ChatGPT训练算力估算:1万块A100 GPU是误传,中小创企也可突围(收录于GPT |
您所在的位置:网站首页 › p600算力 › ChatGPT训练算力估算:1万块A100 GPU是误传,中小创企也可突围(收录于GPT |
ChatGPT训练算力估算:1万块A100 GPU是误传,中小创企也可突围(收录于GPT
|
陈巍谈芯:我们经过测算,按照OpenAI训练集群的规模进行线性估算,甚至可以用22台8卡服务器进行ChatGPT-6B的训练。大概1-4周完成一次模型训练。中小企业一样能进入ChatGPT模型领域。 标准大小的ChatGPT-175B大概需要375-625台8卡A100服务器进行训练。如果愿意等1个月的话,150-200台8卡也是够的。每次训练总的GPU资源消耗量是35000卡天。 我们用几个不同方式来验证ChatGPT训练的资源需求: 1 根据Azura超算资源上限测算在Azure为OpenAI准备的训练研发平台上,CPU与GPU的数量比接近1:2。GPU为1万块V100,而不是国内误传的A100.(在2020年初建好openai超算的时候,A100还未批量上市)  考虑到这一超算同时还要做DALL E 2等模型的训练,同步在跑的还有GPT-4的训练,因此GPU的占用率不会达到100%。如果换算到A100,GPU资源需求量是3000-5000块(一次训练耗时两周)。 2 根据NVIDIA paper上的信息测算在NVIDIA联合发布的paper中,给出了训练时间的经验公式。并使用训练的并行技术将GPU算力利用率提升到52%。在这一paper中,训练175B GPT-3需要34天,使用了1024块A100 GPU。这一推测与上个测算基本一致。 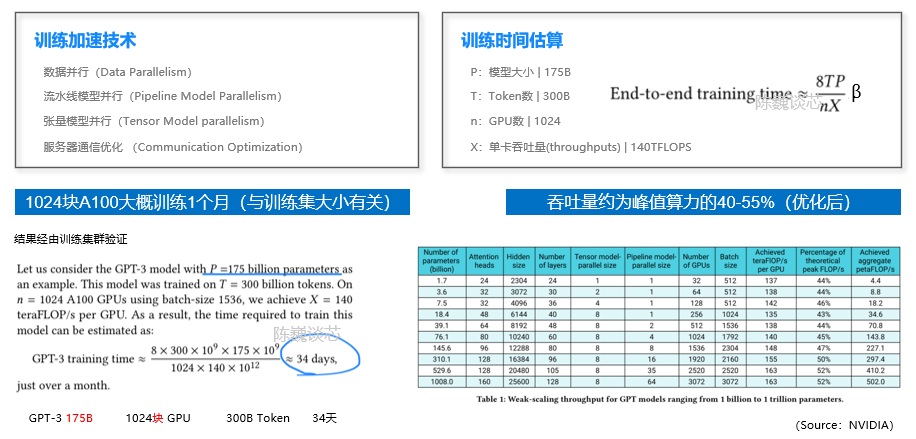 3 根据Google paper信息侧面佐证 3 根据Google paper信息侧面佐证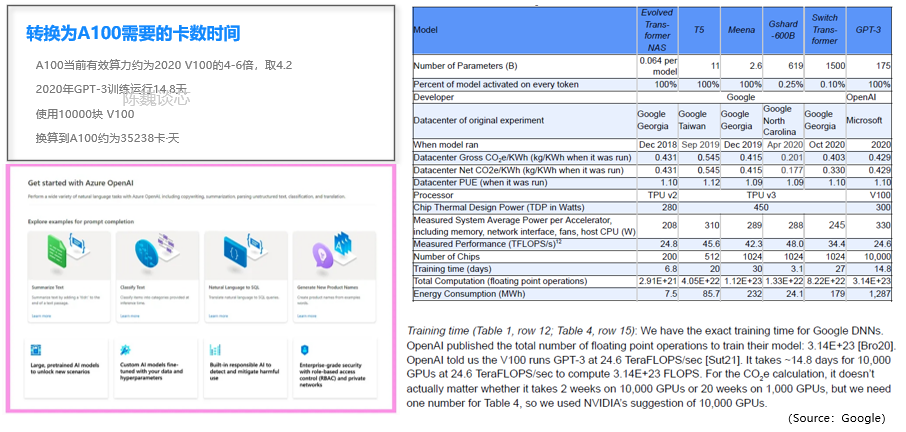 根据Google发表在2年前的paper,当时大概需要1万块v100跑2周。考虑到A100的算力进步和有效算力使用率提升,大概需要使用35238卡天(A100)。 4 其他考量与建议1)另外有些并行训练方法,以及使用FP16或TF16,可以明显降低GPU数量要求。但上面估算并未把这些优化技巧累加进去。 2)实际的算力需求与测算规模应是非线性的。但一般情况下规模越大,算力利用率越低。本测算从高推低,可覆盖小规模情况的成本。 3)如果是创业企业,建议考虑6B这个模型,大概只需要22台8卡GPU服务器。硬件购置成本相当于大概1-2年云服务训练成本。如果未来使用存算一体技术的训练卡,大概只用1-4台就够了。而且,根据OpenAI的论文,ChatGPT/InstructGPT-1.3B的效果都是好于GPT-3 175B的。未来ChatGPT的算力私有化不是问题。  ChatGPT/InstructGPT-1.3B的效果都好于GPT-3 175B(Source:OpenAI) ChatGPT/InstructGPT-1.3B的效果都好于GPT-3 175B(Source:OpenAI)测算依据是OpenAI训练集群的实际参数和GPT-3的并行训练结果。 除了GPU之外,DSA和存算一体也是能有效提升算力降低成本的技术。  不同服务器架构方案对比 不同服务器架构方案对比有专业的朋友建议考虑上线后的请求量和保证qps问题。得说明下本篇主要讨论训练成本而不是部署。实际的部署,与访问量和冗余设计架构有很大关系,就留给各互联网公司自己看吧。另外按照OpenAI创始人(官方)给出的数据,运行成本大概每次回答1美分,这个再细算意义不大。 话说ChatGPT这个领域,我比较看好中小公司,更能坐冷板凳,更能破釜沉舟背水一战。 像OpenAI创始人那种人,在大公司里往往不太合群。 ----------正文结束---------另外附小八卦一个另外有网友认为我写的这个估算不对,提供了另一个参照。我们来对比一下本文和经济账(参照文)的测算情况。  网友看法 网友看法1)第一,这篇参照文以TPUv4成本作为基础参考,而不是GPU。 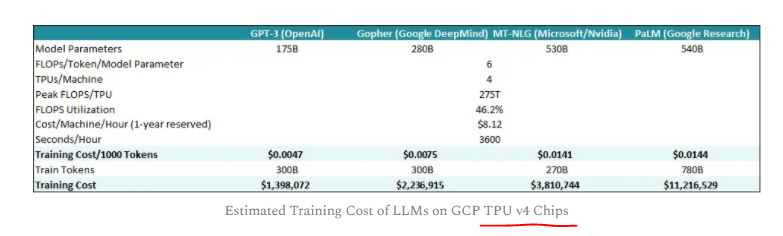 Sunyan经济帐文章中的表格 Sunyan经济帐文章中的表格网上被大量市场研究机构所引用的139.8万美元的训练成本居然是基于TPUv4的云服务成本。但是按照Google的信息,同样训练规模下,TPU成本大概只有同时期GPU的1/5~1/4。Google在TPUv4上具有自产自销的优势,而ChatGPT独家授权的Azura云却要从英伟达那里买GPU。所以这个成本的依据可能是不适合大部分非Google客户的。另外国内大部分人也是用的国内云。 2)第二,这篇参照文引用的成本数据来自2020,咱们现在已经2023年了,硬件成本大概每18个月降低一半(摩尔定律)  Sunyan经济帐文章中的表格 Sunyan经济帐文章中的表格上面这表的一些数据来自于2021年上半年发表的一篇论文(下图表格),里面的2020年的测量算力仅为24.6TFLOPS(算力利用率约22%),跟实际上V100在2023年训练中的有效算力应该能到大概标称值的40-50%)  3)第三,这篇文章如果换算到2023,跟我对卡数的估算相当。 4)最后,这个参照文的作者是一位投资人(Technology Investor at Tudor Investment),OneFlow团队辛勤翻译了他在Substack的文章(The Economics of Large Language Models),并在分享时非常严谨的注明了翻译自该作者文章。所以这个计算依据的锅也不是OneFlow的。从几个2020年的标记来看,参照文的作者也是引用了某paper里2020年的数据,但这位投资人搬运数据的时候,表格里却没有做2020->2023年和TPU->GPU成本变更的调整。 (OneFlow在AI领域非常专业,也是作者合作方) |
【本文地址】