Hello pandas! 新手新篇Hello pandas碰到一些Python或者pandas的初学者,很多基础的语法和使用方法都还没有学会就开始... |
您所在的位置:网站首页 › pandas查看空值 › Hello pandas! 新手新篇Hello pandas碰到一些Python或者pandas的初学者,很多基础的语法和使用方法都还没有学会就开始... |
Hello pandas! 新手新篇Hello pandas碰到一些Python或者pandas的初学者,很多基础的语法和使用方法都还没有学会就开始...
|
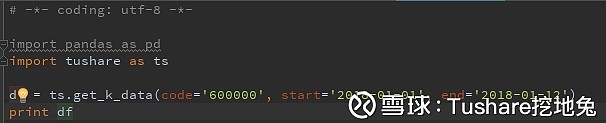
来源:雪球App,作者: Tushare挖地兔,(https://xueqiu.com/9103835084/99747982) 新 手 新 篇 Hello pandas 碰到一些Python或者pandas的初学者,很多基础的语法和使用方法都还没有学会就开始打算用Tushare进行数据分析,毫无疑问会无从下手甚至开始怀疑人生直到放弃。 其实只要稍微花一点时间学习一下基础知识,就会变得豁然开朗,再深入学习后就得心应手了。 以下是一个用户发来的学习笔记(欢迎更多用户投稿~_~),从入门到精通,只差比别人少玩了几轮游戏。 写在前面 网上介绍python之pandas库非常多,这篇从sql语言的角度解读,相信更适合有sql语言(MySql)基础的你,像使用sql一样搞定pandas。 依然要说安装,本篇案例数据均取自tushare。 1、安装pandas,如果你安装的是anaconda,那么就不用单独安装了,因为anaconda已经集成了pandas。 2、安装tushare库 Windows系统(win7及以上) a)打开Anaconda Prompt b)输入命令:pip install tushare c)按“Enter”键 安装tushare,如果你看过前篇《python数据处理之入门》,在“安装python”之“安装python库”章节亦可见。 还是那句话,最重要的是业务,python是帮你实现的工具。 创建表 对于mysql而言,要查看或处理其数据,首先数据肯定得是存储在某个表中,这个表是个二维的结构。 在mysql创建表的语句是create table …… 那么在pandas里,这种二维的数据结构是怎么呈现的呢?他叫DataFrame,创建一个DataFrame就相当于创建了一张表。 比如,在tushare返回的日行情数据(get_k_data)结果就是DataFrame。 上代码:
说说索引 第1列,是不是类似你们经常看到的自增长ID,那么在DataFrame,他叫index(索引),这个索引非常重要,在将来的数据分析计算使用非常频繁。 所以,对于这个index,pandas也提供了一些函数满足你对他的要求,比如set_index,reset_index,举个set_index的例子,当我想使用date列作为索引的时候,请看下面截图代码:
从上面截图可以一目了然的看到字段,对字段的操作,mysql有ALTER命名,那么对于pandas是什么样的呢,字段其实是个一维的结构,在pandas里面叫Series。 加个字段 我想加个字段,内容为”Boss出品”
请看执行结果:
有字段我不想要,怎么办,简单哈,删字段呗,pandas提供了drop函数可以用来删字段,当日,也可以使用筛选filter,等等 比如,对于调出的数据结果,开高低价格用不上,那就去掉。
执行结果: 我很懒,截个执行结果的图都不想干,咱们自己写代码,亲自执行看结果。 修改字段 Pandas不需要指定数据类型,那么就只剩下修改列名了。 你们想改哪个字段名,我想把date修改为trade_date。
懒! 数据查询 像写SQL一样,使用pandas 实现select sql查询,select后面跟着的就是选字段, pandas,哇!!!他更牛,不但可以根据列名来选,还能根据位置来选。 1、根据列名来选 filter,loc,at,ix,drop(drop是反向的,参见”删个字段”),以loc为例,at与loc相近。
df2 = df[['date', 'code', 'close']] 2、根据位置来选 iloc,iat,ix 以iloc为例,iat与iloc相近
细心的你们肯定又注意到了,根据列表和位置来选,都有ix。 ix,既能当loc用,又能当iloc用,兼有根据列名和位置筛选筛选两种功能
1、loc,iloc,at,iat,ix 使用位置过滤 还记得前面说过,pandas的index很常用吗,没错,在数据过滤查询里就会用到了。使用loc,iloc,at,iat,ix过滤,上述截图,大家注意到没有,无论是根据列名,还是根据位置选择列,在前面都有个冒号“:” 没错,这个就是用来做行筛选的,相当于mysql中的where
执行结果:
这个是使用数字序列,如果使用日期作为索引,大家的感受可能会更深一些, 比如:
--执行什么? --什么结果? --结什么果? 算了,咱们敲一遍代码,自己执行看结果吧。 查询筛选 pandas对行的筛选必须要使用index(索引)吗?非也,非也,mysql里有的,pandas肯定能满足你,请继续往下看: mysql里筛选使用的and,or,in,not in之pandas实现。 为了举例更方便,让大家更直观,我在tushare.get_k_data调了浦发银行、万科两只股票的行情。
1、and之实现 筛选出浦发银行2018年1月11日的行情 使用符号“&”
筛选收盘价大于35元,或浦发银行2018年1月11日的行情 使用符号“|”
筛选浦发银行、万科,2018年1月11日和12日两天的日行情
筛选浦发银行、万科,不要2018年1月11日和12日这两天的日行情
对应mysql之order by pandas有使用索引排序或使用列排序两种选择,分别是:sort_index, sort_values,使用参数ascending(True、False)来满足对升序或降序的要求,比如 1、使用索引,按降序排列
取n行 对应mysql之limit pandas不但能取前n行,还提供函数可以取后n行,分别是head()、tail() 如,取前4行、后4行
对应MySql之distinct 在数据查询中,通常会使用去重,对应的pandas函数是drop_duplicates,并且更前大的是drop_duplicates提供了参数keep,供你选择保留第1条,亦或是将重复数据全删除。
对应MySql之Null pandas有空日期pd.NaT,空值None,空值亦或称之为缺失值 1、缺失值筛选 MySql的筛选通常有where date is null,或is not null pandas对应的筛选办法是 df = df[df['close'].isnull()] df = df[df['close'].notnull()] 代码:
参考链接: 网页链接 再重点说下缺失值的填充 2、 fillna 对缺失值的填充,是咱们经常遇到的,比如填充个假值,用前一天数据填充,亦或用下一交易日数据填充 1) 填充为指定的值,即常说的赋值
df.fillna({'close': 1, 'NullValue': 9}, inplace=True) 2) 使用前一天值/后一天值填充
是不是昏昏了,我有点昏昏了,再介绍两个提提神。 下面介绍两个相对于MySql查询的两个重量级应用,关联查询和分组查询 关联查询(join) pandas指join和merge 这两个的使用方法相近,都能通过索引关联和字段关联 1、先说join join被用在通过索引关联较多 DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False) e.g.
left:左连接 right:右连接 outer:外连接 inner:内连接 上述关联关系,相信不用详细介绍,大家都知道了,跟Mysql的关联方法极其相近 lsuffix和rsuffix 这两个参数,用来标记当关联DataFrame出现相同字段名称的时候区分方法 2、merge merge这个单词,印象最深刻的是听青桃说merge,在耳畔萦绕。 下面就介绍下pandas里的merge merge被用在通过字段关联较多 DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None) merge里, how:同上join (on),(left_on,right_on),(left_index,right_index)这3组参数是单选项,3选1就可以了; on:用在当关联的两个DataFrame的字段名相同时; left_on,right_on:当关联的两个DataFrame的字段名不相同时; left_index,right_index:使用索引关联 e.g.
大家在看代码的时候,一定看到了append,没错,就是在调用浦发银行、万科两只股票的时候用到了, append,将两个DataFrame按行合并 那么concat呢,同样的,只是concat功能更多,还提供了axis参数供选择按行还是按列合并,相当于MySql里的union查询 分组查询 MySql之group by 分组求pandas提供的函数值,及自定义的函数值(如beta) 常见的MySql之group by有求和,求最大值,最小值,平均值等 pandas能支持的那就多了,求波动率,求协方差等等等,还可以自定义函数然后调用,说着说着不由得心中一阵兴奋。 e.g.
写到这里,基本上将常用的pandas方法介绍好了。 输入输出 那么,大家可能还有个困惑,案例数据都是从tushare调用的,在日常使用时,还有不使用tushare的情况,那么这个时候,该如何读取(输出),和存储(输入)数据呢? 这就是这一节要说的内容 先说批量读取数据 read_* pandas提供了很多种读取数据的方法: read_sql,read_csv,read_excel,read_json 重点介绍下read_sql pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None) 介绍一下前面最常用的两个参数,后面的参数以后大家在使用的时候慢慢体会 sql:就是你最常用的sql查询语句 conn:连接mysql的接口 还是上栗子,更直观的看明白怎么使用 被抹掉的地方,大家填下你们自己的主机名(或IP),端口,数据库名,用户名,密码。 sql换成你想要查询的数据,最后打印下df(print df)就能很清晰的,你的sql将要查询的数据,被加载到内存中了,接下来,你就可以对这个数据进行处理了。 是不是很简单! 还有其他的read,方法很类似。 to_* 说完读取,该说下,怎么存储数据了,目标格式有很多: to_sql, to_csv,to_excel,to_json 介绍下to_excel, 数据量不大的时候,借助excel工具分析,是很方便的。比如,你可能使用python爬虫,爬了一些数据,数据量也不大,那么你就可以将爬下来的数据转换为DataFrame,再保存到excel中。 那么怎么使用to_excel将数据保存到excel里呢,同样很简单。 e.g.
代码:
定义变量File,定义将数据保存的目标文件,使用pandas函数ExcelWriter, 使用to_excel,并执行保存在哪个sheet上,执行保存 结果: 去D盘看看,是不是有个文件叫600000.xlsx的
所谓进阶,实战一把,计算个简单常用的。 不知大家刚刚注意到没有,调用的get_k_data没有昨收盘,收盘价日收益率,那么就来计算一下。 1、通过tushare接口把数据调出来
code列分组,按日期升序排序
后记 拖了很久,终于把Hello pandas写好了,这里介绍的都是基本的,最重要的还是在工作中亲身使用。 学习代码,最重要的还是有业务场景,亲自来写,进展就会很快,就像以前大家学习SQL一样,SQL同样是数据分析最重要的工具之一,如果能再熟练的使用python,那么又将是一个飞跃。 感谢Boo供稿,希望对初学者有一定帮助,也期待更多热爱学习的朋友参与进来,学数据、用数据! |
 运行结果:
运行结果: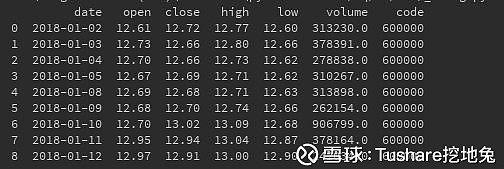 这个运行结果是不是超级熟悉?
这个运行结果是不是超级熟悉?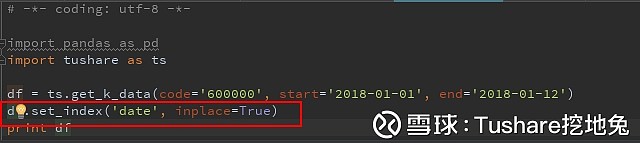 运行结果:
运行结果: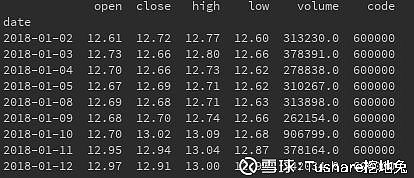 字段
字段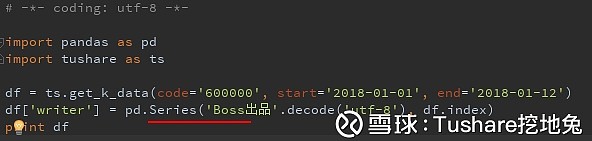 这样这个新的字段就加上了,并且赋了值
这样这个新的字段就加上了,并且赋了值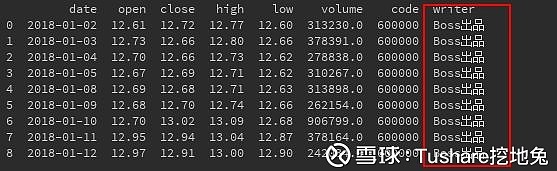 删个字段
删个字段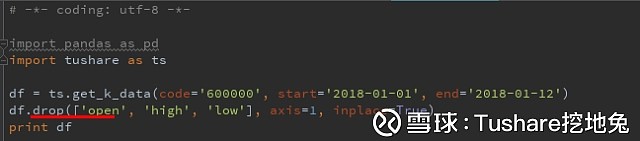 细心的你一定看到了axis这个参数,没错drop可以删除列,也可以对行进行删除。
细心的你一定看到了axis这个参数,没错drop可以删除列,也可以对行进行删除。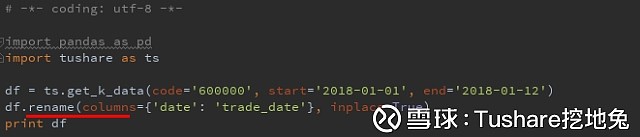 执行结果:
执行结果: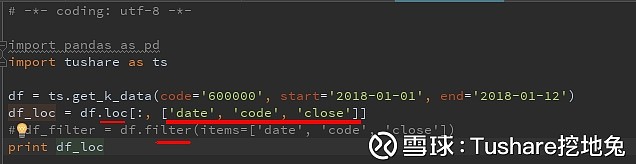 另外,还有一种类似切片的方法,如下:
另外,还有一种类似切片的方法,如下: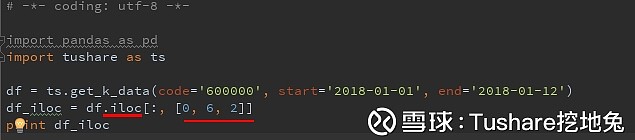 说说ix
说说ix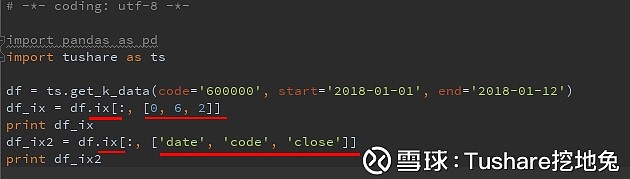 实现where
实现where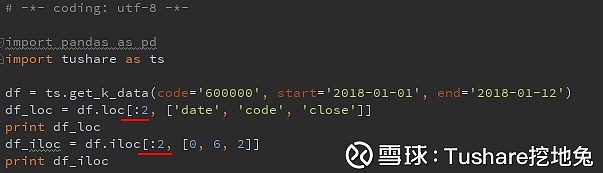 执行结果,在筛选的index范围内,不过你们注意没有,loc与iloc的过滤结果略微有些差异:
执行结果,在筛选的index范围内,不过你们注意没有,loc与iloc的过滤结果略微有些差异: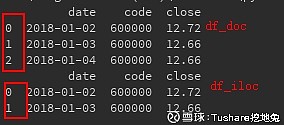 很明显,使用loc,包含了筛选使用的索引,而iloc没有。
很明显,使用loc,包含了筛选使用的索引,而iloc没有。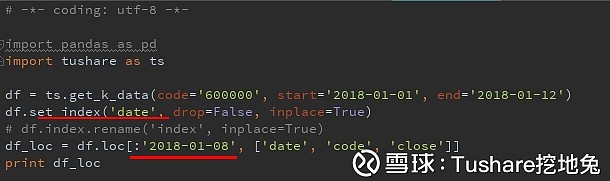 先设置了日期列作为索引,再使用loc对数据进行行列筛选。
先设置了日期列作为索引,再使用loc对数据进行行列筛选。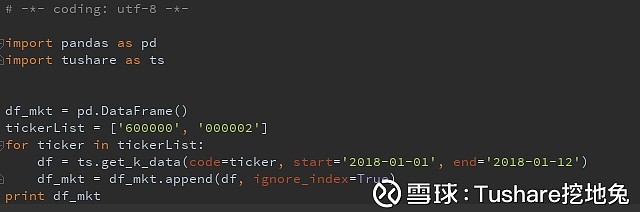 代码运行后,就有了浦发银行、万科的日行情。
代码运行后,就有了浦发银行、万科的日行情。 2、or之实现
2、or之实现 3、 in之实现
3、 in之实现 4、not in 之实现
4、not in 之实现 另外,还可以使用query函数来构造筛选,如,筛选出浦发银行日行情:
另外,还可以使用query函数来构造筛选,如,筛选出浦发银行日行情: order排序
order排序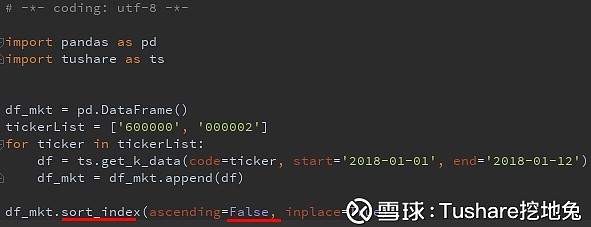 2、按收盘价,升序排列
2、按收盘价,升序排列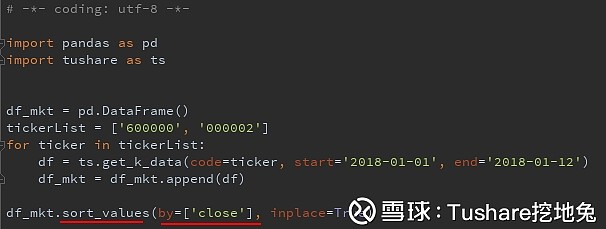 参数ascending默认等于True升序排列,所以不用写了。
参数ascending默认等于True升序排列,所以不用写了。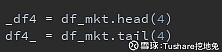 MySql通常有先排序,再limit,pandas同样可以一行代码实现
MySql通常有先排序,再limit,pandas同样可以一行代码实现 去重
去重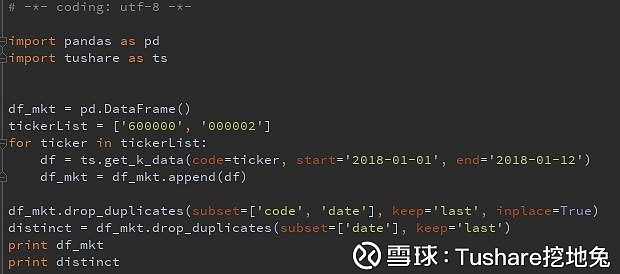 空值
空值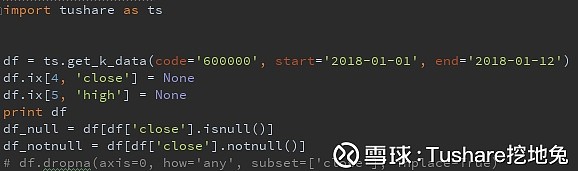 另外,pandas还提供了dropna,用来做缺失值的行列选择,这里不再赘述,大家可以使用参考链接去看下dropna的使用方法,
另外,pandas还提供了dropna,用来做缺失值的行列选择,这里不再赘述,大家可以使用参考链接去看下dropna的使用方法,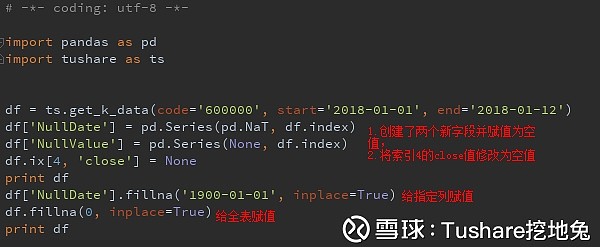 同时指定多个列赋值:
同时指定多个列赋值: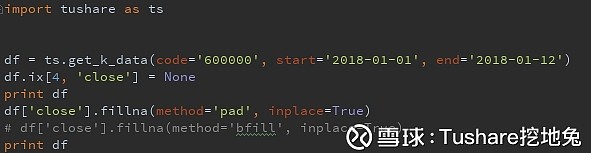 使用fillna提供的的method参数即可
使用fillna提供的的method参数即可 how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default: ‘left’
how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default: ‘left’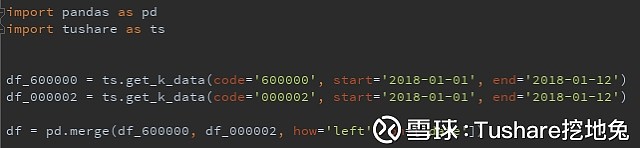 3、concat, append
3、concat, append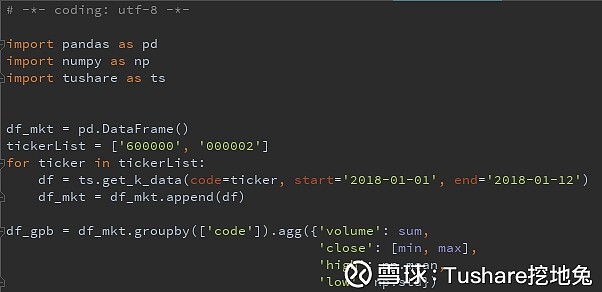 对成交量求和,对收盘价求最小值和最大值,对最高价求平均值,对最低价求标准差
对成交量求和,对收盘价求最小值和最大值,对最高价求平均值,对最低价求标准差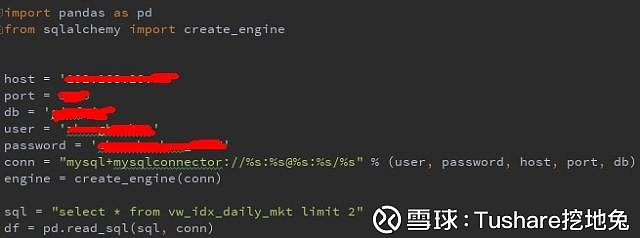 还是从tushare上拿数据,保存到D盘叫做600000的excel文件
还是从tushare上拿数据,保存到D盘叫做600000的excel文件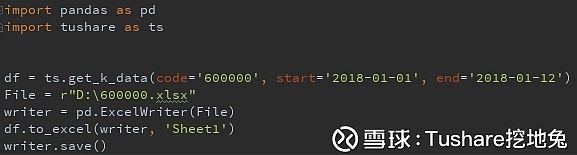 代码说明:
代码说明: 进阶
进阶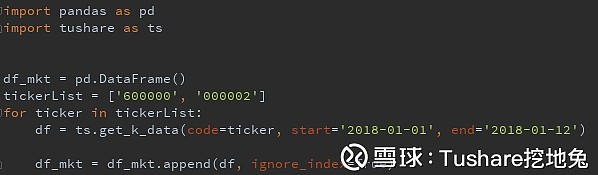 2、求昨收盘,
2、求昨收盘, 计算昨收盘
计算昨收盘 3、计算日收益率
3、计算日收益率 到这里,计算需求就完成了。有没有激起学习的兴趣!
到这里,计算需求就完成了。有没有激起学习的兴趣!【本文地址】
今日新闻 |
推荐新闻 |