用BERT做NER?教你用PyTorch轻松入门Roberta! |
您所在的位置:网站首页 › praat标注教程 › 用BERT做NER?教你用PyTorch轻松入门Roberta! |
用BERT做NER?教你用PyTorch轻松入门Roberta!
|
计算语言学的期中作业是NER任务,之前没有什么项目经验的我和同组小伙伴也是很慌,一点点从零搭建项目,最后终于也能说自己是用过BERT和Roberta的人啦!下面把我们的心路历程分享给大家,如果有错误和可以讨论的地方欢迎评论和私戳! 项目地址:https://github.com/hemingkx/CLUENER2020 1、不懂就问,什么是NER任务?NER(Named Entity Recognition),中文称为命名实体识别,是NLP中一项非常基础的任务。命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括人名、地名、机构名、日期时间、专有名词等。而命名实体识别,就是要在文本中将这些实体标注出来。  命名实体识别任务是信息提取、问答系统、句法分析、机器翻译等诸多NLP任务的基础,其准确度决定了下游任务的效果,是NLP中非常重要的一个基础问题。比如在关系抽取任务中,命名实体识别起到了抽取实体的作用,其准确度直接影响了关系抽取的最终结果。 2、标注方法具体怎么在文本中标注出来实体呢?我们把这个任务视作一个序列标注任务。序列标注,即对一个序列的每一个元素都标注一个标签,这里的序列一般就是指一个句子,而元素指的是句子中的字(下面我们均讨论中文任务,英文NER中的元素指的是每一个单词)。 根据元素粒度的不同,序列标注可分为原始标注和联合标注。原始标注即对句子中的每个字标注上一个标签,可以简单地看成是直接对每个字分类(需要融合上下文信息),因此可以使用一个多分类器,分类器输出类别就是该字的标签。而联合标注则是对一串连续的字标注相同的标签。在NER任务中,实体由一个或多个字组成,所以它属于联合标注任务。 联合标注与原始标注相比,相邻词语标签之间可能会存在依赖关系。这一问题可以通过标签转化的方式,把联合标注转化成原始标注解决。比如使用BIO标注。 BIO标注,即把联合标注中的每种存在“跨字”情况的标签X转化成新的两种标签“B-X”“I-X”: B即Begin,被标注为“B-X”的字表示该字所在词片段类型为X,且该字是词片段的起始字。I即In,“I-X”表示该字所在的词片段类型为X,但该字是词片段的起始字之后的字。BIO中的“O”表示该字不属于事先定义的任何词片段类型。  当然还有更加复杂的标注方案,比如BIOS(S即Single,“S-X”表示该字单独标记为X标签),或者是BIOE(“E-X”表示该字是标签X的词片段末尾的终止字)等。使用更加复杂、细粒度的标注方法,能够更加精准地定位一个实体边界以及类型,但也因此带来了标签稀疏的问题。我们在本项目中采用BIOS标注方法。经过对比,BIO和BIOS标注在结果上没有显著差异。 3、数据集介绍3.1 实验数据来源 实验数据来自CLUENER2020,这是一个中文细粒度命名实体识别数据集,是基于开源文本分类数据集THUCNEWS,选出部分数据进行细粒度标注得到的。该数据集的训练集、验证集和测试集的大小分别为10748,1343,1345,平均句子长度37.4字,最长50字。由于测试集不直接提供,考虑到leaderboard上提交次数有限,我们使用验证集作为模型表现评判的测试集。 CLUENER2020共有10个不同的类别,包括:组织(organization)、人名(name)、地址(address)、公司(company)、政府(government)、书籍(book)、游戏(game)、电影(movie)、职位(position)和景点(scene)。 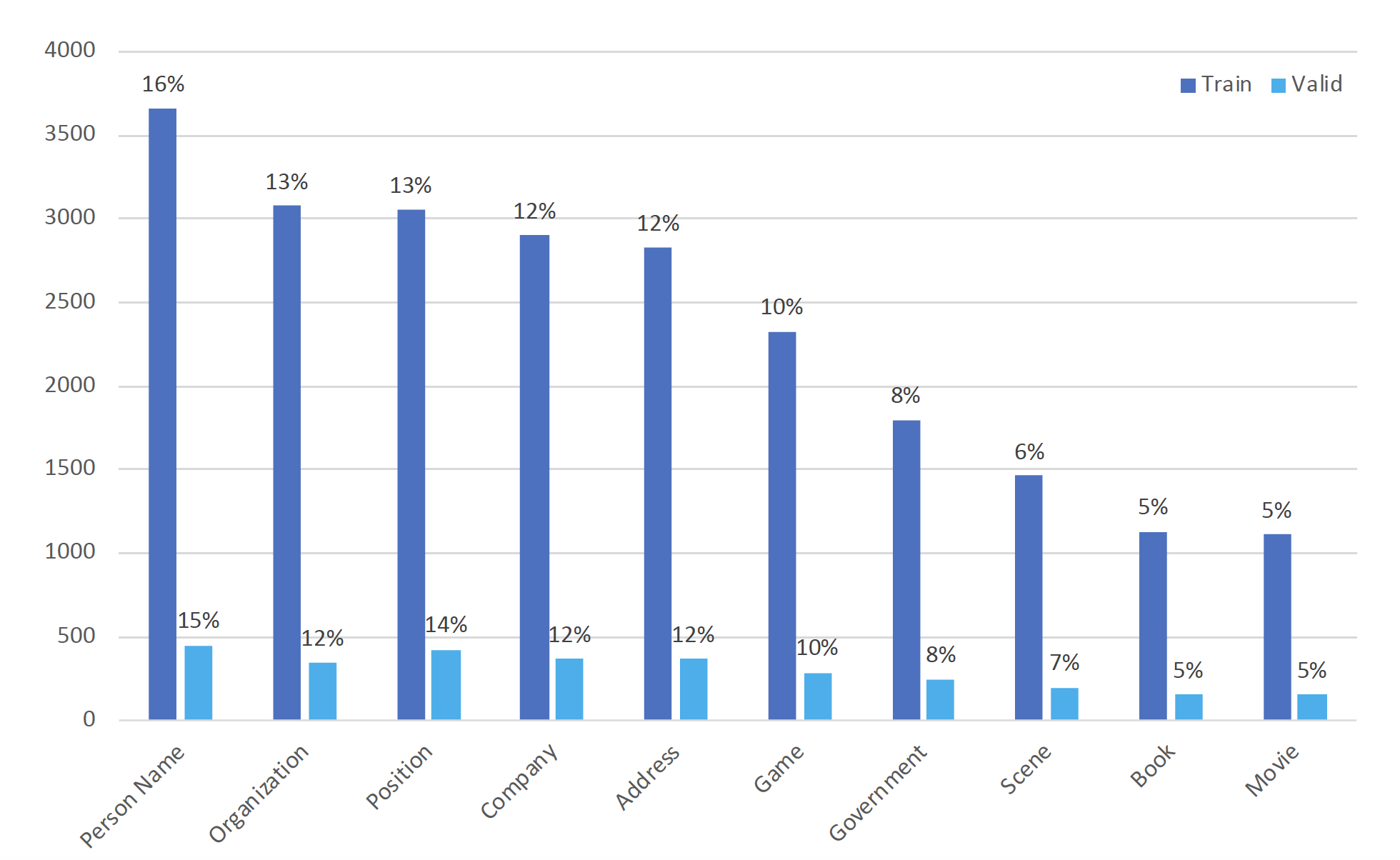 上图为10种标签在训练集和原始验证集上的分布情况,可以看到标签样本不均衡的问题比较明显,人名实体的标签是电影类标签的近三倍多,这也给模型训练带来了挑战。 3.2 原始数据格式 原始数据存储在json文件中。文件中的每一行是一条单独的数据,一条数据包括一个原始句子以及其上的标签,具体形式如下: { "text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": { "name": { "叶老桂": [ [9, 11], [32, 34] ] }, "company": { "浙商银行": [ [0, 3] ] } } }4、数据预处理4.1 是否分词? 在自然语言任务处理中,中文与英文最直观的不同就是中文的词是由一串连续的字组成,词语之间没有像英文那样的天然的空格把词分隔开。因此,大多数中文任务会预先利用工具对中文文本进行分词处理,以词语为单位生成向量表示。但NER作为序列标注任务,输出需要确定实体边界和类型。如果预先进行了分词处理,由于分词工具原本就无法保证绝对正确的分词方案,势必会产生错误的分词结果,而这将进一步影响序列标注结果。因此,我们不进行分词,在字层面进行BIOS标注。 4.2 原始数据处理 我们采用BIOS标注对原始标签进行转换,对于3.2中的范例,转换结果就为 ['B-company', 'I-company', 'I-company', 'I-company', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']列表中的每个元素都与text中相应位置的字一一对应,上述处理过程的代码在data_process.py中~。训练集和测试集都进行相同的处理,最后把处理完的所有文本序列和标签序列以列表的形式保存进npz文件中,生成train.npz、test.npz两个文件。 此外,上述处理过程得到的都是字符或者字符串组成的列表,所以在模型训练或测试之前,为了能够输入到模型中进行计算,还需要构建词表和标签表,把原始的字和标签分别映射成词表和标记表中的索引位置。使用Roberta预训练模型进行训练时,我们直接调用Roberta提供的词表。 4.3 构建数据集 我们使用torch.utils.data.Dataset类定义自己的数据集。我们使用自建词表将单词和标签序列转化为其对应的索引序列。之后,我们将每个batch中的句子和标签补全到同一长度(分别为该batch中句子和标签序列的最大长度)。这一部分代码位于data_loader.py文件中~。 4.4 数据集分割 我们按照9:1的比例将训练用数据分割为训练集和验证集。 5、模型架构我们以Roberta-BiLSTM-CRF为例,介绍模型的具体架构。 5.1 BERT 如图所示,BERT(Bidirectional Encoder Representations from Transformers)使用堆叠的Transformer作为模型的主要架构,在此基础上设计了Masked Language Model(MLM)和Next Sentence Prediction(NSP)两种预训练任务: 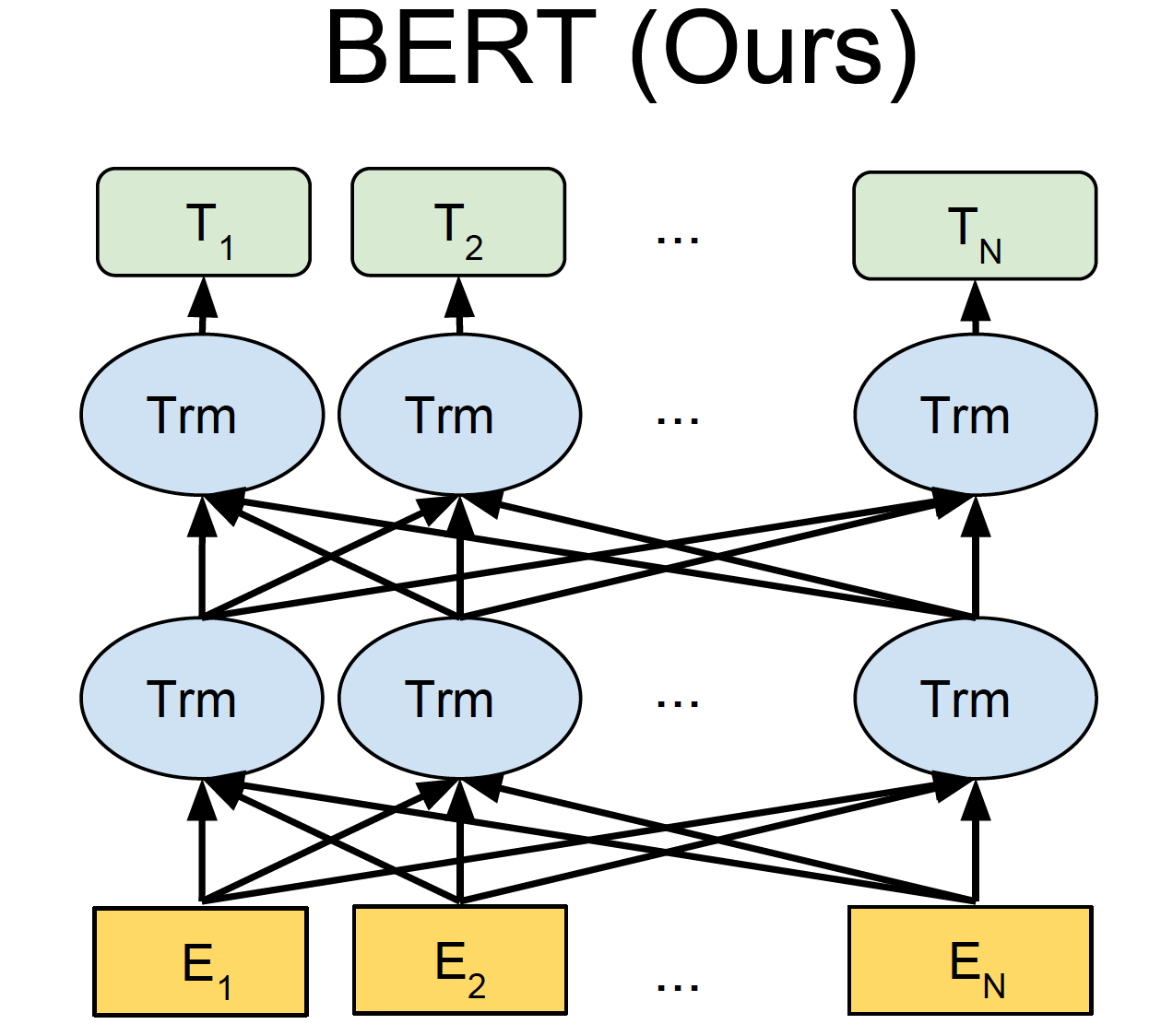 Masked Language Model:在原始句子中mask某些词语,而通过训练模型,让模型还原出被mask的词。这样句子中词语之间的联系就不再是原始语言模型所建模出的单向的联系,而被赋予了双向的词语共现信息,经过预训练后使得BERT具有良好地上下文信息融合的能力,也能够轻松地捕获长距离依赖。Next Sentence Prediction:这一任务主要是为了对句子之间的关系建模。具体而言,BERT采用了一种非常简单的方式来实现句子关系建模,让模型进行一个二分类,即对拼接后的句子对判断后一句子是否是前一句的下一句。句子关系的建模可以使得模型在下游的生成式任务中,提高句子之间的语义相关性。 Masked Language Model:在原始句子中mask某些词语,而通过训练模型,让模型还原出被mask的词。这样句子中词语之间的联系就不再是原始语言模型所建模出的单向的联系,而被赋予了双向的词语共现信息,经过预训练后使得BERT具有良好地上下文信息融合的能力,也能够轻松地捕获长距离依赖。Next Sentence Prediction:这一任务主要是为了对句子之间的关系建模。具体而言,BERT采用了一种非常简单的方式来实现句子关系建模,让模型进行一个二分类,即对拼接后的句子对判断后一句子是否是前一句的下一句。句子关系的建模可以使得模型在下游的生成式任务中,提高句子之间的语义相关性。BERT通过在BooksCorpus和英文维基百科组成的大规模语料上进行预训练,获得强有力的句子语义提取能力,通过fine-tuning的方式与具体任务相结合,在下游的11个自然语言处理任务上都超越了之前的最佳结果。因此,BERT以及之后不断推出的类BERT预训练模型成为了推动NLP模型在各种任务上提高的重要利器。 5.2 RoBERTa RoBERTa脱胎于BERT,同样也是由堆叠的transformer结构组成,并在海量文本数据上训练得到。在模型层面,RoBERTa与BERT基本一致,不同之处在于使用了新的预训练方法并进行了更为精细的调优工作: 动态mask:RoBERTa将BERT的静态mask策略替换成动态mask,其实就是把预训练数据复制10份,每一份都随机选15%进行mask。这样的话,同一句话就有10种不同的mask方式,在不同epoch的训练中,每个序列被mask的词会动态变化,因此被成为动态mask。取消NSP任务:RoBERTa探索了NSP训练策略对模型结果的影响,发现预训练阶段输入同一文档的连续句子,并取消NSP任务,在下游任务可以获得更好的效果。训练trick:RoBERTa在训练阶段还使用了更大的mini-batch,加入了更多训练数据,并进行了更长时间的训练,使其在多个下游的NLP任务上都实现了最佳效果。我们使用哈工大讯飞联合实验室发布的中文RoBERTa-wwm-ext-large预训练模型进行实验,该模型并非原版RoBERTa,只是按照类似于RoBERTa训练方式训练出的BERT模型,所以集成了RoBERTa和BERT-wwm的优点。 关于whole word masking (wwm)介绍详见官方文档。5.3 BiLSTM LSTM(Long Short-Term Memory)是一种特殊的RNN,主要是为解决长序列在训练过程中的梯度消失和梯度爆炸问题。BiLSTM即双向LSTM。由于LSTM只能单向编码,所以一般使用两个方向相反的LSTM对应位置的隐藏层拼接后得到的向量作为融合了上下文信息的词向量。 5.4 CRF 如上所述,序列标注可以朴素地看成是序列元素的多分类问题,但这样的话,序列标签之间并没有显式地约束。NER是一个联合标注任务,标签之间是有依赖关系的。比如上文提到的BIOS标注中,被标记为“I-X”的字的前一个字标签可以是“B-X”、“I-X”,但不能是“S-X”和“O”。 为了提高序列标注的准确性,隐马尔科夫模型(Hidden Markov Model, HMM)和条件随机场(Conditional Random Field, CRF)就被提出并用以专门对序列标注进行建模。由于HMM基于马尔科夫假设,约束了隐状态只跟前一时刻有关,无法获取更远的信息。而CRF引入了特征函数,在计算全局序列时会把各个时刻的特征加和,信息获取得更加全面。在不考虑运算复杂度、训练代价的情况下,CRF与HMM相比能够获得更优的序列标注效果。因此,我们采用CRF进行序列标注。 那么,CRF有没有现成的轮子呢?有的,哈哈哈!pytorch-crf提供了CRF的接口,我们直接调用了该轮子构建模型的序列标注模块~。 5.5 整体模型 如图所示,我们将处理好的文本序列(索引格式)输入到Roberta中,获取Roberta输出的每个位置的表示。这些表示实现与原标签序列的对齐后(去除[CLS]等特殊表示),输入到BiLSTM中进行进一步的处理。随后,将其输入到CRF中,由CRF进行处理得到最后的预测序列表示。预测序列表示经过标签词表的映射,转换为与golden label对应的预测标签序列,用于计算f1 score。这一部分代码在model.py文件中~。 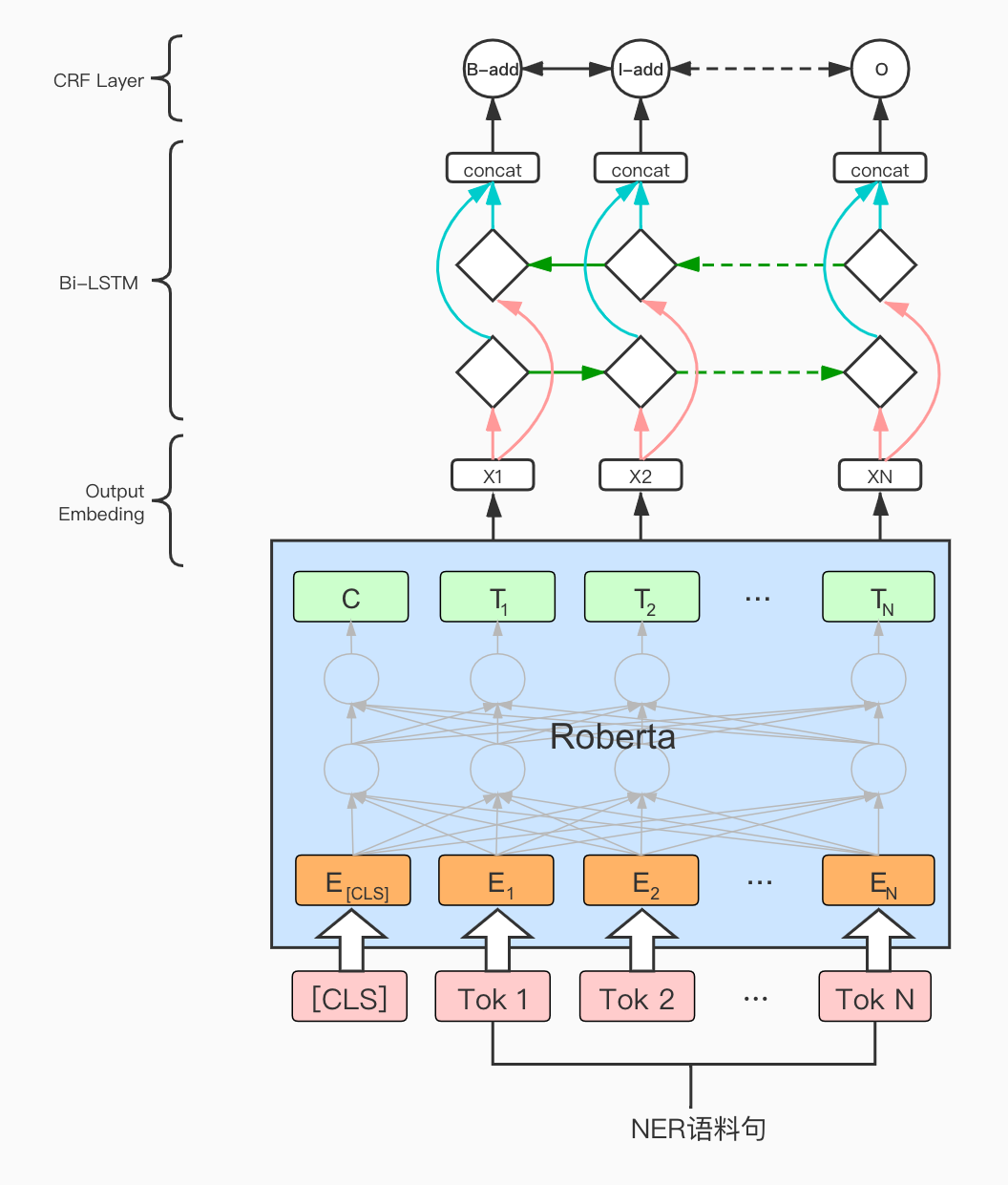 6、F1 score 计算 6、F1 score 计算我们在验证集验证时,使用Micro-Averaging评测得出评测分数,如下式所示: \begin{aligned} M i c r o P &=\frac{\sum_{i=1}^{n} T P_{i}}{\sum_{i=1}^{n} T P_{i}+\sum_{i=1}^{n} F P_{i}} \\ \text { MicroR } &=\frac{\sum_{i=1}^{n} T P_{i}}{\sum_{i=1}^{n} T P_{i}+\sum_{i=1}^{n} F N_{i}} \\ \text { MicroF } &=\frac{2 * \text { MicroP } * \text { MicroR }}{\text { MicroP }+\text { MicroR }} \end{aligned}\\ 其中,n表示NER文本总数, T P_{i} 表示第i条文本中正确识别为实体的数量, F P_{i} 表示第i条文本中误识别为实体的数量, F N_{i} 表示第i条文本中未识别出的实体的数量。 在测试集测试时,我们计算出每个类别的Macro f1 分数,同时也将总的Micro-Averaging f1分数作为参考标准之一。F1 score计算部分代码在metrics.py文件中~。 7、模型训练模型训练及测试部分代码在run.py和train.py文件中~。 7.1 学习率分离 我们在训练过程中对Roberta进行Fine-Tune,学习率设置为 3e-5;同时,BiLSTM和CRF的学习率设置为Roberta学习率的五倍,即1.5e-4。在weight decay参数的设置上,我们设置为对bias、LayerNorm.bias及LayerNorm.weight参数不设置weight decay,而将其他参数的weight decay设置为0.01。 7.2 优化器 我们使用AdamW(Adam + weight decay)作为优化器,AdamW是对传统的Adam + L2 regularization的改进。 7.3 Scheduler 我们使用cosine schedule with warmup调整学习率。我们将warmup steps设置为总训练轮次的十分之一。因此,学习率会在前十分之一的训练轮次线性递增到设置的学习率数值,在之后余弦下降。如下所示:  7.4 训练参数 我们的总训练轮次设置为50个epoch,每个epoch结束后在验证集上计算f1 score,并保存最优模型。我们设置patience num为10,如果模型在10个连续轮次的训练后验证集结果没有提升则提前终止训练。每个epoch的耗时为3min31s,总训练平均历时2h。 7.5 模型测试 我们在最终的测试集上测试最优模型的表现,测试集在模型训练过程中并未出现。我们统计得到模型在每个类别上的f1分数,并求其平均值,作为测试集上的f1得分。 8、结果分析8.1 CRF 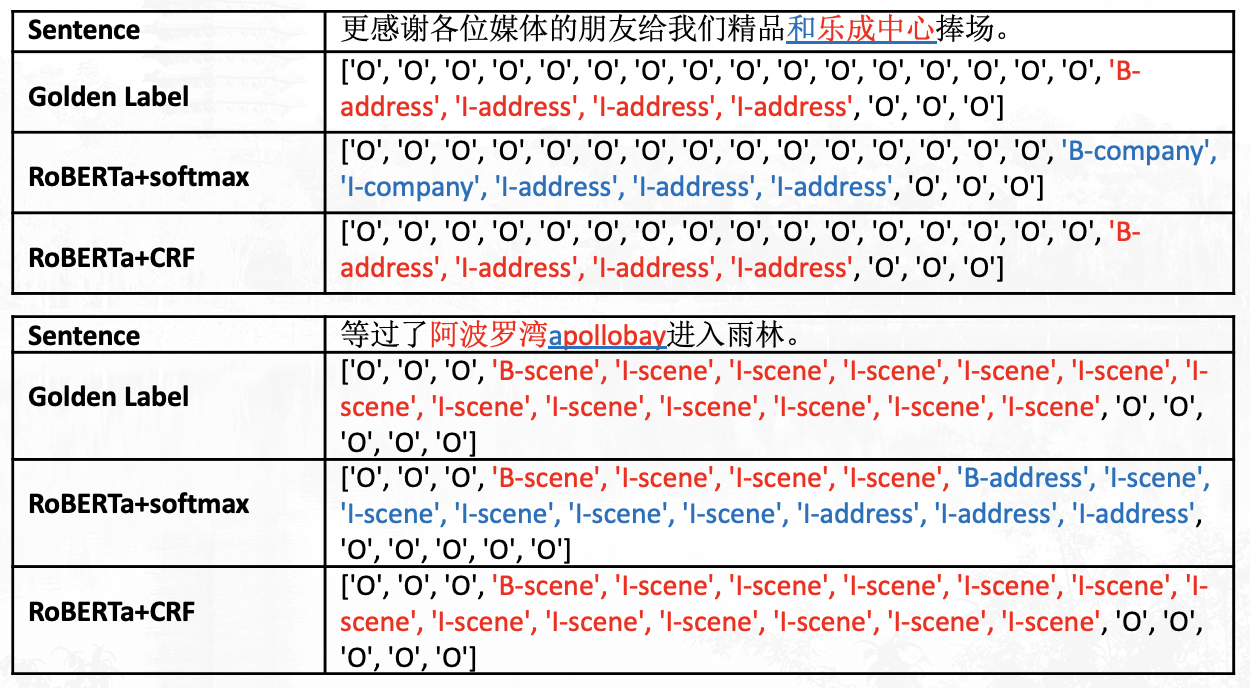 可以看到,在没有CRF的Roberta-softmax模型中,模型出现了’I-company’➡️’I-address’、 ’B-address’➡️’I-scene’等标注错误。这一问题在加入CRF之后得到了较大缓解~。 8.2 类别混淆  第一个例子中,“彩票监管中心”的gold label为organization,但被模型标记为government。第二个例子中,“中彩中心”的gold label为organization,但从字面意思看,也可能是company。经查证,“彩票监管中心”和“中彩中心”都属于我国民政部直属的事业单位,不属于company或government,应归入organization类别。 在上述的分析过程中,我们发现,命名实体的识别仅仅靠实体词本身和上下文信息是不够的,很多情况下都需要增加引入额外的知识进行消歧和判别,这些知识一般人都不见得熟悉(每个人熟悉的领域不同),这也说明了CLUE2020 NER数据集介绍中给的human performance f1值比RoBERTa模型低是可以理解的。RoBERTa从大量实体信息丰富的语料里能够学到非常多的知识,因此在NER上具有非常惊人的表现。 9、总结附上项目的传送门,欢迎star~! 在做项目的过程中,从数据处理到模型搭建,我们都遇到了不少问题,也苦于网上没有较全面的NER任务讲解和实战资源。因此,项目结束后,我们把自己的课程报告扩充后写成了这一篇分享,希望大家多多指教~。有任何的问题欢迎评论或私戳! |
【本文地址】