orcl数据库查询重复数据及删除重复数据方法 |
您所在的位置:网站首页 › orcl删除重复数据 › orcl数据库查询重复数据及删除重复数据方法 |
orcl数据库查询重复数据及删除重复数据方法
|
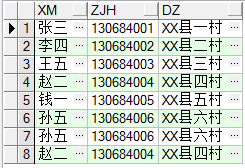
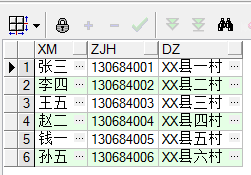
工作中,发现数据库表中有许多重复的数据,而这个时候老板需要统计表中有多少条数据时(不包含重复数据),只想说一句MMP,库中好几十万数据,肿么办,无奈只能自己在网上找语句,最终成功解救,下面是我一个实验,很好理解。 ------------------------------------------------------------------------------------------------------------------------ 假设有一张人员信息表cs(姓名,证件号,地址),将表中三个字段数据都重复的数据筛选出来:
distinct:这个关键字来过滤掉多余的重复数据只保留一条数据 select * from from cs ------所有字段 select distinct xm,zjh,dz from cs; -----指定字段
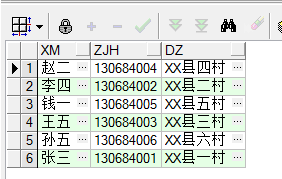
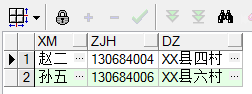
在实践中往往只用它来返回不重复数据的条数,因为distinct对于一个数据量非常大的库来说,无疑是会直接影响到效率的。 ----------------------------------------------------------------------------------------------------------------------- 查询重复数据、删除重复数据的方法如下:↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ①rowid用法: oracle带的rowid属性,进行判断是否存在重复数据。 查询重复数据: select a.* from cs a where rowid !=(select max(rowid) from cs b where a.xm=b.xm and a.zjh=b.zjh and a.dz=b.dz)
删除重复数据: delete from cs a where rowid !=(select max(rowid) from cs b where a.xm=b.xm and a.zjh=b.zjh and a.dz=b.dz)
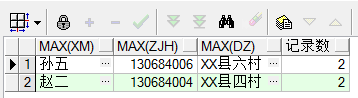
②group by :一般用于将查询结果分组,多配合聚合函数,sum,count,min,max,having等一起使用。 查询重复数据: select max(xm),max(zjh),max(dz),count(xm) as 记录数 from cs group by xm having count(xm)>1 ---------适用于字段少的
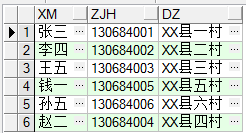
select * from cs a where (a.xm,a.zjh,a.dz) in (select xm,zjh,dz from cs group by xm,zjh,dz having count(*)>1) and rowid not in (select min(rowid) from cs group by xm,zjh,dz having count(*)>1) -------适用于多字段
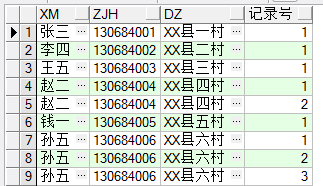
去重重复数据:多个字段,只留有rowid最小的记录 。 delete from cs a where (a.xm,a.zjh,a.dz) in (select xm,zjh,dz from cs group by xm,zjh,dz having count(*)>1) and rowid not in (select min(rowid) from cs group by xm,zjh,dz having count(*)>1) ③row_number()over(partition by 列) select xm,zjh,dz,row_number()over(partition by zjh order by xm) 记录号 from cs
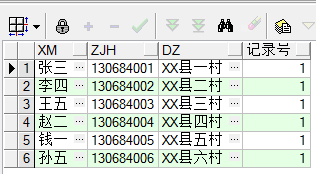
去重重复数据: with cs1 as (select xm,zjh,dz,row_number()over(partition by zjh order by zjh) 记录号 from cs)select * from cs1 where 记录号=1
感谢您的阅读,如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮。本文欢迎各位转载,但是转载文章之后必须在文章页面中给出作者和原文连接。 |

【本文地址】
今日新闻 |
推荐新闻 |