pandas实战(911紧急电话) |
您所在的位置:网站首页 › pandas实战 › pandas实战(911紧急电话) |
pandas实战(911紧急电话)
|
目的:
统计数据中不同类型的紧急情况的次数统计911数据中不同月份电话次数的变化情况统计911数据中不同月份不同类型的电话次数的变化情况
数据来源:911电话数据 一、统计数据中不同类型的紧急情况的次数 file_path = "./911.csv" df = pd.read_csv(file_path) # 行表示电影,列表示电影属性 print(df.head()) print(df.info())首先打印前5行数据和数据的相关信息
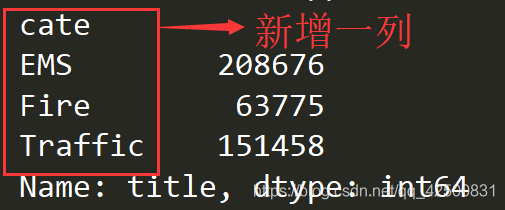
在原始的DataFrame添加种类一列,先获取每个电话的种类放在列表中,根据列表构造DataFrame并添加到原始的DataFrame中,按照列别分组,然后求和 file_path = "./911.csv" df = pd.read_csv(file_path) temp_list = df["title"].str.split(":").tolist() cate_list = list(i[0] for i in temp_list) df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0], 1))) print(df.groupby(by="cate").count()["title"])
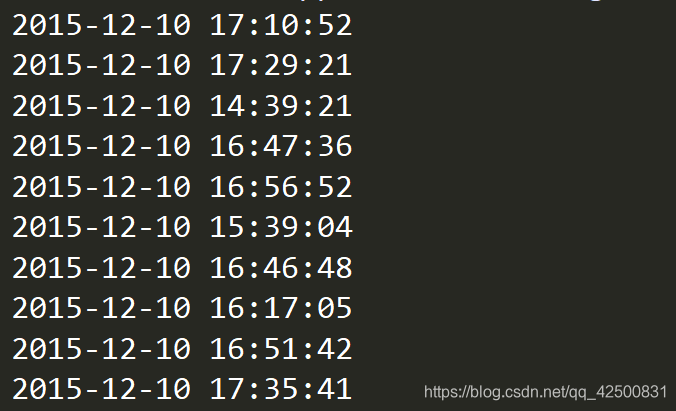
有关时间的要求,我们打印一下数据中的时间戳信息 file_path = "./911.csv" df = pd.read_csv(file_path) for i in range(10): print(df.iloc[i]["timeStamp"])
按每月进行重采样,并统计每月样本的数量(即每月的电话次数) count_by_month = df.resample("M")["title"].count() print(count_by_month)
这个要求和上面的要求差不多,就是把数据按照类别分组后重采样得到数据,然后分别画出3组数据的图即可 1、添加一列,表示类别 file_path = "./911.csv" df = pd.read_csv(file_path) # 添加列,表示分类 temp_list = df["title"].str.split(":").tolist() cate_list = list(i[0] for i in temp_list) df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0], 1)))2、将时间转换为pandas内置时间类型,设置成索引,方便采样 df["timeStamp"] = pd.to_datetime(df["timeStamp"]) df.set_index("timeStamp", inplace=True)3、按照类别分组 grouped = df.groupby(by="cate")4、对每组数据重采样,并画图 plt.figure(figsize=(20, 8)) for name, data in grouped: count_by_month = data.resample("M").count()["title"] # 重新设置时间格式,显示时美观 x = [i.strftime("%Y-%m-%d") for i in count_by_month.index] y = count_by_month.values plt.plot(range(len(x)), y, label=name) plt.xticks(range(len(x)), x, rotation=45) plt.legend(loc="best") plt.show()画图结果: |
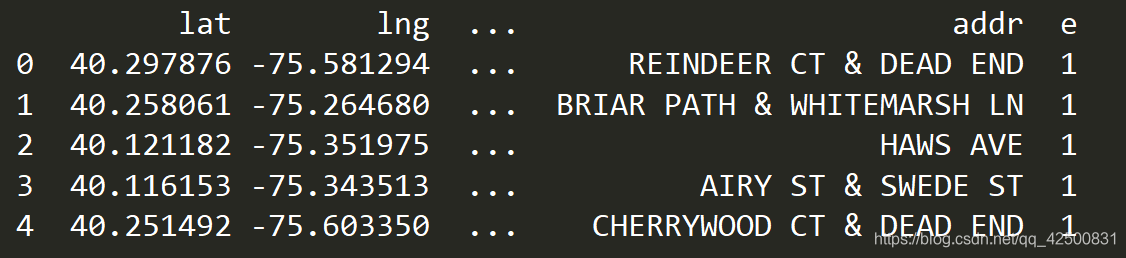
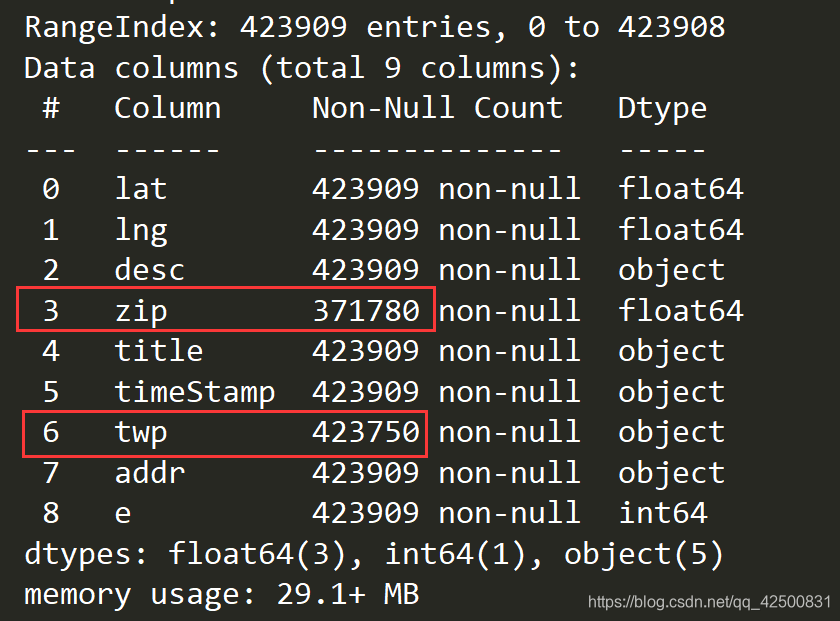 可以看到,只有zip和twp有缺失,别的都没有缺失 打印一下第一条数据
可以看到,只有zip和twp有缺失,别的都没有缺失 打印一下第一条数据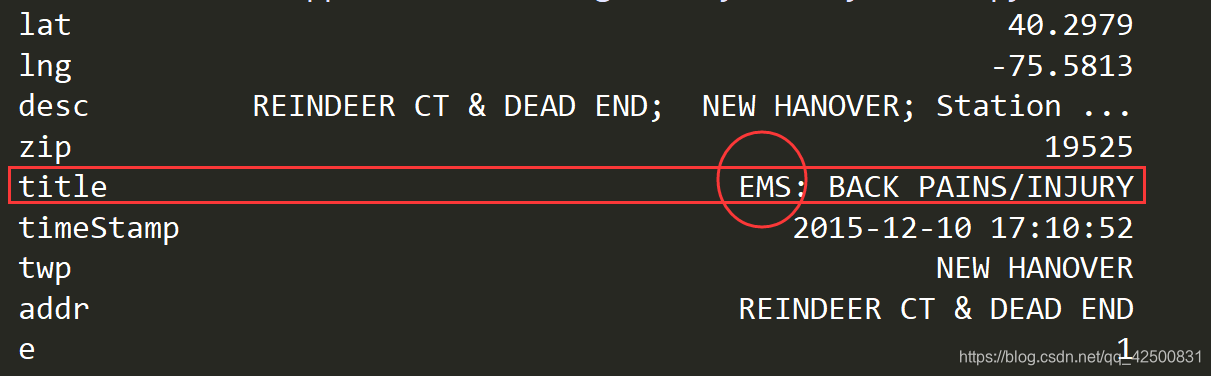 通过分析,我们知道分类情况存在于title中,那我们将title一列的值按照 : 切分 ,将切分后的title一列转换成列表,遍历列表中每个列表的0号元素就可以取到911电话的类别
通过分析,我们知道分类情况存在于title中,那我们将title一列的值按照 : 切分 ,将切分后的title一列转换成列表,遍历列表中每个列表的0号元素就可以取到911电话的类别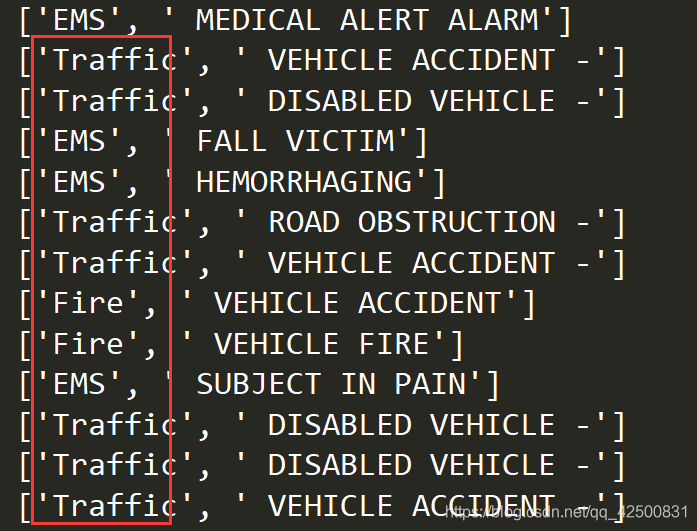 获取所有的类别:
获取所有的类别: 接下来我们构造一个423909*3的全零DataFrame,然后按照类别对相应数据赋值成1,并求和就得到了每个类别的电话数量
接下来我们构造一个423909*3的全零DataFrame,然后按照类别对相应数据赋值成1,并求和就得到了每个类别的电话数量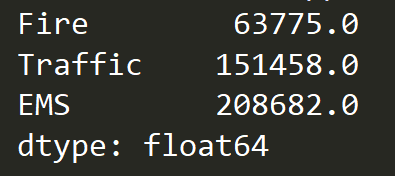
 分析题目要求后,我们将原始数据中的时间转换成pandas内部的时间类型,然后将此列设置成索引,以方便我们进行每月采样,采样后就可以得到每月电话的次数
分析题目要求后,我们将原始数据中的时间转换成pandas内部的时间类型,然后将此列设置成索引,以方便我们进行每月采样,采样后就可以得到每月电话的次数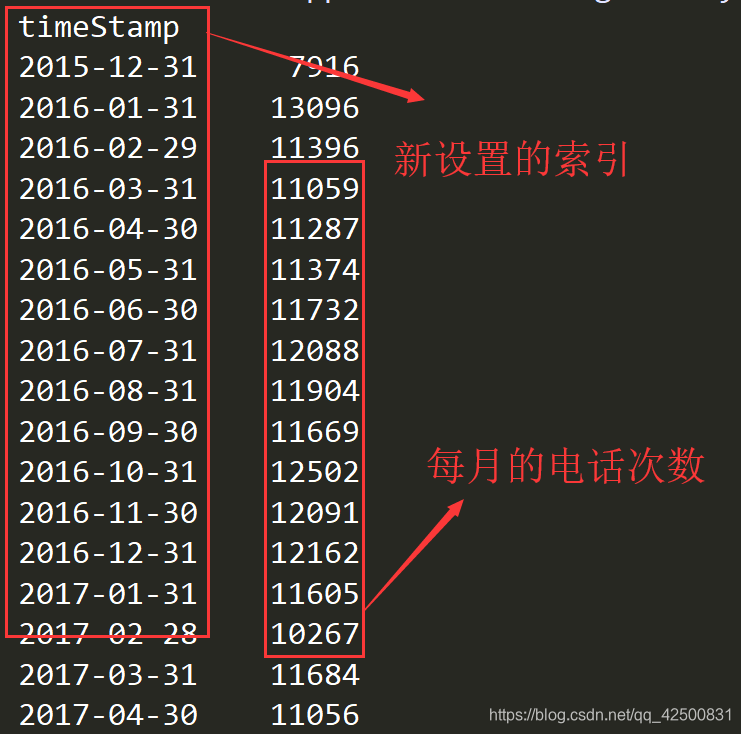 画图
画图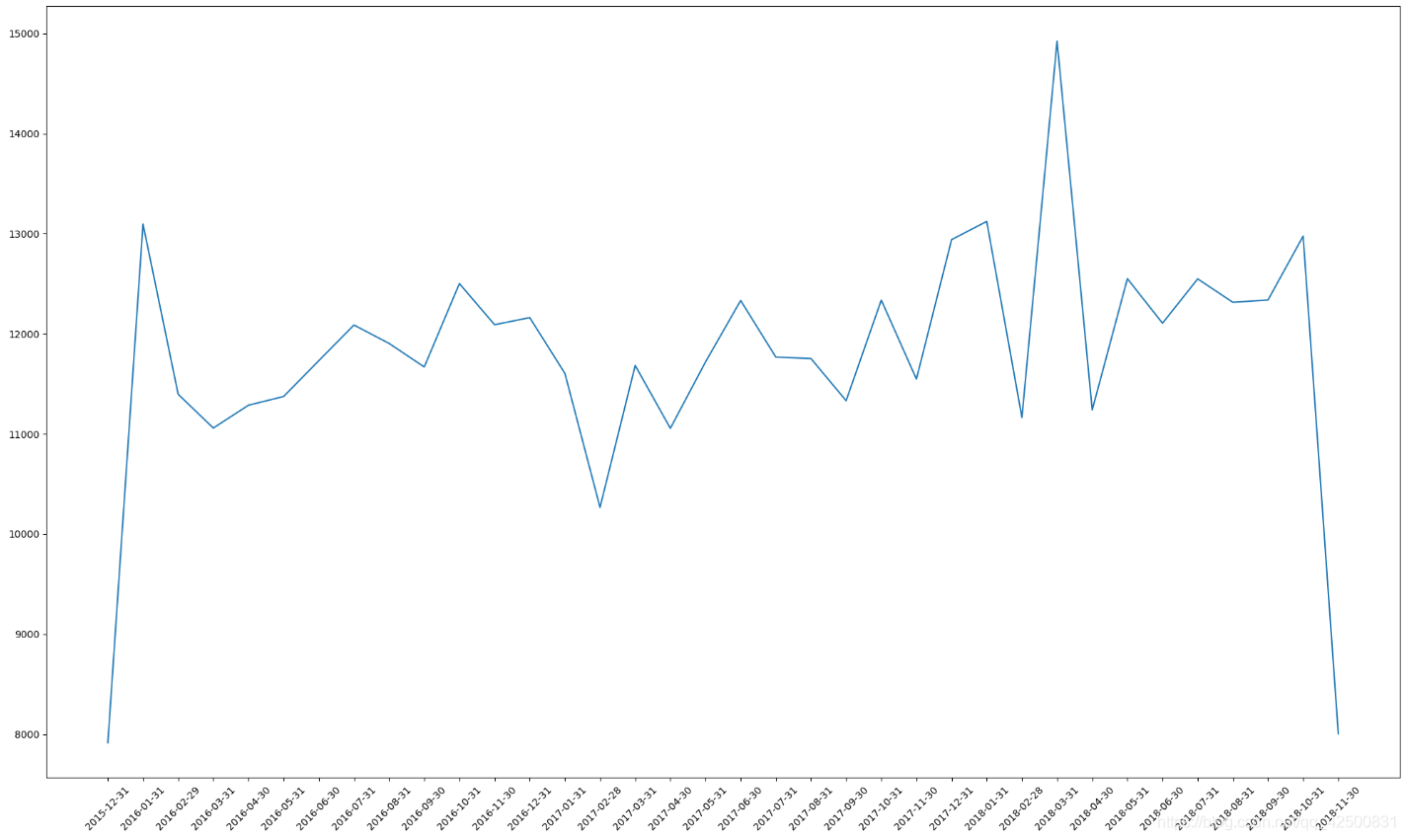 由于两侧统计数据不全,所以采样得到的数据较小
由于两侧统计数据不全,所以采样得到的数据较小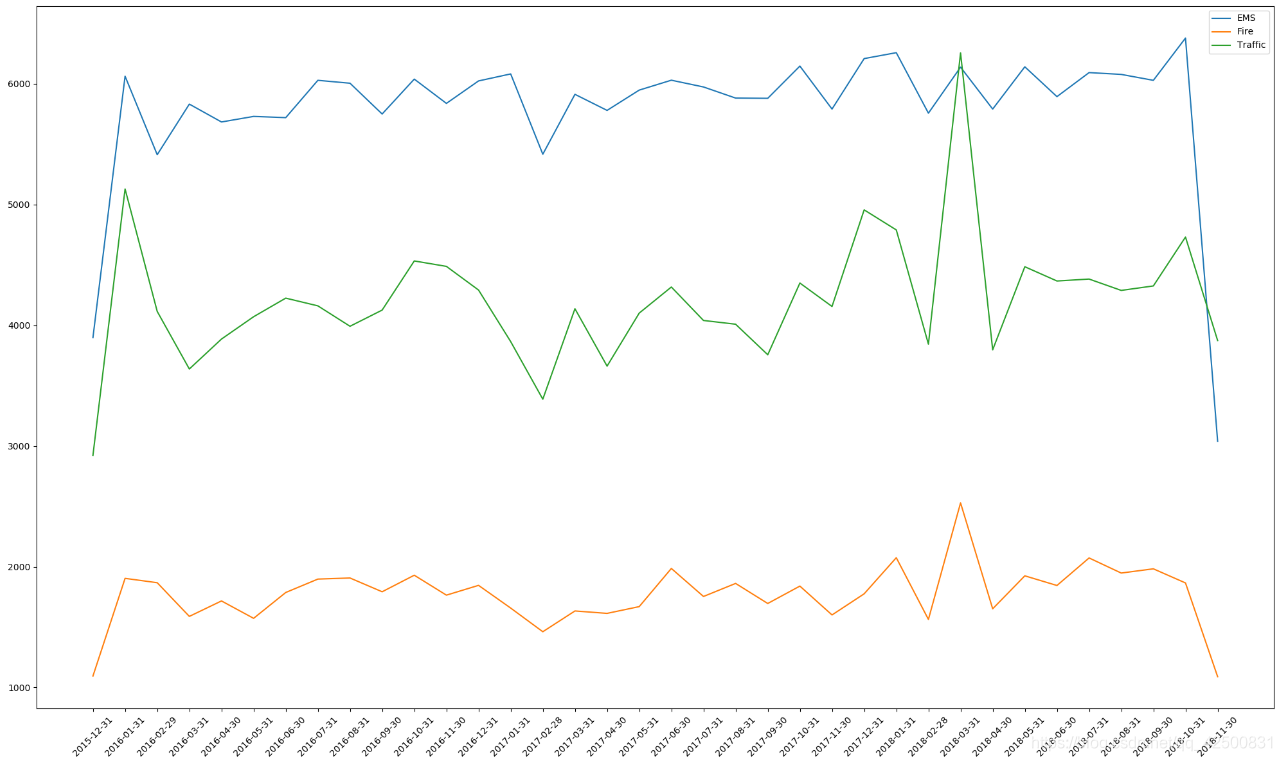
【本文地址】
今日新闻 |
推荐新闻 |