GPU内存(显存)的理解与基本使用 |
您所在的位置:网站首页 › nvidia是用来干什么的 › GPU内存(显存)的理解与基本使用 |
GPU内存(显存)的理解与基本使用
|
引言:GPU显存的组成与CPU的内存架构类似,但为了满足并行化运算GPU的显存做了特殊设计,与之相关的概念很多如host memory、device memory、L1/L2 cache、register、texture、constant、shared memory、global memory等,还会涉及一些硬件概念DRAM、On/Off chip memory,还涉及到一些操作如pin memory,zero copy等。概念多了对于初学者就会困惑,比如: 数据从系统内存传入到GPU运算单元,需要经过一些什么操作/位置?texture memory到底是什么,是否有单独的物理硬件,为什么它对图像数据处理有帮助?本文试图帮助了解这些显存相关的概念,包括一些特殊存储作用是什么,性能如何,以及在CUDA中怎么用。内容如下: 1 系统内存与设备内存 1.1 内存的架构 1.2 传输通道的速度 2 存储(内存)之间的操作 2.1 数据从磁盘/系统内存到GPU 2.2 pinned memory 2.3 zero copy 2.4 卡内异步拷贝 2.5 设备之间的数据传输 3 设备内存的硬件 3.1. GDDR 3.2 HBM 4 设备内部的存储 4.1 全局内存 4.2 L1/L2缓存 4.3 局部内存(local memory) 4.4 寄存器(register) 4.5 共享内存(shared memory) 4.6 常量内存(constant memory) 4.7 图像/纹理内存(texture memory)本文相关样例代码: 1 系统内存与设备内存1.1 内存的架构了解内存,需要先了解内存的几个关键要素:位置、大小、速度与传输通道。位置是指存储的硬件在什么地方,通过位置可知道的信息很多,如硬件单元是在芯片内部还是芯片外部,能不能插拔(意味着可扩展)以及对应的上下游存储是什么;大小与速度是指内存数据能存多大,读写数据的速度有多快;传输通道:存储与存储之间能够通过什么传输协议/通道进行数据交换。 下图列出一个简化的系统内存与设备内存架构示意图: 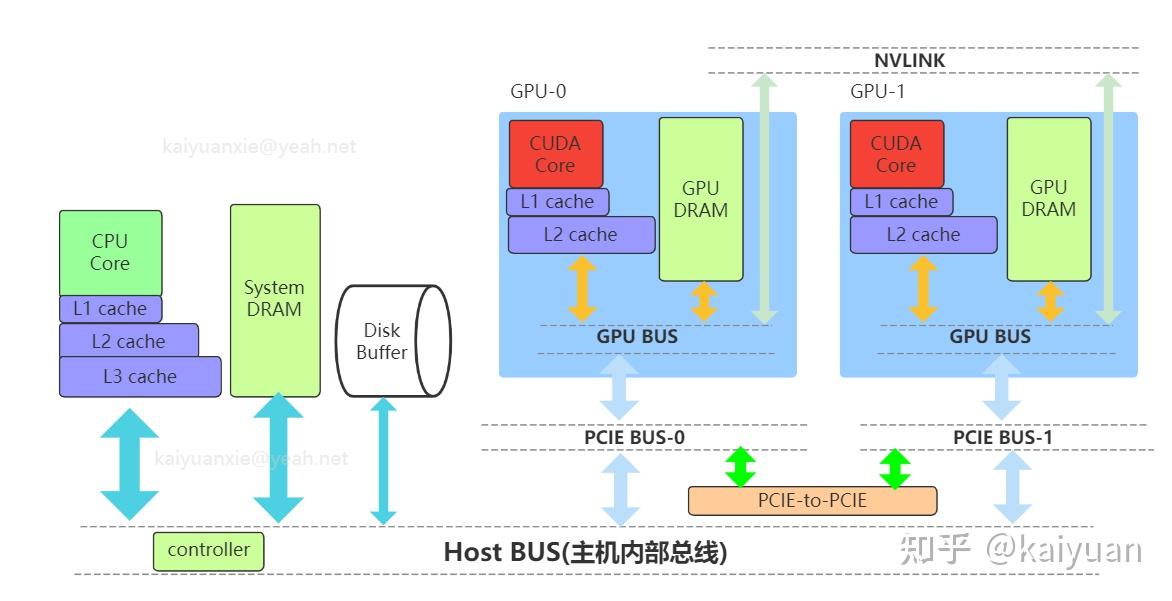 系统内存与两块GPU设备的交互示意图 系统内存与两块GPU设备的交互示意图系统存储: L1/L2/L3:多级缓存,其位置一般在CPU芯片内部;System DRAM:片外内存,内存条;Disk/Buffer:外部存储,如磁盘或者固态硬盘。GPU设备存储: L1/L2 cache:多级缓存,其位置在GPU芯片内部;GPU DRAM:通常所指的显存;设备存储还包含许多片上存储单元,后面进行详细介绍。 传输通道: PCIE BUS:PCIE标准的数据通道,数据就是通过该通道从显卡到达主机;BUS: 总线。计算机内部各个存储之间交互数据的通道;PCIE-to-PCIE:显卡之间通过PCIE直接传输数据;NVLINK:显卡之间的一种专用的数据传输通道,由NVIDIA公司推出。1.2 传输通道的速度对于传输通道的速度需要一个基本的认识,比如常见的PCIE以及专用的NVLINK通道速度的了解能给我们优化算法提供思路。下面对PCIE和NVLINK的速度进行介绍(参照新一代DDR5内存条支持的速度51.2 GB/s): PCIE的速度 第三代的PCIE x16的理论速度是16GB/s,所以受限于PCIE的速度,CPU到GPU速度小于16GB/s,(PCIe x16 第六代 2021:128GB/s),具体参见下表: 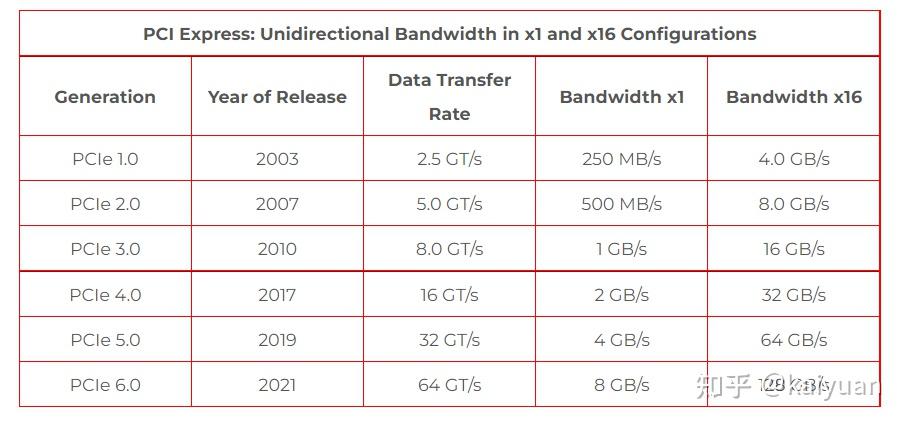 PCIE速度 PCIE速度NVLINK的速度 第二代的速度300GB/s,第三代速度:600GB/s。当前(2022年)发布的H100用了第四代NVLink,全通道速度可达900GB/s. 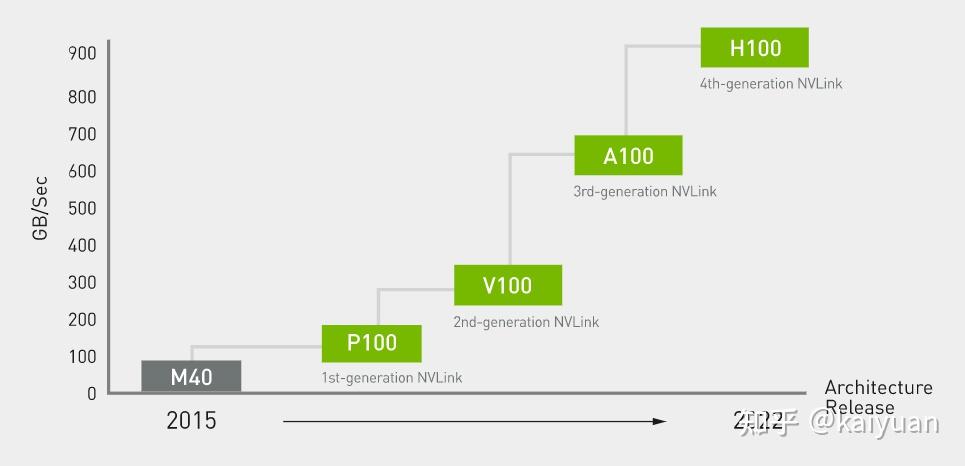 英伟达NVLNK的发展2 存储(内存)之间的操作 英伟达NVLNK的发展2 存储(内存)之间的操作内存之间的操作,无非就是数据在两个物理内存之间的读和写操作,但涉及的路径(方法)以及带宽会有所区别,这里先讨论设备之间的数据传输操作,包括:系统(CPU)到设备(GPU)的数据操作、GPU与GPU之间的数据操作。 2.1 数据从磁盘/系统内存到GPU在磁盘/硬盘(Disk/SSD)上面的数据传入到GPU的内存要经过:硬盘 -> 系统内存 -> 设备内存的过程。 //... data_pointer = cpuReadData("\disk_path") //数据读入内存 cudaMemCpyHostToDevice(data_pointer , gpu_pointer) //数据从内存转移到设备 //操作看似简单,但传输链路最复杂,其整体速度受硬盘速度、CPU(总线)速度、内存速度、PCIE速度的综合影响,在内存数据读写的所有场景中,这个速度一般是最慢的,总体来讲会有个"木桶效应",而且链路长中间的丢失(miss)也严重,所以尽量避免从硬盘中频繁的读写数据到GPU,即减少用硬盘读写中间数据,同时减少系统内存的换页操作,如使用pinned memory减少数据的硬盘读写。 2.2 Pinned memoryPinned memory(Page-locked memory)页锁内存,能够提高数据在系统内存与GPU之间的传输速度,其具体的做法是将数据在系统内存中锁住,避免数据在系统环境切换(如线程更换)时,数据从内存转移到硬盘。要理解页锁内存需要简单了解一下系统内存的管理的方式,系统内存使用中有两个需要考虑条件: 系统的内存是有限的,硬盘相比内存有更大的空间 ;系统是支持多线程/进程并发的,而同时运行的线程/进程对内存的需求往往可能超过系统内存上限。考虑到这两个条件,系统内存管理时会使用分页的管理机制,原理如下图所示,当系统进行内存管理时,它会将一部分暂时不需要用的数据(cache)从系统内存转移到硬盘(buffer),需要用的时候再将其转移回内存。  内存管理简化示意图 内存管理简化示意图对页锁内存的补充: 什么是页? 内存中的一个数据大小单位。4K或者8K什么是换页? 即内存中数据的切换,会使得数据从内存中的cache转换到硬盘。什么是页锁? 将数据固定在内存中,避免换页。CUDA中使用页锁内存,在PCIE x16 (三代,理论带宽16GB/s)能够达到12GB/s的数据吞吐速度。 注意:页锁内存会消耗系统的可用内存,有概率拖慢整个系统运行的速度。进一步的了解页锁推荐阅读一下系统的内存管理virtual memory manager。 页锁内存对传输的影响,测试示例源码,编译与运行: $ nvcc -lcuda hostAndDeviceTrans.cu -o testHost2Device $ ./testHost2Device2.3 Zero copyZero copy(零拷贝) 是GPU计算单元直接从系统内存读取数据,不需要将数据从系统内存转移到GPU的显存。通常系统内存的数据需要经过GPU内存才能进入计算的缓存中,但通过zero copy 能够实现直接的读写,示意图如下: 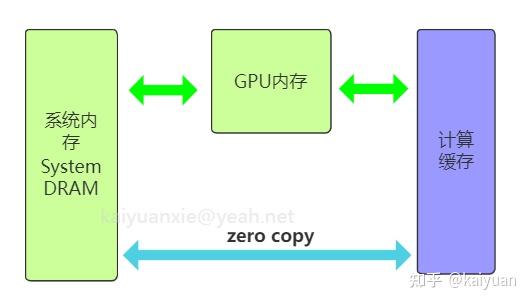 具体的做法是,直接申请pinned memory,然后将指针传递给运算的kernel: float *a_h, *a_map; // 定义两个指针:a_h 内存原指针,a_map映射指针 ... cudaGetDeviceProperties(&prop, 0); // 获取GPU的特性,看是否支持地址映射 if (!prop.canMapHostMemory) exit(0); cudaSetDeviceFlags(cudaDeviceMapHost); // 设置设备属性,打开地址映射 cudaHostAlloc(&a_h, nBytes, cudaHostAllocMapped); // 开辟pinned memory cudaHostGetDevicePointer(&a_map, a_h, 0); // 地址映射 a_h -> a_map. kernel(a_map);注意: zero copy 需要借助pinned memory ;zero copy 适用于只需要一次读取或者写入的数据操作,要频繁读写的数据,不建议用zero copy。zero copy对矢量加法运算的影响,测试示例 源码,编译与运行: $ nvcc -lcuda zeroCopy.cu -o testZeroCopy $ ./testZeroCopy2.4 卡内异步拷贝卡内的异步拷贝(Async-copy)是一种高效的数据传输操作,能够提高数据从全局内存到共享内存之间传输速度,同时降低了L1缓存和寄存器的使用量。其传输原理如下所示,正常情况下数据从全局内存(DRAM)上传输到共享内存(SMEM)需要先经过L2传输到L1,然后由L1写入寄存器(RF),再由寄存器传输给共享内存。如果使用异步拷贝,数据能够直接经由L2传输到SMEM,后者也可以用L1做个中转。这种绕开(Bypass)的操作可以让传输速度提升2倍以上。  异步拷贝 异步拷贝卡内异步拷贝是在Ampere架构之后的GPU上面才支持的操作,主要是通过CUDA 里面的cooperative_groups::memcpy_async 操作完成,使用示例如下所示: /// This example streams elementsPerThreadBlock worth of data from global memory /// into a limited sized shared memory (elementsInShared) block to operate on. #include #include namespace cg = cooperative_groups; __global__ void kernel(int* global_data) { cg::thread_block tb = cg::this_thread_block(); const size_t elementsPerThreadBlock = 16 * 1024; const size_t elementsInShared = 128; __shared__ int local_smem[elementsInShared]; size_t copy_count; size_t index = 0; while (index 设备之间的数据传输与控制设备之间(peer-to-peer)直接访问方式可以降低系统的开销,让数据传输在设备之间通过PCIE或者NVLINK通道完成,而且CUDA的操作也比较简单,示例操作如下: float* p0, *p1; cudaSetDevice(0); // 将GPU0设置为当前设备 size_t size = N * sizeof(float); // size设置为N个 float cudaMalloc(&p0, size); // GPU0开辟内存 cudaSetDevice(1); // 将GPU1设置为当前设备 cudaMalloc(&p1, size); // GPU0开辟内存 cudaMemcpyPeer(p1, 1, p0, 0, size); // Copy p0 to p1GPU之间数据传输测试示例 源码,编译与运行: $ nvcc -lcuda device2Device.cu -o testDevice2Device $ ./testDevice2Device设备之间的数据传递,还涉及到内存地址和传输速度的问题需要考虑,如内存地址可以使用UVA: 2.5.1 UVA的使用 UVA( Unified Virtual Address),是对系统以及设备的内存统一管理的一种机制,在没有UVA的情况下,如下图所示,系统内存地址、两个设备GPU地址都是从0x0000开始到0xFFFF结束, 各个设备的内存的独立意味着需要显示地完成多个设备指针地址之间的映射(转换)操作。  有UVA的情况下,系统内存与设备内存认为进行了统一的编排。如示意图中,三个内存块统一在一起,从0x0000开始到0xFFFF结束:  2.5.2 NVLINK 与PCI-E的差距: 在CUDA API中,我们用cudaMemcpy可以测试数据拷贝的速度差异,拷贝的形式有三种: cudaMemcpyHostToDevice: 主机到GPU;cudaMemcpyDeviceToHost:设备到主机;cudaMemcpyDeviceToDevice: GPU到GPU;// 速度测试的主要代码段: unsigned char *d_idata; checkCudaErrors(cudaMalloc((void **)&d_idata, memSize)); unsigned char *d_odata; checkCudaErrors(cudaMalloc((void **)&d_odata, memSize)); // initialize memory checkCudaErrors( cudaMemcpy(d_idata, h_idata, memSize, cudaMemcpyHostToDevice)); // run the memcopy sdkStartTimer(&timer); checkCudaErrors(cudaEventRecord(start, 0)); for (unsigned int i = 0; i 带宽测试经过测试cudaMemcpyDeviceToDevice一般会走PCIe通道,而且其速度会比到主机的速度还慢(估计是经过了主机中转),使用NVLink进行不同GPU之间的数据copy需要使用cudaMemcpyPeer函数。代码修改后如下所示: // NVlink COPY 代码差异 cudaSetDevice(0); unsigned char *d_idata; checkCudaErrors(cudaDeviceEnablePeerAccess(1, 0)); checkCudaErrors(cudaMalloc((void **)&d_idata, memSize)); cudaSetDevice(1); unsigned char *d_odata; checkCudaErrors(cudaDeviceEnablePeerAccess(0, 0)); checkCudaErrors(cudaMalloc((void **)&d_odata, memSize)); cudaSetDevice(0); // initialize memory checkCudaErrors( cudaMemcpy(d_idata, h_idata, memSize, cudaMemcpyHostToDevice)); // run the memcopy sdkStartTimer(&timer); checkCudaErrors(cudaEventRecord(start, 0)); for (unsigned int i = 0; i 第三代NVLink速度实测NVLink 的卡间通信还可以结合NVSwitch达到节点内GPU之间全量通信。NVSwitch可以理解为一个NVLink连接之间的交换机,目的是提高同一个时刻多组GPU之间的通信带宽。举个例子,在8卡H100 GPU的服务器内部,同一时刻通过NVLink进行数据交换的GPU卡不能做到全量的带宽吞吐,比如有GPU0GPU1, GPU2GPU3同时交换数据时,所有GPU的带宽小于最大带宽900GB/s。增加NVSwitch之后的GPU之间能够以最大带宽进行数据交换,同一个时刻4对GPU以全量通信,总的带宽吞吐可达到3.6T/s。  第三代 NVSwitch3 设备内存的硬件 第三代 NVSwitch3 设备内存的硬件GPU的内存硬件存储介质与CPU的类似,主要的区别是设计的结构有所差异。先说一下GPU内存硬件的分类,按照是否在芯片上面可以分为片上(on chip)内存和片下(off chip)内存,片上内存主要用于缓存(cache)以及少量特殊存储单元(如texture)特点是速度快,存储空间小;片下内存主要用于全局存储(global memory) 即常说的显存,特点是速度相对慢,存储空间大,不同于CPU系统内存可扩展的设计,GPU的内存硬件的大小整体都是固定,所以在选择好显卡型号后就会确定好,包括缓存和全局存储。对于缓存的硬件可以阅读各个芯片的手册,这里简单介绍两种片下GPU存储硬件: 3.1. GDDRGDDR(Graphics Double Data Rate, SDRAM)是一种针对显卡的存储介质。了解GDDR可以用DDR作为参考对比。目前在我们的电脑里面主流的内存条主要是DDR,使用较多的是DDR3/DDR4/DDR5。DDR作为一个为CPU服务的RAM,满足CPU运算的特点,针对的场景是:小数据、多操作,因此DDR的内存条一般设计为时延小,不太计较是否有大的带宽(bandwidth);而GPU的特点是数据大、操作少,或者说单个操作内要进行大批量数据处理,所以在普通的DDR基础上,GDDR增加了带宽。 DDR的参数: 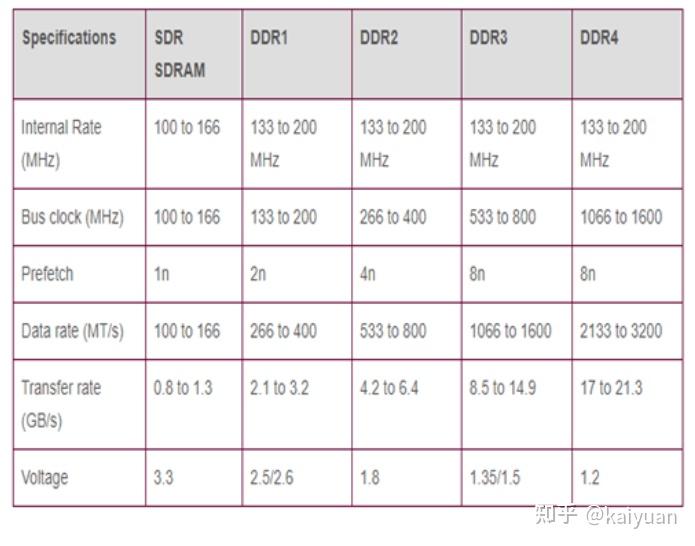 GDDR的参数:  通过比较可知,同系列的GDDR相比DDR的Transfer rate要高不少,同时时钟频率相对较低。 3.2 HBMHBM(High Bandwidth Memory)高带宽存储,是另一种常用显存介质。 顾名思义这个存储介质有着"High Bandwidth",参考NVIDIA P100所用的HBM来说明,该系列的显卡采用HBM第二代存储芯片,如下图是P100的硬质电路侧面视图,其中许多HBM2存储介质堆叠在基板(BASE DIE)上,且基板位置通过无源硅板(passive silicon interposer)紧邻P100芯片。  HBM应用电路示意 HBM应用电路示意这种3D设计空间堆叠方式将存储介质(HBM,DRAM)层层拼接起来,这样的3D结构更能接近芯片单元,同时空间占比相对较小。该设计使得HBM的带宽和存储量都得到了提升,对比GDDR:  注:HBM做显存的优势这么明显,为什么没有完全取代GDDR?因为生产一个3D结构的HBM的难度相比于生产一个平面结构的GDDR难度更大,所以HBM一般价格高。 4 设备内部的存储前面提到GPU的内部存储分为片上存储和片下存储,指的硬件所在位置,为了满足GPU的应用场景,对存储功能进行了细分,包括:局部内存(local memory)、全局内存(global memory)、常量内存(constant memory)、图像/纹理(texture memory)、共享内存(shared memory)、寄存器(register)、L1/L2缓存、常量内存/纹理缓存(constant/texture cache),下面逐个介绍一下。 其中涉及到一些名词,可以参考CUDA手册/NVIDA芯片手册理解,这里先通俗地解释一下: SM(Streaming Multiprocessors):理解为一个GPU内数据处理的大单元,好比多核的CPU芯片里面的一个核,CPU的一个核一般是运行一个线程,而SM能够运行多个轻量线程;nvcc:GPU程序的编译器,其实就是针对CUDA特殊化的gcc编译器;block: thread线程的集合单位。比如让GPU完成一个矩阵数据的运算 ,然后我们给参与运算的thread编个队,队名叫做block,对多个block编队就成了grid单位。warp: SM里面的运算执行单位,理解为运算时一个warp抓一把thread 扔进了计算core里面进行计算。以英伟达的典型芯片Volta为例,首先全局概览一下芯片的存储单元的架构: 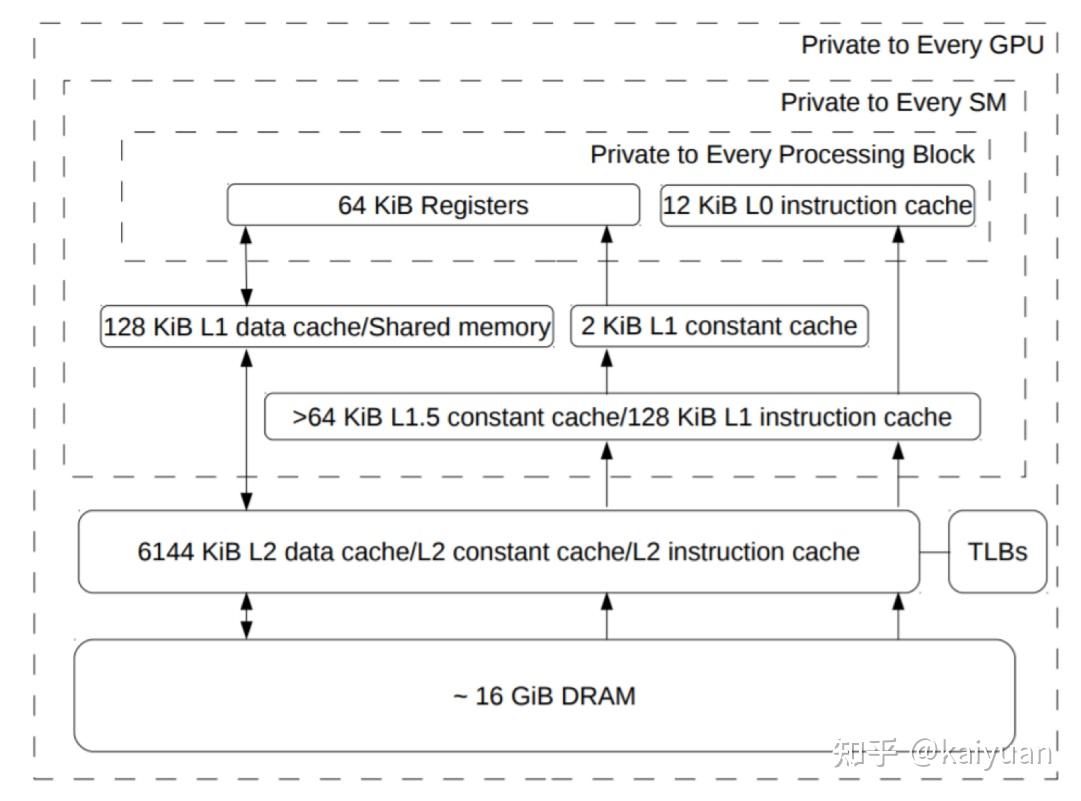 volta芯片的内存架构图 volta芯片的内存架构图Volta架构前存储单元的参数对比:  不同存储硬件速度对比4.1 全局内存 不同存储硬件速度对比4.1 全局内存全局内存(global memory)是数据常用的内存,它能被设备内的所有线程访问、全局共享,为片下(off chip)内存,前面提到的硬件HBM中的大部分都是用作全局内存。跟CPU架构一样,运算单元不能直接的使用全局内存的数据,需要经过缓存,其过程如下图所示: 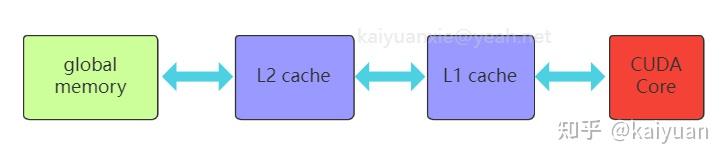 在CUDA runtime中,全局内存申请一般是cudaMalloc开头的函数,常见的如下: cudaMalloc(&ptr, size); kernel(ptr, ...); cudaFreeA(ptr); //其它方式: cudaMallocAsync(&ptr, size,stream); cudaMallocPitch(&devPtr, &pitch, width * sizeof(float), height); cudaMalloc3D(&devPitchedPtr, extent); cudaMallocArray(&cuArray, &channelDesc, width, height); //....注: cudaMallocHost 申请的是系统内存。 使用示例: 4.2 L1/L2缓存L1/L2缓存(Cache)数据缓存,这个存储跟CPU架构的类似。L2为所有SM都能访问到,速度比全局内存块,所以为了提高速度有些小的数据可以缓存到L2上面;L1用于存储SM内的数据,SM内的运算单元能够共享,但跨SM之间的L1不能相互访问。 对于开发者来说,需要注意L2缓存能够提速运算,比如CUDA11 A100 上面L2缓存能够设置至多40MB的持续化数据(persistent data),L2上面的持续化数据能够拉升算子kernel的带宽和性能,设置持续化数据的举例如下(摘取自CUDA 官网的exmaple): cudaGetDeviceProperties( &prop, device_id); // Set aside 50% of L2 cache for persisting accesses size_t size = min( int(prop.l2CacheSize * 0.50) , prop.persistingL2CacheMaxSize ); cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size); // Stream level attributes data structure cudaStreamAttrValue attr ; attr.accessPolicyWindow.base_ptr = /* beginning of range in global memory */ ; attr.accessPolicyWindow.num_bytes = /* number of bytes in range */ ; // hitRatio causes the hardware to select the memory window to designate as persistent in the area set-aside in L2 attr.accessPolicyWindow.hitRatio = /* Hint for cache hit ratio */ // Type of access property on cache hit attr.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache miss attr.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; cudaStreamSetAttribute(stream,cudaStreamAttributeAccessPolicyWindow,&attr);通过persistent data可以使得运算提速1.5倍,具体参看:CUDA Toolkit Documentation 4.3 局部内存(local memory)局部内存(local memory) 是线程独享的内存资源,线程之间不可以相互访问,硬件位置是off chip状态,所以访问速度跟全局内存一样。局部内存主要是用来解决当寄存器不足时的场景,即在线程申请的变量超过可用的寄存器大小时,nvcc会自动将一部数据放置到片下内存里面。 注意,局部内存设置的过程是在编译阶段就会确定。 4.4 寄存器(register)寄存器(register)是线程能独立访问的资源,它所在的位置与局部内存不一样,是在片上(on chip)的存储,用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小。以目前最新的Ampere架构的GA102为例,每个SM上的寄存器总量256KB,使用时被均分为了4块,且该寄存器块的64KB空间需要被warp中线程平均分配,所以在线程多的情况下,每个线程拿到的寄存器空间相当小。寄存器的分配对SM的占用率(occupancy)存在影响,可以通过CUDA Occupancy Calculator 计算比较,举例:如图当registers从32增加到128时,occupancy从100%降低到了33.33%:  占用率计算器4.5 共享内存(shared memory) 占用率计算器4.5 共享内存(shared memory)共享内存(shared memory) 是一种在block内能访问的内存,存储硬件位于芯片上(on chip),访问速度较快,共享内存主要是缓存一些需要反复读写的数据。可以通过一个矩阵运算的例子说明shared memory的作用,比如完成矩阵运算C = A X B, Ai_row表示A的第i行数据, Bj_col表示B的第j列数据,cij表示第i行 第j例的数值,有: cij = A_irow \times B_jcol 假设要得到C矩阵的第i行Ci_row的数据,上述运算需要进行N次,N为:B矩阵列宽大小。  C=AxB中行运算示意图 C=AxB中行运算示意图对于该计算而言,运算中的Ai_row保持不变,Bj_col进行迭代更新。Ai_row假设使用global memory,则每次运算都需要重新加载,数据重复加载了N次。然而Ai_row数据是可以复用的,所以将Ai_row放入共享内存中,这样相同的数据避免反复加载(Ai_row数据加载是要1次),从而提高运算效率。相比只用全局内存,共享内存在上述矩阵运算上可以提升20~50GB/s的速度。 注:共享内存与L1/L2存在差异。共享内存与L1的位置、速度极其类似,区别在于共享内存的控制与生命周期管理与L1不同,共享内存的使用受用户控制,L1受系统控制,CUDA编程的时候,shared memory更利于block之内线程之间数据交互。 shared memory提速求和运算 测试示例 源码,编译与运行: $ nvcc -lcuda sharedMemory.cu -o testSharedMemory $ ./testSharedMemory4.6 常量内存(constant memory)常量内存(constant memory) 是指存储在片下存储的设备内存上,但是通过特殊的常量内存缓存(constant cache)进行缓存读取,常量内存为只读内存。为什么需要设立单独的常量内存?直接用global memory或者shared memory不行吗? 主要是解决一个warp内多线程的访问相同数据的速度太慢的问题,如下图所示:  所有运算的thread都需要访问一个constant_A的常量,在存储介质上面constant_A的数据只保存了一份,而内存的物理读取方式决定了这么多thread不能在同一时刻读取到该变量,所以会出现先后访问的问题,这样使得并行计算的thread出现了运算时差。常量内存正是解决这样的问题而设置的,它有对应的cache位置产生多个副本,让thread访问时不存在冲突,从而提高并行度。 __constant__ int c1 = 10; // 声明__constant__ 即可。 __global__ void kernel1(int *d_dst) { int tId = threadIdx.x + blockIdx.x * blockDim.x; d_dst[tId] += c1; }需要说明的是,在硬件上面,constant单元也分了多级(L1/L1.5/L2),而且存在线程访问延时,比如上述例子中的广播操作,当线程数量增加时延时也会随之增加。  4.7 图像/纹理内存(texture memory) 4.7 图像/纹理内存(texture memory)图像/纹理(texture memory)是一种针对图形化数据的专用内存,其中texture直接翻译是纹理的意思,但根据实际的使用来看texture应该是指通常理解的1D/2D/3D结构数据,相邻数据之间存在一定关系,或者相邻数据之间需要进行相同的运算。 texture内存的构成包含 global + cache + 处理单元,texture为只读内存。texture的优势: texture memory 进行图像类数据加载时, warp内的thread访问的数据地址相邻,从而减少带宽的浪费。texture 在运算之前能进行一些处理(或者说它本身就是运算),比如聚合、映射等。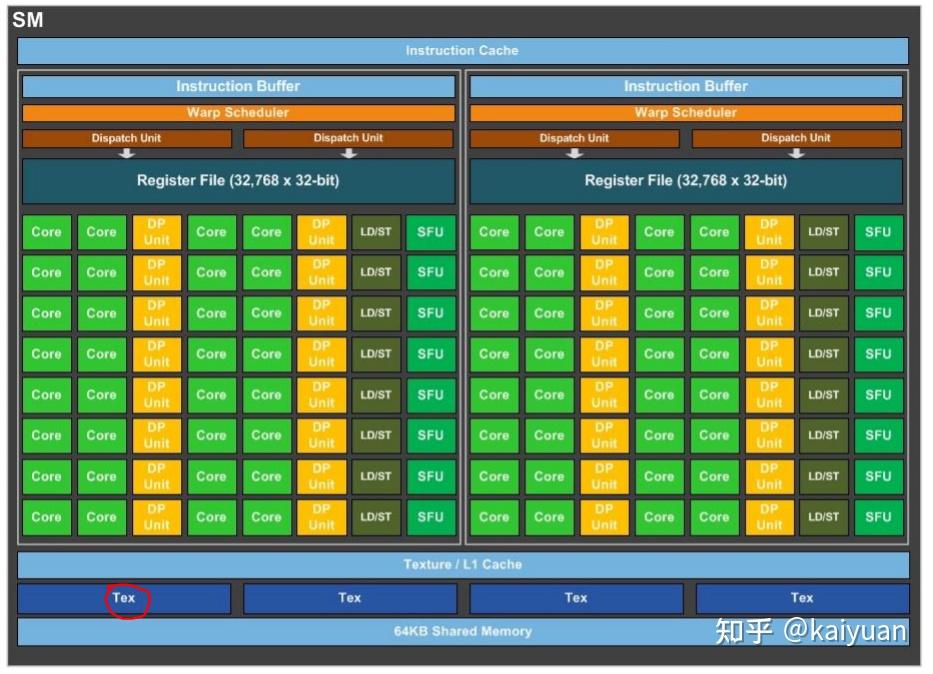 SM架构 SM架构如图所示,是一个P100显卡的SM架构,里面包括了前面提到的shared memory、register、L1和texture,其中有个四个Tex。 注:Tex是专门用来处理texture的单元,进行数据拿取(fetch)的时候,能够在一个clock时钟内完成对数据的一些预处理。 最后放一张各个存储的对比图:  数据来源CUDA best practices参考: 数据来源CUDA best practices参考:https://en.wikipedia.org/wiki/GB/s https://www.trentonsystems.com/blog/pcie-gen4-vs-gen3-slots-speeds https://images.nvidia.cn/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf NVLink & NVSwitch for Advanced Multi-GPU Communication GPUDirect GDDR vs DDR | Difference between GDDR and DDR GDDR vs HBM | Difference between GDDR and HBM https://www.nvidia.com/content/PDF/nvidia-ampere-ga-102-gpu-architecture-whitepaper-v2.pdf CUDA 11 Features Revealed | NVIDIA Developer Blog CUDA Toolkit Documentation |
【本文地址】
今日新闻 |
推荐新闻 |