tensorflow之常用工具类 |
您所在的位置:网站首页 › pointnet优点 › tensorflow之常用工具类 |
tensorflow之常用工具类
|
tensorflow/core/platform里定义了很多平台相关的代码,默认实现在tensorflow/core/platform/default里。同时windows的实现在tensorflow/core/platform/windows下 tensorflow/core/platform/gcs里实现google云的实现,包括文件系统等 CPU profile: ensorflow/core/platform/profile_utils目录下 tensorflow/core/platform/cpu_info.h tensorflow/core/platform/hash.h tensorflow/core/platform/load_library.h 组装,拆分,获取扩展名 tensorflow/core/platform/path.h tensorflow/core/platform/random.h tensorflow/core/platform/mem.h 默认的CpuAllocator就是使用此接口分配内存。不同平台不同实现 namespace tensorflow { namespace port { // Aligned allocation/deallocation. `minimum_alignment` must be a power of 2 // and a multiple of sizeof(void*). void* AlignedMalloc(size_t size, int minimum_alignment); void AlignedFree(void* aligned_memory); void* Malloc(size_t size); void* Realloc(void* ptr, size_t size); void Free(void* ptr); // Tries to release num_bytes of free memory back to the operating // system for reuse. Use this routine with caution -- to get this // memory back may require faulting pages back in by the OS, and // that may be slow. // // Currently, if a malloc implementation does not support this // routine, this routine is a no-op. void MallocExtension_ReleaseToSystem(std::size_t num_bytes); // Returns the actual number N of bytes reserved by the malloc for the // pointer p. This number may be equal to or greater than the number // of bytes requested when p was allocated. // // This routine is just useful for statistics collection. The // client must *not* read or write from the extra bytes that are // indicated by this call. // // Example, suppose the client gets memory by calling // p = malloc(10) // and GetAllocatedSize(p) may return 16. The client must only use the // first 10 bytes p[0..9], and not attempt to read or write p[10..15]. // // Currently, if a malloc implementation does not support this // routine, this routine returns 0. std::size_t MallocExtension_GetAllocatedSize(const void* p); struct MemoryInfo { int64_t total = 0; int64_t free = 0; }; struct MemoryBandwidthInfo { int64_t bw_used = 0; // memory bandwidth used across all CPU (in MBs/second) }; // Retrieves the host memory information. If any of the fields in the returned // MemoryInfo structure is INT64_MAX, it means such information is not // available. MemoryInfo GetMemoryInfo(); // Retrieves the host memory bandwidth information. If any field in the returned // structure is INT64_MAX, it means such information is not available. MemoryBandwidthInfo GetMemoryBandwidthInfo(); // Returns the amount of RAM available in bytes, or INT64_MAX if unknown. static inline int64_t AvailableRam() { return GetMemoryInfo().free; } } // namespace port } // namespace tensorflowtensorflow/core/platform/net.h 这可以用于C语言。实现中并没有用C++ class。 tensorflow/core/platform/ctstring.h tensorflow/core/platform/ctstring_internal.h typedef struct TF_TString { // NOLINT union { // small conflicts with '#define small char' in RpcNdr.h for MSVC, so we use // smll instead. TF_TString_Small smll; TF_TString_Large large; TF_TString_Offset offset; TF_TString_View view; TF_TString_Raw raw; } u; } TF_TString;tensorflow/core/platform/coding.h // Maximum number of bytes occupied by a varint32. static const int kMaxVarint32Bytes = 5; // Maximum number of bytes occupied by a varint64. static const int kMaxVarint64Bytes = 10; // Lower-level versions of Put... that write directly into a character buffer // REQUIRES: dst has enough space for the value being written extern void EncodeFixed16(char* dst, uint16 value); extern void EncodeFixed32(char* dst, uint32 value); extern void EncodeFixed64(char* dst, uint64 value); extern void PutFixed16(string* dst, uint16 value); extern void PutFixed32(string* dst, uint32 value); extern void PutFixed64(string* dst, uint64 value); extern void PutVarint32(string* dst, uint32 value); extern void PutVarint64(string* dst, uint64 value); extern void PutVarint32(tstring* dst, uint32 value); extern void PutVarint64(tstring* dst, uint64 value); extern bool GetVarint32(StringPiece* input, uint32* value); extern bool GetVarint64(StringPiece* input, uint64* value); extern const char* GetVarint32Ptr(const char* p, const char* limit, uint32* v); extern const char* GetVarint64Ptr(const char* p, const char* limit, uint64* v); // Internal routine for use by fallback path of GetVarint32Ptr extern const char* GetVarint32PtrFallback(const char* p, const char* limit, uint32* value); extern const char* GetVarint32Ptr(const char* p, const char* limit, uint32* value); extern char* EncodeVarint32(char* dst, uint32 v); extern char* EncodeVarint64(char* dst, uint64 v); // Returns the length of the varint32 or varint64 encoding of "v" extern int VarintLength(uint64_t v);tensorflow/core/platform/base64.h 功能不必多说 template Status Base64Encode(StringPiece source, bool with_padding, T* encoded); template Status Base64Encode(StringPiece source, T* encoded); // with_padding=false. /// \brief Converts data from web-safe base64 encoding. /// /// See https://en.wikipedia.org/wiki/Base64 template Status Base64Decode(StringPiece data, T* decoded); // Explicit instantiations defined in base64.cc. extern template Status Base64Decode(StringPiece data, std::string* decoded); extern template Status Base64Encode(StringPiece source, std::string* encoded); extern template Status Base64Encode(StringPiece source, bool with_padding, std::string* encoded); extern template Status Base64Decode(StringPiece data, tstring* decoded); extern template Status Base64Encode(StringPiece source, tstring* encoded); extern template Status Base64Encode(StringPiece source, bool with_padding, tstring* encoded); BlockingCounter设置一个初始值counter,调用wait阻塞线程。调用DecrementCount会counter--。如果counter减到0,就唤醒所有阻塞的线程。 tensorflow/core/platform/blocking_counter.h中 Mutex SharedMutex ConditionVariabletensorflow/core/platform/refcount.h 是一个引用计数类,一个类继承此类就能用引用计数功能。禁止了拷贝和赋值。要显示通过Ref(),Unref()方法来增加减小引用计数 class RefCounted { public: RefCounted(); void Ref() const; bool Unref() const; int_fast32_t RefCount() const; bool RefCountIsOne() const; protected: virtual ~RefCounted(); bool TryRef() const; private: mutable std::atomic_int_fast32_t ref_; RefCounted(const RefCounted&) = delete; void operator=(const RefCounted&) = delete; }; // Inlined routines, since these are performance critical inline RefCounted::RefCounted() : ref_(1) {} inline RefCounted::~RefCounted() { DCHECK_EQ(ref_.load(), 0); } inline void RefCounted::Ref() const { int_fast32_t old_ref = ref_.fetch_add(1, std::memory_order_relaxed); DCHECK_GT(old_ref, 0); } inline bool RefCounted::TryRef() const { int_fast32_t old_ref = ref_.load(); while (old_ref != 0) { if (ref_.compare_exchange_weak(old_ref, old_ref + 1)) { return true; } } return false; } inline bool RefCounted::Unref() const { DCHECK_GT(ref_.load(), 0); if (ref_.fetch_sub(1, std::memory_order_acq_rel) == 1) { delete this; return true; } return false; } inline int_fast32_t RefCounted::RefCount() const { return ref_.load(std::memory_order_acquire); } inline bool RefCounted::RefCountIsOne() const { return (ref_.load(std::memory_order_acquire) == 1); }tensorflow的线程池实现了eigen里的ThreadPool接口 namespace Eigen { class ThreadPoolInterface { public: //提交一个任务 virtual void Schedule(std::function fn) = 0; virtual void ScheduleWithHint(std::function fn, int /*start*/, int /*end*/) { // Just defer to Schedule in case sub-classes aren't interested in // overriding this functionality. Schedule(fn); } virtual void Cancel() {} // Returns the number of threads in the pool. virtual int NumThreads() const = 0; // Returns a logical thread index between 0 and NumThreads() - 1 if called // from one of the threads in the pool. Returns -1 otherwise. virtual int CurrentThreadId() const = 0; virtual ~ThreadPoolInterface() {} }; } // namespace Eigentensorflow中的线程池接口:tensorflow/core/platform/thread_interface.h namespace tensorflow { namespace thread { //直接继续了Eigen中的thread pool, 没有增加新方法 class ThreadPoolInterface : public Eigen::ThreadPoolInterface {}; } // namespace thread } // namespace tensorflowtensorflow/core/platform/threadpool.h 调度策略:控制给定工作任务的如何在多个线程上运行 ThreadPool构造函数分析 Env: 环境,真正用来创建线程的是env->StartThread(), Thread只是用来管理线程数量和分配任务的 ThreadOption: 线程选项中有关键参数low_latency_hint,为true表示低延时操作,对应计算密集型任务, 为false则对应高延时操作,为I/O密集型操作。这可涉及多线程实现,如I/O密集型任务其实不需要创建多个线程,一个线程利用EPOLL进行多路复用就行。或者说计算密集型任务,线程数量与CPU核心数相等即可,不需要过多 NumThread: 线程池中的线程数量 allocator: tensor内存分配器还能持有另一个线程池,只要实现了ThreadPoolInterface的线程池 Schedule: 提交一个任务,任务就是一个函数void fn(); ParallelFor:提交任务时可以指定cost_per_unit ScheduleWithHint(std::move(fn), 0, num_threads_);能指定fn运行在0,n个thread上 class ThreadPool { public: // Scheduling strategies for ParallelFor. The strategy governs how the given // units of work are distributed among the available threads in the // threadpool. enum class SchedulingStrategy { // The Adaptive scheduling strategy adaptively chooses the shard sizes based // on the cost of each unit of work, and the cost model of the underlying // threadpool device. // // The 'cost_per_unit' is an estimate of the number of CPU cycles (or // nanoseconds if not CPU-bound) to complete a unit of work. Overestimating // creates too many shards and CPU time will be dominated by per-shard // overhead, such as Context creation. Underestimating may not fully make // use of the specified parallelism, and may also cause inefficiencies due // to load balancing issues and stragglers. kAdaptive, // The Fixed Block Size scheduling strategy shards the given units of work // into shards of fixed size. In case the total number of units is not // evenly divisible by 'block_size', at most one of the shards may be of // smaller size. The exact number of shards may be found by a call to // NumShardsUsedByFixedBlockSizeScheduling. // // Each shard may be executed on a different thread in parallel, depending // on the number of threads available in the pool. Note that when there // aren't enough threads in the pool to achieve full parallelism, function // calls will be automatically queued. kFixedBlockSize }; // Contains additional parameters for either the Adaptive or the Fixed Block // Size scheduling strategy. class SchedulingParams { public: explicit SchedulingParams(SchedulingStrategy strategy, absl::optional cost_per_unit, absl::optional block_size) : strategy_(strategy), cost_per_unit_(cost_per_unit), block_size_(block_size) {} SchedulingStrategy strategy() const { return strategy_; } absl::optional cost_per_unit() const { return cost_per_unit_; } absl::optional block_size() const { return block_size_; } private: // The underlying Scheduling Strategy for which this instance contains // additional parameters. SchedulingStrategy strategy_; // The estimated cost per unit of work in number of CPU cycles (or // nanoseconds if not CPU-bound). Only applicable for Adaptive scheduling // strategy. absl::optional cost_per_unit_; // The block size of each shard. Only applicable for Fixed Block Size // scheduling strategy. absl::optional block_size_; }; // Constructs a pool that contains "num_threads" threads with specified // "name". env->StartThread() is used to create individual threads with the // given ThreadOptions. If "low_latency_hint" is true the thread pool // implementation may use it as a hint that lower latency is preferred at the // cost of higher CPU usage, e.g. by letting one or more idle threads spin // wait. Conversely, if the threadpool is used to schedule high-latency // operations like I/O the hint should be set to false. // // REQUIRES: num_threads > 0 ThreadPool(Env* env, const ThreadOptions& thread_options, const std::string& name, int num_threads, bool low_latency_hint, Eigen::Allocator* allocator = nullptr); // Constructs a pool for low-latency ops that contains "num_threads" threads // with specified "name". env->StartThread() is used to create individual // threads. // REQUIRES: num_threads > 0 ThreadPool(Env* env, const std::string& name, int num_threads); // Constructs a pool for low-latency ops that contains "num_threads" threads // with specified "name". env->StartThread() is used to create individual // threads with the given ThreadOptions. // REQUIRES: num_threads > 0 ThreadPool(Env* env, const ThreadOptions& thread_options, const std::string& name, int num_threads); // Constructs a pool that wraps around the thread::ThreadPoolInterface // instance provided by the caller. Caller retains ownership of // `user_threadpool` and must ensure its lifetime is longer than the // ThreadPool instance. explicit ThreadPool(thread::ThreadPoolInterface* user_threadpool); // Waits until all scheduled work has finished and then destroy the // set of threads. ~ThreadPool(); // Schedules fn() for execution in the pool of threads. void Schedule(std::function fn); void SetStealPartitions( const std::vector>& partitions); void ScheduleWithHint(std::function fn, int start, int limit); // Returns the number of shards used by ParallelForFixedBlockSizeScheduling // with these parameters. int NumShardsUsedByFixedBlockSizeScheduling(const int64_t total, const int64_t block_size); // Returns the number of threads spawned by calling TransformRangeConcurrently // with these parameters. // Deprecated. Use NumShardsUsedByFixedBlockSizeScheduling. int NumShardsUsedByTransformRangeConcurrently(const int64_t block_size, const int64_t total); // ParallelFor shards the "total" units of work assuming each unit of work // having roughly "cost_per_unit" cost, in cycles. Each unit of work is // indexed 0, 1, ..., total - 1. Each shard contains 1 or more units of work // and the total cost of each shard is roughly the same. // // "cost_per_unit" is an estimate of the number of CPU cycles (or nanoseconds // if not CPU-bound) to complete a unit of work. Overestimating creates too // many shards and CPU time will be dominated by per-shard overhead, such as // Context creation. Underestimating may not fully make use of the specified // parallelism, and may also cause inefficiencies due to load balancing // issues and stragglers. void ParallelFor(int64_t total, int64_t cost_per_unit, const std::function& fn); // Similar to ParallelFor above, but takes the specified scheduling strategy // into account. void ParallelFor(int64_t total, const SchedulingParams& scheduling_params, const std::function& fn); // Same as ParallelFor with Fixed Block Size scheduling strategy. // Deprecated. Prefer ParallelFor with a SchedulingStrategy argument. void TransformRangeConcurrently( const int64_t block_size, const int64_t total, const std::function& fn); // Shards the "total" units of work. For more details, see "ParallelFor". // // The function is passed a thread_id between 0 and NumThreads() *inclusive*. // This is because some work can happen on the caller thread while the threads // in the pool are also being used. // // The caller can allocate NumThreads() + 1 separate buffers for each thread. // Each thread can safely write to the buffer given by its id without // synchronization. However, the worker fn may be called multiple times // sequentially with the same id. // // At most NumThreads() unique ids will actually be used, and only a few may // be used for small workloads. If each buffer is expensive, the buffers // should be stored in an array initially filled with null, and a buffer // should be allocated by fn the first time that the id is used. void ParallelForWithWorkerId( int64_t total, int64_t cost_per_unit, const std::function& fn); // Similar to ParallelForWithWorkerId above, but takes the specified // scheduling strategy into account. void ParallelForWithWorkerId( int64_t total, const SchedulingParams& scheduling_params, const std::function& fn); // Returns the number of threads in the pool. int NumThreads() const; // Returns current thread id between 0 and NumThreads() - 1, if called from a // thread in the pool. Returns -1 otherwise. int CurrentThreadId() const; // If ThreadPool implementation is compatible with Eigen::ThreadPoolInterface, // returns a non-null pointer. The caller does not own the object the returned // pointer points to, and should not attempt to delete. Eigen::ThreadPoolInterface* AsEigenThreadPool() const; private: // Divides the work represented by the range [0, total) into k shards. // Calls fn(i*block_size, (i+1)*block_size) from the ith shard (0 total, fn(i*block_size, total) is called instead. // Here, k = NumShardsUsedByFixedBlockSizeScheduling(total, block_size). // Requires 0 < block_size & fn); // underlying_threadpool_ is the user_threadpool if user_threadpool is // provided in the constructor. Otherwise it is the eigen_threadpool_. Eigen::ThreadPoolInterface* underlying_threadpool_; // eigen_threadpool_ is instantiated and owned by thread::ThreadPool if // user_threadpool is not in the constructor. std::unique_ptr> eigen_threadpool_; std::unique_ptr threadpool_device_; TF_DISALLOW_COPY_AND_ASSIGN(ThreadPool); }; 线程池实现tensorflow/core/platform/threadpool.cc 线程启动后,会不断地判断有没有分配给自己的任务,如果有则执行。如果没有就去偷其他线程的任务。Steal()函数就是用来偷任务的 struct EigenEnvironment { typedef Thread EnvThread; struct TaskImpl { std::function f; Context context; uint64 trace_id; }; struct Task { std::unique_ptr f; }; Env* const env_; const ThreadOptions thread_options_; const string name_; EigenEnvironment(Env* env, const ThreadOptions& thread_options, const string& name) : env_(env), thread_options_(thread_options), name_(name) {} //实现使用传入的env来创建线程 EnvThread* CreateThread(std::function f) { return env_->StartThread(thread_options_, name_, [=]() { //lambda把f封装了 // Set the processor flag to flush denormals to zero. port::ScopedFlushDenormal flush; // Set the processor rounding mode to ROUND TO NEAREST. port::ScopedSetRound round(FE_TONEAREST); if (thread_options_.numa_node != port::kNUMANoAffinity) { port::NUMASetThreadNodeAffinity(thread_options_.numa_node); } f(); }); } //创建任务,分配了id,并把f包装了。还创建了context Task CreateTask(std::function f) { uint64 id = 0; if (tracing::EventCollector::IsEnabled()) { id = tracing::GetUniqueArg(); tracing::RecordEvent(tracing::EventCategory::kScheduleClosure, id); } return Task{ std::unique_ptr(new TaskImpl{ std::move(f), Context(ContextKind::kThread), id, }), }; } //执行任务,执行上个函数创建的任务。 也是create里传进去的f void ExecuteTask(const Task& t) { WithContext wc(t.f->context); tracing::ScopedRegion region(tracing::EventCategory::kRunClosure, t.f->trace_id); t.f->f(); } }; ThreadPool::ThreadPool(Env* env, const ThreadOptions& thread_options, const string& name, int num_threads, bool low_latency_hint, Eigen::Allocator* allocator) { CHECK_GE(num_threads, 1); //创建了Eigen::ThreadPoolTempl,只是Env要传入。其他功能在ThreadPoolTempl里已经实现了 eigen_threadpool_.reset(new Eigen::ThreadPoolTempl( num_threads, low_latency_hint, EigenEnvironment(env, thread_options, "tf_" + name))); underlying_threadpool_ = eigen_threadpool_.get(); //创建了了threadpool_device,实际上把eigen_thread_pool传进去了。所以threadpool_device_和eigen_threadpool_共享了env创建的thread threadpool_device_.reset(new Eigen::ThreadPoolDevice(underlying_threadpool_, num_threads, allocator)); }tensorflow/core/platform/context.h tensorflow/core/platform/default/context.h enum class ContextKind { // Initial state with default (empty) values. kDefault, // Initial state inherited from the creating or scheduling thread. kThread, }; class Context { public: Context() {} Context(const ContextKind kind) {} bool operator==(const Context& other) const { return true; } }; class WithContext { public: explicit WithContext(const Context& x) {} ~WithContext() {} };Env是tensorflow用来访问操作系统的,比如对文件系统的访问。而且Env中所有接口必须支持并发操作。Env实现者要自己做好同步。外部是不做任务同步的。 核心功能 class Env { public: Env(); virtual ~Env() = default; static Env* Default(); virtual Status GetFileSystemForFile(const std::string& fname, FileSystem** result); virtual Status GetRegisteredFileSystemSchemes( std::vector* schemes); virtual Status RegisterFileSystem(const std::string& scheme, FileSystemRegistry::Factory factory); virtual Status RegisterFileSystem(const std::string& scheme, std::unique_ptr filesystem); Status SetOption(const std::string& scheme, const std::string& key, const std::string& value); Status SetOption(const std::string& scheme, const std::string& key, const std::vector& values); Status SetOption(const std::string& scheme, const std::string& key, const std::vector& values); Status SetOption(const std::string& scheme, const std::string& key, const std::vector& values); Status FlushFileSystemCaches(); Status NewRandomAccessFile(const std::string& fname, std::unique_ptr* result); Status NewRandomAccessFile(const std::string& fname, TransactionToken* token, std::unique_ptr* result) { return Status::OK(); } Status NewWritableFile(const std::string& fname, std::unique_ptr* result); Status NewWritableFile(const std::string& fname, TransactionToken* token, std::unique_ptr* result) { return Status::OK(); } Status NewAppendableFile(const std::string& fname, std::unique_ptr* result); Status NewAppendableFile(const std::string& fname, TransactionToken* token, std::unique_ptr* result) { return Status::OK(); } Status NewReadOnlyMemoryRegionFromFile( const std::string& fname, std::unique_ptr* result); Status NewReadOnlyMemoryRegionFromFile( const std::string& fname, TransactionToken* token, std::unique_ptr* result) { return Status::OK(); } Status FileExists(const std::string& fname); Status FileExists(const std::string& fname, TransactionToken* token) { return Status::OK(); } bool FilesExist(const std::vector& files, std::vector* status); bool FilesExist(const std::vector& files, TransactionToken* token, std::vector* status) { return true; } Status GetChildren(const std::string& dir, std::vector* result); Status GetChildren(const std::string& dir, TransactionToken* token, std::vector* result) { return Status::OK(); } virtual bool MatchPath(const std::string& path, const std::string& pattern) = 0; virtual Status GetMatchingPaths(const std::string& pattern, std::vector* results); Status GetMatchingPaths(const std::string& pattern, TransactionToken* token, std::vector* results) { return Status::OK(); } /// Deletes the named file. Status DeleteFile(const std::string& fname); Status DeleteFile(const std::string& fname, TransactionToken* token) { return Status::OK(); } Status DeleteRecursively(const std::string& dirname, int64_t* undeleted_files, int64_t* undeleted_dirs); Status DeleteRecursively(const std::string& dirname, TransactionToken* token, int64_t* undeleted_files, int64_t* undeleted_dirs) { return Status::OK(); } Status RecursivelyCreateDir(const std::string& dirname); Status RecursivelyCreateDir(const std::string& dirname, TransactionToken* token) { return Status::OK(); } Status CreateDir(const std::string& dirname); Status CreateDir(const std::string& dirname, TransactionToken* token) { return Status::OK(); } Status DeleteDir(const std::string& dirname); Status DeleteDir(const std::string& dirname, TransactionToken* token) { return Status::OK(); } /// Obtains statistics for the given path. Status Stat(const std::string& fname, FileStatistics* stat); Status Stat(const std::string& fname, TransactionToken* token, FileStatistics* stat) { return Status::OK(); } Status IsDirectory(const std::string& fname); Status HasAtomicMove(const std::string& path, bool* has_atomic_move); Status GetFileSize(const std::string& fname, uint64* file_size); Status GetFileSize(const std::string& fname, TransactionToken* token, uint64* file_size) { return Status::OK(); } Status RenameFile(const std::string& src, const std::string& target); Status RenameFile(const std::string& src, const std::string& target, TransactionToken* token) { return Status::OK(); } Status CopyFile(const std::string& src, const std::string& target); Status CopyFile(const std::string& src, const std::string& target, TransactionToken* token) { return Status::OK(); } Status StartTransaction(const std::string& filename, TransactionToken** token) { *token = nullptr; return Status::OK(); } Status AddToTransaction(const std::string& path, TransactionToken* token) { return Status::OK(); } Status GetTokenOrStartTransaction(const std::string& path, TransactionToken** token) { *token = nullptr; return Status::OK(); } Status GetTransactionForPath(const std::string& path, TransactionToken** token) { *token = nullptr; return Status::OK(); } Status EndTransaction(TransactionToken* token) { return Status::OK(); } std::string GetExecutablePath(); bool LocalTempFilename(std::string* filename); bool CreateUniqueFileName(std::string* prefix, const std::string& suffix); virtual std::string GetRunfilesDir() = 0; virtual uint64 NowNanos() const { return EnvTime::NowNanos(); } virtual uint64 NowMicros() const { return EnvTime::NowMicros(); } virtual uint64 NowSeconds() const { return EnvTime::NowSeconds(); } virtual void SleepForMicroseconds(int64_t micros) = 0; int32 GetProcessId(); virtual Thread* StartThread(const ThreadOptions& thread_options, const std::string& name, std::function fn) TF_MUST_USE_RESULT = 0; virtual int32 GetCurrentThreadId() = 0; virtual bool GetCurrentThreadName(std::string* name) = 0; virtual void SchedClosure(std::function closure) = 0; virtual void SchedClosureAfter(int64_t micros, std::function closure) = 0; virtual Status LoadDynamicLibrary(const char* library_filename, void** handle) = 0; virtual Status GetSymbolFromLibrary(void* handle, const char* symbol_name, void** symbol) = 0; virtual std::string FormatLibraryFileName(const std::string& name, const std::string& version) = 0; virtual void GetLocalTempDirectories(std::vector* list) = 0; private: std::unique_ptr file_system_registry_; TF_DISALLOW_COPY_AND_ASSIGN(Env); };tensorflow/core/platform/filesystem.h class FileSystemRegistry { public: typedef std::function Factory; virtual ~FileSystemRegistry() = default; virtual tensorflow::Status Register(const std::string& scheme, Factory factory) = 0; virtual tensorflow::Status Register( const std::string& scheme, std::unique_ptr filesystem) = 0; virtual FileSystem* Lookup(const std::string& scheme) = 0; virtual tensorflow::Status GetRegisteredFileSystemSchemes( std::vector* schemes) = 0; };tensorflow/core/platform/filesystem.h中定义了FileSystem接口。内容与Env中一样,就不列出来 tensorflow/core/platform/null_file_system.h中定义了NullFileSystem,每个接品都返回:错误,未实现。其他实现可以直接继承这个而不是FileSystem来实现,这样就避免写大量未实现的接口。 tensorflow/core/platform/windows/windows_file_system.h中实现了windows文件系统 [随机,追加]x[读,写] 4种,在tensorflow/core/platform/filesystem.h中定义了接口 看接口,没有随机写。只有追加写。还有只读内存映射文件 ///随机读写,在Env中NewRandomAccessFile中返回这个类的对象 class RandomAccessFile { public: RandomAccessFile() {} virtual ~RandomAccessFile() = default; virtual tensorflow::Status Name(StringPiece* result) const { return errors::Unimplemented("This filesystem does not support Name()"); } virtual tensorflow::Status Read(uint64 offset, size_t n, StringPiece* result, char* scratch) const = 0; #if defined(TF_CORD_SUPPORT) /// \brief Read up to `n` bytes from the file starting at `offset`. virtual tensorflow::Status Read(uint64 offset, size_t n, absl::Cord* cord) const { return errors::Unimplemented( "Read(uint64, size_t, absl::Cord*) is not " "implemented"); } #endif private: TF_DISALLOW_COPY_AND_ASSIGN(RandomAccessFile); }; class WritableFile { public: WritableFile() {} virtual ~WritableFile() = default; virtual tensorflow::Status Append(StringPiece data) = 0; #if defined(TF_CORD_SUPPORT) // \brief Append 'data' to the file. virtual tensorflow::Status Append(const absl::Cord& cord) { for (StringPiece chunk : cord.Chunks()) { TF_RETURN_IF_ERROR(Append(chunk)); } return tensorflow::Status::OK(); } #endif virtual tensorflow::Status Close() = 0; virtual tensorflow::Status Flush() = 0; virtual tensorflow::Status Name(StringPiece* result) const { return errors::Unimplemented("This filesystem does not support Name()"); } virtual tensorflow::Status Sync() = 0; virtual tensorflow::Status Tell(int64_t* position) { *position = -1; return errors::Unimplemented("This filesystem does not support Tell()"); } private: TF_DISALLOW_COPY_AND_ASSIGN(WritableFile); }; //内存映射文件接口 class ReadOnlyMemoryRegion { public: ReadOnlyMemoryRegion() {} virtual ~ReadOnlyMemoryRegion() = default; /// \brief Returns a pointer to the memory region. virtual const void* data() = 0; /// \brief Returns the length of the memory region in bytes. virtual uint64 length() = 0; };tensorflow/core/platform/ram_file_system.h access timer related operations. class EnvTime { public: static constexpr uint64 kMicrosToPicos = 1000ULL * 1000ULL; static constexpr uint64 kMicrosToNanos = 1000ULL; static constexpr uint64 kMillisToMicros = 1000ULL; static constexpr uint64 kMillisToNanos = 1000ULL * 1000ULL; static constexpr uint64 kNanosToPicos = 1000ULL; static constexpr uint64 kSecondsToMillis = 1000ULL; static constexpr uint64 kSecondsToMicros = 1000ULL * 1000ULL; static constexpr uint64 kSecondsToNanos = 1000ULL * 1000ULL * 1000ULL; EnvTime() = default; virtual ~EnvTime() = default; /// \brief Returns the number of nano-seconds since the Unix epoch. static uint64 NowNanos(); /// \brief Returns the number of micro-seconds since the Unix epoch. static uint64 NowMicros() { return NowNanos() / kMicrosToNanos; } /// \brief Returns the number of seconds since the Unix epoch. static uint64 NowSeconds() { return NowNanos() / kSecondsToNanos; } /// \brief A version of NowNanos() that may be overridden by a subclass. virtual uint64 GetOverridableNowNanos() const { return NowNanos(); } /// \brief A version of NowMicros() that may be overridden by a subclass. virtual uint64 GetOverridableNowMicros() const { return GetOverridableNowNanos() / kMicrosToNanos; } /// \brief A version of NowSeconds() that may be overridden by a subclass. virtual uint64 GetOverridableNowSeconds() const { return GetOverridableNowNanos() / kSecondsToNanos; } }; //linux 下是PosixEnv: tensorflow/core/platform/default/env.cc Env* Env::Default() { static Env* default_env = new PosixEnv; return default_env; } //posixEnv也在env.cc中 class PosixEnv : public Env //windows下就会使用windows的Env //在tensorflow/core/platform/windows/env.ccOriginal: https://blog.csdn.net/wyg_031113/article/details/124523860 Author: wyg_031113 Title: tensorflow之常用工具类 相关阅读1 Title: 点云压缩基础目录 点云的概念、来源及应用 压缩点云主流平台 压缩方法分类 直观压缩效果 处理常用的工具 参考链接 点云的概念、来源及应用点云就是一堆点,可以用坐标表示物体形状,通常由三维坐标(XYZ )、激光反射强度(reflectance )和颜色信息(RGB )中的一种或多种组成。 常见来源:雷达扫描的、CAD 生成的、RGB-D (带深度信息的RGB 图片;RGBD 设备是获取点云的设备,比如PrimeSense 公司的PrimeSensor 、微软的Kinect 、华硕的XTionPRO 。);可用于定位、物体检测分类、重建物体(游戏etc.)、面部检测重建、手势识别、姿态检测等。现在所说的点云几乎全是3D 的点云.
点云在数学本质上是一个矩阵; 优点:简单明了易处理 缺点:稀疏;不规则(难以搜索邻居);缺少纹理信息;无序(深度学习难处理,不同顺序的输入矩阵能得到完全不同的结果);旋转不变性(点云数据表三维物体,所有整体数据的旋转不会改变数据特征,但数学上难以识别旋转后矩阵) 按维度可分为二维(从3D 信息映射至2 D )和三维(采用稳定结构对点云所在的空间进行分解,再对该结构进行预测与变换以减少冗余【热点】) 压缩点云主流平台点云数据很大要压缩。压缩点云的平台国际上有MPEG 的基于几何的点云压缩(Geometry Point Cloud Compression ,G-PCC)和基于视频的点云压缩(Video Point Cloud Compression, V-PCC)两个平台;国内有AVS 的AVS-PCC 平台。V-PCC 旨在为需要实时解码的应用提供低复杂度的解码能力,如虚拟/增强现实、沉浸式通信等。G-PCC 可为自主驾驶、3D 地图和其他利用激光雷达生成的点云(或类似内容)的应用程序的部署提供高效的无损和有损压缩。 V-PCC 的整体框架如下图所示,类似于传统的三维视频,整体编码过程可分为四个步骤:补丁生成、几何/纹理图像生成、附加数据压缩和视频压缩。视频压缩过程可以采用已发布的视频编码标准H.265/HEVC 、H.266/VVC 进行压缩。
G-PCC 的流程如图4 。首先体素化,即对输入的三维位置进行积分来得到位置表示,通过创建一个边界框来计算对象在所有xyz 方向上的最大尺寸,然后将最大尺寸用作给定比特范围的最大值(即10 位表示中的1023 )。其次创建八叉树。八叉树非常适合于稀疏采样的点云,八叉树构建过程如图5 所示。当完成了体素化,每个3D 点(或位置)可以表示为八叉树中的叶节点。在这种情况下可以实现无损表示。对于有损压缩,叶节点可以是包含一个或多个点的大体素。图6 是"斯坦福兔子"的体素化结果。八叉树形成后,每个含有一个或多个点的体素通过预测、变换和量化等常规压缩过程进行编码。最后,编码后的数据经过熵编码过程。
图4
图5
图6 G-PCC 的框架如下图所示
具体的一个八叉树与数据结构之间的对应关系如下图。当前八叉树深度为2 ,包围框左上角划分三个红色被占点。即这一级别有三个子立方体被占用。占用码为0110 0001
LOD 生成:假设P0 为起始点,计算各点的欧氏距离,遍历所有点之间的距离,根据点与点之间的距离,划分层级。如图所示,LOD1 层级,P0,P2,P8,P9 为同一层级,因为它们之间的距离相较于其他点之间的距离要>某个阈值。LOD2 层级中的点又包含LOD1 层级的点,往后以此类推。 在实际的PCC中,LOD生成+邻居查找是最费时的模块,占总耗时60~70%,其次是预测和变换,分别各占约3%编码时间。
lifting transform 基于插值的预测(Predict Transform):按照LoD 生成过程定义的顺序进行差分编码,然后预测颜色信息。注意,只有已经编码/解码的点才能作为预测的参考点。对于第i 个点,可以通过其k 个最近邻的线性组合来预测其属性值:提升变换(LT ):为了进一步提高编码效率,[41]中提出了LT 。该方法的基础是使下层LOD 中的点更有影响力(因为它们经常用于进行预测)。
传统方法:先去除一部分冗余,再使用变换与量化将空间域的点云变换到频域并压缩变换系数,再经过熵编码进一步压缩比特流。优点:简单直观易理解、可控易debug ;缺点:语义难建模,用户不友好 深度方法:通过卷积神经网络将点云数据编码为隐藏表示,再量化隐藏特征,基于学习熵模型和熵编码将上下文输入的情况下每个符号出现的概率压缩并产生比特流。优点:简单高效、数据驱动;缺点:不可解释、黑盒不可控、需要硬件支持(GPU/FPGA etc.)、因为门槛低所以难找工作.. 直观压缩效果
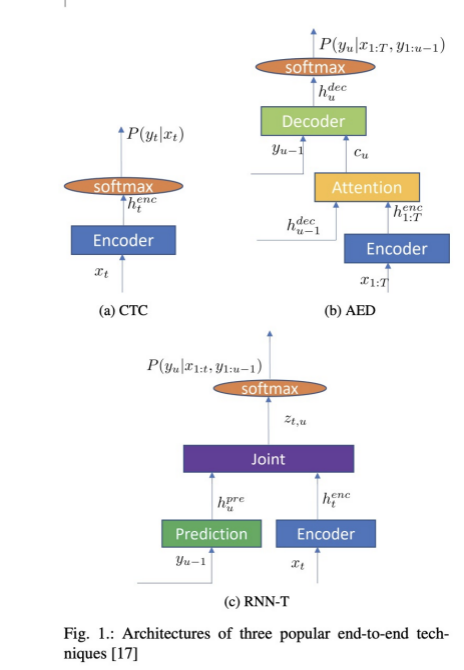
低层次处理方法: ①滤波方法:双边滤波、高斯滤波、条件滤波、直通滤波、随机采样一致性滤波。②关键点:ISS3D 、Harris3D 、NARF ,SIFT3D 中层次处理方法: ①特征描述:法线和曲率的计算、特征值分析、SHOT 、PFH 、FPFH 、3D Shape Context 、Spin Image ②分割与分类: 分割:区域生长、Ransac 线面提取、全局优化平面提取 K-Means 、Normalize Cut (Context based ) 3D Hough Transform(线、面提取)、连通分析 分类:基于点的分类,基于分割的分类,基于深度学习的分类(PointNet ,OctNet ) 高层次处理方法: ①配准:点云配准分为粗配准(Coarse Registration )和精配准(Fine Registration )两个阶段。 精配准的目的是在粗配准的基础上让点云之间的空间位置差别最小化。应用最为广泛的精配准算法应该是ICP 以及ICP 的各种变种(稳健ICP 、point to plane ICP 、Point to line ICP 、MBICP 、GICP 、NICP )。 粗配准是指在点云相对位姿完全未知的情况下对点云进行配准,可以为精配准提供良好的初始值。当前较为普遍的点云自动粗配准算法包括基于穷举搜索的配准算法和基于特征匹配的配准算法。 基于穷举搜索的配准算法:遍历整个变换空间以选取使误差函数最小化的变换关系或者列举出使最多点对满足的变换关系。如RANSAC 配准算法、四点一致集配准算法(4-Point Congruent Set, 4PCS )、Super4PCS 算法等...... 基于特征匹配的配准算法:通过被测物体本身所具备的形态特性构建点云间的匹配对应,然后采用相关算法对变换关系进行估计。如基于点FPFH 特征的SAC-IA 、FGR 等算法、基于点SHOT 特征的AO 算法以及基于线特征的ICL 等... ②SLAM 图优化 Ceres (Google 的最小二乘优化库,很强大),g2o 、LUM 、ELCH 、Toro 、SPA SLAM 方法:ICP 、MBICP 、IDC 、likehood Field 、NDT ③三维重建 泊松重建、Delaunay triangulations 、表面重建,人体重建,建筑物重建,树木重建。结构化重建:不是简单的构建一个Mesh 网格,而是为场景进行分割,为场景结构赋予语义信息。场景结构有层次之分,在几何层次就是点线面。实时重建:重建植被或者农作物的4D (3D+时间)生长态势;人体姿势识别;表情识别; ④点云数据管理:点云压缩,点云索引(KD 、Octree ),点云LOD (金字塔),海量点云的渲染 参考链接【点云阅读笔记】点云压缩综述_Jonathan_Paul 10的博客-CSDN博客 点云压缩——点云压缩相关知识介绍_Surplus°的博客-CSDN博客_点云压缩 点云压缩现状及发展趋势_洌泉_就这样吧的博客-CSDN博客_点云压缩 点云概念与点云处理_Daisey_tang的博客-CSDN博客_点云 三维点云PPT.rar_点云PCA方向中轴线-互联网文档类资源-CSDN下载 GPCC入门说明_凡心_07的博客-CSDN博客 G-PCC点云压缩实验结果_喳喳虾子的博客-CSDN博客 Original: https://blog.csdn.net/dongmie1999/article/details/123515433 Author: dongmie1999 Title: 点云压缩基础 相关阅读2 Title: 语音识别(ASR)论文优选:端到端ASR综述Recent Advances in End-to-End Automatic Speech Recognition 声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。Recent Advances in End-to-End Automatic Speech Recognition 本篇综述是微软JINYU LI在2021.11.02更新的文章,主要从产业界的角度对最近几年端到端ASR的发展进行总结,感兴趣的读者可以阅读该文章,具体的文章链接 https://arxiv.org/pdf/2111.01690.pdf 一 介绍 相对于传统的混合模型的ASR,端到端E2E的ASR系统具备以下优点:1)混合模型的每个模块优化都是单独优化,不能保证获取全局最优,而E2E的ASR使用一个优化函数来优化整个网络;2)E2E的ASR直接输出character或者words,简化流程;而混合模型的每个模块都需要相应的专业知识;3)相对于混合模型,e2e模型使用一个网络进行识别,整个系统更加紧凑,可以更便捷在设备上部署。虽然端到端的ASR具备以上优点,而且在很多benchmarks超过混合模型,但混合模型在工业界依然占据主要市场。混合模型在工业界发展数十年,在streaming,latency,adaptation capability,accuracy等方面的方案技术有较厚的积累,e2e的asr要想替代混合模型,必须在以上诸多方面超越混合模型。本文为了促进e2e的asr方案落地,从工业界的角度对近年来的e2e的方案进行总结,更好的应对以上的挑战。 二 端到端模型(end-to-end models) 现在主流的E2E的ASR模型主要包括 a)CTC (connectionist temporak classification) b) AED(attention-based Encoder-Decoder) c)RNN-T(recurrent neural network Transducer 。其主要网络结构如图一所示
其中CTC的结构如图1(a)所示,本文简单举例ctc path如图2
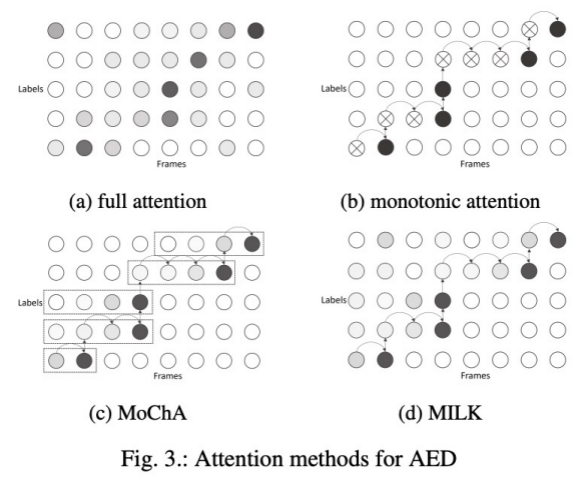
图1(b)为AED模型,其为了实现streaming方式,需要对attention进行处理,本文列举了AED使用的四种attention,如图3所示
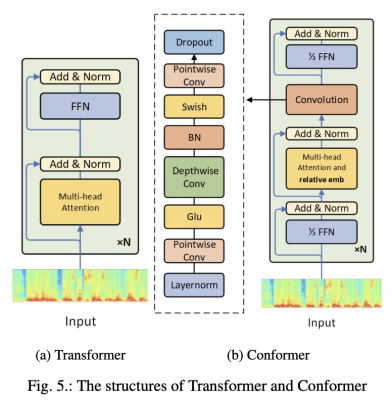
RNN-T主要如图1(c)所示。以上结构详细信息请读者阅读该文章。 三 Encoder 端到端的ASR主要部分encoder,该部分主要把输入信息进行高级的特征表示,本文对encoder使用的结构类型进行总结 A) Lstm B) Transformer 图5展示了transfomer和目前流行的confomer结构。
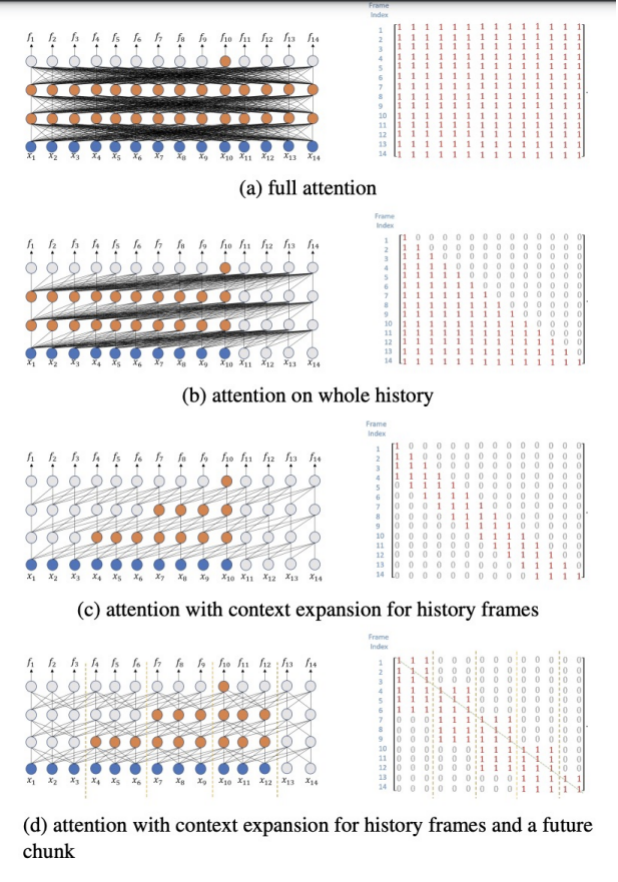
为了实现streaming ASR,需要在attention使用mask策略,使其只看到部分的context。图6展示了不同的attenion及对应的mask矩阵。
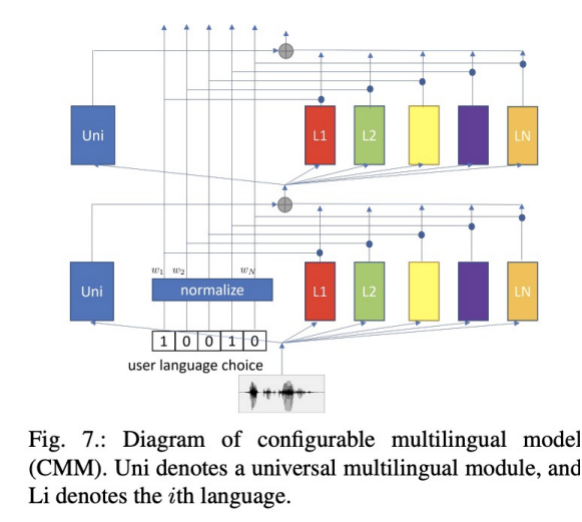
四 其它的训练准则 A) teacher-student learning B) Minimum Word Error Rate Traing 五 多语言模型 本部分主要介绍多语言模型以及方案,主要介绍了使用语言ID(LID)的优劣和CMM方案,以及code-switching在句内和句间的挑战。
六 自适用 A) speaker adaptation 主要使ASR在对应的个人效果更好,常用的方案使用speaker embeddings对应的语料进行微调,但更多情况下是如何处理每个说话人拥有较少语料。而且本部分也提到如何在用户端进行训练,不需要把用户数据发送到服务端,从而保证用户数据安全。 B)Domain Adaptation 该部分主要介绍Domain Adaptation,其主要介绍使用文本进行LM方案和TTS-based的方案。
C) Customization
七 Advanced Models A)非自回归模型Non-Autoregressive Models
B) Unified Models 流式和非流式方案的结合,动态计算等等
C)Two-pass Models
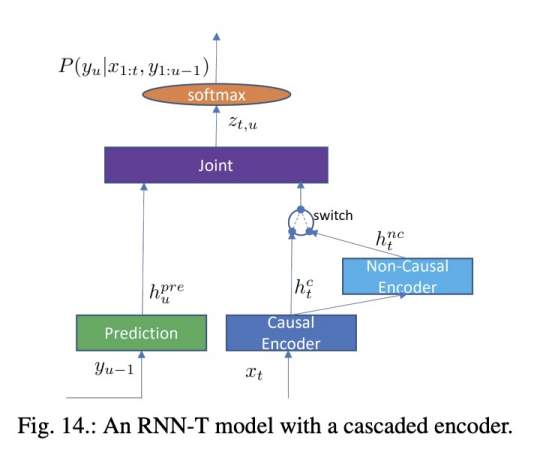
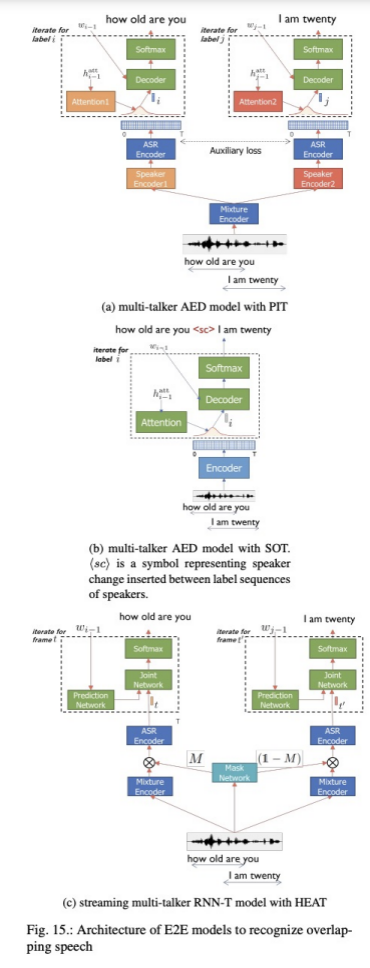
D) Multi-talker Models
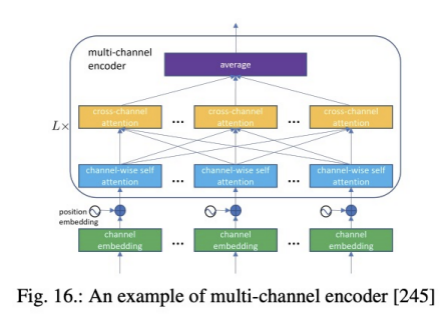
E)Multi-channel Models
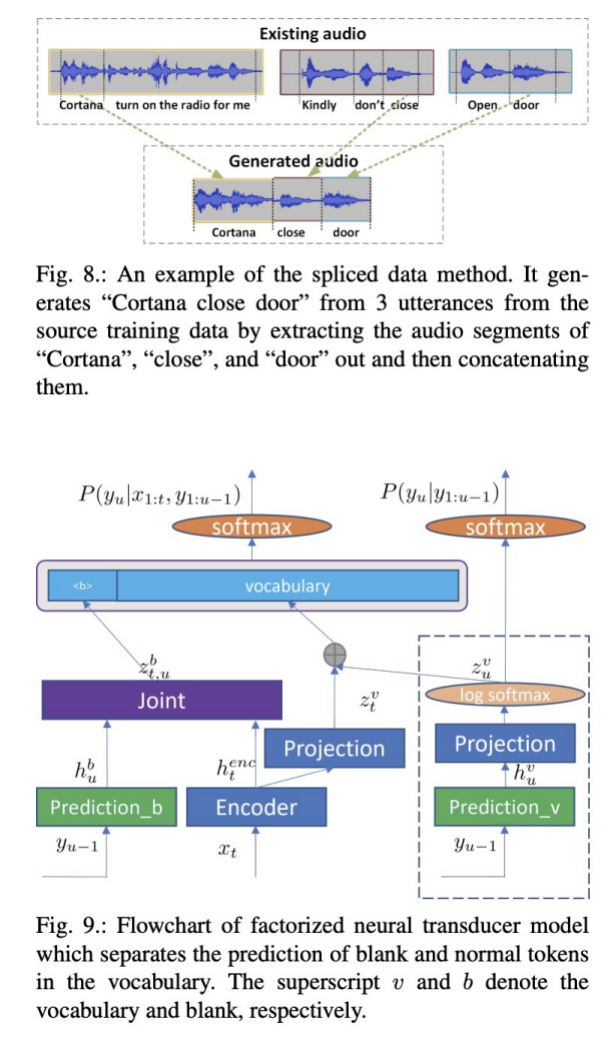
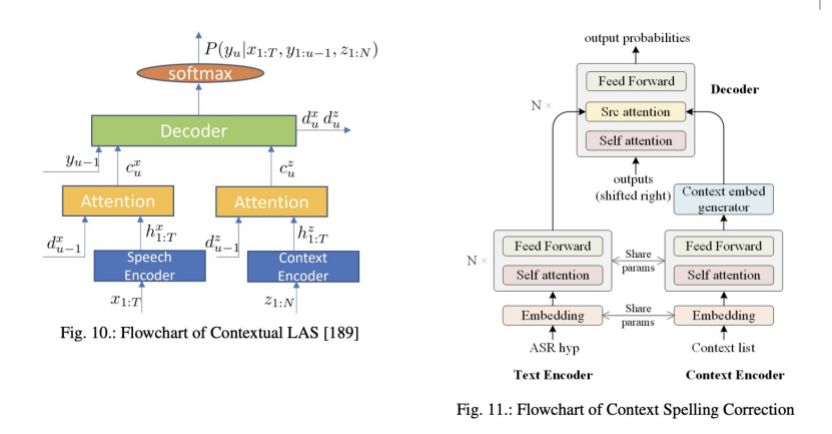
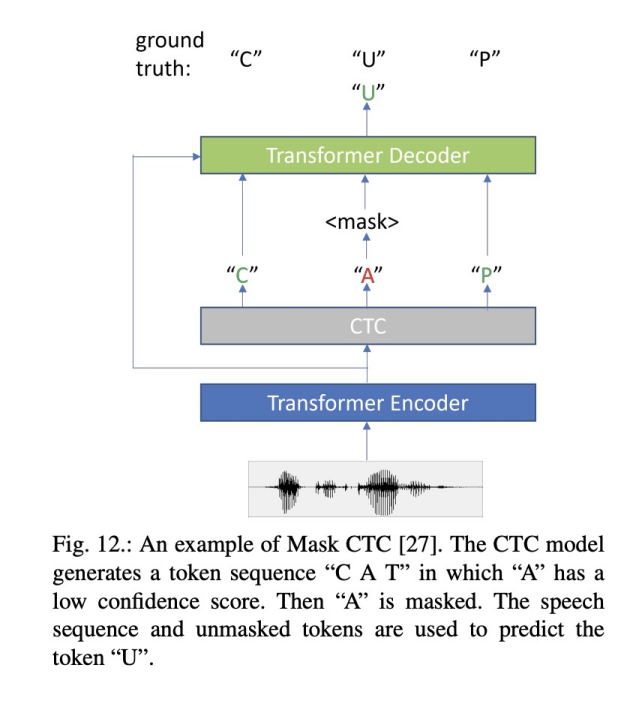
八 多种多样的主题 a) 更多语音的toolkits b) 系统使用的建模单元:characters,word-piece,words等等 c) limited data,data augmentation, self-supervised等等 d) 模型部署的研究,模型压缩,量化等等 e) asr模型的输入直接使用waveform而不是声学特征等等。 f) 鲁棒性的研究 九 总结 本文列举端到端ASR相比混合模型方案的优势以及劣势。为了促进端到端对混合模型在工业界的替代,本文详细描述了端到端ASR的模型、挑战以及各种解决方案。最后作者也可列举端到端ASR未来的挑战。 Original: https://blog.csdn.net/liyongqiang2420/article/details/121148536 Author: 我叫永强 Title: 语音识别(ASR)论文优选:端到端ASR综述Recent Advances in End-to-End Automatic Speech Recognition 相关阅读3 Title: 氨基酸分子结构和原子命名 技术背景在前面的一篇文章中,我们讲述了蛋白质的组成结构,一共是20种氨基酸。由这20种氨基酸的排列组合,可以得到一条相应的蛋白质链,而这条蛋白质链经过各种螺旋和折叠,会得到一个最终稳定的蛋白质构象,也是我们日常生活中所能够接触到的蛋白质的存在形态。那么在上一篇文章中的表格里面,我们可以看到众多的氨基酸在蛋白质链的中间时候的构象,本文将要讲述一些其他位置所对应的构象,以及其中原子的命名法则。 同残基不同位置的构象即使是同一个残基,在位于蛋白质链的不同位置时,也有可能表现出不同的构象。比如在蛋白质的头部时,有可能会出现一些氢离子跟氮原子的成键。而残基位于蛋白质链的中部时,我们往往会略去其中的一个(H_2O),跟两侧的其他残基形成2个肽键。具体结构如下表所示: 英文名 中文名 三字母缩写 单字母缩写 三维结构图 N起始点结构图 C终点结构图 Alanine 丙氨酸 Ala A
Arginine 精氨酸 Arg R
Asparagine 天冬酰胺 Asn N
Asparticacid 天冬氨酸 Asp D
Cysteine 半胱氨酸 Cys C
Glutamine 谷氨酰胺 Gln Q
Glutamicacid 谷氨酸 Glu E
Glycine 甘氨酸 Gly G
Histidine 组氨酸 His H
Isoleucine 异亮氨酸 Ile I
Leucine 亮氨酸 Leu L
Lysine 赖氨酸 Lys K
Methionine 甲硫氨酸(蛋氨酸) Met M
Phenylalanine 苯丙氨酸 Phe F
Proline 脯氨酸 Pro P
Serine 丝氨酸 Ser S
Threonine 苏氨酸 Thr T
Tryptophan 色氨酸 Trp W
Tyrosine 酪氨酸 Tyr Y
Valine 缬氨酸 Val V
当我们把这些生成的构象存储成PDB文件时,我们会发现其中每一个原子在所处的残基内的命名都是唯一的。我们以丙氨酸为例,来解读一下其中的命名法则。 在上面这个结构图中,绿色的代表碳原子,灰色代表氢原子,红色代表氧原子,蓝色代表氮原子。一般我们先找到当前氨基酸的氮基碳原子,由于丙氨酸中只有一个氮原子,因此与氮原子成键的这个碳原子就是我们要找的氮基碳原子,我们将其命名为"CA",对应的氮原子命名为"N"。一般我们会发现,这个氮基碳原子并不是位于主链的顶点,也就是在氨基酸内部还会连接至少2个其他的重原子。我们找到其连接的带氧原子的那个碳原子,将其命名为"C",对应的氧原子命名为"O","CA"表示的是这个碳原子处于(\alpha)位。另外一个被氮基碳原子所连接的碳原子,被命名为"CB",也就是(\beta)位的碳。按照与氮基碳原子的远近关系,分别用"A,B,G,D,E,Z,H"来标记这些重原子,对应的希腊字母是"(\alpha,\beta,\gamma,\delta,\epsilon,\zeta,\eta)"。那么这就是丙氨酸的所有重原子在PDB文件中的命名,如下图是一个含有丙氨酸的蛋白质的PDB文件。 对于氢原子来说,命名是取决于其所连接的碳原子的位置,比如连接氮的氢原子,可以直接命名为"H",连接(\alpha)碳的氢原子,可以命名为"HA"。而(\beta)位的碳连接了3个氢原子,因此需要加上额外的数字标记,那么对应的命名就是"HB1,HB2,HB3"。并且,这种加数字编号的方法对于重原子也是同样适用的,比如下图所示的色氨酸: 同样的方法我们可以找到氮基碳原子和(\alpha)位的氧基碳原子,这样我们就可以按照连接的远近关系对其中的重原子进行命名。比如我们可以(\beta)位有1个碳,(\gamma)位也是1个碳,(\delta)位是2个碳,(\epsilon)位有1个氮原子和2个碳原子,(\zeta)位有2个碳原子,(\eta)位有1个碳原子。那么综合下来,我们将会得到的重原子的命名就是:"C,N,O,CA,CB,CG,CD1,CD2,NE1,CE2,CE3,CZ2,CZ3,CH2",下图是一个真实蛋白质PDB文件中的色氨酸的命名: 总结概要PDB格式的文件是最常用于存储蛋白质构象的一种,其中也是以各个氨基酸(残基)为基本单位,在氨基酸内部对原子进行唯一性的命名。本文先通过展示各种氨基酸在蛋白质链的不同位置的结构,介绍各类氨基酸的基础构象。再通过丙氨酸和色氨酸两个案例,详细介绍了在蛋白质链的中的各种氨基酸内部的原子命名法则。需要注意的是,atom_name和atom_type是不一样的,atom_name是一个唯一的标识符,atom_type则是用于导出力场参数的重要标记。 版权声明本文首发链接为:https://www.cnblogs.com/dechinphy/p/cnaminos.html 作者ID:DechinPhy 更多原著文章请参考:https://www.cnblogs.com/dechinphy/ 打赏专用链接:https://www.cnblogs.com/dechinphy/gallery/image/379634.html 腾讯云专栏同步:https://cloud.tencent.com/developer/column/91958 CSDN同步链接:https://blog.csdn.net/baidu_37157624?spm=1008.2028.3001.5343 51CTO同步链接:https://blog.51cto.com/u_15561675 Original: https://www.cnblogs.com/dechinphy/p/cnaminos.html Author: DECHIN Title: 氨基酸分子结构和原子命名 |
 重建一个3D 物体的几种方法:面、体素网格和八叉树(上图从左至右)
重建一个3D 物体的几种方法:面、体素网格和八叉树(上图从左至右)

































【本文地址】
今日新闻 |
推荐新闻 |