pandas之 read |
您所在的位置:网站首页 › pandas提取一行不带索引 › pandas之 read |
pandas之 read
|
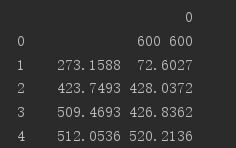
pandas的read_table返回一个DataFrame,是二维的,会像一棋盘那样标识数据,例如:
如上图,txt文件的数据在黑色内一块,而旁边每行和每列会被额外标上数字记录是哪一行那一列。这就是DataFrame
========================================================================================= 现有txt文件如下: 这些数据表示的是每个城市的(x,y)坐标
两列数据,中间以空间隔开。 import pandas as pd #引入pandas包 citys=pd.read_table('./1.txt',sep='\t',header=None) #读入txt文件,分隔符为\t print(citys)seq标识分隔符,分隔符为\t ,即制表符,表示列与列之间用\t分开 header=None 表示txt文件的第一行不是列的名字,是数据。若不写head=None,则读入txt数据时,会没了第一行 打印结果:
可以看到全部数据就只有一列了,因为分割符为制表符,而制表符存在于txt文件每行的末尾。
接着把第一列的名字改成x,并添加一列,名字为y,y这一列的数值全是None: citys.columns=['x'] citys['y']=None print(citys)打印结果:
最后把 x列中的数据,以空格为分割符,分给y一个数: for i in range(len(citys)): #遍历每一行 coordinate = citys['x'][i].split() #分开第i行,x列的数据。split()默认是以空格等符号来分割,返回一个列表 citys['x'][i]=coordinate[0] #分割形成的列表第一个数据给x列 citys['y'][i]=coordinate[1] #分割形成的列表第二个数据给y列 print(citys)打印结果:
可以看到,已经给txt的数据打上了x和y的标志了。
完整代码: import pandas as pd #引入pandas包 citys=pd.read_table('./1.txt',sep='\t',header=None) #读入txt文件,分隔符为\t citys.columns=['x'] citys['y']=None for i in range(len(citys)): #遍历每一行 coordinate = citys['x'][i].split() #分开第i行,x列的数据。split()默认是以空格等符号来分割,返回一个列表 citys['x'][i]=coordinate[0] #分割形成的列表第一个数据给x列 citys['y'][i]=coordinate[1] #分割形成的列表第二个数据给y列 print(citys)打印结果:
|




【本文地址】