on the Cray MTA-2, in Proc. 35th Intl. Conf. on Parallel Processing (ICPP’06), Columbus, OH, August 2006, 523|530. [3] Luiz Barroso, Jerey Dean, and Urs Hoelzle, Web search for a planet: The Google Cluster Architecture. IEEE Micro 23(2), 2003, 22-28. [4] Mohsen Bayati, Devavrat Shah, and Mayank Sharma, Maximum Weight Matching via Max Product Belief Propagation. in Proc. IEEE Intl. Symp. on Information Theory, 2005, 1763-1767. [5] Richard Bellman, On a routing problem. Quarterly of Applied Mathematics 16(1), 1958, 87-90. [6] Olaf Bonorden, Ben H.H. Juurlink, Ingo von Otte, and Ingo Rieping, The Paderborn University BSP (PUB) Library. Parallel Computing 29(2), 2003, 187{207. [7] Sergey Brin and Lawrence Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine. in Proc. 7th Intl. Conf. on the World Wide Web, 1998, 107-117. [8] Albert Chan and Frank Dehne, CGMGRAPH/CGMLIB: Implementing and Testing CGM Graph Algorithms on PC Clusters and Shared Memory Machines. Intl. J. of High Performance Computing Applications 19(1), 2005, 81-97. [9] Fay Chang, Jerey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber, Bigtable: A Distributed Storage System for Structured Data. ACM Trans. Comp. Syst. 26(2), Art. 4, 2008. [10] Boris V. Cherkassky, Andrew V. Goldberg, and Tomasz Radzik, Shortest paths algorithms: Theory and experimental evaluation. Mathematical Programming 73, 1996, 129-174. [11] Jonathan Cohen, Graph Twiddling in a MapReduce World. Comp. in Science & Engineering, July/August 2009, 29-41. [12] Joseph R. Crobak, Jonathan W. Berry, Kamesh Madduri, and David A. Bader, Advanced Shortest Paths Algorithms on a Massively-Multithreaded Architecture. in Proc. First Workshop on Multithreaded Architectures and Applications, 2007, 1-8. [13] John T. Daly, A higher order estimate of the optimum checkpoint interval for restart dumps. Future Generation Computer Systems 22, 2006, 303{312. [14] Jerey Dean and Sanjay Ghemawat, MapReduce: Simpli ed Data Processing on Large Clusters. in Proc. 6th USENIX Symp. on Operating Syst. Design and Impl., 2004, 137-150. [15] Edsger W. Dijkstra, A Note on Two Problems in Connexion with Graphs. Numerische Mathematik 1,1959, 269-271. [16] Martin Erwig, Inductive Graphs and Functional Graph Algorithms. J. Functional Programming 1(5), 2001, 467-492. [17] Lester R. Ford, L. R. and Delbert R. Fulkerson, Flowsin Networks. Princeton University Press, 1962. [18] Ian Foster and Carl Kesselman (Eds), The Grid 2: Blueprint for a New Computing Infrastructure (2nd edition). Morgan Kaufmann, 2003. [19] Sanjay Ghemawat, Howard Gobio, and Shun-Tak Leung, The Google File System. in Proc. 19th ACM Symp. on Operating Syst. Principles, 2003, 29-43. [20] Michael T. Goodrich and Roberto Tamassia, Data Structures and Algorithms in JAVA. (second edition). John Wiley and Sons, Inc., 2001. [21] Mark W. Goudreau, Kevin Lang, Satish B. Rao, Torsten Suel, and Thanasis Tsantilas, Portable and Ecient Parallel Computing Using the BSP Model. IEEE Trans. Comp. 48(7), 1999, 670-689. [22] Douglas Gregor and Andrew Lumsdaine, The Parallel BGL: A Generic Library for Distributed Graph Computations. Proc. of Parallel Object-Oriented Scienti c Computing (POOSC), July 2005. [23] Douglas Gregor and Andrew Lumsdaine, Lifting Sequential Graph Algorithms for Distributed-Memory Parallel Computation. in Proc. 2005 ACM SIGPLAN Conf. on Object-Oriented Prog., Syst., Lang., and Applications (OOPSLA’05), October 2005, 423{437. [24] Jonathan L. Gross and Jay Yellen, Graph Theory and Its Applications. (2nd Edition). Chapman and Hall/CRC, 2005. [25] Aric A. Hagberg, Daniel A. Schult, and Pieter J.Swart, Exploring network structure, dynamics, and function using NetworkX. in Proc. 7th Python in Science Conf., 2008, 11-15. [26] Jonathan Hill, Bill McColl, Dan Stefanescu, Mark Goudreau, Kevin Lang, Satish Rao, Torsten Suel, Thanasis Tsantilas, and Rob Bisseling, BSPlib: The BSP Programming Library. Parallel Computing 24, 1998, 1947-1980. [27] Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly, Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks. in Proc. European Conf. on Computer Syst., 2007, 59{72. [28] Paris C. Kanellakis and Alexander A. Shvartsman, Fault-Tolerant Parallel Computation. Kluwer Academic Publishers, 1997. [29] Donald E. Knuth, Stanford GraphBase: A Platform for Combinatorial Computing. ACM Press, 1994. [30] U Kung, Charalampos E. Tsourakakis, and Christos Faloutsos, Pegasus: A Peta-Scale Graph Mining System - Implementation and Observations. Proc. Intl. Conf. Data Mining, 2009, 229-238. [31] Andrew Lumsdaine, Douglas Gregor, Bruce Hendrickson, and Jonathan W. Berry, Challenges in Parallel Graph Processing. Parallel Processing Letters 17, 2007, 5-20. [32] Kamesh Madduri, David A. Bader, Jonathan W. Berry, and Joseph R. Crobak, Parallel Shortest Path Algorithms for Solving Large-Scale Graph Instances. DIMACS Implementation Challenge - The Shortest Path Problem, 2006. [33] Kamesh Madduri, David Ediger, Karl Jiang, David A. Bader, and Daniel Chavarria-Miranda, A Faster Parallel Algorithm and Efficient Multithreaded Implementation for Evaluating Betweenness Centrality on Massive Datasets, in Proc. 3rd Workshop on Multithreaded Architectures and Applications (MTAAP’09), Rome, Italy, May 2009. [34] Grzegorz Malewicz, A Work-Optimal Deterministic Algorithm for the Certi ed Write-All Problem with a Nontrivial Number of Asynchronous Processors. SIAM J. Comput. 34(4), 2005, 993-1024. [35] Kurt Mehlhorn and Stefan Naher, The LEDA Platform of Combinatorial and Geometric Computing. Cambridge University Press, 1999. |
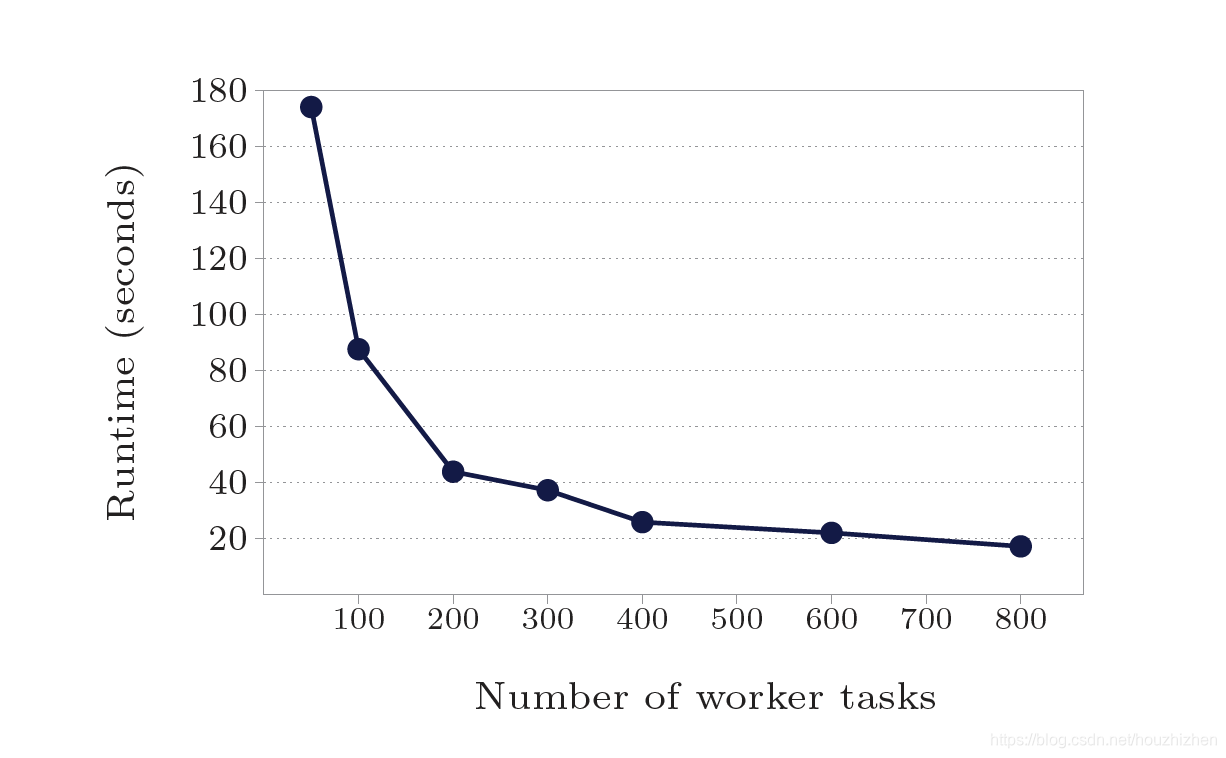 图7:最短路径--10亿顶点的二叉树: 在300台多核服务器上,不同数量的计算任务的运行时间
图7:最短路径--10亿顶点的二叉树: 在300台多核服务器上,不同数量的计算任务的运行时间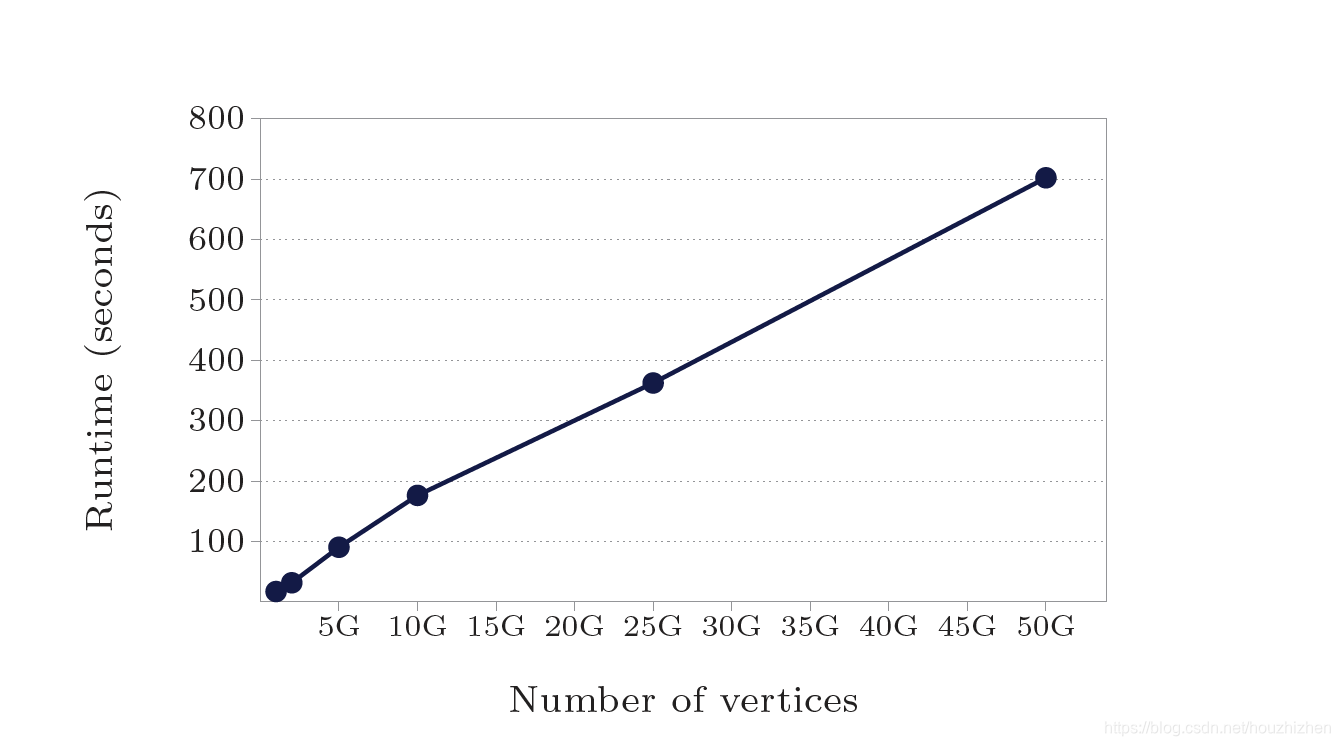 图8: 最短路径--二叉树: 不同图大小,运行800个计算任务,运行在由300台多核服务器组成的集群上
图8: 最短路径--二叉树: 不同图大小,运行800个计算任务,运行在由300台多核服务器组成的集群上【本文地址】
今日新闻 |
推荐新闻 |