PCA(主成分分析)原理、代码详解 |
您所在的位置:网站首页 › pca协方差矩阵特征值和特征向量 › PCA(主成分分析)原理、代码详解 |
PCA(主成分分析)原理、代码详解
|
PCA-主成分分析原理、代码详解
一、简介二、数学原理2.1 中心化2.2 协方差矩阵
三、步骤四、公式推导过程4.1 标准化4.2 求协方差矩阵4.3 投影
五、代码
一、简介
PCA(Principal Components Analysis)即主成分分析法,是机器学习领域一种常用的降维方法,基本上也是每个初学者接触机器学习之后首先会遇到的一种方法,我本人也正刚刚开始机器学习,之前对PCA只是知道有这么一种算法,拿过来就用,对他的数学原理和程序语句一点思考都没有,导致后期自己要做的东西也没做出来,回想自己的脑子里什么也没掌握,因此才决心对这一些基本的方法进行专门的学习,毕竟只有打好了基础才能进行更深层次的学习。 二、数学原理我承认我个人的数学水平也就一般,因此在数学原理方面我会尽可能的用通俗易懂的方法来解释,太高深的语言我也讲不出来。 2.1 中心化对于中心化求均值,这个大家应该都有意识,就是一个标准化步骤,为后边求协方差做准备工作。 2.2 协方差矩阵为什么要用协方差,可能大家都会考虑这个问题,我一开始也有这样的疑惑。其实,不用太纠结这个问题,我在这里简单说明一下。先列举一下我们在概率统计里学到的一些统计学公式。 设 n × m n×m n×m维的矩阵 X X X,此即为待降维的数据矩阵,其中 n n n为采样的个数即样本数, m m m为属性数。PCA的目的就是将 n × m n×m n×m维的矩阵 X X X降维成为 n × k n×k n×k维的矩阵 Y Y Y。 基本步骤: 1、获得数据矩阵X。 2、对矩阵 X n × m X_{n×m} Xn×m的每一列求均值,同时每一列的元素减去自身所在列的均值,此成为中心化,得到矩阵 A n × m A_{n×m} An×m。 3、对 A n × m A_{n×m} An×m求协方差得矩阵 B m × m B_{m×m} Bm×m, 4、求协方差矩阵 B m × m B_{m×m} Bm×m的特征值和特征向量。 5、将特征向量按特征值的降序排列,并提取前 k k k个特征向量,组成矩阵 C m × k C_{m×k} Cm×k。 6、令 Y = X n × m × C m × k Y=X_{n×m}×C_{m×k} Y=Xn×m×Cm×k即为所求降维后的矩阵。 四、公式推导过程 4.1 标准化首先需要对原始数据按列进行标准化, X ~ = X i − X ‾ i \tilde{X} = X_i-\overline{X}_i X~=Xi−Xi 4.2 求协方差矩阵根据我们上文提到的协方差计算公式,可以得到数据样本的协方差矩阵为: c o v ( X i ) = 1 m ∑ i = 1 m ( X i − X ‾ i ) 2 = 1 m ∑ i = 1 m ( X ~ i ) 2 = 1 m ∑ i = 1 m X ~ i ⋅ X ~ i T \begin{aligned} cov(X_{i})& =\frac1m\sum_{i=1}^m(X_i-\overline{X}_i)^2 \\ &=\frac1m\sum_{i=1}^m(\tilde{X}_i)^2 \\ &=\frac1m\sum_{i=1}^m\tilde{X}_i\cdot \tilde{X}_i^T \end{aligned} cov(Xi)=m1i=1∑m(Xi−Xi)2=m1i=1∑m(X~i)2=m1i=1∑mX~i⋅X~iT 4.3 投影设投影超平面为 W W W,投影后的特征值为 Λ \Lambda Λ, Λ = 1 m ∑ i = 1 m ( X i T W − E ( X i T W ) ) 2 = 1 m ∑ i = 1 m ( X ~ i W ) 2 = 1 m ∑ i = 1 m W T X ~ i X ~ i T W = 1 m W T X ~ X ~ T W \begin{aligned} \Lambda&=\frac{1}{m}\sum_{i=1}^m\left(X_i^TW-E(X_i^TW)\right)^2 \\ &=\frac1m\sum_{i=1}^m(\tilde{X}_iW)^2 \\ &=\frac1m\sum_{i=1}^mW^T\tilde{X}_i\tilde{X}_i^TW \\ &=\frac1mW^T\tilde{X}\tilde{X}^TW \end{aligned} Λ=m1i=1∑m(XiTW−E(XiTW))2=m1i=1∑m(X~iW)2=m1i=1∑mWTX~iX~iTW=m1WTX~X~TW 令 A = 1 m X ~ X ~ T A=\frac1m\tilde{X}\tilde{X}^T A=m1X~X~T, Λ = W T A W \Lambda=W^TAW Λ=WTAW,因为PCA的首要目标就是让投影后的散度最大,所以可以将上边的问题转化为如下的优化问题 a r g m a x W T A W s . t . ∣ W ∣ = 1 argmax\space{W^TAW}\\ s.t.|W|=1 argmax WTAWs.t.∣W∣=1 对于有限制条件的优化问题,我们采用拉格朗日乘子法来解决 f ( W , λ ) = W T A W − λ ( W W T − 1 ) f(W,\lambda)=W^TAW-\lambda(WW^T-1) f(W,λ)=WTAW−λ(WWT−1) 对于求极值问题,求导 ∂ f ∂ W = 2 A W − 2 λ W \frac{\partial f}{\partial W}=2AW-2\lambda W ∂W∂f=2AW−2λW 令偏导数为0,即: A W = λ W AW=\lambda W AW=λW 上边就是特征值,特征向量的定义式,其中 λ \lambda λ即是特征值, W W W即是特征向量,这也就解释了PCA是求特征值与特征向量,即特征值分解问题。 把求出来的偏导带入到中,即: f ( W , λ ) = λ f(W,\lambda)=\lambda f(W,λ)=λ 由公式可知散度的值只由 λ \lambda λ来决定, λ \lambda λ的值越大,散度越大,也就是说我们需要找到最大的特征值与对应的特征向量。 五、代码 # 导入相关模块 import numpy as np import seaborn as sns import matplotlib.pyplot as plt from numpy.linalg import eig X = np.array([[5.1, 3.5, 1.4, 0.2], [4.9, 3, 1.4, 0.2]]) # 通过去除平均值进行标准化 X = X - X.mean(axis=0) # 计算协方差矩阵 X_cov = np.cov(X.T, ddof=0) # 计算协方差矩阵的特征值和特征向量 eigenvalues, eigenvectors = eig(X_cov) pi = eigenvalues/np.sum(eigenvalues) #计算贡献率 p = np.cumsum(pi) #计算累计贡献率 k=np.min(np.argwhere(p > 0.95))+1 #返回达到累计贡献率的阈值的下标 # 选取前k个特征向量 klarge_index = eigenvalues.argsort()[-k:][::-1] k_eigenvectors = eigenvectors[klarge_index] # X和k个特征向量进行点乘 X_pca = np.dot(X, k_eigenvectors.T) print(X_pca) #输出主成分结果 |
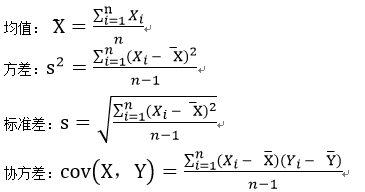 我们可以发现,方差和标准差一般用来描述一维数据,但我们遇到的经常是包含了多个属性的多维数据集,要考察两个维度之间的关系,就要用到协方差,要考察多个维度之间关系,那就需要计算多个协方差。
我们可以发现,方差和标准差一般用来描述一维数据,但我们遇到的经常是包含了多个属性的多维数据集,要考察两个维度之间的关系,就要用到协方差,要考察多个维度之间关系,那就需要计算多个协方差。 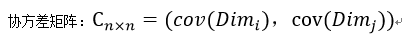 举一个简单的三维的例子,假设数据集有三个维度{x,y,z},则协方差矩阵为
举一个简单的三维的例子,假设数据集有三个维度{x,y,z},则协方差矩阵为 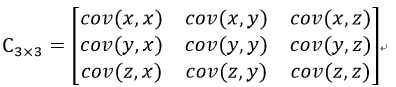 即协方差矩阵是一个对称矩阵,对角线上是个维度的方差。
即协方差矩阵是一个对称矩阵,对角线上是个维度的方差。【本文地址】
今日新闻 |
推荐新闻 |