panda dataframe简易上手空值统计与处理 |
您所在的位置:网站首页 › pandas填充空值 › panda dataframe简易上手空值统计与处理 |
panda dataframe简易上手空值统计与处理
|
1.空值统计
空值统计
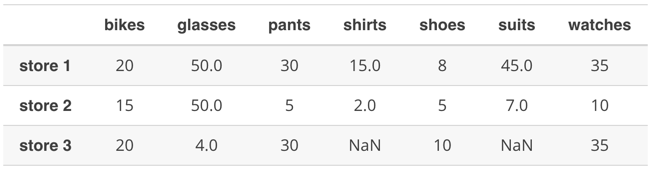
num_vars['Salary'].isnull().sum() 非空值统计num_vars['Salary'].count() 单行空值比例统计(例如:空值占百分之五十以上)np.sum(num_vars['salary'].isnull().mean()>=.50) 整个dataframe中统计空值超过百分五十的列np.sum(num_vars.isnull().mean()>=.50) 为什么对空值这么关心呢?因为不同的空值比例,我们的处理方案也不一样。比如全空,空值占一半,空值占一大半。下一次会写一篇pandas数据分析的基础模版,对各种情况进行分析。比如对不同的文本分类种类进行one-hot编码 2.空值处理 1.1 傻X无脑填充法
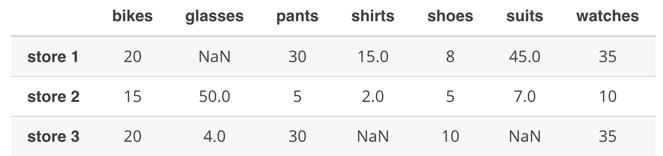
1.使用前项填充 store_items.fillna(method = 'ffill', axis = 0)
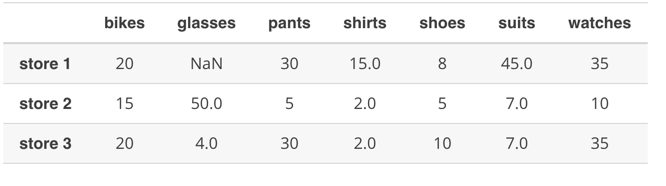
发现glasses 的一个值没有被填充,前向填充就是用后一个人舔自己的位置,后向填充相反。 2.使用后项填充 store_items.fillna(method = 'backfill', axis = 0)
3.线性填充(可与理解为等差序列填充)
对于控制的处理我们要慎重,空值如何填充,如何处理?是一个值得考量的问题,这里给出两种法 Mean()平均值填充df=df.fillna(df.mean()) 但若遇上了布尔值,或者字符串以及类别就很不好。 Mode() 众数填充
您在此看到了两种最常用的估算值方法,并且希望您意识到即使这些方法也很复杂。同样,这些方法可以是迈出建立模型的第一步,但是使用这些方法可能会对引入模型的偏差产生不利影响。 2.删除法data.dropna(how = 'all') # 传入这个参数后将只丢弃全为缺失值的那些行 data.dropna(axis = 1) # 丢弃有缺失值的列(一般不会这么做,这样会删掉一个特征) data.dropna(axis=1,how="all") # 丢弃全为缺失值的那些列 data.dropna(axis=0,subset = ["Age", "Sex"]) # 丢弃‘Age’和‘Sex’这两列中有缺失值的行 |


【本文地址】