论文阅读 |
您所在的位置:网站首页 › potential与possible › 论文阅读 |
论文阅读
|
一、论文信息
论文名称:Combining EfficientNet and Vision Transformers for Video Deepfake Detection 论文代码:https://github.com/davide-coccomini/Combining-EfficientNet-and-Vision-Transformers-for-Video-Deepfake-Detection 会议:ICIAP2022 作者团队:
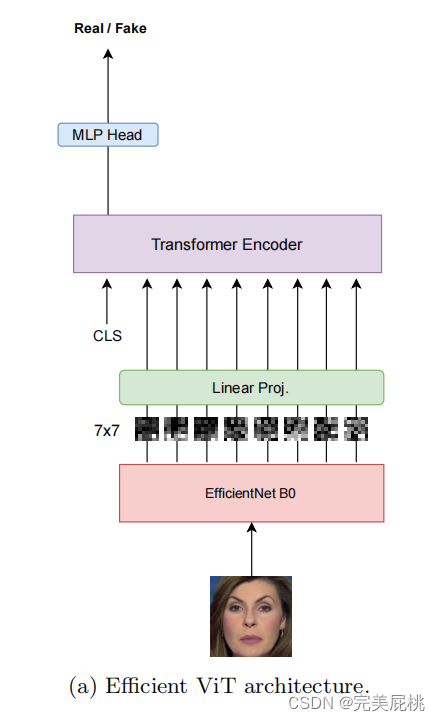
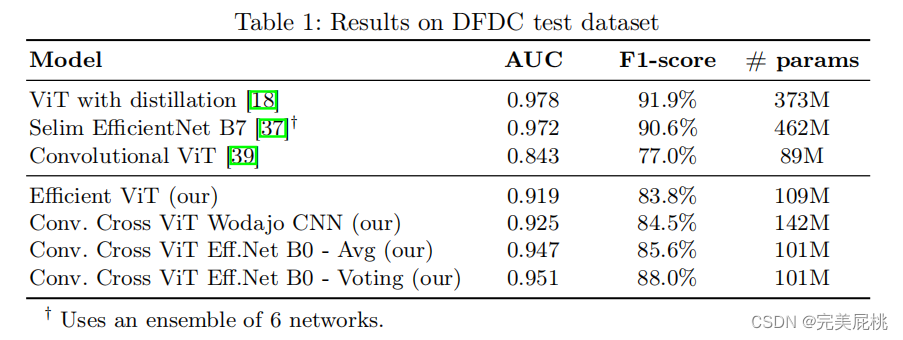
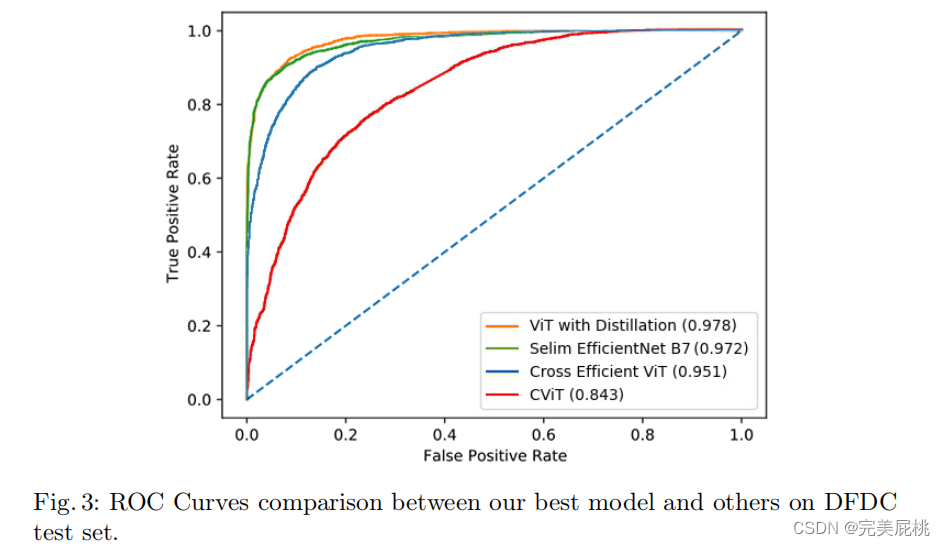
传统基于CNN的方法在EfficientNetB7上效果很好,本文使用EfficientNet B0和ViT结合在DFDC数据集上取得了auc 0.951和f1 0.88的成绩,与DFDC数据集上最好的检测水平非常接近。将各种类型的视觉变换器与卷积EfficientNet B0相结合,提取人脸特征。不使用蒸馏法,也不使用集成法。而是一种基于简单投票的方案,用于处理同一视频镜头中的多个不同人脸。在时间上和跨多个人脸上 聚合推断出视频片段的真伪。 三、方法网络输入:提取的人脸。 网络输出:人脸被操纵的概率。 用人脸检测器MTCNN对人脸进行预提取; 再用Efficient ViT and Convolutional Cross ViT两个网络训练。 Efficient ViT 两个模块组成:卷积模块(EfficientNet B0特征提取)+ Transformer Encoder。 具体步骤: 用EfficientNet B0为人脸每个块生成一个视觉特征,(一个块为7*7像素); 每个特征都由视觉变换器(Linear Proj)进一步处理; 用CLS生成二分类的分数; Transformer encoder编码器,把特征编码为向量; MLP Head将图片分为real/fake。
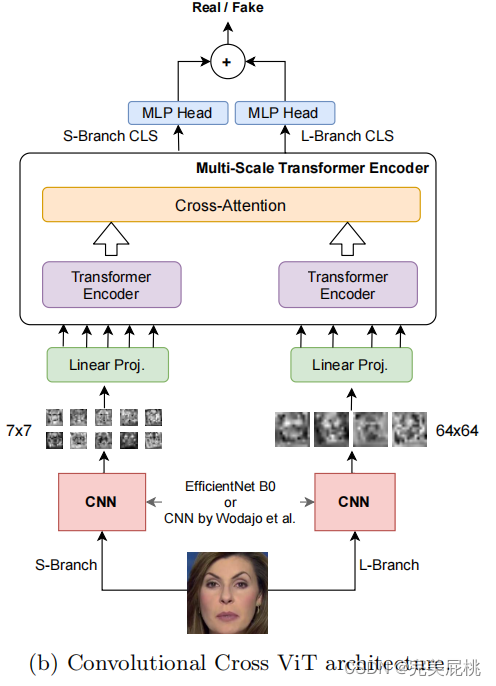
缺陷:只能用于小的patch,而伪影可能在全局出现。 Convolutional Cross ViT 两分支组成: Efficient ViT and the multi-scale Transformer architecture 即 S分支处理较小的patch,L分支处理较大的patch,以获得更宽的感受野。 使用两个不同的CNN主干作为特征提取器。(只使用其一) EfficientNet B0,它为S分支处理7×7图像补丁,为L分支处理54×54图像补丁。 Wodajo等人的CNN,它为S分支处理7×7图像补丁,为L分支处理64×64图像补丁。 Linear Proj:视觉变换器处理特征。 Transformer Encoder:解码器解码。 Cross-Attention:两条分支交互,生成独立的S-CLS,L-CLS。 MLP Head:分类图片。
推理 真假阀值设置:0.55。 投票机制:针对同一个视频里有多个不同人脸的视频。根据人脸特征分类人脸,并平均得分,判断是否是假脸。一个视频里有一张假脸就判定该视频是假的。
优化器:使用 SGD,学习率0.01进行端到端训练。 性能指标:AUC(准确率)+F1-score(伪造人脸的平均分数) 数据集:FaceForensics++, DFDC
|



【本文地址】