Python数据分析之Pandas学习笔记(很全包含案例及数据截图) |
您所在的位置:网站首页 › pandas创建表格 › Python数据分析之Pandas学习笔记(很全包含案例及数据截图) |
Python数据分析之Pandas学习笔记(很全包含案例及数据截图)
|
一、Pandas认识 pandas主要是用来进行数据处理/数据分析的第三方库,其中不仅包含了数据处理、甚至还有统计分析等相关计算,其内部封装了numpy的相关组件。 pandas的主要数据类型有:series(一维结构)、dataframe(二维结构)、pannel(三维结构) 二、创建DataFrame和Series1、加载数据import numpy as np # 加载数据 res = np.load('某数据.npz') columns = res['columns'] values = res['values'] print('columns:\n',columns) print('values:\n',values)2、数组转化为df结构将数组转化成 我们想要的 比较好看的行列结构 # df 相对于数组,多了行索引,列索引 index = ['index_' + str(i) for i in np.arange(69)] df = pd.DataFrame(values, columns=columns, index=index) print(df)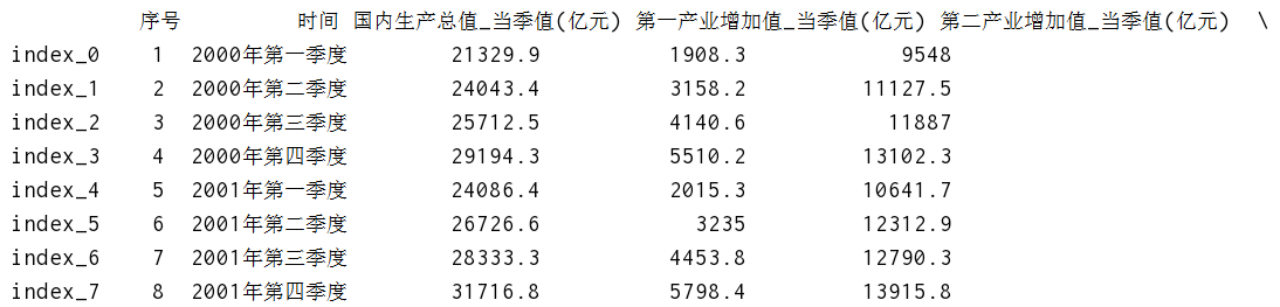 3、将df转化为Series结构(取df某一列) 3、将df转化为Series结构(取df某一列)如何将df转化为Series,由于Series只有行索引,没有列索引,所以Series只是DataFrame取一列的特殊情况 ser = df['序号'] print(ser) print(type(ser)) 根据行索引或行索引名称取出series中的行数据 ser = df['时间'][['index_0', 'index_1', 'index_3']] # ser = df['时间'][[0,1,2,3,4]] print(ser) 4、使用字典生成一个df数据d = {'col1':[0,1,2],'col2':[1,2,3],'col3':[3,4,5]}
df = pd.DataFrame(data=d,index=['a','b','c'])
print(df)
print(type(df)) 4、使用字典生成一个df数据d = {'col1':[0,1,2],'col2':[1,2,3],'col3':[3,4,5]}
df = pd.DataFrame(data=d,index=['a','b','c'])
print(df)
print(type(df)) 拿取多列数据,可以发现,数据类型还是df并不是series(series只能是拿取df的一列数据) # 取多列 res = df[['col1','col2']] print(res) print(type(res)) 5、使用series方法自己生成一个series数据ser = pd.Series([1,2,3],index=['a','b','c'])
print(ser)
print(type(ser)) 5、使用series方法自己生成一个series数据ser = pd.Series([1,2,3],index=['a','b','c'])
print(ser)
print(type(ser)) 三、DataFrame的属性1、手动创建一个df数据(每一列数据类型一致)import pandas as pd
# 创建df
df = pd.DataFrame(
{
'col1': [0,1,2],
'col2': ['zs','ls','ww'],
'col3': [1.2,3.14,5.20],
'col4': [1,1,0]
},
index = ['index0','index1','index2'])
print(df)
print(type(df)) 三、DataFrame的属性1、手动创建一个df数据(每一列数据类型一致)import pandas as pd
# 创建df
df = pd.DataFrame(
{
'col1': [0,1,2],
'col2': ['zs','ls','ww'],
'col3': [1.2,3.14,5.20],
'col4': [1,1,0]
},
index = ['index0','index1','index2'])
print(df)
print(type(df)) 2、df的values属性(可用于数组和dataframe数据转化)# df的值,获取df数组
print('df 的values:\n',df.values) 2、df的values属性(可用于数组和dataframe数据转化)# df的值,获取df数组
print('df 的values:\n',df.values) 3、获取df行索引名称# 获取行索引名称
print('df 的index:\n',df.index) 3、获取df行索引名称# 获取行索引名称
print('df 的index:\n',df.index)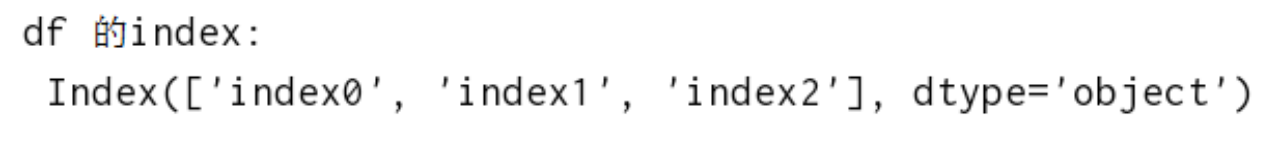 4、获取df列索引名称# 获取列索引名称
print('df 的columns:\n',df.columns) 4、获取df列索引名称# 获取列索引名称
print('df 的columns:\n',df.columns) 5、获取df元素个数# 获取元素个数
print('df 的size:\n',df.size)6、获取df每一列的数据类型# 获取数据类型
print('df 的dtypes:\n',df.dtypes) 5、获取df元素个数# 获取元素个数
print('df 的size:\n',df.size)6、获取df每一列的数据类型# 获取数据类型
print('df 的dtypes:\n',df.dtypes)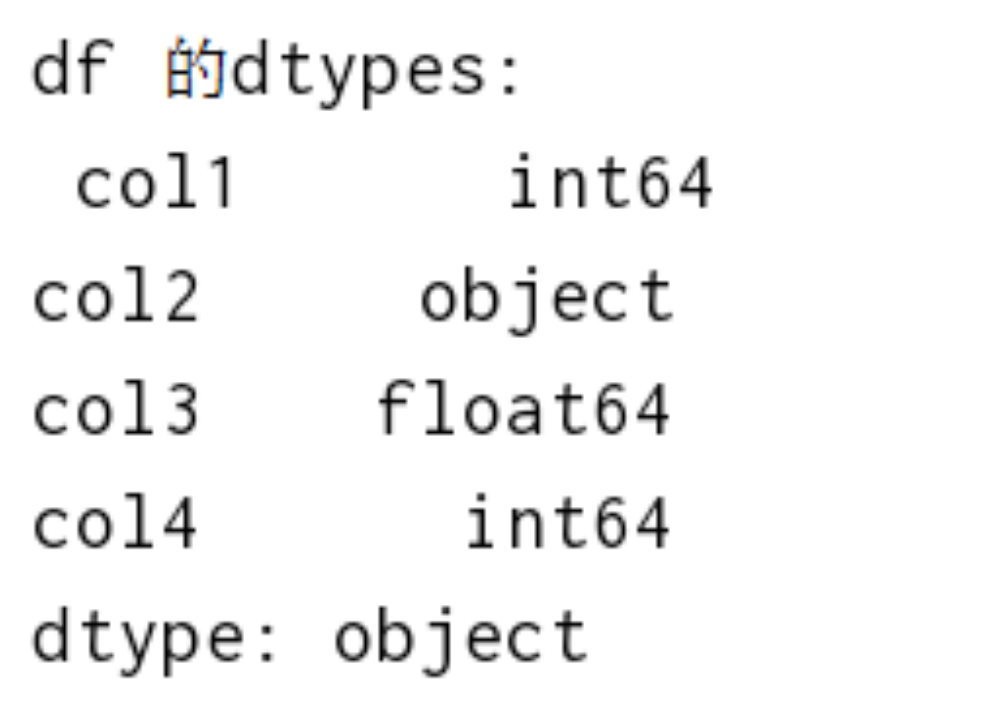 7、获取df的形状# 获取形状
print('df 的shape:\n',df.shape)8、获取df维度# 获取维度
print('df 的ndim:\n',df.ndim)四、Pandas数据存储与读取1、加载文本数据(table方式)# table 默认\t分隔
info = pd.read_table('xxxx.csv',encoding='ansi',sep=',')
print(info)2、加载文本数据(csv方式)info = pd.read_csv('xxxx.csv',encoding='ansi',usecols=['phone','name'])
print(info)
参数:
header=infer 自动识别列名 自动认为第一行为列名
names 设置列名 接收array 默认为None
index_col 设置行索引 如[0,1]是将第0列,第1列作为行索引
nrows 读取的时候读取前n行
usecols 指定读取的列 ['info_id','use_id'] 7、获取df的形状# 获取形状
print('df 的shape:\n',df.shape)8、获取df维度# 获取维度
print('df 的ndim:\n',df.ndim)四、Pandas数据存储与读取1、加载文本数据(table方式)# table 默认\t分隔
info = pd.read_table('xxxx.csv',encoding='ansi',sep=',')
print(info)2、加载文本数据(csv方式)info = pd.read_csv('xxxx.csv',encoding='ansi',usecols=['phone','name'])
print(info)
参数:
header=infer 自动识别列名 自动认为第一行为列名
names 设置列名 接收array 默认为None
index_col 设置行索引 如[0,1]是将第0列,第1列作为行索引
nrows 读取的时候读取前n行
usecols 指定读取的列 ['info_id','use_id'] 3、excel文件读取info = pd.read_excel('xxxx.xlsx')
print(info)
参数:无数据以NaN填充
sheetname 默认为0 第0个工作表
header 以哪一行作为列名,默认以第0行作为列名
index_col 设置列索引 设置一个列或多个列作为行索引
names 设置列名 接收array 默认为None
parse_cols 读取某些列 ,parse_cols=['info_id'] 3、excel文件读取info = pd.read_excel('xxxx.xlsx')
print(info)
参数:无数据以NaN填充
sheetname 默认为0 第0个工作表
header 以哪一行作为列名,默认以第0行作为列名
index_col 设置列索引 设置一个列或多个列作为行索引
names 设置列名 接收array 默认为None
parse_cols 读取某些列 ,parse_cols=['info_id'] 4、保存数据(对象为df) 4、保存数据(对象为df)有多种方式,这里只演示df.to_excel及pd.to_csv info = pd.to_excel('xxx.xlsx',columns=['detail_id','order_id'],index_label='index_id') print(info) 参数: columns 指定需要保存的列 header 保存列索引 index 保存行索引 index_label 给保存好的excel文件的行索引起个名称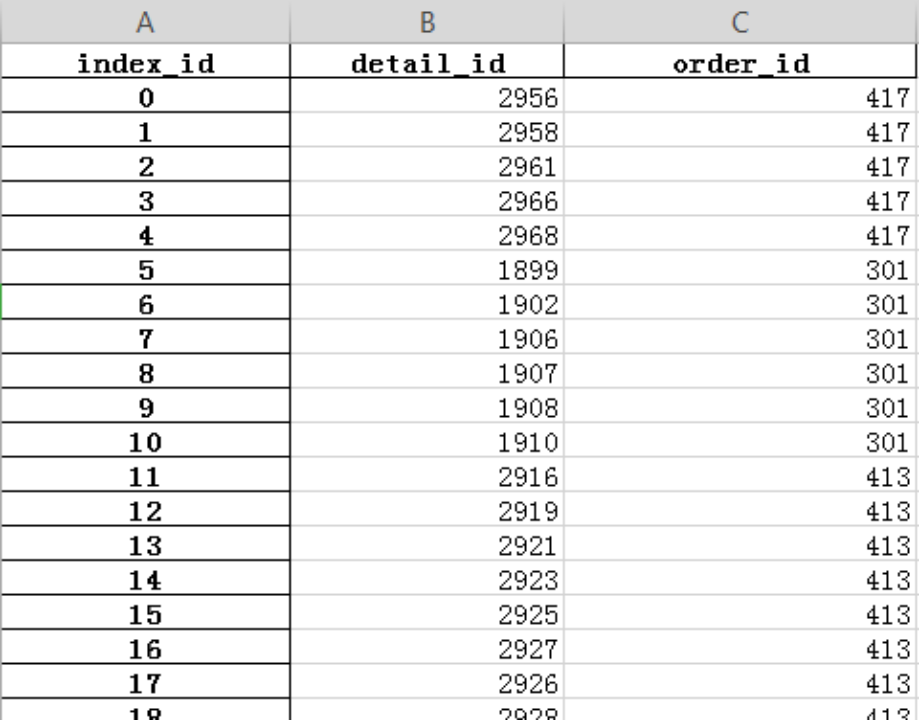 五、df数据索引取值1、加载数据detail = pd.read_excel('xxx_detail.xlsx')2、普通索引获取单列数据 五、df数据索引取值1、加载数据detail = pd.read_excel('xxx_detail.xlsx')2、普通索引获取单列数据pandas获取数据,都是先获取列,再获取行(非同时索引) 数组是同时索引(arr[行,列])  获取单列 之后在获取行数据; 如果是单行,单行的名称或者下标,也可以是名称列表; 如果是多行,多行的名称列表或者下标列表3、普通索引获取多列数据 获取单列 之后在获取行数据; 如果是单行,单行的名称或者下标,也可以是名称列表; 如果是多行,多行的名称列表或者下标列表3、普通索引获取多列数据  获取多列 之后在获取行 如果是单行,直接写名称 如果是多行,需要将多列的名称组成一个列表4、loc iloc索引方式(同时索引) 获取多列 之后在获取行 如果是单行,直接写名称 如果是多行,需要将多列的名称组成一个列表4、loc iloc索引方式(同时索引)使用方法:detail.loc[行名称,列名称] or detail.iloc[行下标,列下标]   5、混合索引(ix) 5、混合索引(ix)ix 混合索引,既可以使用名称也可以使用下标,索引方式同一维度(只能混合,不能混搭) 从效率上讲,ix最慢 如果数据过大不推荐使用  六、df的修改操作1、加载数据 六、df的修改操作1、加载数据 2、定位sex=男的这一列数据,返回bool数组 2、定位sex=男的这一列数据,返回bool数组 3、获取到所有sex=男的所有数据 3、获取到所有sex=男的所有数据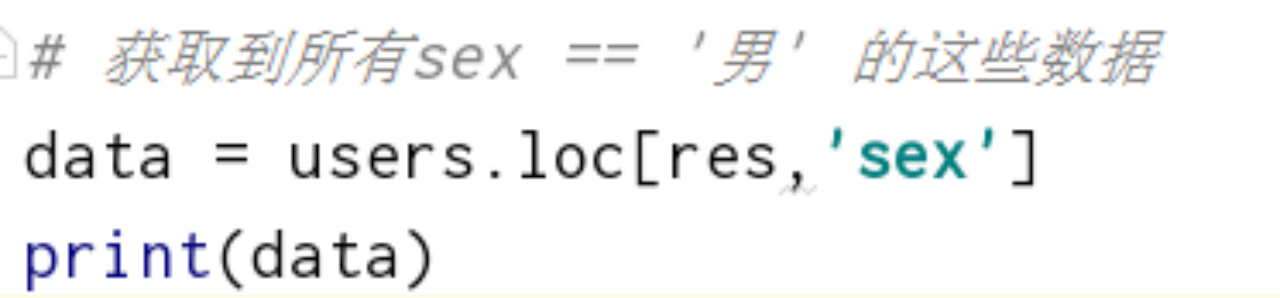 4、重新对获取到的这些数据进行赋值 4、重新对获取到的这些数据进行赋值  5、不加条件的修改(针对所有数据) 5、不加条件的修改(针对所有数据) 简单修改数据:  七、df的增加操作1、加载数据 七、df的增加操作1、加载数据 2、增加一个列,并添加数据 2、增加一个列,并添加数据  八、df的删除操作drop 只能用行或列名称删除,不能用下标参数: labels 列名或行名 inplace=True 对原df产生影响,返回一个None inplace=False 对原df不产生影响,返回一个删除之后的结果1、加载数据2、删除列 八、df的删除操作drop 只能用行或列名称删除,不能用下标参数: labels 列名或行名 inplace=True 对原df产生影响,返回一个None inplace=False 对原df不产生影响,返回一个删除之后的结果1、加载数据2、删除列labels 指定列名,设置axis=1  3、删除行 3、删除行labels 指定行名,设置axis=0(默认)  示例:  九、Pandas的统计分析1、读取数据 九、Pandas的统计分析1、读取数据 2、统计函数 2、统计函数 3、pandas对于非数值型数据的统计分析 3、pandas对于非数值型数据的统计分析  示例1:在detail中哪些菜品最火?菜品卖出了多少份?   白饭不算菜,---把白饭删除,在统计   示例2:在detail中哪个订单点的菜最多,点了多少份菜?   十、Pandas时间数据datetime64[ns]---numpy 里面的时间点类型Timestamp ---pandas 默认的时间点类型--封装了datetime64[ns]DatetimeIndex ---pandas 默认支持的时间序列结构1、通过pd.to_datetime 将时间点数据转化为pandas默认支持的时间点数据 十、Pandas时间数据datetime64[ns]---numpy 里面的时间点类型Timestamp ---pandas 默认的时间点类型--封装了datetime64[ns]DatetimeIndex ---pandas 默认支持的时间序列结构1、通过pd.to_datetime 将时间点数据转化为pandas默认支持的时间点数据  2、通过pd.to_datetime 或者 pd.DatetimeIndex将时间序列转化为pandas默认支持的时间序列结构 2、通过pd.to_datetime 或者 pd.DatetimeIndex将时间序列转化为pandas默认支持的时间序列结构  示例:  获取该时间序列的属性---可以通过列表推导式来获取时间点的属性 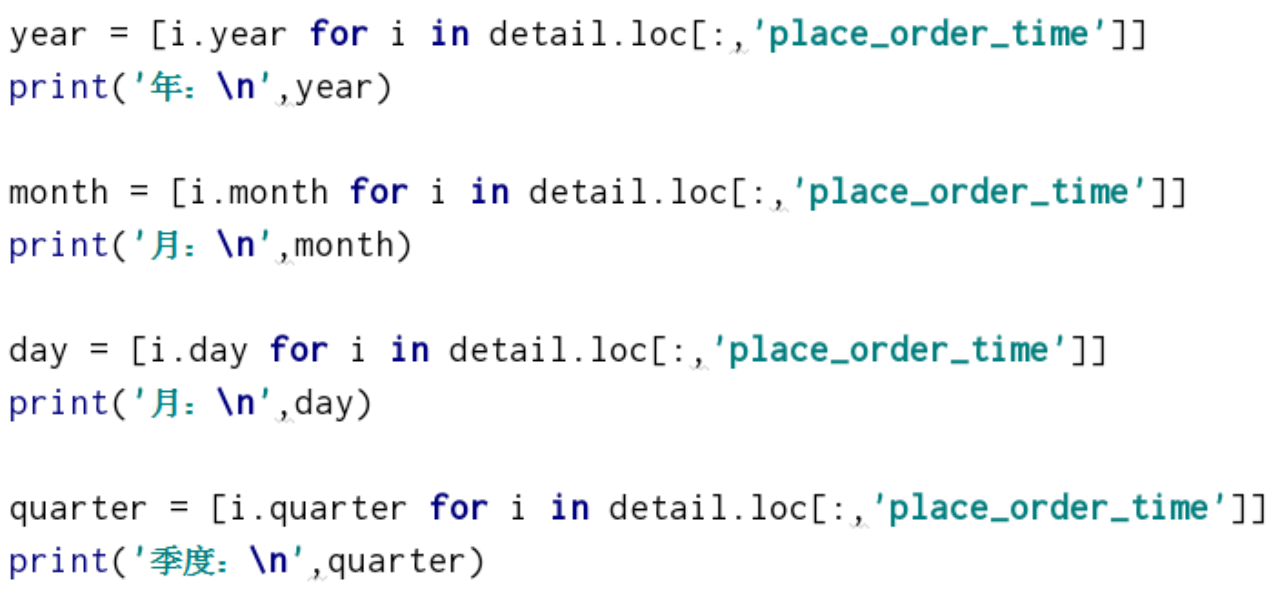 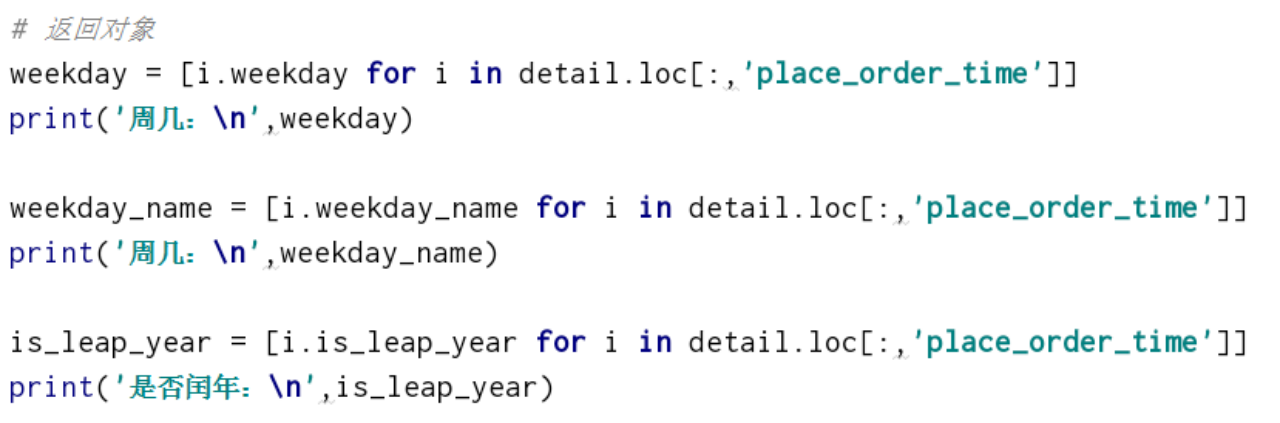 3、时间的相加减 3、时间的相加减 4、时间差距计算 4、时间差距计算 5、获取本机可以使用的初始时间和最后可以使用的时间节点 5、获取本机可以使用的初始时间和最后可以使用的时间节点 十一、Pandas的分组聚合1、读取数据 十一、Pandas的分组聚合1、读取数据 2、根据班级分组,统计学生的平均年龄 2、根据班级分组,统计学生的平均年龄  3、先按照班级分组,在按照地址进行分组,求平均年龄 3、先按照班级分组,在按照地址进行分组,求平均年龄  4、按照单列进行分组,统计多个列的指标 4、按照单列进行分组,统计多个列的指标  5、利用agg,同时对age求平均值,对USRE_ID求最大值 5、利用agg,同时对age求平均值,对USRE_ID求最大值  6、同时对age和USER_ID同时分别求和及均值 6、同时对age和USER_ID同时分别求和及均值  7、对age USER_ID 求取不同个数的统计指标 7、对age USER_ID 求取不同个数的统计指标  8、自定义函数进行计算 8、自定义函数进行计算  9、销售额计算(以每日分组计算每天的销售额)import pandas as pd
# detail 有时间数据
detail = pd.read_excel('meal_order_detail.xlsx')
print('detail:\n',detail)
print('detail的列索引名称:\n',detail.columns)
print('detail的形状:\n',detail.shape)
print('detail的列数据类型:\n',detail.dtypes)
# 计算每个彩品的销售额,增加到detail中
detail.loc[:,'pay'] = detail.loc[:,'counts'] * detail.loc[:,'amounts']
print(detail)
# 获取时间点的日属性
# 必须pandas默认支持的时间序列类型
detail.loc[:,'place_order_time'] = pd.to_datetime(detail.loc[:,'place_order_time'])
# 以列表推导式获取日属性
detail.loc[:,'day'] = [i.day for i in detail.loc[:,'place_order_time']]
print(detail)
# 以日分组
res = detail.groupby(by='day')['pay'].sum()
print(res)十二、Pandas透视表与交叉表1、加载数据 9、销售额计算(以每日分组计算每天的销售额)import pandas as pd
# detail 有时间数据
detail = pd.read_excel('meal_order_detail.xlsx')
print('detail:\n',detail)
print('detail的列索引名称:\n',detail.columns)
print('detail的形状:\n',detail.shape)
print('detail的列数据类型:\n',detail.dtypes)
# 计算每个彩品的销售额,增加到detail中
detail.loc[:,'pay'] = detail.loc[:,'counts'] * detail.loc[:,'amounts']
print(detail)
# 获取时间点的日属性
# 必须pandas默认支持的时间序列类型
detail.loc[:,'place_order_time'] = pd.to_datetime(detail.loc[:,'place_order_time'])
# 以列表推导式获取日属性
detail.loc[:,'day'] = [i.day for i in detail.loc[:,'place_order_time']]
print(detail)
# 以日分组
res = detail.groupby(by='day')['pay'].sum()
print(res)十二、Pandas透视表与交叉表1、加载数据 2、透视表创建透视表 是一种plus版的分组聚合
创建一个透视表
参数:
data dataframe数据
values 最终统计指标所针对对象,要关心的数据主体
index 按照index进行 行分组
columns 按照columns进行 列分组
aggfunc 对主体 进行什么指标的统计
res = pd.pivot_table(data=detail[['amounts','order_id','counts']],values='amounts',index='order_id',columns='counts',aggfunc='mean')
# res = pd.pivot_table(data=detail[['amounts','order_id','counts','dishes_name','day']],values='amounts',index=['order_id','dishes_name'],columns=['counts','day'],aggfunc='mean')
print(res)
res.to_excel('hh.xlsx') 2、透视表创建透视表 是一种plus版的分组聚合
创建一个透视表
参数:
data dataframe数据
values 最终统计指标所针对对象,要关心的数据主体
index 按照index进行 行分组
columns 按照columns进行 列分组
aggfunc 对主体 进行什么指标的统计
res = pd.pivot_table(data=detail[['amounts','order_id','counts']],values='amounts',index='order_id',columns='counts',aggfunc='mean')
# res = pd.pivot_table(data=detail[['amounts','order_id','counts','dishes_name','day']],values='amounts',index=['order_id','dishes_name'],columns=['counts','day'],aggfunc='mean')
print(res)
res.to_excel('hh.xlsx')  3、交叉表 mini版的透视表 3、交叉表 mini版的透视表   十三、Pandas数据去重与相关性衡量1、加载数据 十三、Pandas数据去重与相关性衡量1、加载数据 2、对指定数据去重参数:
subset---指定要去重的数据
只有同列才能进行去重 2、对指定数据去重参数:
subset---指定要去重的数据
只有同列才能进行去重 3、数据相关性衡量 3、数据相关性衡量  十四、DataFrame数据拼接1、加载数据 十四、DataFrame数据拼接1、加载数据 2、concat方式基于行方向连接outer 代表外链接 在行的方向上,直接拼接;列的方向上求列的并集 2、concat方式基于行方向连接outer 代表外链接 在行的方向上,直接拼接;列的方向上求列的并集  inner 代表内链接 在行的方向上,直接拼接;列的方向上求列的交集 inner 代表内链接 在行的方向上,直接拼接;列的方向上求列的交集  3、concat方式基于列方向连接outer 代表外链接 在列的方向上,直接拼接;行的方向上求行的并集 3、concat方式基于列方向连接outer 代表外链接 在列的方向上,直接拼接;行的方向上求行的并集  inner 代表内链接 在列的方向上,直接拼接;行的方向上求行的交集 inner 代表内链接 在列的方向上,直接拼接;行的方向上求行的交集  4、merge方式连接outer 外连接,key值的列,求并集,没有值的 用NaN填充 4、merge方式连接outer 外连接,key值的列,求并集,没有值的 用NaN填充  inner 内连接,,key值的列,求交集,没有值的 用NaN填充 inner 内连接,,key值的列,求交集,没有值的 用NaN填充  left 左外连接,,key值的列,以左表为主 left 左外连接,,key值的列,以左表为主  right 右外连接,,key值的列,以右表为主 right 右外连接,,key值的列,以右表为主  左表的列的名称与右表的列的名称 不一样 但里面的数据是一样的 左表的列的名称与右表的列的名称 不一样 但里面的数据是一样的  十五、DataFrame数据填充 十五、DataFrame数据填充  十六、缺失值处理1、缺失值检测 十六、缺失值处理1、缺失值检测  2、删除法处理缺失值对于删除法,容易改变数据结构,容易造成大量数据丢失;只有行或列大部分为缺失值,我们才进行删除或者 行、列的数据对结果不重要 才进行删除 2、删除法处理缺失值对于删除法,容易改变数据结构,容易造成大量数据丢失;只有行或列大部分为缺失值,我们才进行删除或者 行、列的数据对结果不重要 才进行删除  3、填充法处理缺失值对于数值型数据---可以使用均值、中位数、众数来填充 对于类别型数据---可以使用众数来填充 3、填充法处理缺失值对于数值型数据---可以使用均值、中位数、众数来填充 对于类别型数据---可以使用众数来填充     4、插值法处理缺失值对于线性关系的数据---线性插值比较准确,多项式插值和样条插值都不错如果是线性关系的数据---都可以使用 4、插值法处理缺失值对于线性关系的数据---线性插值比较准确,多项式插值和样条插值都不错如果是线性关系的数据---都可以使用对于非线性数据---线性插值效果较差,多项式插值和样条插值效果较好如果是非线性关系的数据---推荐使用多项式插值或样条插值 线性插值:  多项式插值:  样条插值:  十七、异常值处理import pandas as pd
# 根据正态分布得出 99.73%的数据都在[u-3sigma,u+sigma]之间,那么我们认为超出这个区间的数据为异常值
# [μ-3σ]
# 剔除异常值---保留数据在[u-3sigma,u+3sigma]
def three_sigma(data):
"""
进行3 sigma异常值剔除
:param data: 传入的数据
:return: 剔除之后的数据,或者剔除异常值之后的行索引名称
"""
# bool_num = ((data.mean() - 3 * data.std()) = data)
bool_id_1 = ((data.mean() - 3 * data.std()) = data)
# 位与运算
bool_num = bool_id_1 & bool_id_2
# return data.loc[bool_num,:]
return bool_num
# 以detail为例 展示以amounts进行异常值剔除,查看detail结果
# 加载数据
detail = pd.read_excel('meal_order_detail.xlsx',sheetname=0)
print('detail:\n',detail)
print('detail的列名:\n',detail.columns)
# 调用函数进行detail中amounts的异常值剔除
# detail = three_sigma(detail)
bool_num = three_sigma(detail.loc[:,'amounts'])
# 获取正常的detail
detail = detail.loc[bool_num,:]
print(detail.shape)箱线图异常处理:import pandas as pd
import numpy as np
# 箱线图分析
arr = pd.DataFrame(np.array([1,2,3,4,5,6,7,8,9,100]))
print(arr.quantile(0.1))
# 75% 的数 qu
# 25% 的数 ql
# iqr = qu - ql
# 上限:qu + 1.5 * iqr
# 下限:ql - 1.5 * iqr
def box_analysis(data):
"""
进行箱线图分析,剔除异常值
:param data: series
:return: bool数组
"""
qu = data.quantile(0.75)
ql = data.quantile(0.25)
iqr = qu - ql
# 上限
up = qu + 1.5 * iqr
# 下限
low = ql - 1.5 * iqr
# 进行比较运算
bool_id_1 = data = low
bool_num = bool_id_1 & bool_id_2
return bool_num
# 加载数据
detail = pd.read_excel('meal_order_detail.xlsx',sheetname=0)
bool_num = box_analysis(detail.loc[:,'amounts'])
detail = detail.loc[bool_num,:]
print(detail.shape)
# quantile 参数为[0,1]的小数---返回分位数,series类型
# percentile 参数为[0,100]的整数---返回分位数的列表十八、标准化数据 十七、异常值处理import pandas as pd
# 根据正态分布得出 99.73%的数据都在[u-3sigma,u+sigma]之间,那么我们认为超出这个区间的数据为异常值
# [μ-3σ]
# 剔除异常值---保留数据在[u-3sigma,u+3sigma]
def three_sigma(data):
"""
进行3 sigma异常值剔除
:param data: 传入的数据
:return: 剔除之后的数据,或者剔除异常值之后的行索引名称
"""
# bool_num = ((data.mean() - 3 * data.std()) = data)
bool_id_1 = ((data.mean() - 3 * data.std()) = data)
# 位与运算
bool_num = bool_id_1 & bool_id_2
# return data.loc[bool_num,:]
return bool_num
# 以detail为例 展示以amounts进行异常值剔除,查看detail结果
# 加载数据
detail = pd.read_excel('meal_order_detail.xlsx',sheetname=0)
print('detail:\n',detail)
print('detail的列名:\n',detail.columns)
# 调用函数进行detail中amounts的异常值剔除
# detail = three_sigma(detail)
bool_num = three_sigma(detail.loc[:,'amounts'])
# 获取正常的detail
detail = detail.loc[bool_num,:]
print(detail.shape)箱线图异常处理:import pandas as pd
import numpy as np
# 箱线图分析
arr = pd.DataFrame(np.array([1,2,3,4,5,6,7,8,9,100]))
print(arr.quantile(0.1))
# 75% 的数 qu
# 25% 的数 ql
# iqr = qu - ql
# 上限:qu + 1.5 * iqr
# 下限:ql - 1.5 * iqr
def box_analysis(data):
"""
进行箱线图分析,剔除异常值
:param data: series
:return: bool数组
"""
qu = data.quantile(0.75)
ql = data.quantile(0.25)
iqr = qu - ql
# 上限
up = qu + 1.5 * iqr
# 下限
low = ql - 1.5 * iqr
# 进行比较运算
bool_id_1 = data = low
bool_num = bool_id_1 & bool_id_2
return bool_num
# 加载数据
detail = pd.read_excel('meal_order_detail.xlsx',sheetname=0)
bool_num = box_analysis(detail.loc[:,'amounts'])
detail = detail.loc[bool_num,:]
print(detail.shape)
# quantile 参数为[0,1]的小数---返回分位数,series类型
# percentile 参数为[0,100]的整数---返回分位数的列表十八、标准化数据标准化数据的目的:将数据转化为同一量级,避免量级对结果产生不利的影响,消除量高影响 三种方式: 1、离差标准化---(x - min)/(max - min)将数据转化为[0,1]之间去 def min_max_sca(data): """ 离差标准化 :param data:传入的数据 :return: 标准化之后的数据 """ data = (data - data.min()) / (data.max() - data.min()) return data # 离差标准化容易受到异常点影响2、标准差标准化---(x - mean)/std# 转化完成的数据---将数据转化到标准差为1,均值为0的一种状态 def stand_sca(data): """ 标准差标准化数据 :param data: 传入的数据 :return: 标准化之后的数据 """ data = (data - data.mean()) / data.std() return data # 对异常值不敏感(出场率--使用比较高)3、小数定标标准化---x/10^k# k---k=log10(|x|.max())在向上取整 # 通过移动数据的小数点来使得数据转化到[-1,1]之间 import numpy as np def desc_sca(data): """ 小数定标标准化 :param data:传入的数据 :return: 标准化之后的数据 """ data = data / (10 ** np.ceil(np.log10(data.abs().max()))) return data4、三种标准化数据函数应用# 加载数据 detail = pd.read_excel('meal_order_detail.xlsx') # print(detail) print(detail.loc[:,'amounts'].max()) print(detail.loc[:,'amounts'].min()) # 标准化数据 # 离差标准化(基本不用) res = min_max_sca(detail.loc[:,'amounts']) # 标准差标准化 res = stand_sca(detail.loc[:,'amounts']) # 小数定标标准化 res = desc_sca(detail.loc[:,'amounts']) print(res)十九、数据离散化1、将类别型数据 转化为 哑变量矩阵数据分析模型中有相当一部分的算法模型都要求输入的特征为数值型,但实际数据中特征的类型不一定只有数值型,还会存在相当一部分的类别型,这部分的特征需要经过哑变量处理才可以放入模型之中。 类别型数据转化为数据值数据   2、将连续型数据进行离散化---进行分组,将具体的值转化为区间数据 2、将连续型数据进行离散化---进行分组,将具体的值转化为区间数据  等宽分组(可以发现等宽分组时分布不均) 等宽分组(可以发现等宽分组时分布不均)  等频分组(等频分组数据分组比较均匀) 等频分组(等频分组数据分组比较均匀)   将连续型数据再次转化为哑变量矩阵# # 将连续型数据转为哑变量
print(pd.get_dummies(res,prefix='区间',prefix_sep=':')) 将连续型数据再次转化为哑变量矩阵# # 将连续型数据转为哑变量
print(pd.get_dummies(res,prefix='区间',prefix_sep=':'))
|
【本文地址】
今日新闻 |
推荐新闻 |