[系统安全] 五十四.恶意软件分析 (6)PE文件解析及利用Python获取样本时间戳详解 |
您所在的位置:网站首页 › peview什么意思 › [系统安全] 五十四.恶意软件分析 (6)PE文件解析及利用Python获取样本时间戳详解 |
[系统安全] 五十四.恶意软件分析 (6)PE文件解析及利用Python获取样本时间戳详解
|
最近真的太忙了,天天打仗一样,感谢大家的支持和关注,继续加油!该系列文章将系统整理和深入学习系统安全、逆向分析和恶意代码检测,文章会更加聚焦,更加系统,更加深入,也是作者的慢慢成长史。漫漫长征路,偏向虎山行。享受过程,一起奋斗~ 前文详细介绍2022 DataCon大数据安全分析中恶意样本IOC自动化提取和攻击者画像分析内容。这篇文章将尝试软件来源分析,结合网络攻击中常见的判断方法,利用Python调用扩展包进行溯源,但也存在局限性。文章同时也普及了PE文件分析相关基础,且看且珍惜。 作者的github资源: 逆向分析:https://github.com/eastmountyxz/ SystemSecurity-ReverseAnalysis网络安全:https://github.com/eastmountyxz/ NetworkSecuritySelf-study作者作为网络安全的小白,分享一些自学基础教程给大家,主要是关于安全工具和实践操作的在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习网络安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!  声明:本人坚决反对利用教学方法进行犯罪的行为,一切犯罪行为必将受到严惩,绿色网络需要我们共同维护,更推荐大家了解它们背后的原理,更好地进行防护。(参考文献见后) 你是否想过如何判断PE软件或APP来源哪个国家或地区呢?你又想过印度是如何确保一键正确卸载中国APP呢?使用黑白名单吗?本文尝试进行软件来源溯源,目前想到的方法包括: 通过PE文件分析抓取创建文件时间戳,然后UTC定位国家地区,但受样本数量较少,活动规律不稳定影响很大通过静态分析获取非英文字符串,软件中一般有供该国使用的文字,然后进行编码比对溯源地区某些APP或软件存在流量反馈或IP定位,尝试进行流量抓取分析利用深度学习进行分类,然后提取不同区域的特征完成溯源欢迎大家讨论和留言,我们一起进行更深入的尝试和安全测试 O(∩_∩)O 一.PE文件格式什么是PE文件? PE文件的全称是Portable Executable,意为可移植的可执行的文件,常见的EXE、DLL、OCX、SYS、COM都是PE文件,PE文件是微软Windows操作系统上的程序文件(可能是间接被执行,如DLL)。 EXE文件格式: DOS:MZ格式WIndows 3.0/3.1:NE(New Executable)、16位Windows可执行文件格式为什么要重点学习这种文件格式呢? PE文件是可移植、可执行、跨Win32平台的文件格式所有Win32执行体(exe、dll、kernel mode drivers)知道PE文件本质后,能更好进行恶意样本分析、APT攻击分析、勒索病毒分析了解软件加密和加壳的思想,能够PJ相关的PE文件它是您熟悉Windows操作系统的第一步,包括EXE程序怎么映射到内存,DLL怎么导入等软件逆向工程的基本思想与PE文件格式息息相关如果您想成为一名黑客、系统安全工程师,那么精通PE文件是非常必要的可执行程序是具有不同的形态的,比如用户眼中的QQ如下图所示。  本质上,QQ如下图所示。  PE文件格式总体结构 接着让我们来欣赏下PE文件格式总体结构图,包括:MZ头部、DOS stub、PE文件头、可选文件头、节表、节等。  本文的第二部分我们将对PE文件格式进行详细解析。比如,MZ头文件是定位PE文件头开始位置,用于PE文件合法性检测。DOS下运行该程序时,会提示用户“This Program cannot be run in DOS mode”。  PE文件格式与恶意软件的关系 何为文件感染或控制权获取? 使目标PE文件具备或启动病毒功能(或目标程序) 不破坏目标PE文件原有功能和外在形态(如图标)等 …病毒代码如何与目标PE文件融为一体呢? 代码植入 控制权获取 图标更改 Hook …PE文件解析常用工具包括: PEView:可按照PE文件格式对目标文件的各字段进行详细解析。Stud_PE:可按照PE文件格式对目标文件的各字段进行详细解析。Ollydbg:可跟踪目标程序的执行过程,属于用户态调试工具。UltraEdit \ 010Editor:可对目标文件进行16进制查看和修改。二.PE文件格式解析该部分实验内容: 使用010Editor观察PE文件例子程序hello-2.5.exe的16进制数据使用Ollydbg对该程序进行初步调试,了解该程序功能结构,在内存中观察该程序的完整结构使用010Editor修改该程序,使得该程序仅弹出第二个对话框1.010Editor解析PE文件PE文件结构如下图所示,我推荐大家使用010Editor工具及其模板来进行PE文件分析。 MZ头部+DOS stub+PE文件头+可选文件头+节表+节  (1) 使用010Editor工具打开PE文件,并运行模板。 该PE文件可分为若干结构,如下图所示。 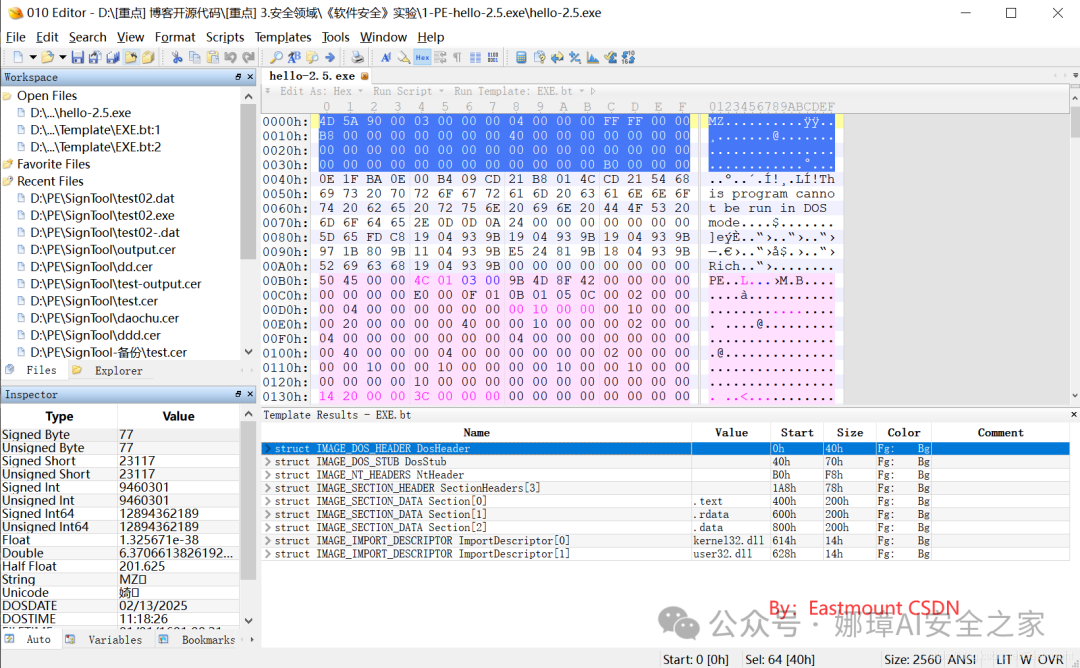 (2) MZ文件头(000h-03fh)。 下图为hello-2.5.exe的MZ文件头,该部分固定大小为40H个字节。偏移3cH处字段Offset to New EXE Header,指示“NT映象头的偏移地址”,其中000000B0是NT映象头的文件偏移地址,定位PE文件头开始位置,用于PE文件合法性检验。 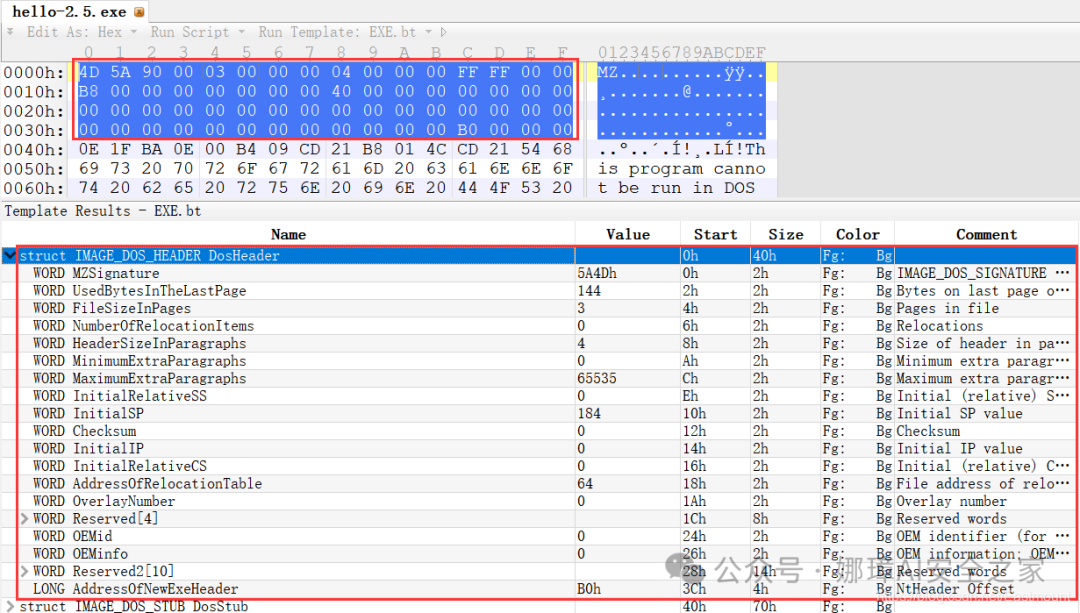 000000B0指向PE文件头开始位置。 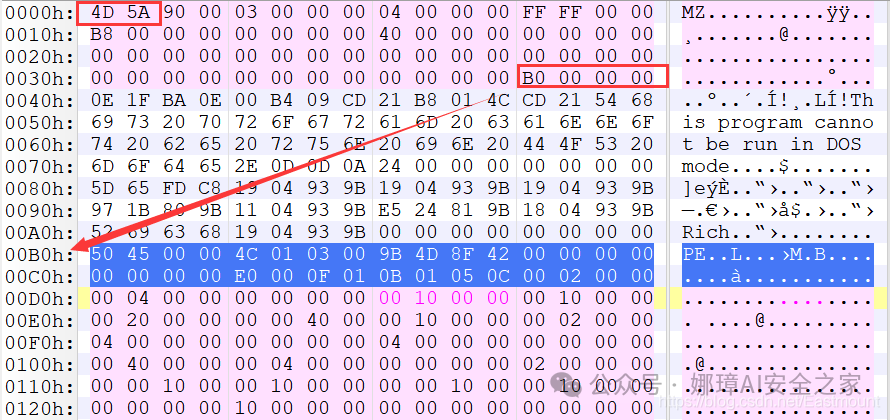 (3) DOS插桩程序(040h-0afh) DOS Stub部分大小不固定,位于MZ文件头和NT映象头之间,可由MZ文件头中的Offset to New EXE Header字段确定。下图为hello-2.5.exe中的该部分内容。  (4) PE文件头(0b0h-1a7h) 该部分包括PE标识、映像文件头、可选文件头。 Signature:字串“PE\0\0”,4个字节(0b0H~0b4H)映象文件头File Header:14H个字节(0b5H~0c7H) 偏移2H处,字段Number of Section 给出节的个数(2个字节):0003 偏移10H处,字段Size of Optional Header 给出可选映象头的大小(2个字节):00E0可选映象头Optional Header:0c8H~1a7H 对应解析如下图所示,包括PE标识、X86架构、3个节、文件生成时间、COFF便宜、可选头大小、文件信息标记等。  010Editor使用模板定位PE文件各节点信息。 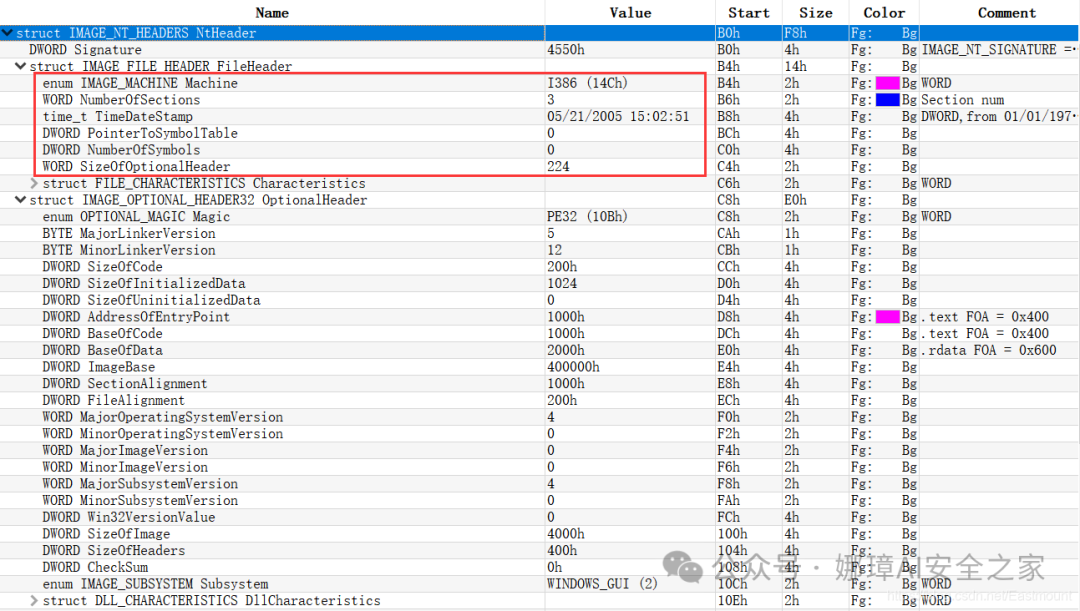 PE文件可选文件头224字节,其对应的字段信息如下所示: 代码语言:javascript复制typedef struct _IMAGE_OPTIONAL_HEADER { WORD Magic; /*机器型号,判断是PE是32位还是64位*/ BYTE MajorLinkerVersion; /*连接器版本号高版本*/ BYTE MinorLinkerVersion; /*连接器版本号低版本,组合起来就是 5.12 其中5是高版本,C是低版本*/ DWORD SizeOfCode; /*代码节的总大小(512为一个磁盘扇区)*/ DWORD SizeOfInitializedData; /*初始化数据的节的总大小,也就是.data*/ DWORD SizeOfUninitializedData; /*未初始化数据的节的大小,也就是 .data ? */ DWORD AddressOfEntryPoint; /*程序执行入口(OEP) RVA(相对偏移)*/ DWORD BaseOfCode; /*代码的节的起始RVA(相对偏移)也就是代码区的偏移,偏移+模块首地址定位代码区*/ DWORD BaseOfData; /*数据结的起始偏移(RVA),同上*/ DWORD ImageBase; /*程序的建议模块基址(意思就是说作参考用的,模块地址在哪里)*/ DWORD SectionAlignment; /*内存中的节对齐*/ DWORD FileAlignment; /*文件中的节对齐*/ WORD MajorOperatingSystemVersion; /*操作系统版本号高位*/ WORD MinorOperatingSystemVersion; /*操作系统版本号低位*/ WORD MajorImageVersion; /*PE版本号高位*/ WORD MinorImageVersion; /*PE版本号低位*/ WORD MajorSubsystemVersion; /*子系统版本号高位*/ WORD MinorSubsystemVersion; /*子系统版本号低位*/ DWORD Win32VersionValue; /*32位系统版本号值,注意只能修改为4 5 6表示操作系统支持nt4.0 以上,5的话依次类推*/ DWORD SizeOfImage; /*整个程序在内存中占用的空间(PE映尺寸)*/ DWORD SizeOfHeaders; /*所有头(头的结构体大小)+节表的大小*/ DWORD CheckSum; /*校验和,对于驱动程序,可能会使用*/ WORD Subsystem; /*文件的子系统 :重要*/ WORD DllCharacteristics; /*DLL文件属性,也可以成为特性,可能DLL文件可以当做驱动程序使用*/ DWORD SizeOfStackReserve; /*预留的栈的大小*/ DWORD SizeOfStackCommit; /*立即申请的栈的大小(分页为单位)*/ DWORD SizeOfHeapReserve; /*预留的堆空间大小*/ DWORD SizeOfHeapCommit; /*立即申请的堆的空间的大小*/ DWORD LoaderFlags; /*与调试有关*/ DWORD NumberOfRvaAndSizes; /*下面的成员,数据目录结构的项目数量*/ IMAGE_DATA_DIRECTORY DataDirectory[16]; /*数据目录,默认16个,16是宏,这里方便直接写成16*/ } IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;(5) 节表(1a8h-21fh) 表项大小固定,28H个字节;表项个数由映象文件头的字段Number of Section 给出。每个表项的起始位置起(8个字节),字段Name给出对应节的名称。每个表项的偏移14H处(4个字节),字段Offset to Raw Data给出对应节的起始文件偏移。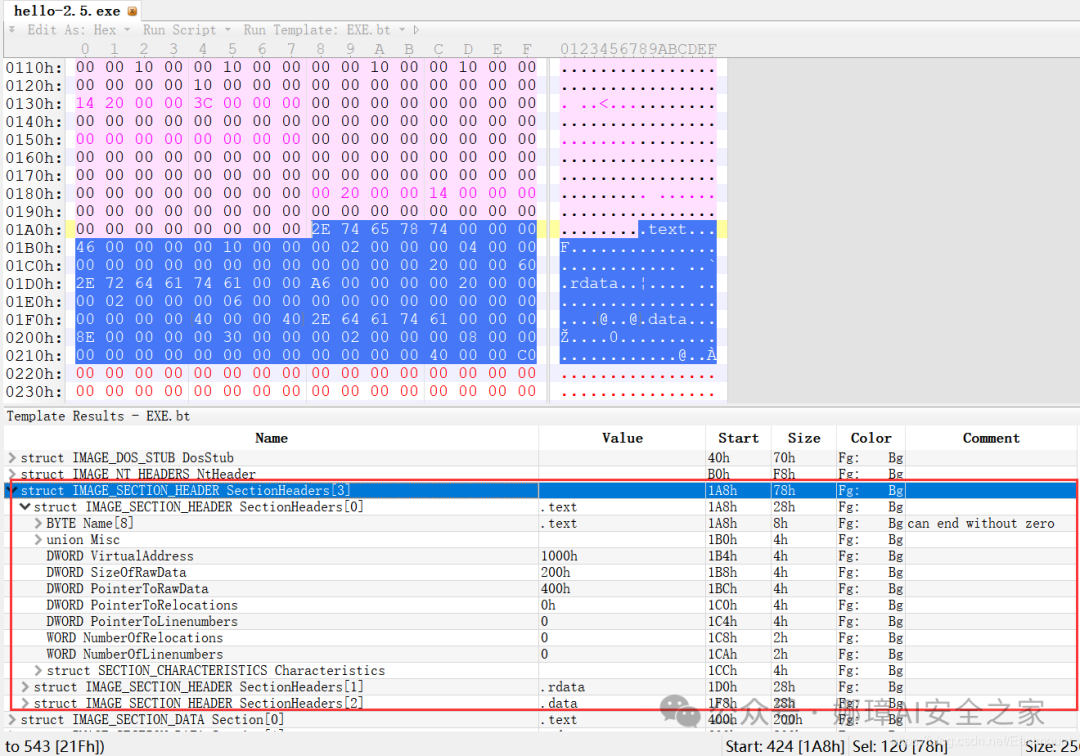 该结构包括3个节,对应上图的3个struct IMAGE_SECTION_HEADER,即“.test”、“.rdata”、“.data”节,其偏移地址对应下图紫色区域,分别是400、600、800的位置。  (6) 3个节 400H-5ffH:代码节600H-7ffH:引入函数节800H-9ffH:数据节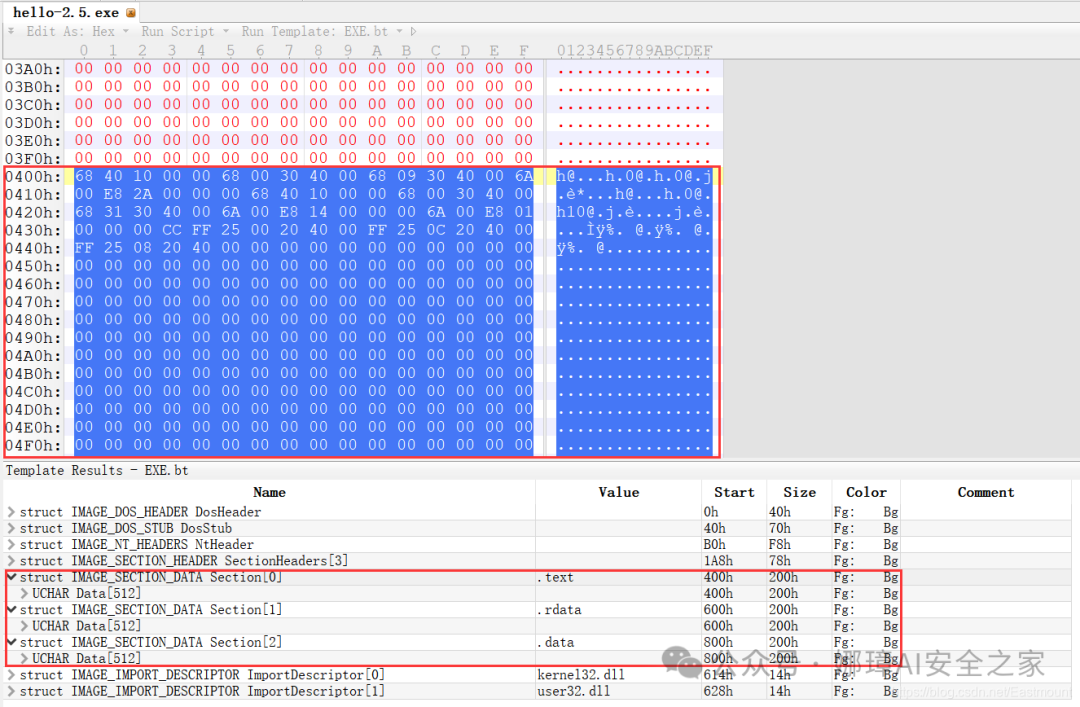 注意,代码节“.text”前46H为数据,后面全是0位填充值,为了实现文件的200H对齐,所以代码节是400H到5ffH。  (7) 引入函数节 ⽤来从其他DLL中引⼊函数,引入了kernel32.dll和user32.dll,这个节一般名为“.rdata”。引入函数是被某模块调用的但又不在调用者模块中的函数,用来从其他(系统或第三方写的)DLL中引入函数,例如kernel32.dll、gdi32.dll等。  010Editor打开如下图所示: 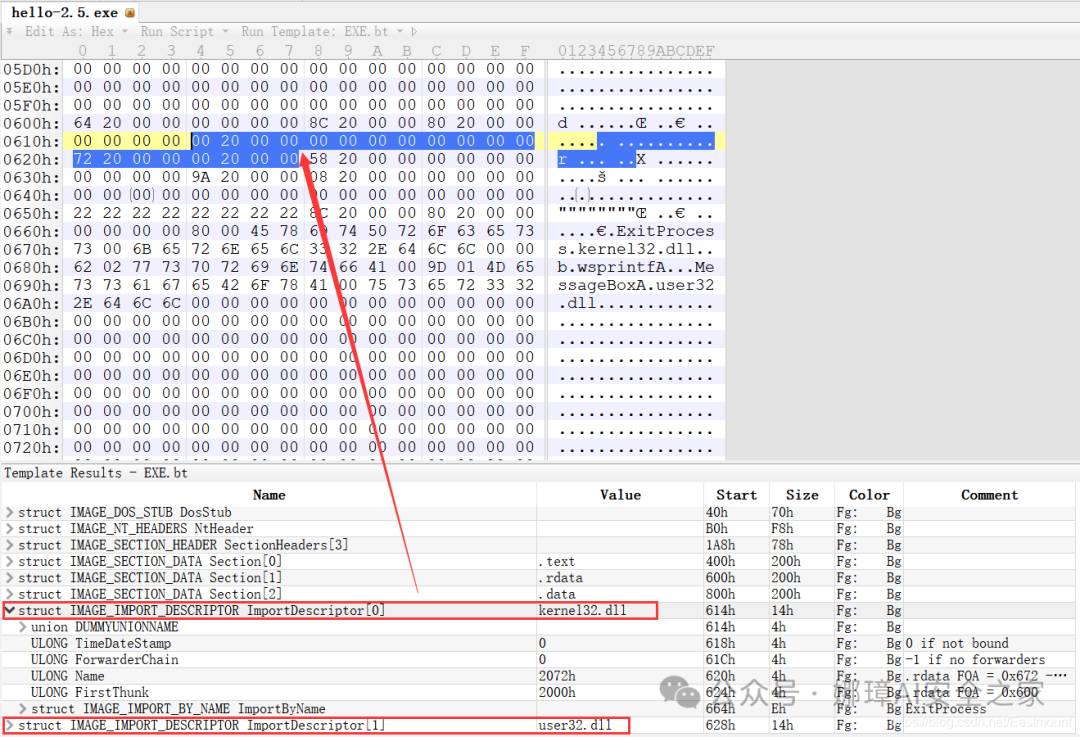 详细标注信息如下图所示:(图引自HYQ同学,再此感谢) 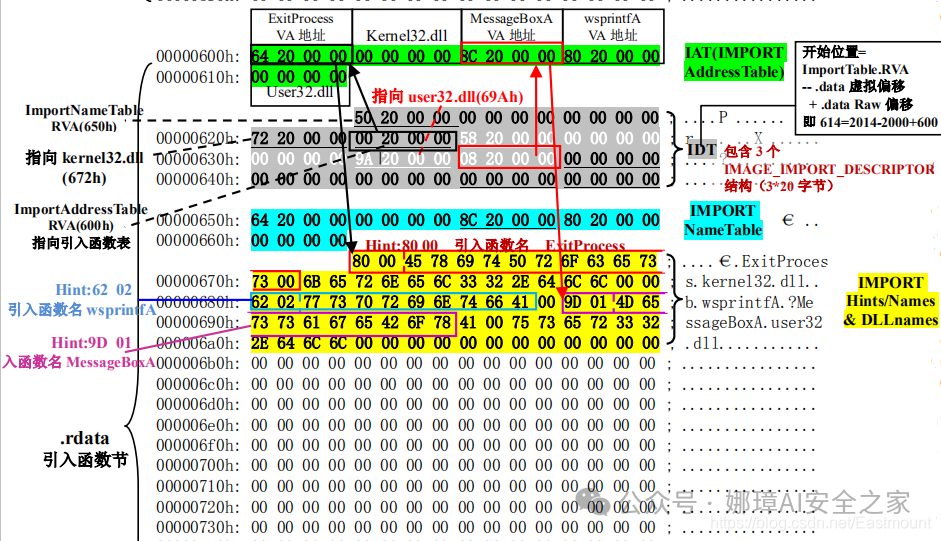 (8) 数据节 数据节实际大小58h,对齐后大小200h,地址为800h-9ffh,包括对话框弹出的具体内容。  2.Ollydbg动态调试程序 2.Ollydbg动态调试程序使用Ollydbg对该程序进行初步调试,了解该程序功能结构,在内存中观察该程序的完整结构。注意,内存对齐单位和文件对齐单位的不同,内容和文件中IAT表内容的不同。 第一步,打开OD加载PE文件。 OD是一款PE文件动态调试器,此时程序断点自动停止在程序入口点00401000H位置。 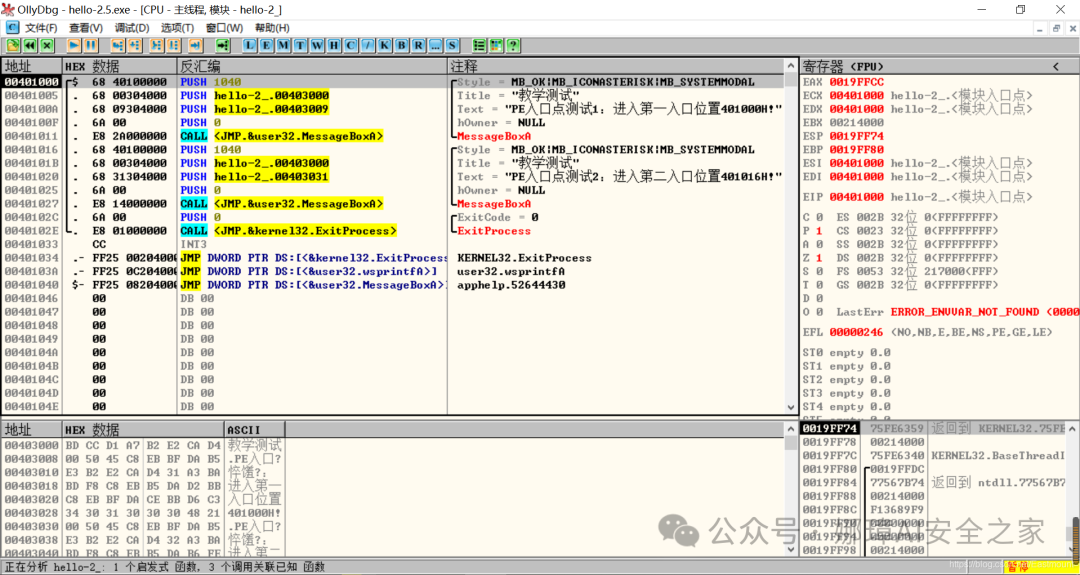 在010Editor中,我们可以看到,该PE程序基地址是400000h,程序入口地址是1000h,两个相加为加载至内存中的地址,即401000h。  第二步,动态调试程序。 当我们双击地址位置,则可以下断点且变红,比如0040100Fh。  接着查看对应调试快捷键,F7是单步步入,F8是单步步过。  我们直接按F8单步步过,此时的位置会CALL一个MessageBoxA函数。  直接单步步过,此时会弹出第一个对话框,点击“确定”按钮。 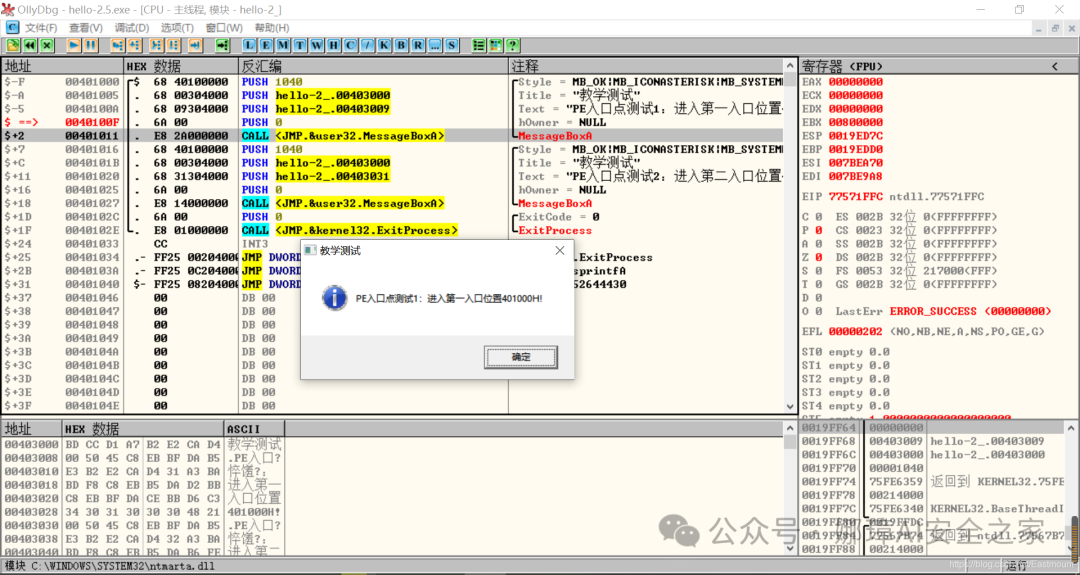 第三步,动态调试程序之数据跟随。 接着我们看左下角部分的内存数据,在该区域按下“Ctrl+G”在数据窗口中跟随,输入基地址400000。 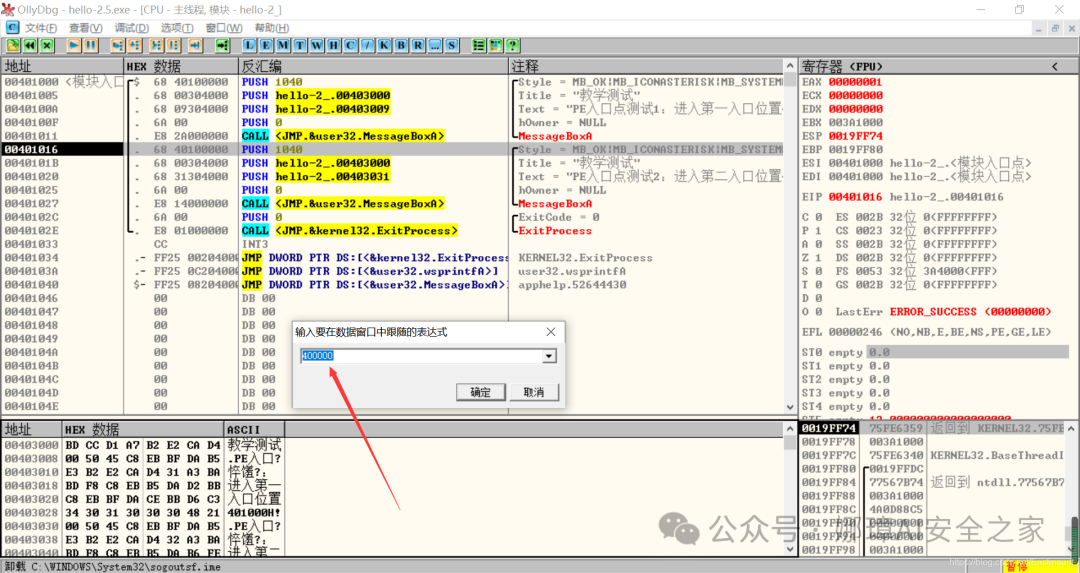 此时可以看到加载到内存中的数据,可以看到该数据与010Editor打开的PE文件数据一致的。  接着继续按F8单步步过弹出第二个窗口。 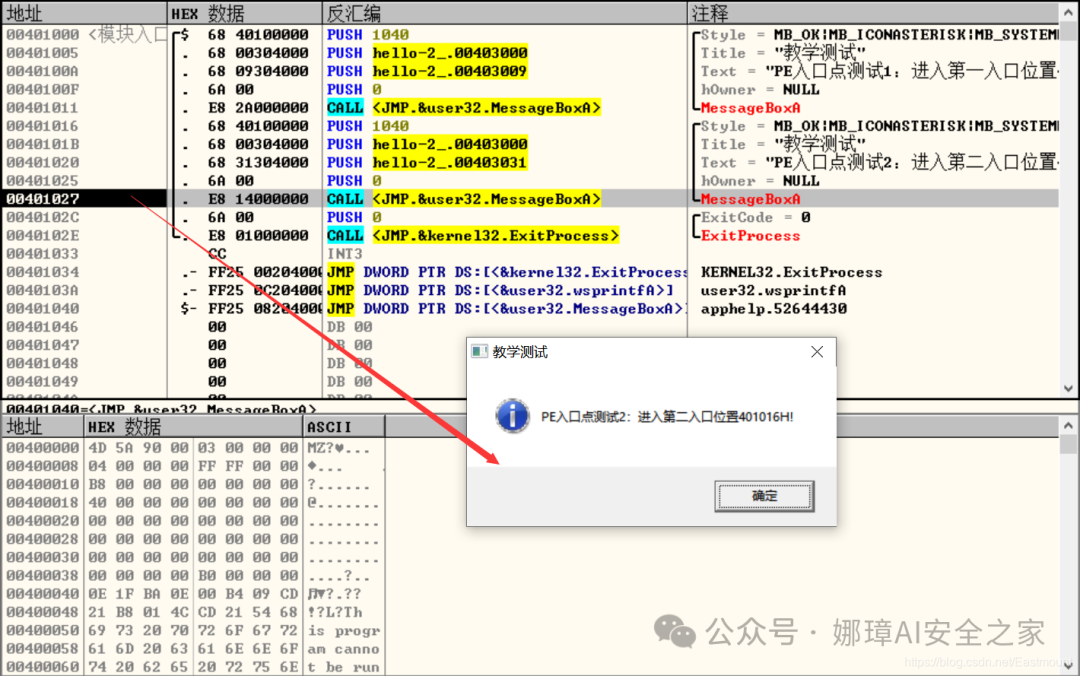 右上角是它寄存器的值,包括各个寄存器中的数据,我们实验中主要使用的寄存器包括EAX、ECX、EDX、EBX等。 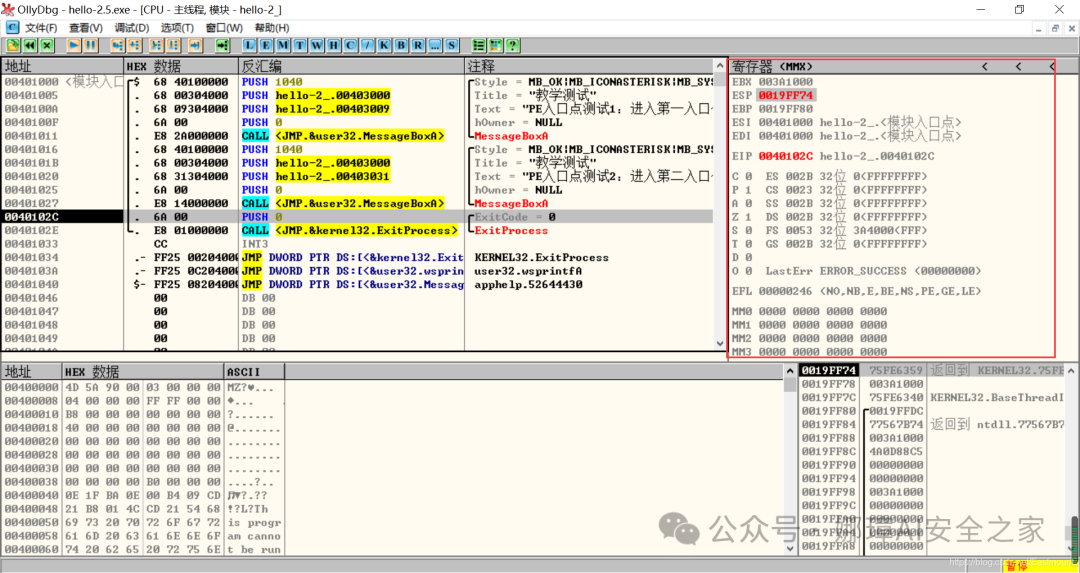 接着步过0040102E,它是退出进程ExitProcess的位置,此时进程已经终止,如下图所示。 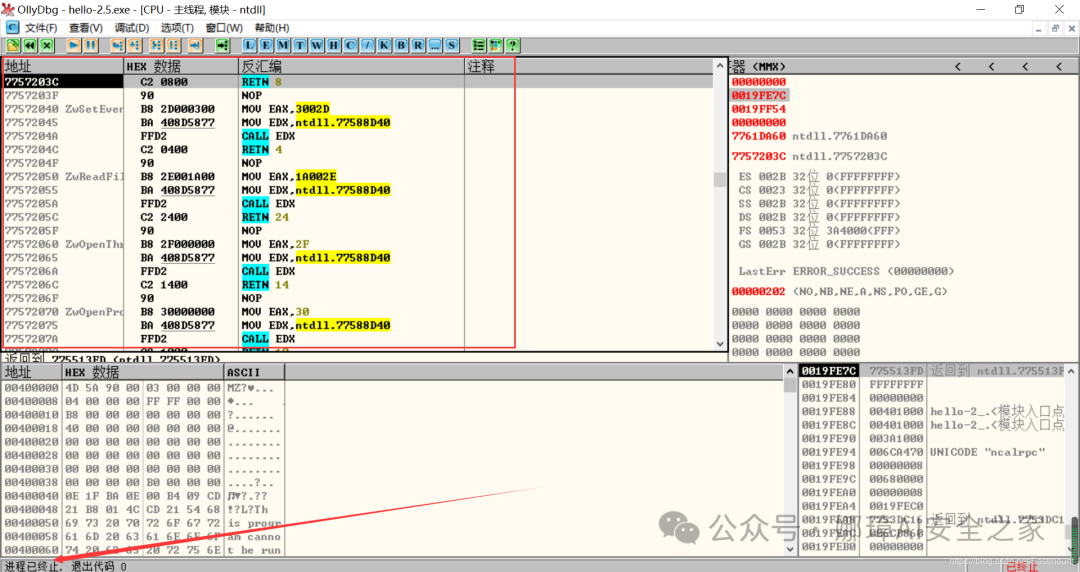 实验讲到这里,使用OD动态调试的PE文件的基础流程就讲解完毕,后续随着实验深入,我们还会使用该工具。 三.Python获取时间戳接着我们尝试通过Python来获取时间戳,python的PE库是pefile,它是用来专门解析PE文件的,可静态分析PE文件。pefile能完成的任务包括: 检查头分析部分数据检索嵌入式数据从资源中读取字符串警告值可疑和格式错误PE的基本分析,喜欢写一些领域和其他部分的PE的带有PEiD签名的打包程序检测PEiD签名 生成推荐大家学习官方资料和github文档。 https://github.com/erocarrera/pefilehttps://pypi.org/project/pefile/https://github.com/erocarrera/pefile/releases安装扩展包的方法如下: pip install pefile 假设安装成功之后,我们需要对下图所示的软件进行分析,该软件是我在前面博客中生成的,大家直接使用即可(文章开头的github链接能下载)。 Windows黑客编程之注入技术详解 第一步,我们通过010Editor分析PE文件。 其时间戳的输出结果如下: 06/19/2020 10:46:21我们希望通过Python写代码实现自动化提取,为后续自动化溯源提供帮助。 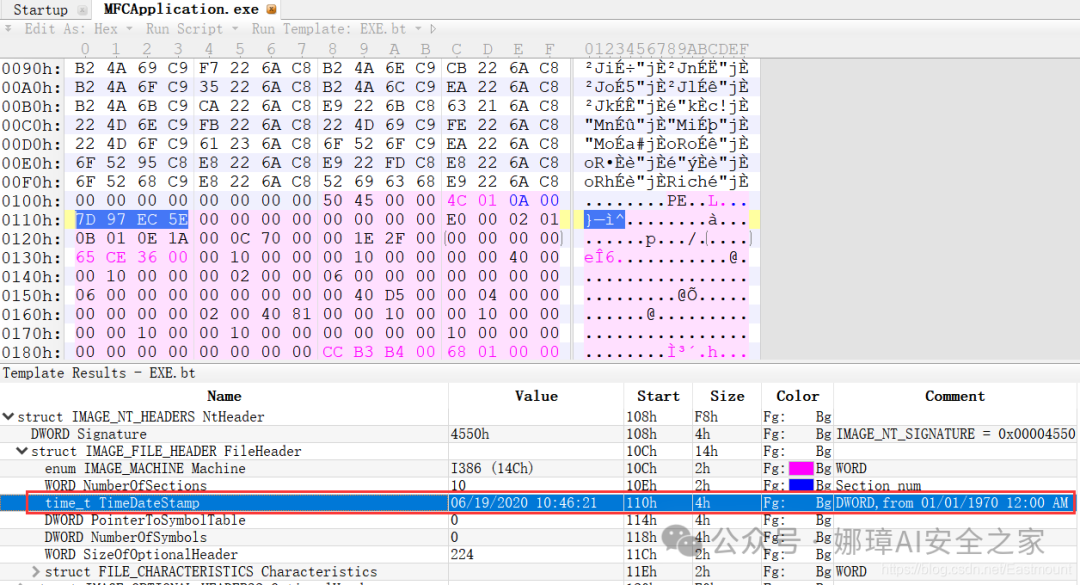 第二步,撰写Python代码实现简单分析。 代码语言:javascript复制import pefile import os,string,shutil,re PEfile_Path = "MFCApplication.exe" pe = pefile.PE(PEfile_Path) print(type(pe)) print(pe)输出如下图所示结果,这是Python包自定义的PE结构。  squeezed text表示python的一种编程规范要求,简称pep8,你只需要将鼠标放到Squeezed上,右键Copy即可查看内容,显示的是该PE文件的基本结构,如下所示: 代码语言:javascript复制----------Parsing Warnings---------- Byte 0xcc makes up 17.8750% of the file's contents. This may indicate truncation / malformation. Suspicious flags set for section 0. Both IMAGE_SCN_MEM_WRITE and IMAGE_SCN_MEM_EXECUTE are set. This might indicate a packed executable. ----------DOS_HEADER---------- [IMAGE_DOS_HEADER] 0x0 0x0 e_magic: 0x5A4D 0x2 0x2 e_cblp: 0x90 0x4 0x4 e_cp: 0x3 0x6 0x6 e_crlc: 0x0 0x8 0x8 e_cparhdr: 0x4 0xA 0xA e_minalloc: 0x0 0xC 0xC e_maxalloc: 0xFFFF 0xE 0xE e_ss: 0x0 0x10 0x10 e_sp: 0xB8 0x12 0x12 e_csum: 0x0 0x14 0x14 e_ip: 0x0 0x16 0x16 e_cs: 0x0 0x18 0x18 e_lfarlc: 0x40 0x1A 0x1A e_ovno: 0x0 0x1C 0x1C e_res: 0x24 0x24 e_oemid: 0x0 0x26 0x26 e_oeminfo: 0x0 0x28 0x28 e_res2: 0x3C 0x3C e_lfanew: 0x108 ----------NT_HEADERS---------- [IMAGE_NT_HEADERS] 0x108 0x0 Signature: 0x4550 ----------FILE_HEADER---------- [IMAGE_FILE_HEADER] 0x10C 0x0 Machine: 0x14C 0x10E 0x2 NumberOfSections: 0xA 0x110 0x4 TimeDateStamp: 0x5EEC977D [Fri Jun 19 10:46:21 2020 UTC] 0x114 0x8 PointerToSymbolTable: 0x0 0x118 0xC NumberOfSymbols: 0x0 0x11C 0x10 SizeOfOptionalHeader: 0xE0 0x11E 0x12 Characteristics: 0x102 Flags: IMAGE_FILE_32BIT_MACHINE, IMAGE_FILE_EXECUTABLE_IMAGE ----------OPTIONAL_HEADER---------- [IMAGE_OPTIONAL_HEADER] 0x120 0x0 Magic: 0x10B 0x122 0x2 MajorLinkerVersion: 0xE 0x123 0x3 MinorLinkerVersion: 0x1A 0x124 0x4 SizeOfCode: 0x700C00 0x128 0x8 SizeOfInitializedData: 0x2F1E00 0x12C 0xC SizeOfUninitializedData: 0x0 0x130 0x10 AddressOfEntryPoint: 0x36CE65 0x134 0x14 BaseOfCode: 0x1000 0x138 0x18 BaseOfData: 0x1000 0x13C 0x1C ImageBase: 0x400000 0x140 0x20 SectionAlignment: 0x1000 0x144 0x24 FileAlignment: 0x200 0x148 0x28 MajorOperatingSystemVersion: 0x6 0x14A 0x2A MinorOperatingSystemVersion: 0x0 0x14C 0x2C MajorImageVersion: 0x0 0x14E 0x2E MinorImageVersion: 0x0 0x150 0x30 MajorSubsystemVersion: 0x6 0x152 0x32 MinorSubsystemVersion: 0x0 0x154 0x34 Reserved1: 0x0 0x158 0x38 SizeOfImage: 0xD54000 0x15C 0x3C SizeOfHeaders: 0x400 0x160 0x40 CheckSum: 0x0 0x164 0x44 Subsystem: 0x2 0x166 0x46 DllCharacteristics: 0x8140 0x168 0x48 SizeOfStackReserve: 0x100000 0x16C 0x4C SizeOfStackCommit: 0x1000 0x170 0x50 SizeOfHeapReserve: 0x100000 0x174 0x54 SizeOfHeapCommit: 0x1000 0x178 0x58 LoaderFlags: 0x0 0x17C 0x5C NumberOfRvaAndSizes: 0x10 DllCharacteristics: IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE, IMAGE_DLLCHARACTERISTICS_NX_COMPAT, IMAGE_DLLCHARACTERISTICS_TERMINAL_SERVER_AWARE ----------PE Sections---------- [IMAGE_SECTION_HEADER] 0x200 0x0 Name: .textbss 0x208 0x8 Misc: 0x35B30B 0x208 0x8 Misc_PhysicalAddress: 0x35B30B 0x208 0x8 Misc_VirtualSize: 0x35B30B 0x20C 0xC VirtualAddress: 0x1000 0x210 0x10 SizeOfRawData: 0x0 0x214 0x14 PointerToRawData: 0x0 0x218 0x18 PointerToRelocations: 0x0 0x21C 0x1C PointerToLinenumbers: 0x0 0x220 0x20 NumberOfRelocations: 0x0 0x222 0x22 NumberOfLinenumbers: 0x0 0x224 0x24 Characteristics: 0xE00000A0 Flags: IMAGE_SCN_CNT_CODE, IMAGE_SCN_CNT_UNINITIALIZED_DATA, IMAGE_SCN_MEM_EXECUTE, IMAGE_SCN_MEM_READ, IMAGE_SCN_MEM_WRITE Entropy: 0.000000 (Min=0.0, Max=8.0) MD5 hash: d41d8cd98f00b204e9800998ecf8427e SHA-1 hash: da39a3ee5e6b4b0d3255bfef95601890afd80709 SHA-256 hash: e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855 SHA-512 hash: cf83e1357eefb8bdf1542850d66d8007d620e4050b5715dc83f4a921d36ce9ce47d0d13c5d85f2b0ff8318d2877eec2f63b931bd47417a81a538327af927da3e ....对应于010Editor分析的结果,前后是一致的。  同时,我们可以输入help(pefile.PE) 查看帮助信息,它定义了pefile包的一些函数和属性。 代码语言:javascript复制Help on class PE in module pefile: class PE(builtins.object) | PE(name=None, data=None, fast_load=None) | | A Portable Executable representation. | | This class provides access to most of the information in a PE file. | | It expects to be supplied the name of the file to load or PE data | to process and an optional argument 'fast_load' (False by default) | which controls whether to load all the directories information, | which can be quite time consuming. | | pe = pefile.PE('module.dll') | pe = pefile.PE(name='module.dll') | | would load 'module.dll' and process it. If the data is already | available in a buffer the same can be achieved with: | | pe = pefile.PE(data=module_dll_data) | | The "fast_load" can be set to a default by setting its value in the | module itself by means, for instance, of a "pefile.fast_load = True". | That will make all the subsequent instances not to load the | whole PE structure. The "full_load" method can be used to parse | the missing data at a later stage. | | Basic headers information will be available in the attributes: | | DOS_HEADER | NT_HEADERS | FILE_HEADER | OPTIONAL_HEADER | | All of them will contain among their attributes the members of the | corresponding structures as defined in WINNT.H | | The raw data corresponding to the header (from the beginning of the | file up to the start of the first section) will be available in the | instance's attribute 'header' as a string. | | The sections will be available as a list in the 'sections' attribute. | Each entry will contain as attributes all the structure's members. | | Directory entries will be available as attributes (if they exist): | (no other entries are processed at this point) | | DIRECTORY_ENTRY_IMPORT (list of ImportDescData instances) | DIRECTORY_ENTRY_EXPORT (ExportDirData instance) | DIRECTORY_ENTRY_RESOURCE (ResourceDirData instance) | DIRECTORY_ENTRY_DEBUG (list of DebugData instances) | DIRECTORY_ENTRY_BASERELOC (list of BaseRelocationData instances) | DIRECTORY_ENTRY_TLS | DIRECTORY_ENTRY_BOUND_IMPORT (list of BoundImportData instances) | | The following dictionary attributes provide ways of mapping different | constants. They will accept the numeric value and return the string | representation and the opposite, feed in the string and get the | numeric constant: | | DIRECTORY_ENTRY | IMAGE_CHARACTERISTICS | SECTION_CHARACTERISTICS | DEBUG_TYPE | SUBSYSTEM_TYPE | MACHINE_TYPE | RELOCATION_TYPE | RESOURCE_TYPE | LANG | SUBLANG ......第三步,撰写代码获取PE文件的方法和属性,比如section。 代码语言:javascript复制import pefile import os,string,shutil,re PEfile_Path = "MFCApplication.exe" #解析PE文件 pe = pefile.PE(PEfile_Path) print(type(pe)) print(pe) #查看方法和属性 print(dir(pefile.PE)) for section in pe.sections: print(section)输出如下结果:  获取导入表信息代码如下: 代码语言:javascript复制import pefile import os,string,shutil,re PEfile_Path = "MFCApplication.exe" #解析PE文件 pe = pefile.PE(PEfile_Path) print(type(pe)) print(pe) #获取导入表信息 for item in pe.DIRECTORY_ENTRY_IMPORT: print(item.dll) for con in item.imports: print(con.name) print("") #换行输出如下所示的结果,包括KERNEL32.dll、USER32.dll等。 代码语言:javascript复制b'KERNEL32.dll' b'RtlUnwind' b'GetModuleHandleExW' b'GetCommandLineA' b'GetSystemInfo' b'CreateThread' ... b'USER32.dll' b'DlgDirSelectExA' b'FindWindowExA' b'FindWindowA' b'SetParent' b'ChildWindowFromPointEx' ... b'GDI32.dll' b'CreateEllipticRgn' b'CreateFontIndirectA' b'CreateHatchBrush' b'CreateICA' b'CreatePalette' b'CreatePen' ... b'MSIMG32.dll' b'AlphaBlend' b'GradientFill' b'TransparentBlt' b'ADVAPI32.dll' b'RegCloseKey' b'RegQueryValueExA' b'RegCreateKeyExA' b'RegDeleteKeyA' ... b'SHELL32.dll' b'SHGetPathFromIDListA' b'SHGetSpecialFolderLocation' b'SHBrowseForFolderA' b'SHGetDesktopFolder' b'DragAcceptFiles' ... b'COMCTL32.dll' b'InitCommonControlsEx' ...对应010editor的PE软件分析结果如下: 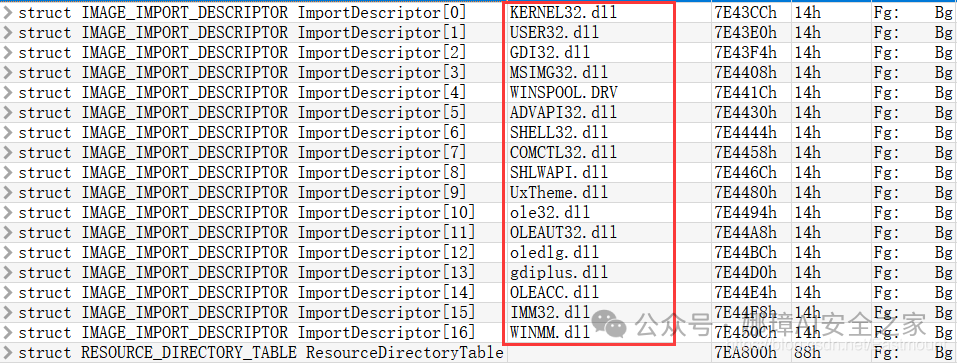 第四步,分析文件结构及时间戳位置。 同样,我们可以使用stud_PE查看文件属性,该软件用于显示头部、DOs、区段、函数等信息,包括导入表、导出表等,显示该EXE程序加载的DLL文件及函数。  这里我们最关心的内容是“TimeDateStamp”,接下来想办法获取它即可。 代码语言:javascript复制typedef struct _IMAGE_FILE_HEADER { +04h WORD Machine; // 运行平台 +06h WORD NumberOfSections; // 文件的区块数目 +08h DWORD TimeDateStamp; // 文件创建日期和时间 +0Ch DWORD PointerToSymbolTable; // 指向符号表(主要用于调试) +10h DWORD NumberOfSymbols; // 符号表中符号个数(同上) +14h WORD SizeOfOptionalHeader; // IMAGE_OPTIONAL_HEADER32 结构大小 +16h WORD Characteristics; // 文件属性 } IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;对应的Python包返回的值如下所示: 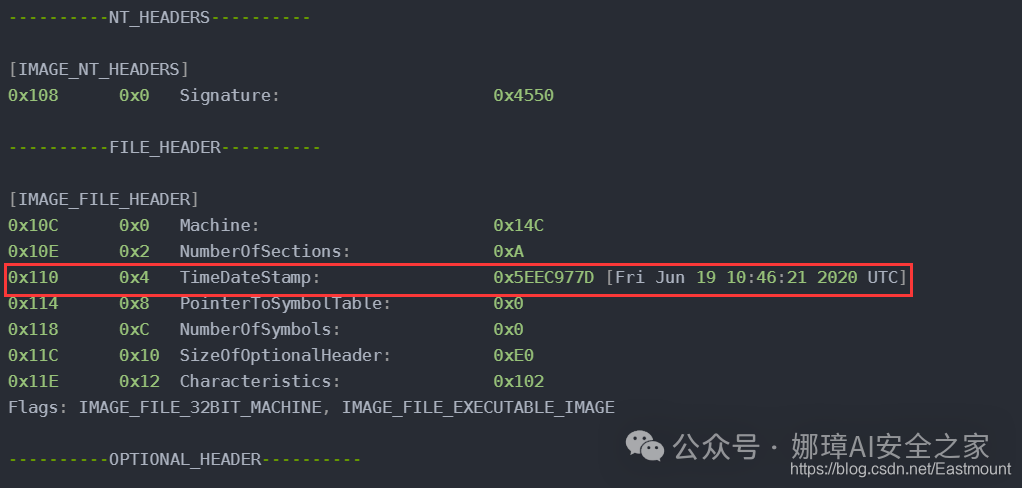 第五步,接着我们通过pe.DOS_HEADER、pe.FILE_HEADER等方法获取对应的内容。 代码语言:javascript复制import pefile import os,string,shutil,re PEfile_Path = "MFCApplication.exe" #解析PE文件 pe = pefile.PE(PEfile_Path, fast_load=True) print(type(pe)) print(pe) #显示DOS_HEADER print(pe.DOS_HEADER,"\n") #显示NT_HEADERS print(pe.NT_HEADERS,"\n") #显示FILE_HEADER print(pe.FILE_HEADER,"\n") #显示OPTIONAL_HEADER print(pe.OPTIONAL_HEADER,"\n")输出如下图所示的结构,其中时间戳也在其中。  作者本想通过它指定的方法提取对应的值,但一直失败,但作为长期从事NLP和数据挖掘的程序员,这都不是事,我们通过正则表达式即可提取所需知识。 代码语言:javascript复制import pefile import os,string,shutil,re PEfile_Path = "MFCApplication.exe" #解析PE文件 pe = pefile.PE(PEfile_Path, fast_load=True) print(type(pe)) print(pe) print(pe.get_imphash()) #显示DOS_HEADER dh = pe.DOS_HEADER #显示NT_HEADERS nh = pe.NT_HEADERS #显示FILE_HEADER fh = pe.FILE_HEADER #显示OPTIONAL_HEADER oh = pe.OPTIONAL_HEADER print(type(fh)) # print(str(fh)) #通过正则表达式获取时间 p = re.compile(r'[[](.*?)[]]', re.I|re.S|re.M) #最小匹配 res = re.findall(p, str(fh)) print(res[1]) #第一个值是IMAGE_FILE_HEADER # Fri Jun 19 10:46:21 2020 UTC最终输出结果如下所示,这样我们就完成了Python自动化提取PE软件的时间戳过程。任何一个PE软件都能进行提取,该时间戳也记录了软件的编译时间。 代码语言:javascript复制 Squeezed text(347 lines). [IMAGE_FILE_HEADER] 0x10C 0x0 Machine: 0x14C 0x10E 0x2 NumberOfSections: 0xA 0x110 0x4 TimeDateStamp: 0x5EEC977D [Fri Jun 19 10:46:21 2020 UTC] 0x114 0x8 PointerToSymbolTable: 0x0 0x118 0xC NumberOfSymbols: 0x0 0x11C 0x10 SizeOfOptionalHeader: 0xE0 0x11E 0x12 Characteristics: 0x102 Fri Jun 19 10:46:21 2020 UTC四.时间戳判断来源地区1.UTC时间转换协调世界时,又称世界统一时间、世界标准时间、国际协调时间。由于英文(CUT)和法文(TUC)的缩写不同,作为妥协,简称UTC。协调世界时是以原子时秒长为基础,在时刻上尽量接近于世界时的一种时间计量系统。Python时间解析代码如下: 代码语言:javascript复制import pefile import time import datetime import os,string,shutil,re PEfile_Path = "MFCApplication.exe" #----------------------------------第一步 解析PE文件------------------------------- pe = pefile.PE(PEfile_Path, fast_load=True) print(type(pe)) print(pe) print(pe.get_imphash()) #显示DOS_HEADER dh = pe.DOS_HEADER #显示NT_HEADERS nh = pe.NT_HEADERS #显示FILE_HEADER fh = pe.FILE_HEADER #显示OPTIONAL_HEADER oh = pe.OPTIONAL_HEADER print(type(fh)) # print(str(fh)) #----------------------------------第二步 获取UTC时间------------------------------- #通过正则表达式获取时间 p = re.compile(r'[[](.*?)[]]', re.I|re.S|re.M) #最小匹配 res = re.findall(p, str(fh)) print(res[1]) #第一个值是IMAGE_FILE_HEADER res_time = res[1].replace(" UTC","") # Fri Jun 19 10:46:21 2020 UTC #获取当前时间 t = time.ctime() print(t) # Thu Jul 16 20:42:18 2020 final_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') print(final_time) # 2020-06-19 10:46:21输出结果如下,可以看到该EXE的创建时间。如果想转换成时间戳可以进一步处理。 Fri Jun 19 10:46:21 2020 UTC2020-06-19 10:46:21接下来我们需要进一步分析,根据时间戳判断所在区域。 2.时区APT溯源案例安天公司通过时区溯源白象APT来自南亚地区,这里再进行回顾下。 在过去的四年中,安天的工程师们关注到了中国的机构和用户反复遭遇来自“西南方向”的网络入侵尝试。这些攻击虽进行了一些掩盖和伪装,我们依然可以将其推理回原点——来自南亚次大陆的某个国家。 参考文章:白象的舞步——来自南亚次大陆的网络攻击安天在2014年4月相关文章中披露的针对中国两所大学被攻击的事件,涉及以下六个样本。其中五个样本投放至同一个目标,这些样本间呈现出模块组合作业的特点。 4号样本是初始投放样本,其具有下载其他样本功能3号样本提取主机相关信息生成日志文件5号样本负责上传6号样本采集相关文档文件信息2号样本则是一个键盘记录器 那么,如何溯源该组织所来自的区域呢? 安天通过对样本集的时间戳、时区分析进行分析,发现其来自南亚。样本时间戳是一个十六进制的数据,存储在PE文件头里,该值一般由编译器在开发者创建可执行文件时自动生成,时间单位细化到秒,通常可以认为该值为样本生成时间(GMT时间)。  时间戳的分析需要收集所有可用的可执行文件时间戳,并剔除过早的和明显人为修改的时间,再将其根据特定标准分组统计,如每周的天或小时,并以图形的形式体现,下图是通过小时分组统计结果: 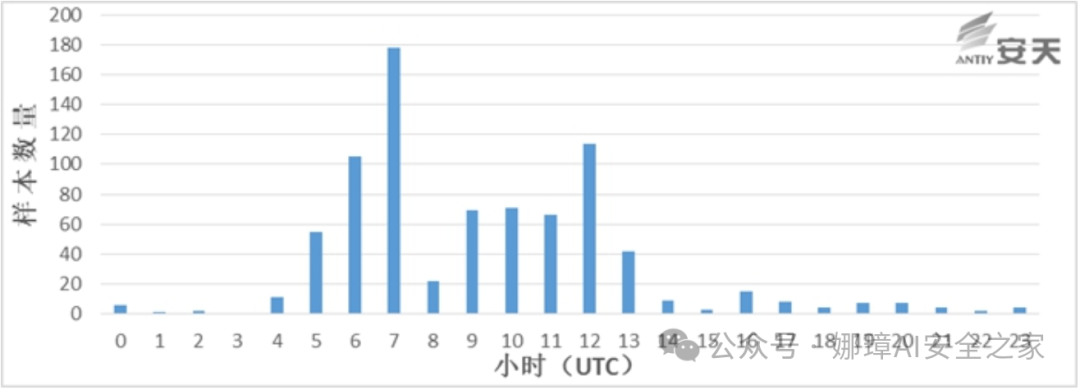 从上图的统计结果来看,如果假设攻击者的工作时间是早上八九点至下午五六点的话,那么将工作时间匹配到一个来自UTC+4或UTC+5时区的攻击者的工作时间。根据我们匹配的攻击者所在时区(UTC+4 或UTC+5),再对照世界时区分布图,就可以来推断攻击者所在的区域或国家。 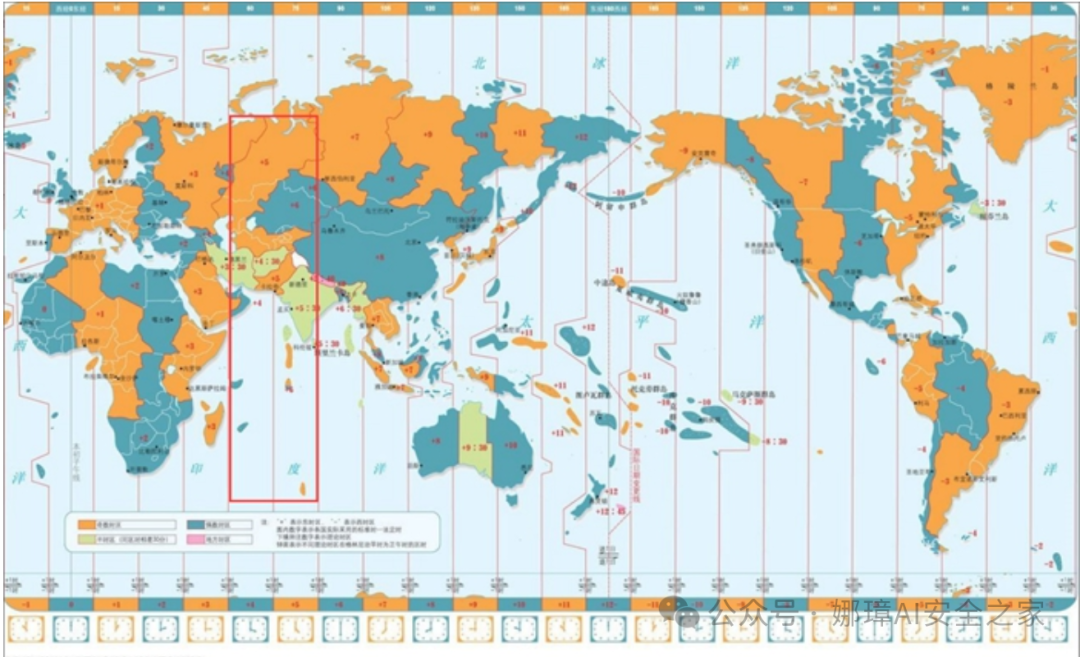 接着对该攻击组织进行更深入的分析。对这一攻击组织继续综合线索,基于互联网公开信息,进行了画像分析,包括成员、C&C关联等。通过这个案例,我们可以通过时区、公开信息、黑客ID、C&C域名进行溯源,并一步步递进。 3.时间戳分析比如当前北京时间是2020年7月16日晚上9点3分,而UTC时间是13点3分。  但这里存在一个问题,当有很多恶意样本的时候,我们基于多个样本时间戳并结合正常作息时间进行分析,才能判断其来源。但是,如果仅从一个样本进行分析,其准确率还是会有影响,有的恶意软件是深夜发布,也影响了该方法的准确性,同时混淆、加壳、对抗样本也能影响我们的实验效果,但作者仅是提供了一种方法,更深入的研究还在继续,如果您有好的方法也欢迎和我讨论。  这里我们PE软件获取的时间是“2020-06-19 10:46:21”,对应北京时间是19点46分。因为作者习惯晚上写代码,但如果是软件或恶意样本,大公司通常会有正常的作息,从而可以结合海量数据分析来确定最终的软件来源地区或国家。 Fri Jun 19 10:46:21 2020 UTC2020-06-19 10:46:21此时的Python代码如下: 代码语言:javascript复制import pefile import time import warnings import datetime import os,string,shutil,re #忽略警告 warnings.filterwarnings("ignore") PEfile_Path = "MFCApplication.exe" #----------------------------------第一步 解析PE文件------------------------------- pe = pefile.PE(PEfile_Path, fast_load=True) print(type(pe)) print(pe) print(pe.get_imphash()) #显示DOS_HEADER dh = pe.DOS_HEADER #显示NT_HEADERS nh = pe.NT_HEADERS #显示FILE_HEADER fh = pe.FILE_HEADER #显示OPTIONAL_HEADER oh = pe.OPTIONAL_HEADER print(type(fh)) # print(str(fh)) #----------------------------------第二步 获取UTC时间------------------------------- #通过正则表达式获取时间 p = re.compile(r'[[](.*?)[]]', re.I|re.S|re.M) #最小匹配 res = re.findall(p, str(fh)) print(res[1]) #第一个值是IMAGE_FILE_HEADER res_time = res[1].replace(" UTC","") # Fri Jun 19 10:46:21 2020 UTC #获取当前时间 t = time.ctime() print(t,"\n") # Thu Jul 16 20:42:18 2020 utc_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') print("UTC Time:", utc_time) # 2020-06-19 10:46:21 #----------------------------------第三步 全球时区转换------------------------------- #http://zh.thetimenow.com/india #UTC时间比北京时间晚八个小时 故用timedelta方法加上八个小时 china_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=8) print("China Time:",china_time) #美国 UTC-5 america_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') - datetime.timedelta(hours=5) print("America Time:",america_time) #印度 UTC+5 india_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=5) print("India Time:",india_time) #澳大利亚 UTC+10 australia_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=10) print("Australia Time",australia_time) #俄罗斯 UTC+3 russia_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=3) print("Russia Time",russia_time) #英国 UTC+0 england_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') print("England Time",england_time) #日本 UTC+9 japan_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=9) print("Japan Time",england_time) #德国 UTC+1 germany_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=1) print("Germany Time",germany_time) #法国 UTC+1 france_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=1) print("France Time",france_time) #加拿大 UTC-5 canada_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') - datetime.timedelta(hours=5) print("Canada Time:",canada_time) #越南 UTC+7 vietnam_time = datetime.datetime.strptime(res_time, '%a %b %d %H:%M:%S %Y') + datetime.timedelta(hours=7) print("Vietnam Time:",vietnam_time)输出结果如下图所示,不同地区有对应的时间分布,如果正常作息是早上9点到12点、下午2点到5点,从结果看更像是来自India、England、Japan等地区。当然,只有恶意样本很多的时候,我们才能进行更好的溯源。 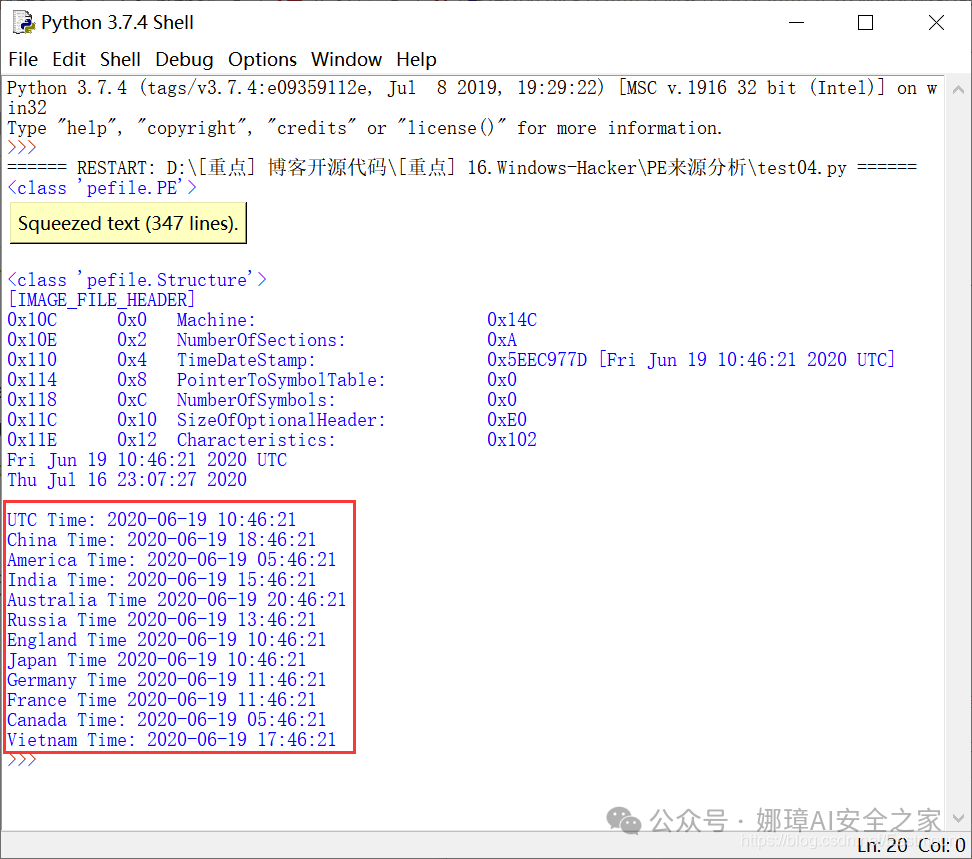 五.总结 五.总结写到这里,这篇文章就介绍完毕,希望对您有所帮助,最后进行简单的总结下作者的猜想。 通过PE文件分析抓取创建文件时间戳,然后UTC定位国家地区,但受样本数量较少,活动规律不稳定影响很大通过静态分析获取非英文字符串,软件中一般有供该国使用的文字,然后进行编码比对溯源地区某些APP或软件存在流量反馈或IP定位,尝试进行流量抓取分析利用深度学习进行分类,然后提取不同国家的特征完成溯源本文尝试的是最简单的方法,所以也存在很多问题,比如当有很多恶意样本的时候,我们才能基于多个样本时间戳并结合正常作息时间进行分析,才能判断其来源。如果仅从一个样本进行分析,其准确率还是会有影响,有的恶意软件是深夜发布,也影响了该方法的准确性,同时混淆、加壳、对抗样本也能影响我们的实验效果,但作者仅是提供了一种方法,更深入的研究还在继续,如果您有好的方法也欢迎和我讨论。 最后欢迎大家讨论如何判断PE软件或APP来源哪个国家或地区呢?印度又是如何确保一键正确卸载中国APP呢?未知攻,焉知防。加油~ 感谢大家2023年的支持和关注,让我们在2024年继续加油!分享更多好文章,感恩,娜璋白首。 (By:Eastmount 2023-06-27 夜于火星) 参考文章如下,感谢这些大佬。 [1] 武汉大学,彭老师《软件安全之恶意代码机理与防护》课程(强推大家关注,MOOC有) [2] [网络安全自学篇] 六十二.PE文件逆向之PE文件解析、PE编辑工具使用和PE结构修改(三) [3] 白象的舞步——来自南亚次大陆的网络攻击: https://www.antiy.com/response/WhiteElephant/WhiteElephant.html [4] https://xz.aliyun.com/t/2688 [5] [原创]利用python+pefile库做PE格式文件的快速开发 - jmpjerryy [6] python 时间类型和相互转换 - shhnwangjian |
【本文地址】
今日新闻 |
推荐新闻 |