强化学习(问题集) |
您所在的位置:网站首页 › pomdp值迭代 › 强化学习(问题集) |
强化学习(问题集)
|
什么是强化学习 强化学习是一种从行动中学习的计算方法。强化学习循环输出state,action和reward的序列,agent的目的是最大化预计累计奖励(expected cumulative reward) 为什么 Agent 的目标是最大化预期的累积奖励 实际上,强化学习是基于奖励假设的想法。所有目标都可以通过预期累积奖励的最大化来描述。 gamma的折扣率 它必须介于0和1之间。越大,折扣越小。这意味着学习,agent 更关心长期奖励。另一方面,gamma越小,折扣越大。这意味着我们的 agent 更关心短期奖励(最近的奶酪)。 累积的折扣预期奖励是: 创建一个表格,计算每种状态 state 下采取的每种行动 action的最大的未来预期奖励。 目标:最大化Q函数(给定状态和行动的预期未来奖励)。 Q表示来自特定状态下某个动作的质量。 Q学习算法:学习动作值函数 动作值函数(或“ Q 函数”)有两个输入:“状态”和“动作”。它返回该动作在该状态下的预期未来奖励。 生成一个随机数。如果这个数字> epsilon,那么将进行“ 开发”(这意味着使用已知的方法来选择每一步的最佳动作)。否则,会进行探索。 在Q函数训练开始时必须有一个较大的epsilon。然后,随着Agent变得做得越来越好,逐渐减少它。 使用Bellman方程更新Q(s,a) Q-Learning缺陷 状态空间是大型环境时,生成和更新Q表可能会失效。 Deep Q神经网络 神经网络获取智能体的状态并为该状态的每个动作计算Q值。 什么是Deep Q-Learning(DQL)? 以四个图像帧的堆叠作为输入。它们通过其网络,并在给定状态下为每个可能的动作输出Q值向量。采用此向量的最大Q值来找到我们最好的行动。 使用DQL的最佳策略是什么? 如何处理时间限制问题 使用LSTM神经网络 来处理。 将图像帧堆叠在一起,因为它有助于我们处理时间限制(temporal limitation)的问题。 为什么我们使用经验回放 更有效地利用观察到的体验,避免被固定在状态空间的一个区域上。这可以防止反复强化相同的动作。 (1)避免忘记以前的经历。 问题:权重的可变性,因为行动和状态之间存在高度相关性。在每个时间步,得到一个元组(state, action, reward, new_state)。从(这个元组)中学习,然后扔掉这个经验。问题是将智能体与环境相互作用的得到序列样本输入到神经网络进行训练过程中。 神经网络往往会忘记以前的经历,因为它的参数会被新的经验覆盖。 解决方案:创建一个“replay buffer”存盘。在智能体与环境交互时存储经验元组,然后我们用小批量元组数据a small batch of tuple来训练神经网络。防止网络只学习智能体当前的经验。 (2)减少经验之间的相关性。 问题 :每个行动都会影响下一个状态。行动过程得到了一个序列的经验元组,这些元组可能会高度相关。如果按序列顺序训练网络,这种相关性会影响我们的智能体。 解决方案:通过在replay buffer随机抽取,我们可以打破这种相关性。可以防止动作值发生振荡或发散。 优先级经验回放:这让我们可以更频繁地向神经网络呈现罕见或“重要”的元组。 DQL背后的数学是什么? 使用Bellman方程更新给定状态和动作的Q值 |
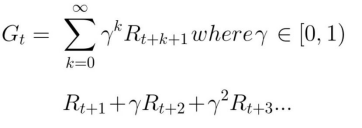 情节性任务(episodic tasks) 这种情况下,强化学习任务会有一个起点和终点(一个最终状态)。 持续性任务 这些是永远持续的任务(没有终点状态)。在这种情况下,agent必须学习如何选择最佳操作并同时与环境交互。 蒙特卡洛方法 当剧集结束时(智能体达到“终端状态”),Agent 会查看总累积奖励,看看它的表现如何。在蒙特卡洛方法中,奖励仅在比赛结束时收到。
情节性任务(episodic tasks) 这种情况下,强化学习任务会有一个起点和终点(一个最终状态)。 持续性任务 这些是永远持续的任务(没有终点状态)。在这种情况下,agent必须学习如何选择最佳操作并同时与环境交互。 蒙特卡洛方法 当剧集结束时(智能体达到“终端状态”),Agent 会查看总累积奖励,看看它的表现如何。在蒙特卡洛方法中,奖励仅在比赛结束时收到。  时序差分方法:每一步的学习 TD学习不会等到剧集结束时更新最大预期未来奖励估计:它将更新其在该经历中发生的非最终状态St的价值估计V。该方法称为TD(0) 或一步TD(在任何单个步骤之后更新值函数)。
时序差分方法:每一步的学习 TD学习不会等到剧集结束时更新最大预期未来奖励估计:它将更新其在该经历中发生的非最终状态St的价值估计V。该方法称为TD(0) 或一步TD(在任何单个步骤之后更新值函数)。  探索/开发权衡 探索是寻找有关环境的更多信息。 开发是利用已知信息来最大化奖励。 基于数值方法 在基于数值的RL中,目标是优化价值函数 V(s)。价值函数是一个函数,表明agent在每个状态获得的最大预期未来奖励。
探索/开发权衡 探索是寻找有关环境的更多信息。 开发是利用已知信息来最大化奖励。 基于数值方法 在基于数值的RL中,目标是优化价值函数 V(s)。价值函数是一个函数,表明agent在每个状态获得的最大预期未来奖励。 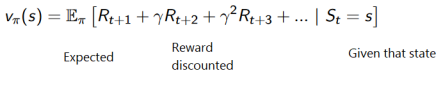 在给定一个状态下,我们选择有最高Q值(在所有状态下最大的期望奖励)的行动。因此,在基于价值的学习中,一个策略存在仅仅出于这些行动价值的评估。 当行动个数有限时,该方法很有效。 基于策略方法 不使用值函数的情况下直接优化策略函数 π(s) 有两种策略类型: 确定性:给定状态下的策略将始终返回相同的操作。 随机:输出行动上的分别概率。 当动作空间是连续的或随机时,这很有效。
在给定一个状态下,我们选择有最高Q值(在所有状态下最大的期望奖励)的行动。因此,在基于价值的学习中,一个策略存在仅仅出于这些行动价值的评估。 当行动个数有限时,该方法很有效。 基于策略方法 不使用值函数的情况下直接优化策略函数 π(s) 有两种策略类型: 确定性:给定状态下的策略将始终返回相同的操作。 随机:输出行动上的分别概率。 当动作空间是连续的或随机时,这很有效。  基于模型方法 对环境进行建模。这意味着我们创建了一个环境行为的模型。问题是每个环境都需要不同的模型表示。 Q-Learning 一种基于数值的强化学习算法,用于使用q函数找到最优的动作选择策略。它根据动作值函数评估要采取的动作,该动作值函数确定处于某种状态的值并在该状态下采取某种动作。
基于模型方法 对环境进行建模。这意味着我们创建了一个环境行为的模型。问题是每个环境都需要不同的模型表示。 Q-Learning 一种基于数值的强化学习算法,用于使用q函数找到最优的动作选择策略。它根据动作值函数评估要采取的动作,该动作值函数确定处于某种状态的值并在该状态下采取某种动作。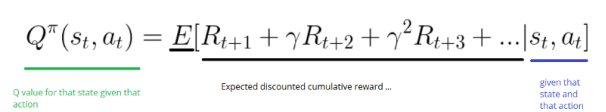 epsilon贪心策略 指定一个探索率“epsilon”,开始时设置为1,即随机执行step的速度。刚开始学习时,这个速率必须是最高值,因为对Q表的取值一无所知。这意味着需要通过随机选择行动进行大量探索。
epsilon贪心策略 指定一个探索率“epsilon”,开始时设置为1,即随机执行step的速度。刚开始学习时,这个速率必须是最高值,因为对Q表的取值一无所知。这意味着需要通过随机选择行动进行大量探索。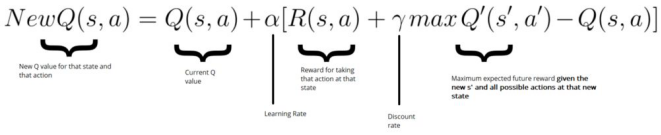
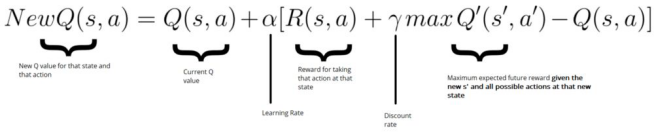 时序差分误差(或TD误差)是通过Q_target(来自下一个状态的最大可能值)和Q_value(我们当前预测的Q值)之间的差来计算的。
时序差分误差(或TD误差)是通过Q_target(来自下一个状态的最大可能值)和Q_value(我们当前预测的Q值)之间的差来计算的。 
【本文地址】
今日新闻 |
推荐新闻 |