Pyspark,Python下安装Spark,无需安装Hadoop |
您所在的位置:网站首页 › pip安装环境依赖必须在c盘吗 › Pyspark,Python下安装Spark,无需安装Hadoop |
Pyspark,Python下安装Spark,无需安装Hadoop
|
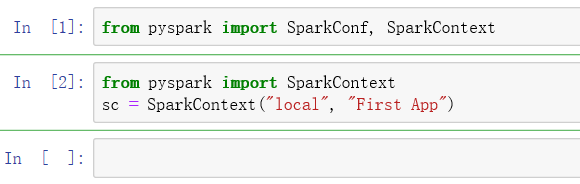
又是装环境斗志斗勇的一天,苦笑 之前一直不想搭虚拟机/Hadoop/spark这些环境,后来python三千万行数据实在跑不动了,知道有pyspark这等好东西,以为conda install pyspark一下就可以了,发现并没有那么简单。找了很多资料,搜了很多也没找到合适的教程,正好记录一下,希望能帮到需要的同学。不用虚拟机不用Hadoop。 环境:anconda 3.0 win10 64位 1.下载 第一步conda install pyspark下载spark http://spark.apache.org/downloads.html 红框那个下载后解压即可,无需安装 需要注册登陆一下,会发邮箱验证,其他信息随便填就行 按照默认路径安装最好 值:压缩文件解压路径 值:jdk安装路径 系统变量PATH添加两个新变量 %SPARK_HOME %\bin %JAVA_HOME %\bin 还有这个 安装完pyspark,这两行就是成功了的,但是继续写下去就会有层出不穷的问题 import pyspark from pyspark import SparkConf, SparkContext我是看这个教程学习的https://www.it1352.com/OnLineTutorial/pyspark/pyspark_sparkcontext.html
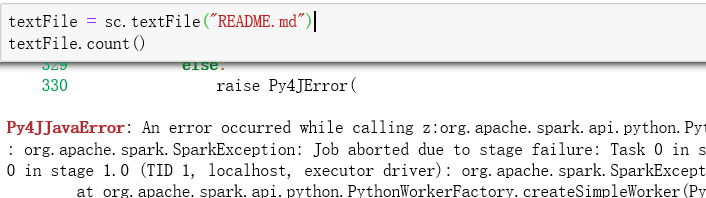
README.md是spark文件夹自带的
于是爆了这个An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1, localhost, executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
有文章说需要绝对路径,仍然不行
1.spark-env.sh文件,刚开始看到好几个人写这个了但是找不到在哪 原来的它后面有蓝色框,最下面填完三句把蓝色的后缀删了【忘了在哪看的了】 export PYSPARK_PYTHON=/C:/Users/10391/AppData/Local/Continuum/anaconda3 export PYSPARK_DRIVER_PYTHON=/C:/Users/10391/AppData/Local/Continuum/anaconda3 export PYSPARK_SUBMIT_ARGS='--master local[*]'
这条不知道有用没,如果环境变量填完重启还不管用可以试试,由于我这配的时候是交叉的步骤,最后成功了 2.刚开始这两句还是成功的,后来又有了这个问题,说是加两句 import findspark findspark.init(),我刚开始安装conda install findspark这个包也没成功 后来改下channels就可以了https://www.cnblogs.com/yikemogutou/p/11396045.html
留下激动的泪水
这一句也终于成功了,检验成不成功就是看.count(),之前一到这就有问题,爆那一大串问题 绝对路径还是相对路径都可以了 之前也想过是C盘要改成file才可以吗,那会真是怎么着都不行,现在怎么都行了,开心撒花
最最最感谢的文章https://www.cnblogs.com/jackchen-Net/p/6667205.html 环境变量配置完不行的话也可重启试试 |
















【本文地址】