学习数据结构:深入了解串的定义和实际应用 |
您所在的位置:网站首页 › plsql查看函数定义 › 学习数据结构:深入了解串的定义和实际应用 |
学习数据结构:深入了解串的定义和实际应用
|
三种特殊的线性表——栈、队列、串 从数据结构角度看,栈和队列是操作受限的线性表,他们的逻辑结构相同。 串是重要的非数值处理对象,它是以字符作为数据元素的线性表。 串类型的定义串:即字符串,是由零个或多个字符组成的有限序列,是数据元素为单个字符的特殊线性表。
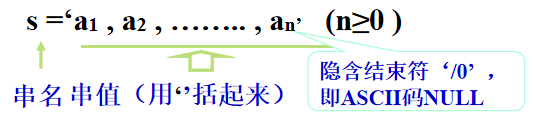
串长:串中字符个数(n≥0). n=0 时称为空串 。 空白串:由一个或多个空格符组成的串。 字符位置:字符在串中的序号。 串相等:串长度相等,且对应位置上字符相等。 子串:串中任意个连续的字符组成的子序列。 主串:包含子串的串。 子串的位置:子串的第一个字符在主串中的序号。 串的数据对象约束为某个字符集。 串是有限长的字符序列,由一对双引号相括,如: “a string”
StrInsert (&S, pos, T) (插入) 初始条件:串 S 和 T 均存在,1≤pos≤StrLength(S)+1。 操作结果:在串 S 的第 pos 个字符之前插入串T。例如:S = "chater",T = "rac ", 则执行 StrInsert (S, 4, T) ,得到 S = "character" StrDelete (&S, pos, len) (删除) 初始条件:串 S 存在,且1≤pos≤StrLength(S)-len+1。 操作结果:从串 S 中删除第 pos 个字符起长度为len的子串。 StrAssign (&T, chars) (串赋值) 初始条件:chars 是字符串常量。 操作结果:把 chars 赋为 T 的值。 StrCopy (&T, S) (串复制) 初始条件:串 S 存在。 操作结果:由串 S 复制得串 T。 Concat (&T, S1, S2) (串联接) 初始条件:串 S1 和 S2 存在。 操作结果: T 为由串 S1 和串 S2 联接所得的串。例如: Concat( T, "man", "kind") 求得 T = "mankind" Concat( T, "kind", "man") 求得 T = "kindman" StrCompare (S, T) (串比较) 初始条件:串 S 和 T 都存在。 操作结果:由串 S > T, 则返回值>0;若S=T,则返回值=0;由串 S 例如:StrCompare(" data ", " state ") 0 Replace ( S, T, V) (串置换) 初始条件:串 S, T 和 V 均已存在,且 T 是非空串。 操作结果:用 V 替换主串 S 中出现的所有与(模式串)T 相等的不重叠的子串。例如:假设 S = "abcaabcaaabca", T = "bca ",若 V = "x ", 则经置换后得到 S = "axaxaax " SubString (&Sub, S, pos, len) (求子串) 初始条件:串 S 存在,1≤pos≤StrLength(S) 且 0≤len≤StrLength(S)-pos+1。 操作结果: 以 Sub 返回串 S 中第 pos 个字符起长度为 len 的子串。例如:子串为“串”中的一个字符子序列.SubString ( sub, "commander ", 4, 3)求得 sub = "man ";SubString( sub, "commander ", 1, 9)求得 sub = "commander ";SubString( sub, "commander ", 9, 1)求得 sub = "r ". Index ( S, T, pos) (定位函数) 初始条件:串 S 和 T 存在,且 T 是非空串,1≤pos≤StrLength(S)。 操作结果:若主串 S 中存在和串 T 值相同的子串,则返回它在主串 S 中第 pos个字符之后第一次出现的位置; 否则函数值为0。 “子串在主串中的位置”意指子串中的第一个字符在主串中的“位序” 。假设 S = "abcaabcaaabc ", T = 'bca “,Index(S, T, 1) = 2;Index(S, T, 3) = 6;Index(S, T, 8) = 0; 串赋值 StrAssign 串比较 StrCompare、求串长 StrLength、 串联接 Concat 以及求子串 SubString 等5种操作构成串类型的最小操作子集。 串的逻辑结构和线性表极为相似,区别仅在于串的数据对象约束为字符集。 串的基本操作和线性表有很大差别。 在线性表的基本操作中,大多以“单个元素”作为操作对象; 而在串的基本操作中,通常以“串的整体”作为操作对象。 串的表示和实现串有三种机内表示方法: 顺序存储 定长顺序存储表示 ——用一组地址连续的存储单元存储串值的字符序列。 堆分配存储表示 ——用一组地址连续的存储单元存储串值的字符序列,但存储空间是在程序执行过程中动态分配而得。 链式存储 串的块链存储表示 ——链式方式存储 定长顺序存储特点: 用一组连续的存储单元来存放串,直接使用定长的字符数组来定义,数组的上界预先给出,故称为静态存储分配。 例如: #define Maxstrlen 255 //用户可用的最大串长 typedef unsigned char SString[ Maxstrlen+1 ] ; SString s; //s是一个可容纳255个字符的顺序串。 注: 一般用SString[0]来存放串长信息; C语言约定用字符数组存储字符串常量时,自动在串尾加结束符 ‘ \0’,以利操作加速,但不计入串长; char c[10]=“abcde” 若字符串超过Maxstrlen 则自动截断(因为静态数组存不 进去)。 1) 串连接 Concat(&T, S1,S2) Status Concat ( Sstring &T, Sstring S2){if ( S1[0] +S2[0] } // Concat 2) 求子串函数SubString (&Sub, S, pos, len)----将串S中从第pos个字符开始长度为len的字符序列复制到串Sub中(注:串Sub的预留长度与S一样) Status SubString (SString &sub, SString S, int pos, int len ){if (posS[0] || lenS[0]-pos+1)return ERROR; //pos不合法则警告Sub[1……len] = S [pos……pos+len-1];Sub[0]=len;return OK;} 想存放超长字符串怎么办?——静态数组有缺陷!改用动态分配的一维数组——“堆”! 堆分配存储特点:仍用一组连续的存储单元来存放串,但存储空间是在程序执行过程中动态分配而得。 思路:利用malloc函数合理预设串长空间。 特点: 若在操作中串值改变,还可以利用realloc函数按新串长度增加(堆砌)空间。 约定:所有按堆存储的串,其关键信息放置在: Typedef struct {char *ch; // 若非空串,按串长分配空间; 否则 ch = NULLint length; //串长度}HString 1)用“堆”实现串插入操作 Status StrInsert ( HString &S, int pos, HString T ) {//在串S的第pos个字符之前(包括尾部)插入串Tif (posS.length+1) return ERROR; //pos不合法则告警if(T.length){ //只要串T不空,就需要重新分配S空间,以便插入Tif (!(S.ch=(char*)realloc (S.ch, (S.length+T.length)*sizeof(char)) ))exit(OVERFLOW); for ( i=S.length-1; i>=pos-1; --i ) //为插入T而腾出pos之后的位置 S.ch [i+T.length] = S.ch [i]; //从S的pos位置起全部字符均后移S.ch[pos-1…pos+T.length-2] = T.ch[0…T.length-1];//插入T,略/0 S.length + = T.length; //刷新S串长度}return OK;}//StrInsert 2) 堆分配存储表示 Status StrAssign( HString &T, char *chars ) {if (T.ch) free(T.ch);for (i=0, c=chars;* c; ++i, ++c); //求串长度//直到终值为“假”停止,串尾特征是‘/0’=NULL=0//指针变量C也可以自增!意即每次后移一个数据单元。if (!i) {T.ch = NULL; T.length = 0;}else{if (!(T.ch = (char*)malloc (i*sizeof(char))))exit(OVERFLOW);T.ch[0..i-1] = chars[0..i-1];T.length =i;}Return OK;}//StrAssign 3) 比较字符串是否相同 Int Strcompare ( Hstring S, Hstring T ){ for ( i = 0; i 4) 清空字符串 Status ClearString ( Hstring &S){ if ( S.ch ) { free(S.ch); S.ch = NULL; }S.length = 0;return OK;} // ClearString 5) 联接两个串成新串 Status Concat ( HString &T, Hstring S1, Hstring S2 ){ //用T返回由S1和S2联接而成的新串。 if (T.ch) free(T.ch); // 释放旧空间if ( !(T.ch = (char *) malloc ((S1.length+S2.length) * sizeof (char) ) ) ) exit ( OVERFLOW);T.ch[0 .. S1.length-1] = S1.ch[0 .. S1.length-1];T.length = S1.length + S2.length ;T.ch [S1.length .. T.length-1] = S2.ch [0 .. S2.length-1];return OK;} // Concat 6)求子串 Status SubString ( Hstring &Sub, Hstring S,int pos,int len ){ //用Sub返回串S的第pos个字符起长度为len的子串。// 其中,1S.length || lenS.length-pos+1)return ERROR; // 参数不合法if ( Sub.ch) free ( Sub.ch); // 释放旧空间if (!len) { Sub.ch = NULL; Sub.length = 0; } // 空子串else { // 完整子串Sub.ch = ( char *) malloc ( len *sizeof ( char ));Sub.ch[0..len-1] = S.ch [ pos-1.. Pos+len-2] ;Sub.length = len;}return OK;} 链式存储特点 :用链表存储串值,易插入和删除。 链表结点(数据域)大小取1
链表结点(数据域)大小取n(例如n=4)
法1存储密度为 1/2 ;法2存储密度为 9/15=3/5 ; 显然,若数据元素很多,用法2存储更优—称为块链结构 块链类型定义: #define CHUNKSIZE 80 //可由用户定义的块大小typedef struct Chunk { //首先定义结点类型char ch [ CHUNKSIZE ]; //结点中的数据域struct Chunk * next ; //结点中的指针域}Chunk; typedef struct { //其次定义用链式存储的串类型Chunk *head; //头指针Chunk *tail; //尾指针int curLen; //结点个数} Lstring; 串的链式存储结构对某些操作比较方便,但是总体来说没有前面的两种存储结构灵活。 再次强调:串与线性表的运算有所不同,是以“串的整体”作为操作对象,例如查找某子串,在主串某位置上插入一个子串等。 这类操作中均涉及到子串的定位问题,称为串的模式匹配。它是串处理系统中最重要的操作之一。 空串和空白串的区别:空串(Null String)是指长度为零的串;而空白串(Blank String),是指包含一个或多个空白字符‘ ’(空格键)的字符串. 串的模式匹配算法模式匹配(Pattern Matching) 即子串定位运算(Index函数)。 算法目的:确定主串中所含子串第一次出现的位置(定位) ——即如何实现 Index(S,T,pos)函数 初始条件:串S和T存在,T是非空串,1≤pos≤StrLength(s) 操作结果:若主串S中存在和串T值相同的子串,则返回它在主串S中第pos个字符之后第一次出现的位置;否则函数值为0。 注:S称为被匹配的串,T称为模式串。若S包含串T,则称“匹配成功”,否则称 “匹配不成功” 。 BF算法 (又称古典或经典的、朴素的、穷举的) KMP算法(特点:速度快) ① BF算法设计思想: 将主串的第pos个字符和模式的第1个字符比较,若相等,继续逐个比较后续字符;若不等,从主串的下一字符(pos+1)起,重新与第一个字符比较。 直到主串的一个连续子串字符序列与模式相等 。返回值为S中与T匹配的子序列第一个字符的序号,即匹配成功。 否则,匹配失败,返回值 0 . 模式匹配——BF算法 例:主串S="ababcabcacbab",模式T="abcac"
② BF算法的实现—即Index()操作的实现 Int Index (SString S, SString T, int pos) {i=pos; j=1;while ( iT[0]) return i-T[0]; //子串结束,说明匹配成功else return 0;}//Index 若n为主串长度,m为子串长度,则串的BF匹配算法最坏的情况下需要比较字符的总次数为O(n*m)----BF匹配算法的最坏时间复杂度 最恶劣情况是:主串中前面n-m个位置都部分匹配到子串的最后一位时出现不等,此时需要将指针i回溯,并从模式的第一个字符开始重新比较,整个匹配过程中,指针i需回溯(n-m)次,则while循环次数为(n-m+1)*m。例如:S="aaaaaaaaaaab" ,T="aaab",但一般情况下BF算法的时间复杂度为近似于O(n+m) KMP算法(特点:速度快) ① KMP算法设计思想 利用已经部分匹配的结果而加快模式串的滑动速度,而且主串S的指针i不必回溯!可提速到O(n+m)!
② KMP算法的推导过程 抓住部分匹配结果的两个特征:
设目前应与T的第k字符开始比较,则T的k-1~1位=S前i-1~i-(k-1)位,即:S中位置i前面的k-1位字符串=T中的前k-1位
刚才肯定是在S的i处和T的第j字符 处失配,则S前i-1~i-(k-1)位=T的j-1~j-(k-1)位,即:S中位置i前面的k-1位字符串=T中j前面的k-1位 两式联立可得:‘T1…Tk-1’=‘Tj-(k-1) …Tj-1’ 注意:j 为当前已知的失配位置,我们的目标是计算新起点 k, 仅剩一个未知数k,理论上已可解,且k仅与模式串T有关! 根据模式串T的规律: ‘T1…Tk-1’=‘Tj-(k-1) …Tj-1’ 和已知的当前失配位置j ,可以归纳出计算新起点 k的表达式。 令k = next[ j ],则
③ KMP算法的实现 (关键技术:计算next[j]) 第一步:先把模式T所有可能的失配点j所对应的next[j]计算出来; 第二步: 执行定位函数index_kmp (与BF算法模块非常相似) Int Index_KMP (SString S, SString T, int pos) {i=pos; j=1;while ( iT[0]) return i-T[0]; //子串结束,说明匹配成功else return0;}//Index_KMP 求解next[j] 算法的流程图: void get_next (SString T, int &next[ ] ){ //next函数值存入数组nexti=1; next[1]=0; j=0;while(i}// get_next
改进算法nextval [ j ] void get_nextval (SString T, int &nextval[ ] ){ //next函数修正值存入数组nextvali=1; nextval[1]=0; j=0;while ( i}// get_nextval
④ KMP算法的时间复杂度 回顾BF的最恶劣情况:S与T之间存在大量的部分匹配,比较总次数为: (n-m+1)*m=O(n*m) 而此时KMP的情况是:由于指针i无须回溯,比较次数仅为n,即使加上计算next[j]时所用的比较次数m,比较总次数也仅为n+m=O(n+m),大大快于BF算法。 注意:由于BF算法在一般情况下的时间复杂度也近似于O(n+m), 所以至今仍被采用。 KMP算法的用途:因为主串指针i不必回溯,所以从外存输入文件时可以做到边读入边查找,“流式”作业!
|




















【本文地址】
今日新闻 |
推荐新闻 |