数据分析新手必读!Python Pandas 分组和聚合操作详解 |
您所在的位置:网站首页 › pandas股票数据分析 › 数据分析新手必读!Python Pandas 分组和聚合操作详解 |
数据分析新手必读!Python Pandas 分组和聚合操作详解
|
1.引言
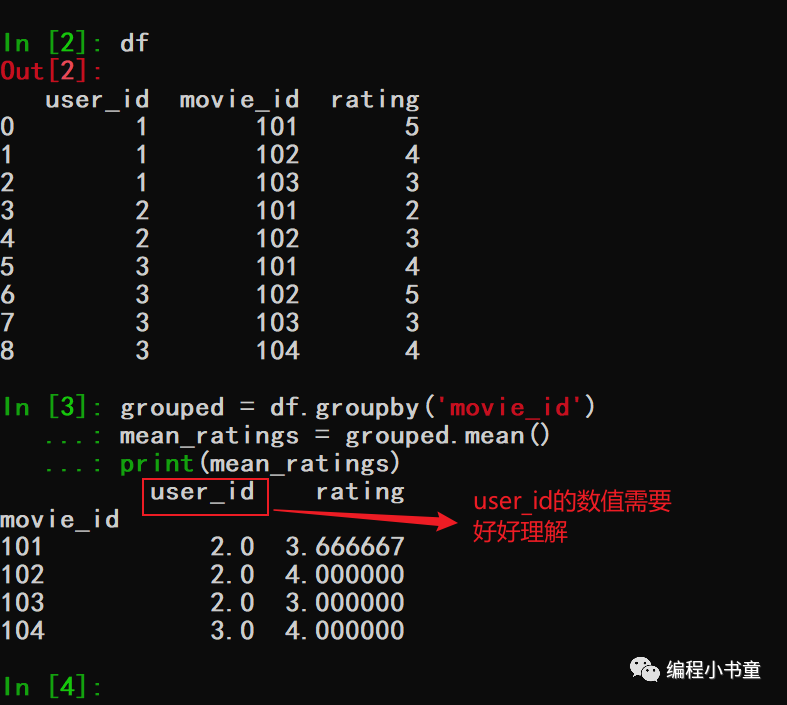
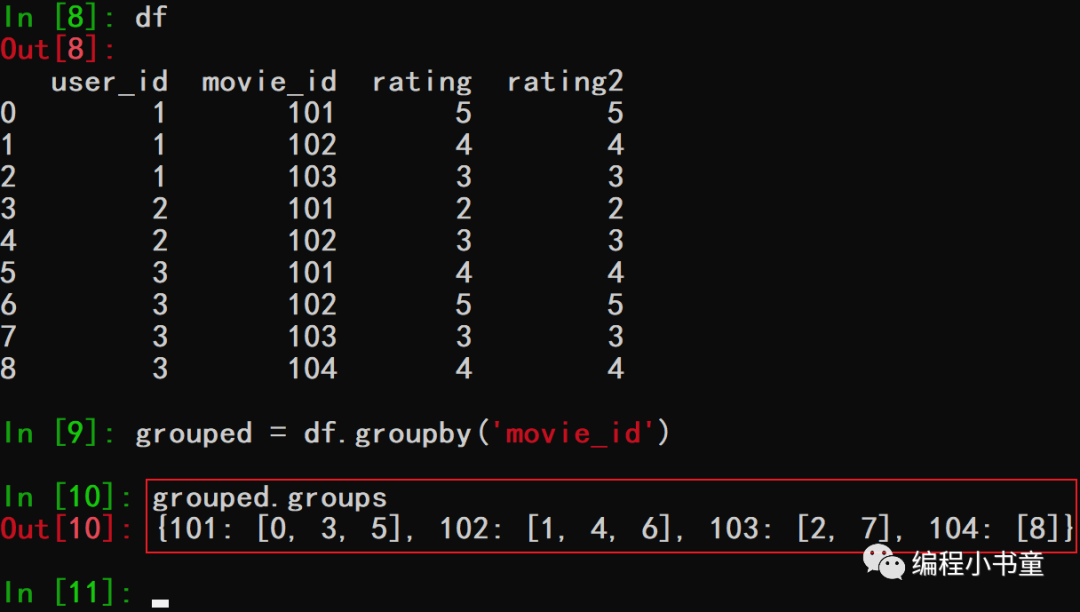
在数据分析和数据科学领域,数据聚合和分组是非常常见的操作。它提供了大量的功能,用于读取,清洗和处理各种类型的数据。Pandas是一个流行的Python库,提供了丰富的数据分析和处理功能。本文将介绍如何使用Pandas进行数据分组和聚合,包括分组操作和聚合函数的使用,以及使用transform和apply方法进行数据变换。 2.分组操作基础讲解Pandas的groupby方法是数据分组和聚合的核心。groupby方法可以对数据进行分组,并在每个组上应用聚合函数。下面是一个示例代码: import pandas as pd df = pd.read\_csv('data.csv') grouped = df.groupby('column\_name')上面的代码将数据框按照“column_name”列进行分组,并将结果保存在grouped对象中。现在,我们可以在每个组上应用聚合函数。 2.1聚合函数Pandas提供了各种聚合函数,如mean,sum,max和min等。这些函数可以应用于groupby对象中的每个组。下面是一些常用的聚合函数: grouped.mean() # 每个组的平均值 grouped.sum() # 每个组的总和 grouped.max() # 每个组的最大值 grouped.min() # 每个组的最小值 2.2使用transform进行数据变换transform方法可以**在每个组上应用一个函数,并将结果广播回原始数据框中的每个元素。**这个函数必须返回与原始数据框具有相同大小的对象。下面是一个示例代码: import pandas as pd df = pd.read\_csv('data.csv') grouped = df.groupby('column\_name') mean\_values = grouped.transform(lambda x: x.mean())上面的代码将数据框按照“column_name”列进行分组,并在每个组上应用mean函数。然后,mean函数的结果被广播回原始数据框中的每个元素。 2.3使用apply进行数据变换apply方法可以在每个组上应用一个函数,并将结果作为新的数据框返回。这个函数可以返回任何大小的对象。下面是一个示例代码: import pandas as pd df = pd.read\_csv('data.csv') grouped = df.groupby('column\_name') result = grouped.apply(lambda x: x + 1)上面的代码将数据框按照“column_name”列进行分组,并在每个组上应用一个函数。 3.具体例子、实例演示当然,以下是一些使用Pandas进行数据分组和聚合的更具体的例子。 3.1 对电影评分数据进行分组和聚合考虑以下电影评分数据,其中包括用户ID,电影ID和评分。 import pandas as pd \# 创建一个dataframe data = {'user\_id': \[1, 1, 1, 2, 2, 3, 3, 3, 3\], 'movie\_id': \[101, 102, 103, 101, 102, 101, 102, 103, 104\], 'rating': \[5, 4, 3, 2, 3, 4, 5, 3, 4\], 'rating2': \[5, 4, 3, 2, 3, 4, 5, 3, 4\]} df = pd.DataFrame(data)如上,这三个变量在示例中用于描述电影评分数据的结构。user_id 列表示哪个用户给电影打了分,movie_id 列表示哪部电影被打了分,rating 列则表示这个用户对这个电影的评分。通过这三个变量,我们可以对电影评分数据进行分组和聚合。例如,我们可以按照 movie_id 列对数据进行分组,然后计算我们可以使用groupby方法将数据按电影ID分组,并对每个组应用mean函数以计算每部电影的平均评分。 grouped = df.groupby('movie\_id') mean\_ratings = grouped.mean() print(mean\_ratings)输出: 对于user_id的值,在第二个例子中会好好进行理解。 查看具体的分组情况如下所示。主要调用grouped.group属性。
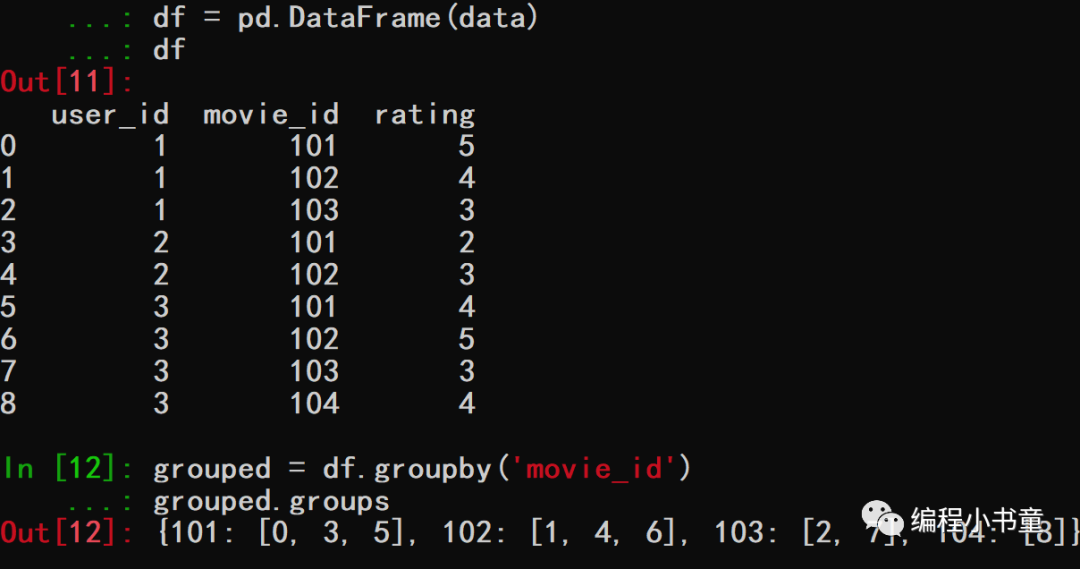
我们可以使用transform方法在每个电影ID分组上应用一个函数,并将结果广播回原始数据框中的每个元素。下面是一个示例代码: import pandas as pd data = {'user\_id': \[1, 1, 1, 2, 2, 3, 3, 3, 3\], 'movie\_id': \[101, 102, 103, 101, 102, 101, 102, 103, 104\], 'rating': \[5, 4, 3, 2, 3, 4, 5, 3, 4\]} df = pd.DataFrame(data) df grouped = df.groupby('movie\_id') grouped.groups mean\_ratings = grouped.transform(lambda x: x.mean()) print(mean\_ratings)输出df和grouped值如下:
结果显示每个元素在其所属的组中的平均评分。
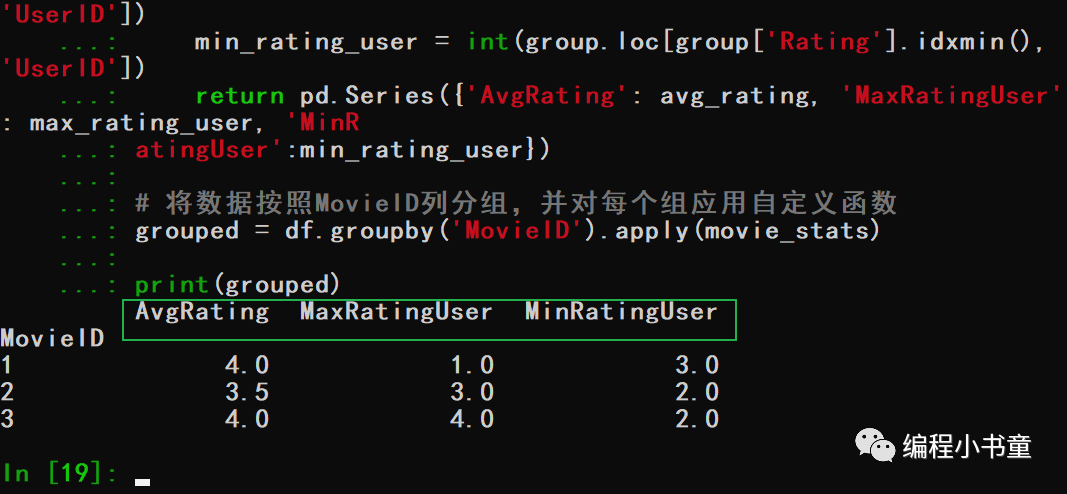
其中图中,红框值2.0计算过程: ①按照movie_id分组后,对应电影101的用户平均id,(1+2+3)/3,即2.0。 ②但是user_id列的平均值没有实际意义。 3.3 使用apply进行分组和聚合使用apply()方法进行分组和聚合操作。假设你有一个包含多个电影评分的数据集,每个电影有多个用户对其进行评分,数据如下: MovieID UserID Rating 0 1 1 5 1 1 2 4 2 1 3 3 3 2 1 3 4 2 2 2 5 2 3 5 6 2 4 4 7 3 1 4 8 3 2 3 9 3 4 5现在我们想要找出每个电影的平均评分,以及评分最高的用户。我们可以使用apply()方法进行分组和聚合操作。首先,我们可以按照电影ID进行分组,然后对每个分组应用一个自定义函数,该函数将计算该分组的平均评分和评分最高的用户。 下面是代码: import pandas as pd \# 创建示例数据 data = {'MovieID': \[1, 1, 1, 2, 2, 2, 2, 3, 3, 3\], 'UserID': \[1, 2, 3, 1, 2, 3, 4, 1, 2, 4\], 'Rating': \[5, 4, 3, 3, 2, 5, 4, 4, 3, 5\]} df = pd.DataFrame(data) df \# 定义自定义函数,计算每个分组的平均评分和评分最高的用户和评分最低的用户 def movie\_stats(group): avg\_rating = group\['Rating'\].mean() max\_rating\_user = int(group.loc\[group\['Rating'\].idxmax(), 'UserID'\]) min\_rating\_user = int(group.loc\[group\['Rating'\].idxmin(), 'UserID'\]) return pd.Series({'AvgRating': avg\_rating, 'MaxRatingUser': max\_rating\_user, 'MinRatingUser':min\_rating\_user}) \# 将数据按照MovieID列分组,并对每个组应用自定义函数 grouped = df.groupby('MovieID').apply(movie\_stats) print(grouped)输出: AvgRating MaxRatingUser MinRatingUser MovieID 1 4.0 1.0 3.0 2 3.5 3.0 2.0 3 4.0 4.0 2.0
这个例子的目的是计算每个电影的平均评分和评分最高的用户和最低的用户,然后将结果保存在grouped变量中。 首先,我们使用groupby()方法将数据按照MovieID列进行分组,然后对每个组应用一个自定义函数movie_stats()。该函数计算每个分组的平均评分和评分最高和最低的用户,并将结果作为Series返回。最后,apply()方法将返回的Series合并成一个DataFrame,包含每个电影的平均评分和评分最高的用户。 3.4 对销售数据进行分组和聚合假设你有一份销售数据,其中包括每个销售员的姓名、销售日期、销售金额等信息。你想知道每个销售员每个月的总销售额,可以使用Pandas进行分组和聚合来实现。输出: 4.总结在数据分析中,经常需要对数据进行分组和聚合操作。Pandas 是一种常用的 Python 数据分析库,它提供了丰富的分组和聚合操作功能,方便我们对数据进行处理。 Pandas 中的分组操作可以使用 groupby() 方法进行,该方法可以将数据按照指定的列或者函数进行分组。分组后,我们可以对分组后的数据进行聚合操作,例如计算分组后的平均值、最大值、最小值、中位数等等。 Pandas 中的聚合操作可以使用 agg() 方法进行,该方法可以对分组后的数据进行多个聚合操作,同时也可以对不同的列进行不同的聚合操作。聚合操作可以使用内置的聚合函数,例如 mean()、sum()、max() 等等,也可以使用自定义的聚合函数。 除了使用内置的聚合函数外,我们还可以使用 apply() 方法对分组后的数据进行自定义的操作。该方法可以传入一个函数或者 lambda 函数,对分组后的数据进行任意的操作, 例如计算多个列之间的相关性,或者将分组后的数据进行可视化等等。 好了,今天的分享就到这里! 最后免费分享给大家一份Python全套学习资料,包含视频、源码,课件,希望能帮到那些不满现状,想提升自己却又没有方向的朋友。 整理不易,请多多点赞分享哦~ 微信扫描下方CSDN官方认证二维码即可领取 Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。 工欲善其事,必先利其器。学习Python常用的开发软件都在这里了! 还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~ 每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈! 光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。这份资料也包含在内的哈~ 我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。 |





 需要的小伙伴可自行微信扫描下方CSDN官方认证二维码免费领取!!
需要的小伙伴可自行微信扫描下方CSDN官方认证二维码免费领取!! 【本文地址】
今日新闻 |
推荐新闻 |