VS2019使用C++调用并部署pytorch VGG模型全过程(libtorch+opencv)(cpu+gpu) |
您所在的位置:网站首页 › opencv调用pytorch › VS2019使用C++调用并部署pytorch VGG模型全过程(libtorch+opencv)(cpu+gpu) |
VS2019使用C++调用并部署pytorch VGG模型全过程(libtorch+opencv)(cpu+gpu)
|
环境配置vs2019+libtorch1.9.0+opencv3.4.2+cuda11.0+cudnn8.0(实测可用,不踩坑)
须知
Libtorch版本需与pytorch版本兼容(最好一致),系统下载与pytorch版本相同的CUDA和Cudnn,否则导入模型将出错。 若想使程序在GPU上运行,需下载GPU版libtorch,其也支持cpu运行。 文中给出图片或许版本与标题不一致,不影响实际操作,作者已亲测可行 用C++调用pytorch模型,其目的在于:使用C++及多线程可以加快模型预测速度 模型训练有两种方法: 1.直接使用C++编写训练代码,搭建完整的网络模型,但此方法无法使用迁移学习,而迁移学习是目前训练样本几乎都会用到的方法 2.使用python代码训练好模型,使用JIT技术,将python模型导出为C++可调用的模型 TorchScript:一种从PyTorch代码创建可序列化和可优化模型的方法。用TorchScript编写的任何代码都可以从Python进程中保存并加载到没有Python依赖关系的进程中。 利用工具可增量地将模型从纯Python程序转换为能够独立于Python运行的TorchScript程序,例如,一个独立的c++程序。 实验流程 1.安装librtorch(有gpu和cpu版本,都可实现)[1] pytorch官网. opencv官网. 官网下载opencv库压缩包,解压至本地 3.python端:(1)搭建pytorch网络模型(以vgg分类网络为例) (2)将PyTorch模型转换为Torch Script Module 第一个方法是tracing。该方法通过将样本输入到模型中一次,来对该过程进行评估从而捕获模型结构,并记录该样本在模型中的flow。该方法适用于模型中很少使用控制flow的模型。 第二个方法就是向模型添加显式注释,通知Torch Script编译器它可以直接解析和编译模型代码,受Torch Script语言强加的约束。 利用Tracing将模型转换为Torch Script (无论后续选择用cpu或gpu,此步操作相同) 要通过tracing来将PyTorch模型转换为Torch脚本,必须将模型的实例以及样本输入传递给torch.jit.trace函数,并在模块的forward方法中嵌入模型评估的跟踪,这将生成一个torch.jit.ScriptModule对象,最后将该对象保存(即将ScriptModule序列化为一个文件。然后,C++就可以不依赖任何Python代码来执行该Script所对应的Pytorch模型。)。 【导入模型:(按照自己保存模型的方式进行导入:直接保存模型or保存权重参数)】 这里是保存的权重参数信息… tips:以上代码针对输入单个图像送入网络的情况,后续将更新如何将孪生网络(输入两个图像)模型序列化并在C++中调用的博客 3.C++端(1)在VS中配置libtorch库 创建新项目; 配置头文件(项目->属性); 添加依赖库的文件名(此处为确保libtorch的所有相关lib文件被导入,可写为~lib\*.lib) 包含目录: ~\OpenCV\build\include ~\OpenCV\build\include\opencv ~\OpenCV\build\include\opencv2 库目录: ~\OpenCV\build\x64\vc15\lib 链接器>附加依赖项: opencv_world342d.lib (对应debug) opencv_world342.lib (对应release) (3)在C++中加载和执行Script Module 要在C ++中加载序列化的PyTorch模型,必须依赖于PyTorch C ++ API - 也称为LibTorch。 即创建最终调用网络模型.cpp文件;(cpu运行可直接在新项目中创建,gpu运行需单独创建) 【导入头文件】
(4)LibTorch构建应用程序(生成.exe文件) 【CPU版本:】 可在vs中直接创建项目,在项目中创建.cpp文件,再直接点击运行进行调试 【GPU版本:】 先创建.cpp文件,再配置CMakeLists.txt来建立项目,最后在cmd中通过cmake编译项目,生成.exe可执行程序。如下: 1、执行(3),将代码保存到名为main.cpp的文件中。 2、构建它的CMakeLists.txt cmake_minimum_required(VERSION 3.0 ) # 指定cmake的最小版本 project(gpucode) # 设置项目名称 SET(CMAKE_BUILE_TYPE Debug) find_package(Torch REQUIRED) set(OpenCV_DIR D:/opencv3.4.2/build) set(OpenCV_MODULE_PATH D:/opencv3.4.2/build) find_package(OpenCV REQUIRED) include_directories( ${OpenCV_INCLUDE_DIRS} ) # 需要用到opencv,则需要配置 include_directories( ${Torch_INCLUDE_DIRS} ) message(STATUS "Pytorch status:") message(STATUS " libraries: ${TORCH_LIBRARIES}") message(STATUS "OpenCV library status:") message(STATUS " version: ${OpenCV_VERSION}") message(STATUS " libraries: ${OpenCV_LIBS}") message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}") add_executable(gpucode main.cpp) # 生成可执行文件 target_link_libraries(gpucode "${TORCH_LIBRARIES}" "${OpenCV_LIBS}") # 设置 target 需要链接的库 set_property(TARGET gpucode PROPERTY CXX_STANDARD 11)
3、CMD中运行以下命令从gpucode1/文件夹中构建应用程序: 【1】cd "F:\C++code\gpucode1"再输入: 【2】cmake -DCMAKE_PREFIX_PATH="F:\C++code\gpucode1"DCMAKE_PREFIX_PATH:该路径为生成项目的位置,路径下需包含CMakeLists.txt 【若出现以下报错】(即未指定生成项目使用的平台类型) [tip]:网上有的方法写的是加上: 若又出现下错误:(即与之前使用的生成器不匹配) 【make可用cmake --build . --config Debug/Release替代,(Debug/Release具体看自己的C++代码选择的调试模式),效果一致】 如果一切顺利,它将出现以下语句: ➀ Cmake-DCMAKE_PREFIX_PATH="F:\C++code\gpucode1"
使用相同的序列化模型(.pt文件)通过libtorch在vs上运行来尝试。通过比较,发现C++端的输出与Python端的输出是一样的,表明实验成功。 在CMD对应路径下运行gpucode.exe文件: (tip)若使用的是torch.jit.load(argv[1]),运行时记得添加.pt文件对应路径,如 : gpucode.exe(空格)d:/model.pt否则: gpucode.exe
1.利用cpu运行时,占用率太高 ------tbc------- 有用可以点个大拇指哦 🤭 【作者有话说】 以上内容仅为博主自主整理分享,很多内容也是来源于网络,若有侵权,请私聊告知 大家有任何问题可在评论区讨论交流~ |
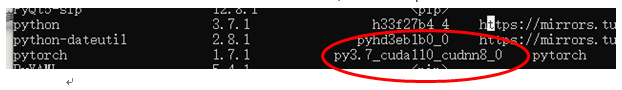
 [2] 某博主整理的libtorch各版本下载地址.👍! 【gpu版本需要在电脑上安装对应的版本的cuda和cudnn! 】
[2] 某博主整理的libtorch各版本下载地址.👍! 【gpu版本需要在电脑上安装对应的版本的cuda和cudnn! 】 【提供任意输入张量(size需符合网络输入要求):】
【提供任意输入张量(size需符合网络输入要求):】  【将输入送入网络,追踪模型所有操作】 序列化模型时,模型和输入在cpu上运算
【将输入送入网络,追踪模型所有操作】 序列化模型时,模型和输入在cpu上运算  【保存序列化后模型:】
【保存序列化后模型:】  跟踪的ScriptModule可以与常规PyTorch模块进行相同的计算。
跟踪的ScriptModule可以与常规PyTorch模块进行相同的计算。 配置库目录;
配置库目录; 
 tips:
tips:  (2)在VS(2019)中配置opencv库 Vc++目录 >
(2)在VS(2019)中配置opencv库 Vc++目录 > 【载入模型】 模型路径中必须是’\\';路径中可以有中文(但一般路径最好不用中文!),必须是绝对路径;
【载入模型】 模型路径中必须是’\\';路径中可以有中文(但一般路径最好不用中文!),必须是绝对路径;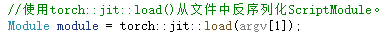 *argv[[1]]为序列化后模型的路径(此为官方例程,实际自用时可用自定义string model_path 替代),如下:
*argv[[1]]为序列化后模型的路径(此为官方例程,实际自用时可用自定义string model_path 替代),如下:  【执行模型】
【执行模型】  创建一个torch :: jit :: IValue的向量并添加一个输入。 要创建输入张量,我们可以使用torch :: ones(),相当于C ++ API中的torch.ones。
创建一个torch :: jit :: IValue的向量并添加一个输入。 要创建输入张量,我们可以使用torch :: ones(),相当于C ++ API中的torch.ones。 然后运行script::Module的forward方法,将我们创建的输入向量传递给它。最后调用**.toTensor() **将其转换为张量。
然后运行script::Module的forward方法,将我们创建的输入向量传递给它。最后调用**.toTensor() **将其转换为张量。 构建应用程序时,假设我们的目录布局如下:
构建应用程序时,假设我们的目录布局如下: ==》将指令改为:
==》将指令改为: 运行出现:(路径只是举例说明)
运行出现:(路径只是举例说明)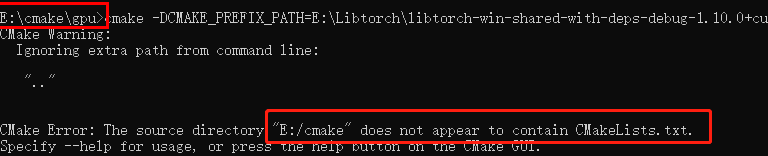 说明指令是从运行目录的上一级寻找所需文件,所以不写[..]可避免问题发生。
说明指令是从运行目录的上一级寻找所需文件,所以不写[..]可避免问题发生。 解决方法:删除CMakeCache.txt, 重新运行指令即可
解决方法:删除CMakeCache.txt, 重新运行指令即可 ➁ cmake --build . --config Debug
➁ cmake --build . --config Debug 

 Pycharm运行.py文件:
Pycharm运行.py文件: 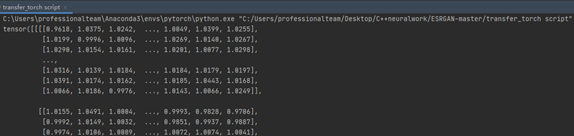
 2.验证c++端gpu是否可用 std::cout 链接库配置,重新生成解决方案 gpu:检查项目–>属性–>链接库配置,重新执行cmake第二步。若修改后重新运行问题依然存在,则在vs中先清理解决方案,再在cmd中重新cmake
2.验证c++端gpu是否可用 std::cout 链接库配置,重新生成解决方案 gpu:检查项目–>属性–>链接库配置,重新执行cmake第二步。若修改后重新运行问题依然存在,则在vs中先清理解决方案,再在cmd中重新cmake【本文地址】
今日新闻 |
推荐新闻 |