训练属于自己的ChatGPT(2) |
您所在的位置:网站首页 › nox是怎么生成的 › 训练属于自己的ChatGPT(2) |
训练属于自己的ChatGPT(2)
|
很多人其实不太了解ChatGPT成为通用人工智能体(AGI)到底会经历怎样的步骤,接下来笔者会详细的描述一下ChatGPT是如何成为ChatGPT的。其实整个过程就是:学习说人话—>学习懂人话—>学习社会化 大语言模型的(LLM)的预训练(pretrain):即将人类的文本数据喂给LLM让他学习文字接龙这个任务,即让它在大规模无标注数据上学习,如何输出通顺的人类语言。换句话说就是学习说人话提示学习指令精调 (instruct tuninig): 即让语言模型和人类意图对齐,让LLM能够理解人类语言,即让它在大量有监督的NLP任务上进行指令精调。希望它能够面对一下这些问题,能够明白人类的意图,并给出正确的回答。换句话说就是学习懂人话。强化学习优化生成结果:通过人类的反馈,使用强化学习优化其输出的结果,让输出的结果满足人类的希望。换句话说就是学习社会化。笔者之前已经介绍了如何做采用无监督的方式进行预训练, 训练属于自己的ChatGPT--在GPT2上进行chatbot微调实战 ,让LLM学会说人话。至于懂人话,可以参考一下笔者之前的文章:UIE信息抽取模型之评论观点情感分析小样本微调实战 ,其实UIE的思想就是指令微调的思想,通过标注数据让一个模型完成很多的NLP任务,只不过和它的交互还达不到直接和他对话的程度。 今天笔者来介绍一下让机器学习如何通过PPO强化学习而变得社会化。其中PPO的原理笔者曾经在ChatGPT的强化学习部分介绍——PPO算法实战LunarLander-v2 这篇文章中做了详细的介绍和实战。 TRL 强化学习优化LLM流程这里笔者采用的TRL GitHub - lvwerra/trl: Train transformer language models with reinforcement learning. 这个专门针对transformer 语言模型进行强化学习微调的python包,即具体微调流程如下: 你需要有一个语言模型 (LLM: large language model)能够进行通顺的文本输出。你需要有个评估模型(RM :reward model) 去评估你模型的输出。让RM 评估 LLM的输出, 采用PPO算法通过RM的评估值 对 LM优化,让LM的输出在RM的评估体系中拿到高分,同时不能失去LM输出通顺文本能力,即优化后的模型输出和原模型输出的KL散度越接近越好。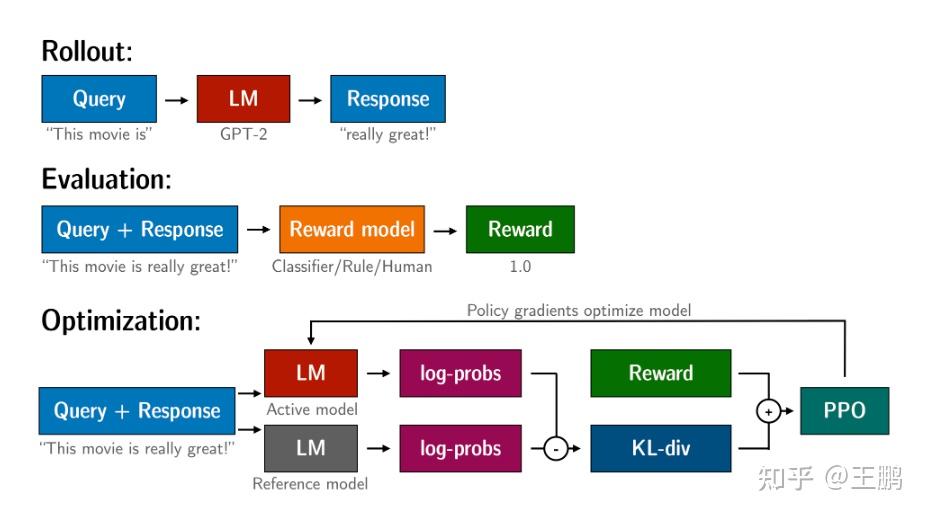 TRLPPO控制GPT2生成正向情感文本 TRLPPO控制GPT2生成正向情感文本根据上述流程我们开始采用trl这个包调整GPT2语言模型去让它 偏向生成正向情感的回复。 其整个过程和上述一样: 1.初始化一个GPT2 对话模型即LLM模型。笔者使用的是Huggface中的这个中文对话模型https://huggingface.co/shibing624/gpt2-dialogbot-base-chinese  GPT2 对话模型 GPT2 对话模型2.初始化一个情感分类模型即RM模型。这里笔者使用的是Huggface中的这个情感分类模型 。其中我们可以看到 样本情感极性越正向,模型输出的得分越大。 https://huggingface.co/liam168/c2-roberta-base-finetuned-dianping-chinese  RM模型 RM模型3.通过PPO强化学习算法,利用情感分类模型评估对话模型的输出,对GPT2对话模型进行优化,让GPT2对话模型的输出的结果在情感分类模型中得到高分。同时不破坏GPT2对话模型输出通顺对话的能力。 代码实战导入毕业的python 包,并初始化一个对话模型GPT2 # imports import torch from transformers import AutoTokenizer from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model from trl.core import respond_to_batch import random import torch.nn.functional as F # get models gen_model = AutoModelForCausalLMWithValueHead.from_pretrained('dialoggpt/') model_ref = create_reference_model(gen_model) tokenizerOne = AutoTokenizer.from_pretrained('dialoggpt/',padding_side='left') tokenizerOne.eos_token_id = tokenizerOne.sep_token_id初始化一个情感分类模型,输入文本,判断文本的情感极性 from transformers import AutoModelForSequenceClassification , AutoTokenizer, pipeline ts_texts = ["我喜欢下雨。", "我讨厌他."] cls_model = AutoModelForSequenceClassification.from_pretrained("./chineseSentiment/", num_labels=2) tokenizerTwo = AutoTokenizer.from_pretrained("./chineseSentiment/") classifier = pipeline('sentiment-analysis', model=cls_model, tokenizer=tokenizerTwo) classifier(ts_texts)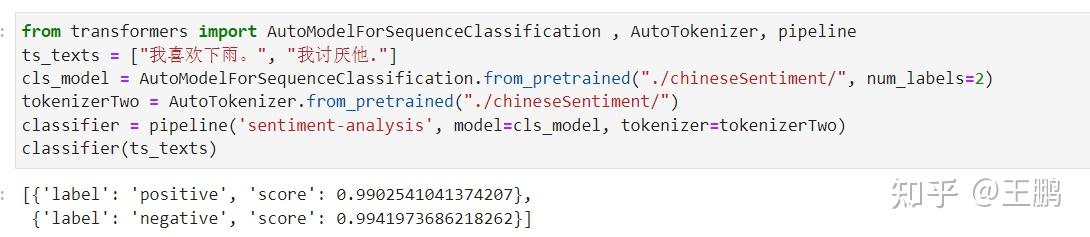 情感分类模型 情感分类模型数据预处理 这里笔者就是随机到网上找了5000多条对话文本。 from torch.utils.data import Dataset import torch.nn.utils.rnn as rnn_utils import json data = [] with open("./train.txt", "r", encoding="utf-8") as f: for i in f.readlines(): line = json.loads(i) data.append(line) def preprocess_conversation(data): sep_id = tokenizerOne.sep_token_id cls_id = tokenizerOne.cls_token_id dialogue_list = [] for conver in data: input_ids = [cls_id] start = conver["conversation"][0] # print(start["utterance"]) input_ids += tokenizerOne.encode(start["utterance"], add_special_tokens=False) input_ids.append(sep_id) dialogue_list.append(input_ids) return dialogue_list dialogue_list = preprocess_conversation(data) class MyDataset(Dataset): def __init__(self, data): self.data = data def __getitem__(self, index): x = self.data[index] return torch.tensor(x) def __len__(self): return len(self.data) mydataset = MyDataset(dialogue_list) def collate_fn(batch): padded_batch = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=tokenizerOne.sep_token_id) return padded_batch定义PPO优化器,这里需要定义一下 学习率,强化学习steps,batch_size等参数,注意笔者实践过,学习率不宜调大,容易把LLM语言模型调坏。 config = PPOConfig( model_name="gpt2-positive", learning_rate=1.41e-5, steps = 2000, batch_size = 16 ) ppo_trainer = PPOTrainer(config, gen_model, model_ref, tokenizerOne, dataset=mydataset, data_collator=collate_fn)开始强行学习训练, 1.输入一下样本给GPT2 , 拿到对话语言模型GPT2的输出。 2.将对话语言模型GPT2的输出 输入到 情感分类模型 拿到 情感分类模型的输出,作为reward。 3.将 对话语言模型GPT2 输入,输出, 以及 情感分类模型的 reward 一并输入给PPO优化器,让PPO优化器去优化对话语言模型GPT2。 rewards_list = [] for epoch, batch in enumerate(ppo_trainer.dataloader): #### Get response from gpt2 query_tensors = [] response_tensors = [] query_tensors = [torch.tensor(t).long() for t in batch] for query in batch: input_ids = query.unsqueeze(0) response = [] for _ in range(30): outputs = ppo_trainer.model(input_ids=input_ids) logits = outputs[0] next_token_logits = logits[0, -1, :] next_token_logits[ppo_trainer.tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf') next_token = torch.multinomial(F.softmax(next_token_logits, dim=-1), num_samples=1) if next_token == ppo_trainer.tokenizer.sep_token_id: # break input_ids = torch.cat((input_ids, next_token.unsqueeze(0)), dim=1) response.append(next_token.item()) response_tensors.append(torch.Tensor(response).long()) responseSet = ["".join(ppo_trainer.tokenizer.convert_ids_to_tokens([i.item() for i in r])) for r in response_tensors] print(responseSet) #### Get reward from sentiment model pipe_outputs = classifier(responseSet) rewards = [torch.tensor(output["score"]) for output in pipe_outputs] #### Run PPO step stats = ppo_trainer.step(query_tensors, response_tensors, rewards) print("epoch{}, reword is {}".format(epoch, sum(rewards))) rewards_list.append(sum(rewards))训练过程如下: 最开始几轮 reward 在15.6左右,而且GPT2语言模型的输出会稍微变得不连贯甚至很多重复。应该是PPO优化器让语言模型的参数变动一定程度上破坏了它的语言输出能力。  前4轮的效果 前4轮的效果到后面几轮 reward 在15.7左右,而且GPT2语言模型输出恢复正常了。  20多轮的效果结语 20多轮的效果结语至此我们就学会了如何采用PPO强化学习去控制 LLM的生成结果了。这样我们后续就可以定义不同的RM去控制语言模型生成 指定风格的文本了。 比如用chatgpt 使用的就是 RLHF(Reinforcement Learning from Human Feedback) 就是希望LLM生成的文章符合人类预期。 不得不说,对生成模型进行控制才是王道,比如图像生成界的controlNet 去控制扩散模型,估计后续会有各种各样的控制生成的方法出来,让生成模型的结果变得越来越实用。也许符合人类期望,将会是AGI一生的宿命。 参考 ChatGPT的强化学习部分介绍——PPO算法实战LunarLander-v2 训练属于自己的ChatGPT--在GPT2上进行chatbot微调实战 UIE信息抽取模型之评论观点情感分析小样本微调实战 https://huggingface.co/liam168/c2-roberta-base-finetuned-dianping-chinese https://huggingface.co/shibing624/gpt2-dialogbot-base-chinese GitHub - lvwerra/trl: Train transformer language models with reinforcement learning. |
【本文地址】
今日新闻 |
推荐新闻 |