oracle和hive之间关于sql的语法差异及转换 |
您所在的位置:网站首页 › oracle与mysql的sql语句区别 › oracle和hive之间关于sql的语法差异及转换 |
oracle和hive之间关于sql的语法差异及转换
|
1. oracle的(+) 改为hive左右连接
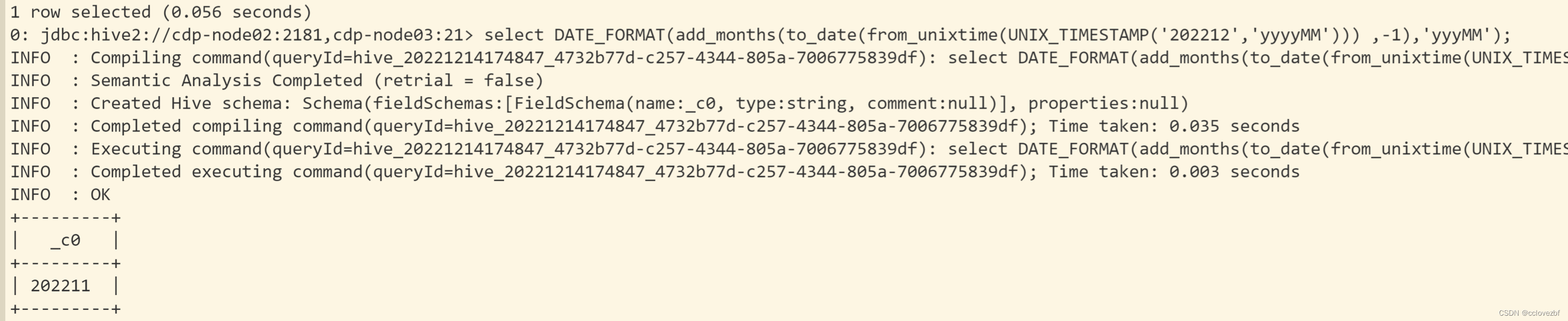
oracle (+)学习_cclovezbf的博客-CSDN博客最近工作需要将oracle的存储过程转化为hive的sql脚本。遇到很多不一样的地方,例如oracle连接中有(+)号的用法。借鉴这篇文章,但是这个排版比较烂。。。先建表和插入数据首先说明(+)代表什么?代表这一侧的数据可以为空!a.id=b.id(+) 代表b表和a表关联的时候以a表作为主表。 例如select a.id, (select b.id from b where b.name=a.id) from a hive 是不支持select 里面子查询的。 修改如下 select a.id ,b.id from a left join b on a.id=b.name 3.oracle的decode函数decode('key',if1,then1 ,if2,then2...thenN) 一般来说可以改为case key when if1 then then1 when if2 then then2 else thenN 但是如果decode比较简单 可以直接改为 if('key'=if1,then1,then2) 复杂的改为case when 。特别注意hive有个decode函数是编码函数 4.oracle的时间转化例如某字符串yyyyMM获取上个月时间 oracle select to_char(add_months(to_date('202202','yyyymm'),-1),'yyyymm') from dual hive select date_format(add_months(to_date(from_unixtime(unix_timestamp('202212','yyyyMM'))) ,-1),'yyyMM'); 其实可以简化 select add_months(from_unixtime(unix_timestamp('202212','yyyyMM')),-1,'yyyMM');
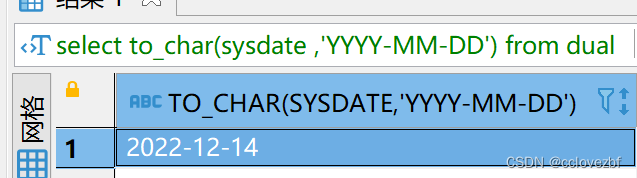
select to_char(sysdate ,'YYYY-MM-DD') from dual
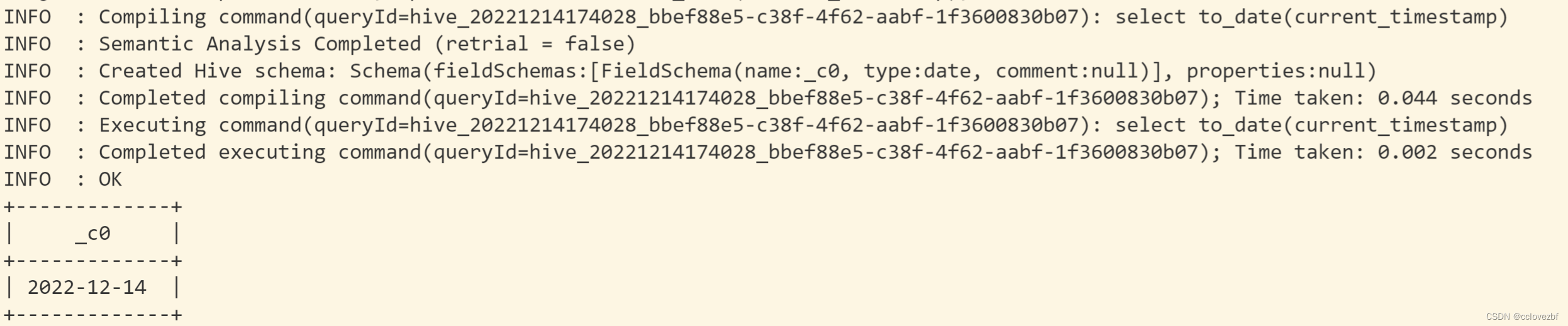
hive的 select to_date(current_timestamp); --这里返回值是date!!!!
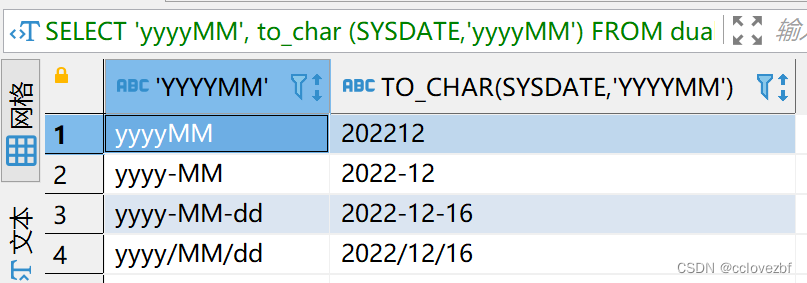
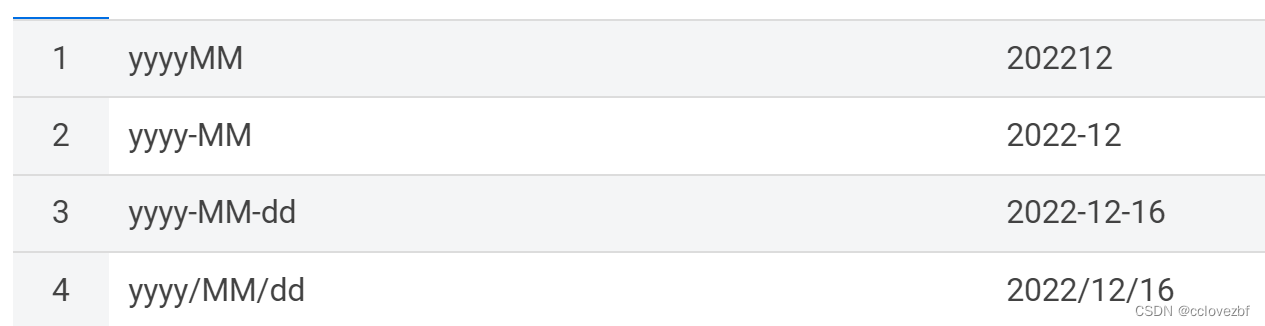
如果hive要转化为其他格式 可以用date_format(current_date,'yyyy-MM-dd HH:mm:ss') 这里要注意oracle对格式要求比较严格,hive则不需要特别严格。 我们这边为了图方便把hive的日期格式都拿string去存,所以会有些些出入 例如oracle SELECT 'yyyyMM', to_char (SYSDATE,'yyyyMM') FROM dual UNION ALL SELECT 'yyyy-MM', to_char (SYSDATE,'yyyy-MM') FROM dual UNION ALL SELECT 'yyyy-MM-dd', to_char (SYSDATE,'yyyy-MM-dd') FROM dual UNION ALL SELECT 'yyyy/MM/dd', to_char (SYSDATE,'yyyy/MM/dd') FROM dual oracle的to_char 函数非常方便只要你的入参1是日期类型 就可以想要什么格式要什么格式
如果我们hive存的是日期格式也还好 hive的date类型格式化 SELECT 'yyyyMM', date_format (current_date(),'yyyyMM') UNION ALL SELECT 'yyyy-MM', date_format (current_date,'yyyy-MM') UNION ALL SELECT 'yyyy-MM-dd', date_format (current_date,'yyyy-MM-dd') UNION ALL SELECT 'yyyy/MM/dd', date_format (current_date,'yyyy/MM/dd')
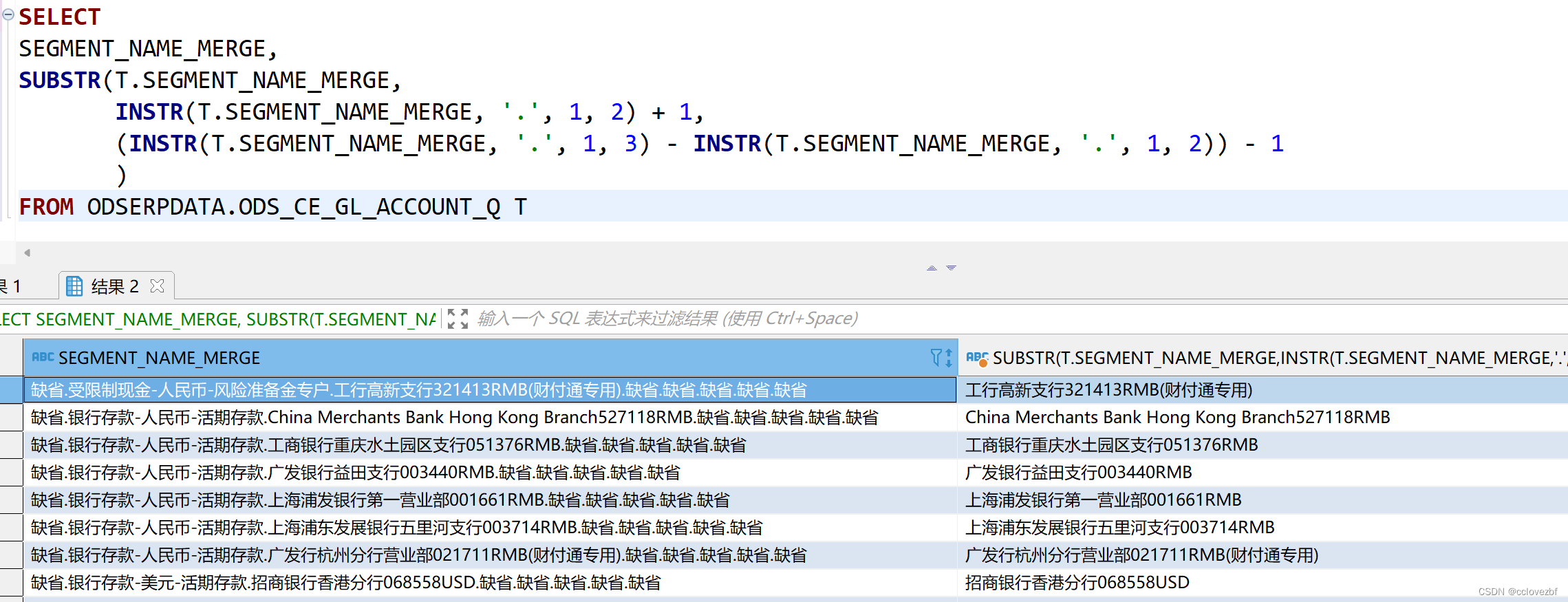
hive的string 类型格式。 如果你存标准日期格式例如 2022-12-13 14:15:16 可以直接按照上面写。 但是如果你存的是20221213 2022/12/13这种格式。(当然你可以substring+ concat("-")拼)。 说点其他的。 可以通过如下方法格式,我们只需要修改format对应hive表里用string存储的日期格式即可 select from_unixtime(UNIX_TIMESTAMP('20200102','yyyyMMdd')--2020-01-02 00:00:00 select to_date(from_unixtime(UNIX_TIMESTAMP('20200102','yyyyMMdd'))) -- 2020-01-02 说个简单且经常遇到的的转化 oracle ->TO_CHAR(TO_DATE(REPLACE(ADJ.VAR1, '-',''), 'YYYYMMDD'), 'yyyy') hive -> from_unixtime(UNIX_TIMESTAMP(REPLACE(ADJ.VAR1, '-',''), 'YYYYMMDD'), 'yyyy') 6.oracle的trunc函数https://blog.csdn.net/cclovezbf/article/details/128326389 参考文章 Oracle中的instr()函数 详解及应用_Java&Develop的博客-CSDN博客_oracle中instr SELECT instr('1234567890123456789','3') FROM dual -- 3 SELECT instr('1234567890123456789','3',1) FROM dual -- 3 ,从第1位开始查找第一个3 SELECT instr('1234567890123456789','3',1,2) FROM dual --13 从第1位开始查找第二个3 SELECT instr('1234567890123456789','3',4) FROM dual -- 13 从第4位开始查找第一个3 SELECT instr('1234567890123456789','3',4,1) FROM dual --13 从第4位开始查找第一个3 SELECT instr('1234567890123456789','3',4,2) FROM dual --0 从第4位开始查找第二个3 select instr('被查找的字符串','我们需要查找的字符',从第几位开始 首位是0,查找第几个出现的) 注意这里返回的下标是从1开始的。 接着我们来看下hive的函数 有几个类似的 instr instr(str, substr) - Returns the index of the first occurance of substr in str SELECT instr('1234567890123456789','3') -- 3 没问题 但是这个功能比较简单,远没有oracle的强大,不过也凑合用了。 hive-locate函数 select locate('3','12345123',4) --8 select locate('3','12345123',1) --3 -- 这个locate函数也是找到字符串的下标 locate('要找的字符','被找的字符串',' 从下标多少开始找')。 说实话 感觉这个函数也没有oracle instr的函数好用,因为 instr(str,substr, count) 可以找第几次出现 对于 xx.xx.xx 和x.x.x 这种格式的数据特别好用 说个遇到的案例 oracle中 需要截取某个字段 SELECT SEGMENT_NAME_MERGE, SUBSTR(T.SEGMENT_NAME_MERGE, INSTR(T.SEGMENT_NAME_MERGE, '.', 1, 2) + 1, (INSTR(T.SEGMENT_NAME_MERGE, '.', 1, 3) - INSTR(T.SEGMENT_NAME_MERGE, '.', 1, 2)) - 1 ) FROM ODSERPDATA.ODS_CE_GL_ACCOUNT_Q T
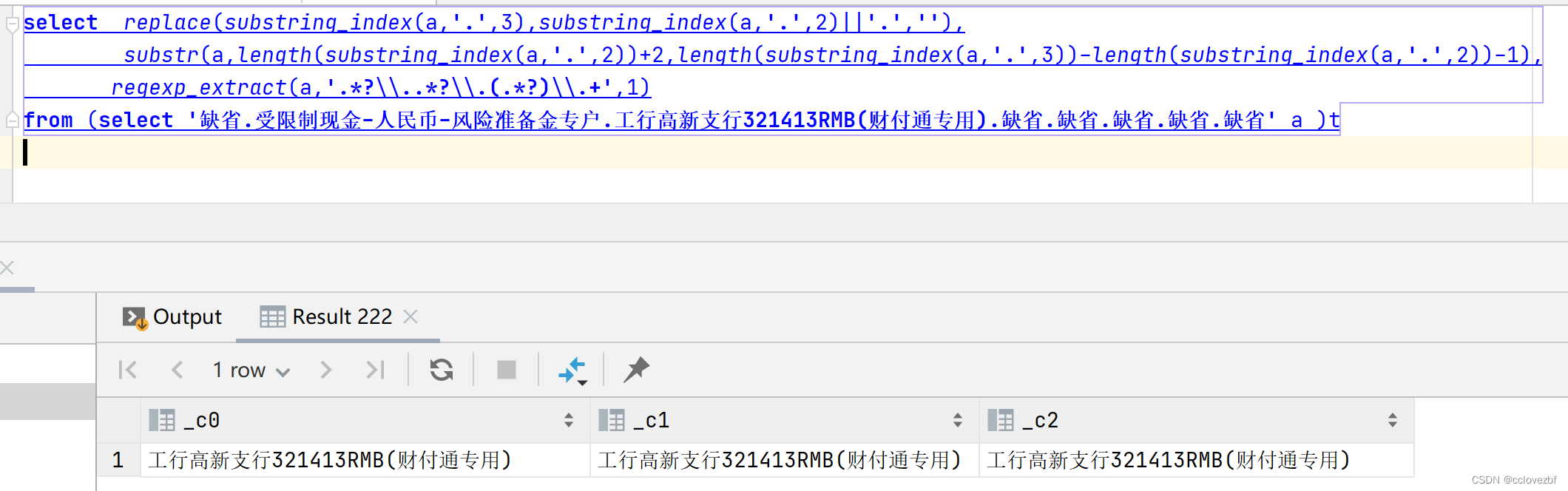
字段格式是: xx1.xxxxx2.xx3.xxx4.xx5.xx6 我们需要xx3格式的数据 缺省.受限制现金-人民币-风险准备金专户.工行高新支行321413RMB(财付通专用).缺省.缺省.缺省.缺省.缺省 -> 工行高新支行321413RMB(财付通专用) 之前的人采用了substring('字符串',第二个.字符的下标+1, (第三个. - 第二个.的长度 + 1))。 现在我们要在hive中也截取成这样。 我们能一样采用instr +substr吗? 不能!!! 因为hive的instr只能定位到第一个. 那我们怎么办? 这里我们可以使用substring_index 或regexp_extract select replace(substring_index(a,'.',3),substring_index(a,'.',2)||'.',''), substr(a,length(substring_index(a,'.',2))+2,length(substring_index(a,'.',3))-length(substring_index(a,'.',2))-1), regexp_extract(a,'.*?\\..*?\\.(.*?)\\.+',1) from (select '缺省.受限制现金-人民币-风险准备金专户.工行高新支行321413RMB(财付通专用).缺省.缺省.缺省.缺省.缺省' a )t 上面是三种办法。 1.是替换 2.是截取 3是正则
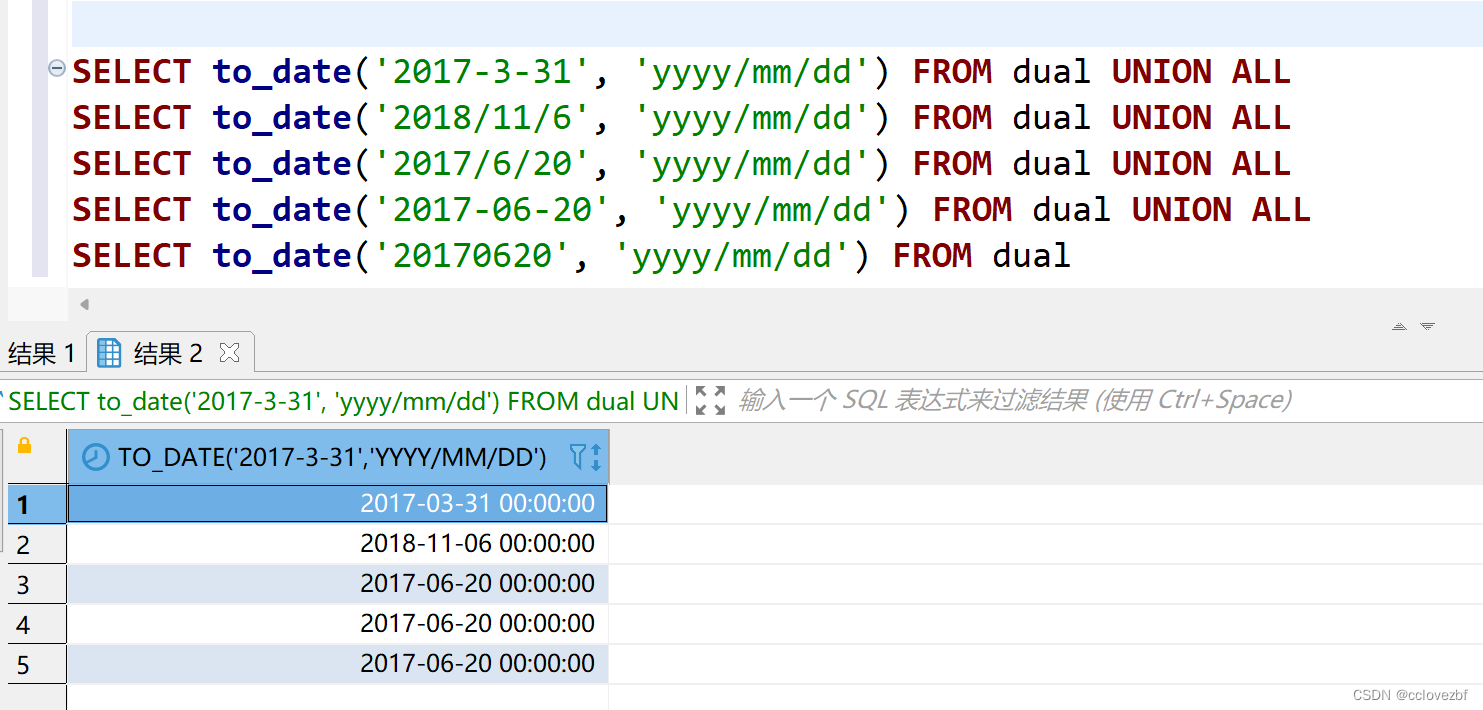
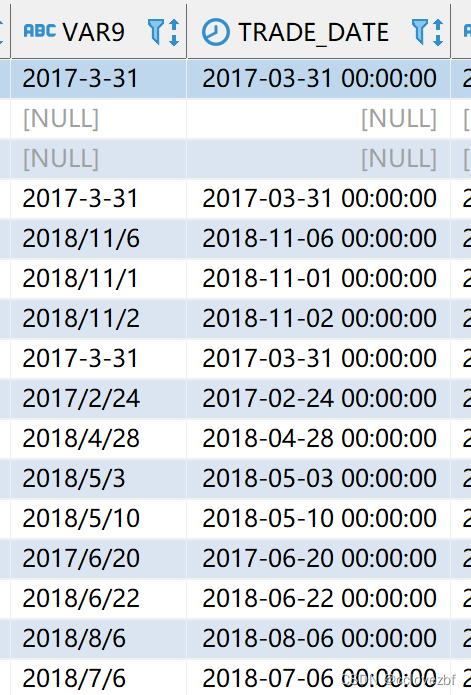
oracle 这样是可以的 SELECT * FROM (SELECT 1,2 FROM dual ) hive注意必须临时表名 select * from (select 1, 2 )t --正确 select * from (select 1, 2 ) --错误 9.with插入用法。oracle INSERT INTO TEST.CC_STUDENT_02WITH tmp AS (SELECT * FROM TEST.CC_STUDENT_02 cs ) SELECT * FROM tmp hive 顺序有点不同 WITH tmp AS (SELECT * FROM TEST.CC_STUDENT_02 cs ) INSERT INTO TEST.CC_STUDENT_02 SELECT * FROM tmp 10.计算语法 或者||用法不同oracle SELECT substr('202212', 1, 4) - 1 || 'aa' FROM dual -- 2021aa hive SELECT substr('202212', 1, 4) - 1 || 'aa' -- 2021.0aa 解决办法 SELECT cast(substr('202212', 1, 4) - 1 as int)|| 'aa' -- 2021aa SELECT cast(substr('202212', 1, 4) as int) - 1|| 'aa' -- 2021aa 因为int-int=int 。 string-int 和int-string=double 这是因为hive 在'2022'-1的时候计算结果是double类型 double+string 保留了一位小数 oracle SELECT 1||NULL||2 FROM dual -- 12 hive SELECT 1||NULL||2 --null 解决办法 select 1||nvl(null,'')||2 —————————————————————————————————————————— 最近遇到了一个特别搞人的oracle时间转化。就是oracle有个string字段里面的日期格式非常不标准有 - / 然后01省略0的,但是通过to_date函数都可以转化 不得不说oracle的to_date函数非常强大可以转化不标准的时间字符串为date类型 SELECT to_date('2017-3-31', 'yyyy/mm/dd') FROM dual UNION ALL SELECT to_date('2018/11/6', 'yyyy/mm/dd') FROM dual UNION ALL SELECT to_date('2017/6/20', 'yyyy/mm/dd') FROM dual UNION ALL SELECT to_date('2017-06-20', 'yyyy/mm/dd') FROM dual UNION ALL SELECT to_date('20170620', 'yyyy/mm/dd') FROM dual
hive呢? hive怎么搞? var9就是原列,trade_date就是转化后的。案例中的20170620是不存在的(我自己造的)。。
此时我已经想到了一个复杂的办法。。。 说下思路 1.自己定义一个udf函数,用java的方式去判断然后补充0 成为标准的时间字符串 2.我想到了oracle的instr函数可以获取的第一个和第二个 / 或 - 的位置 然后根据位置来补充0 3.第2个没问题 但是注意看我的第7点,hive的instr函数阉割了这个功能。 所以需要找其他函数 有两种 一种是通过 index获取 月份和天的具体下表 ,这个可以用subtring_index。 一种是通过正则直接提取。 我直接用这个regexp_extract了 select y||'-'||if(length(m)=1,0||m,m)||'-'||if(length(d)=1,0||d,d) from ( select replace(a,'/','-') a , regexp_extract(replace(a,'/','-'),'(\\d+)-(\\d+)-(\\d+)',1) y, regexp_extract(replace(a,'/','-'),'(\\d+)-(\\d+)-(\\d+)',2) m, regexp_extract(replace(a,'/','-'),'(\\d+)-(\\d+)-(\\d+)',3) d from ( select '2020/3/23'as a union all select '2019-12-1'as a union all select '2019-12-6'as a union all select '2018/7/6'as a )t )t1 ;
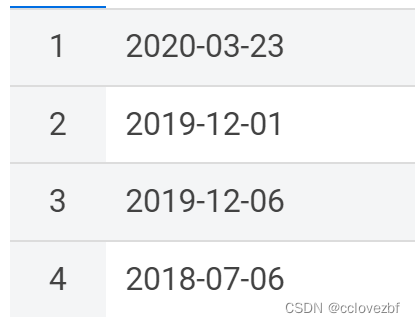
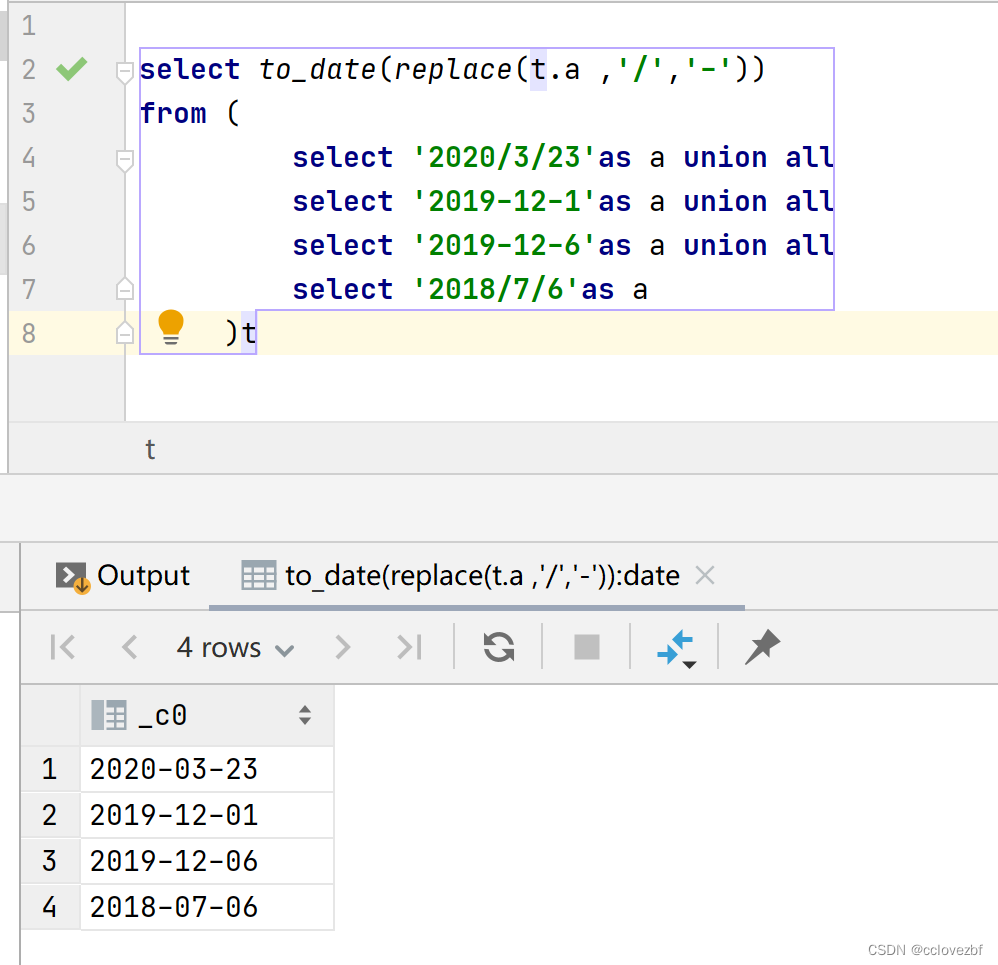
结果也ok,但是总感觉很lowb 有没有和oracle一样的to_date可以解决这个问题的呢? 我是暂时没看到,有没有小伙伴能够解决,可以留言,感激不尽。 ---------------------------2023-02-24更新------------------------ 最近发现了一个比较简单的算法。。。。 select to_date(replace(t.a ,'/','-')) from ( select '2020/3/23'as a union all select '2019-12-1'as a union all select '2019-12-6'as a union all select '2018/7/6'as a )t
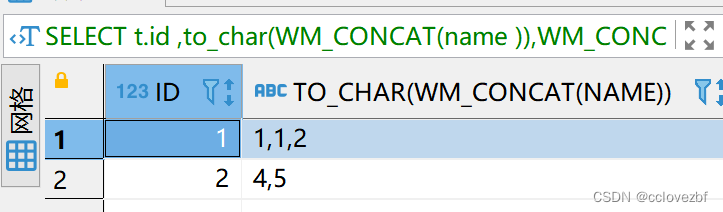
oracle是真吉儿复杂。 简简单单的一个算第几周的函数搞这么复杂 oracle的iw算法,关于Oracle to_char()函数中的IW,WW 周别显示 ._liu威的博客-CSDN博客 hive是不行了。但是有个weekofyear()凑合用吧 oracle ww 初始不完整的一周算第一周 iw 是完整的第一周才算第一周 hive的还没尝试。。 11、WM_CONCAT这个函数其实和mysql的group_concat 差不多 ,都是列转行。 SELECT t.id ,to_char(WM_CONCAT(name )),WM_CONCAT(name ) FROM ( SELECT 1 AS id ,1 as name FROM dual UNION ALL SELECT 1 AS id ,2 as name FROM dual UNION ALL SELECT 1 AS id ,1 as name FROM dual UNION ALL SELECT 2 AS id ,4 as name FROM dual UNION ALL SELECT 2 AS id ,5 as name FROM dual )t GROUP BY t.id
等价于hive的 concat_ws(',',collect_list(column)) 因为可以看到oracle没有去重,所以collect_list即可,不需要用collect_set 12 FOR IN LOOP其实不想写这个。。之前遇到了几个简单的loop,我都通过shell来实现,后来发现之前的pkg写的是越来越过分。。。没办法只能加强的学习一波。 【Oracle】for in loop_Hi竹子的博客-CSDN博客 FOR 结果集 IN ( SELECT [匹配字段],[更新字段] FROM A表 ) loop UPDATE B表 SET B表.[需要更新字段]= 结果集.[更新字段]; WHERE B表.[匹配字段]= 结果集.[匹配字段]; END loop ; --------------------------------------------------- SQL执行含义: 先执行IN里的SQL,得到结果集; 循环结果集,结果集可用于 loop里的SQL。 单看这么一段可能不太好理解。直接来实战 --- 不举例了。 其实简单的循环可以通过shell来实现。在shell里写while循环 有点实战不动了,我这边的例子里是个 for in loop , while () end loop 里面搞了一个递归,日了狗了,只能想着用spark代码去跑递归了。 这里我遇到了一个比较简单的循环,给大家展示下如何直接在hive里处理不经过shell和其他方法。 oracle pck -- V_START_PERIOD := V_YEAR_ID || '01'; -- V_END_PERIOD := V_YEAR_ID || '12'; --Part3、增长率计算:自动计算按增长率预估的数据 WHILE V_START_PERIOD |
【本文地址】
今日新闻 |
推荐新闻 |