|
第6章 判别分析
文章会用到的数据请在这个网址下下载多元统计分析及R语言建模(第五版)数据 练习题 1)考虑两个数据集x1 = [3 7 2 4 4 7],x2 = [6 9 5 7 4 8] (1)计算Fisher线性判别函数
library(MASS)
library(openxlsx)
x1 = c(3,2,4,6,5,4)
x2 = c(7,4,7,9,7,8)
y = c(1,1,1,2,2,2)
(data1 = data.frame(x1,x2,y))
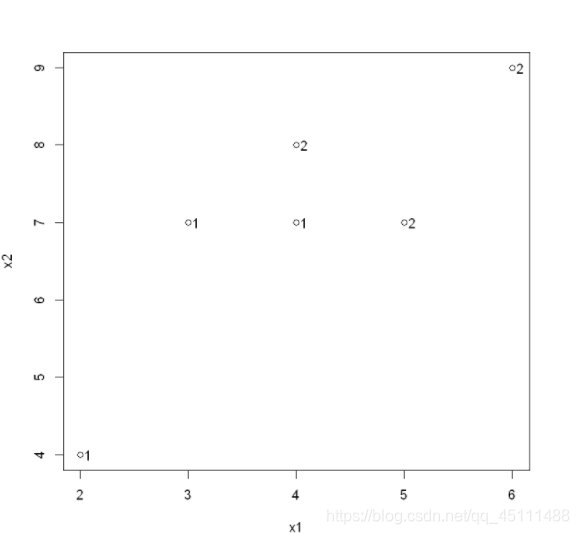
plot(data1[,-3])
text(x1,x2,y,adj = -0.5)
x1_bar = data1[1:3,-3]
x1_bar

x2_bar = data1[4:6,-3]
x2_bar

(x1_mean = apply(x1_bar,2,mean))
(x2_mean = apply(x2_bar,2,mean))

Sp = matrix(c(1,1,1,2),ncol = 2)
Sp_re = solve(Sp)
(2 * cov(x1_bar) + 2 * cov(x2_bar)) / 4

#a = t(x1_mean - x2_mean)%*%Sp_re
#a用公式求判别直线
fy y2_bar
y_0 >= (y2_bar + y1_bar) / 2
c(y1_bar,y2_bar,y_0) #距离哪个中心更近,被判为哪一类
 因为y2_bar距离中心更近,所以观测值属于G2 3)以舒张期血压和血浆胆固醇含量预测被检查者是否患冠心病。测得15名冠心病人和16名健康人的舒张压x1(mmHg)及血浆胆固醇含量x2(mg/dl),…。 (1)对每一组数据用不同的符号,作两变量的散点图,观察它们在平面上的散布情况,该组数据做判别分析是否合适? 因为y2_bar距离中心更近,所以观测值属于G2 3)以舒张期血压和血浆胆固醇含量预测被检查者是否患冠心病。测得15名冠心病人和16名健康人的舒张压x1(mmHg)及血浆胆固醇含量x2(mg/dl),…。 (1)对每一组数据用不同的符号,作两变量的散点图,观察它们在平面上的散布情况,该组数据做判别分析是否合适?
library(openxlsx)
d6.3 = read.xlsx('mvexer5.xlsx',sheet = 'E6.3',colNames = T)
head(d6.3)

attach(d6.3)
plot(x1,x2) #绘制散点图
text(x1,x2,Y,adj = -0.5) #标记处途中原始点
 由上图可知,该组数据适合做判别分析 (2)分别建立距离判别(等方差阵和不等方差阵)、Fisher判别和Bayes判别分析模型,计算各自的判别符合率,确定哪种判别方法最恰当。 由上图可知,该组数据适合做判别分析 (2)分别建立距离判别(等方差阵和不等方差阵)、Fisher判别和Bayes判别分析模型,计算各自的判别符合率,确定哪种判别方法最恰当。
library(MASS) #距离判别模型
qda_1 = qda(Y ~ x1 + x2)
qda_1

#距离判别符合率
pre1 = predict(qda_1)
Y5 = pre1$class
tab1 = table(Y,Y5)
tab1

sum(diag(prop.table(tab1)))

#Fisher判别分析
lda_1 = lda(Y ~ x1 + x2)
lda_1

#Fisher判别符合率
pre2 = predict(lda_1)
Y6 = pre2$class
tab2 = table(Y,Y6)
tab2

sum(diag(prop.table(tab2)))
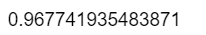
#Bayes判别分析
lda_2 = lda(Y ~ x1 + x2,prior = c(1,2)/3)
lda_2

#Bayes判别符合率
pre3 = predict(lda_2)
Y7 = pre3$class
tab3 = table(Y,Y7)
tab3

sum(diag(tab3))/sum(tab3)
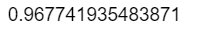 由以上结果,根据各自的判别符合率大小可知,距离判别最恰当。 (3)绘制线性判别函数图。 由以上结果,根据各自的判别符合率大小可知,距离判别最恰当。 (3)绘制线性判别函数图。
plot(lda_1)
 4)对于A股市场2009年陷入财务困境的上市公司(ST公司),我们收集了8家ST公司陷入财务困境前一年(2008年)的财务数据,同时对于财务良好的公司(非ST公司),收集了同一时期8家非ST公司对应的财务数据,…,数据涉及四个变量:资产负债率x1,流动资产周转率x2,总资产报酬率x3,和营业收入增长率x4,类别变量G中2代表ST公司,1代表非ST公司。 (1)分别建立线性判别、非线性判别和Bayes判别分析模型,计算各自的判别符合率,确定哪种判别方法最恰当; 4)对于A股市场2009年陷入财务困境的上市公司(ST公司),我们收集了8家ST公司陷入财务困境前一年(2008年)的财务数据,同时对于财务良好的公司(非ST公司),收集了同一时期8家非ST公司对应的财务数据,…,数据涉及四个变量:资产负债率x1,流动资产周转率x2,总资产报酬率x3,和营业收入增长率x4,类别变量G中2代表ST公司,1代表非ST公司。 (1)分别建立线性判别、非线性判别和Bayes判别分析模型,计算各自的判别符合率,确定哪种判别方法最恰当;
library(openxlsx)
d6.4 = read.xlsx('mvexer5.xlsx',sheet = 'E6.4')
d6.4

attach(`d6.4`)
#建立线性判别模型
library(MASS)
lda_1 = lda(G ~ x1 + x2 + x3 + x4)
lda_1

#线性判别符合率
pre1 = predict(lda_1)
G1 = pre1$class
tab1 = table(G,G1)
tab1

sum(diag(prop.table(tab1)))
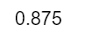
#非线性判别模型
qda_1 = qda(G ~ x1 + x2 + x3 + x4)
qda_1

#非线性符合率
pre2 = predict(qda_1)
G2 = pre2$class
tab2 = table(G,G2)
tab2

sum(diag(prop.table(tab2)))

#Bayes判别分析模型
lda_2 = lda(G ~ x1 + x2 + x3 + x4,prior = c(2,3)/5)
lda_2

#Bayes判别符合率
pre3 = predict(lda_2)
G3 = pre3$class
tab3 = table(G,G3)
tab3
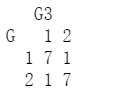
sum(diag(prop.table(tab3)))
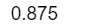 (2)某公司2008年财务数据为:x1 = 78.3563,x2 = 0.8895,x3 = 1.8001,x4 = 14.1002。试判定2009年该公司是否会陷入财务困境。 (2)某公司2008年财务数据为:x1 = 78.3563,x2 = 0.8895,x3 = 1.8001,x4 = 14.1002。试判定2009年该公司是否会陷入财务困境。
predict(qda_1,data.frame(x1 = 78.3563,x2 = 0.8895,x3 = 1.8001,
x4 = 14.1002))
 5)植物分类的判别分析:费歇(Fisher)于1936年发表的鸢尾花(Iris)数据被广泛的作为判别分析的例子。数据是对3种鸢尾花(g):刚毛鸢尾花(第1组)、变色鸢尾花(第2组)和佛吉尼亚鸢尾花(第3组)各抽取一个容量为50的样本,测量其花萼长(sepallen,x1),花萼宽(sepalwide,x2)、花瓣长(petallen,x3)、花瓣宽(petalwide,x4),单位为mm,…。试对该数据进行Fisher判别分析和Bayes判别分析。 5)植物分类的判别分析:费歇(Fisher)于1936年发表的鸢尾花(Iris)数据被广泛的作为判别分析的例子。数据是对3种鸢尾花(g):刚毛鸢尾花(第1组)、变色鸢尾花(第2组)和佛吉尼亚鸢尾花(第3组)各抽取一个容量为50的样本,测量其花萼长(sepallen,x1),花萼宽(sepalwide,x2)、花瓣长(petallen,x3)、花瓣宽(petalwide,x4),单位为mm,…。试对该数据进行Fisher判别分析和Bayes判别分析。
library(openxlsx)
d6.5 = read.xlsx('mvexer5.xlsx',sheet = 'E6.5')
d6.5

#Fisher判别分析
attach(`d6.5`)
library(MASS)
lda_1 = lda(G ~ x1 + x2 + x3 + x4)
lda_1

pre1 = predict(lda_1)
G1 = pre1$class
head(data.frame(G,G1))
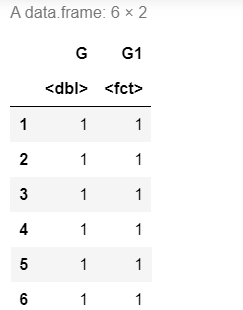
tab1 = table(G,G1)
tab1

diag(prop.table(tab1,1))

sum(diag(prop.table(tab1)))
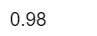
#Bayes判别分析
lda_1 = lda(G ~ x1 + x2 + x3 + x4,prior = c(1,2,3)/6)
lda_1

pre2 = predict(lda_1)
G2 = pre2$class
tab2 = table(G,G2)
tab2

sum(diag(prop.table(tab2)))
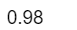
|