一文弄懂Jupyter的配置与使用(呕心沥血版) |
您所在的位置:网站首页 › note和notebook › 一文弄懂Jupyter的配置与使用(呕心沥血版) |
一文弄懂Jupyter的配置与使用(呕心沥血版)
|
Jupyter 是一个基于 Web 的交互式计算平台,使用户能够创建和共享文档,这些文档包含实时代码、方程式、可视化图表和解释文字。Jupyter 在数据分析领域被广泛应用,它提供了一个直观、交互式的操作界面,使得用户能够更容易地探索数据、可视化数据以及进行数据处理和建模的实验。 Jupyter 不仅能够对 Python 代码进行展示和格式化,还能够保存用户的历史代码和结果以及数据分析结果。这些结果可以在后期随时查看和修改,使得 Python 的学习和应用变得更加方便和高效。 总之,学习一下jupyter还是非常必要的,也非常的方便,本文的操作主要针对Windows系统。 1.安装Jupyter安装是非常简单的,一般有两种方式,一种就是python环境,另外一种就是Anaconda环境; 1.1Python 环境下安装安装 Python。从 Python 官方网站[1]下载最新版本的 Python。 安装 pip。pip 是 Python 的包管理工具,用于安装和管理 Python 包。在命令行输入以下命令来检查 pip 是否已经安装: 代码语言:javascript复制pip --version如果 pip 已经安装则会输出 pip 的版本信息,否则需要手动安装。 安装 Jupyter Notebook。使用 pip 命令来安装 Jupyter Notebook。在命令提示符或终端窗口中输入以下命令: 代码语言:javascript复制pip install jupyter等待一段时间,Jupyter Notebook 就会被安装到你的电脑上了。 启动 Jupyter Notebook。安装完成后,在命令提示符或终端窗口中输入以下命令来启动 Jupyter Notebook : 代码语言:javascript复制jupyter notebook这个命令会自动打开你的默认浏览器,展示 Jupyter Notebook 的主页,并在后台启动一个 Jupyter 内核(Kernel)。 1.2Anaconda 环境下安装正常的话,安装Anaconda的时候,jupyter是伴随anaconda安装好的,不需要按照如下步骤再去安装; 安装 Anaconda。从 Anaconda 官方网站[3]下载最新版本的 Anaconda。 启动 Anaconda Navigator。安装完毕后,启动 Anaconda Navigator,它是一个可视化的应用程序,方便用户管理和运行 Anaconda 中包含的各种工具和应用。 安装 Jupyter Notebook。在 Anaconda Navigator 中,点击左侧导航栏的 “Environments”,然后在右边的区域中选中需要安装 Jupyter Notebook 的环境,在下方的 “Packages” 标签页中搜索 “jupyter”,并勾选 “jupyter” 和 “notebook”。然后点击 “Apply” 按钮进行安装即可。  image-20230423155830561 image-20230423155830561启动 Jupyter Notebook。安装完成后,在 Anaconda Navigator 中点击 “Launch” 按钮启动 Jupyter Notebook,也可以在命令提示符或终端窗口中输入以下命令来启动: 代码语言:javascript复制jupyter notebook2.启动命令默认端口启动 代码语言:javascript复制jupyter notebook浏览器地址栏中默认地将会显示:http://localhost:8888/tree。其中,“localhost”指的是本机,“8888”则是端口号,每多启动一次,端口号类推 指定端口启动 代码语言:javascript复制jupyter notebook --port 指定端口号只有数字,不含启动服务器但不打开浏览器 代码语言:javascript复制jupyter notebook --no-browser终端会显示出打开浏览器的链接,若需启动浏览器,复制链接打开即可 3.配置文件存放位置Jupyter Notebook 的启动目录是指 Jupyter Notebook 执行服务时的默认工作目录。当你在 Jupyter Notebook 中新建一个文件时,默认情况下会在该目录下创建文件。 设置 Jupyter Notebook 的启动目录非常有用,尤其是在你的工程有大量分散在不同目录中的数据或代码时。通过将启动目录设置为你的工程根目录,你就可以更轻松的管理和访问这些数据或代码了。 例如,假设你有一个名为 “my_project” 的项目,其中包含多个子目录和数据文件。如果你将 Jupyter Notebook 的启动目录设置为 “my_project” 目录,那么你就可以很方便地访问这个项目中的任何文件,而无需在 Jupyter Notebook 中输入完整路径。 另外,在 Jupyter Notebook 里,你可以使用一些 Python 库来处理和可视化你的数据。如果你使用的是相对路径来访问数据文件,那么使用相对于启动目录的路径通常会比使用绝对路径更方便。 jupyter默认文件都放在用户目录下,如下图,启动的时候就可以看到启动目录;进入jupyter也确实是这个目录下的内容;显然这是有问题的,所以需要我们更改文件的存放位置; 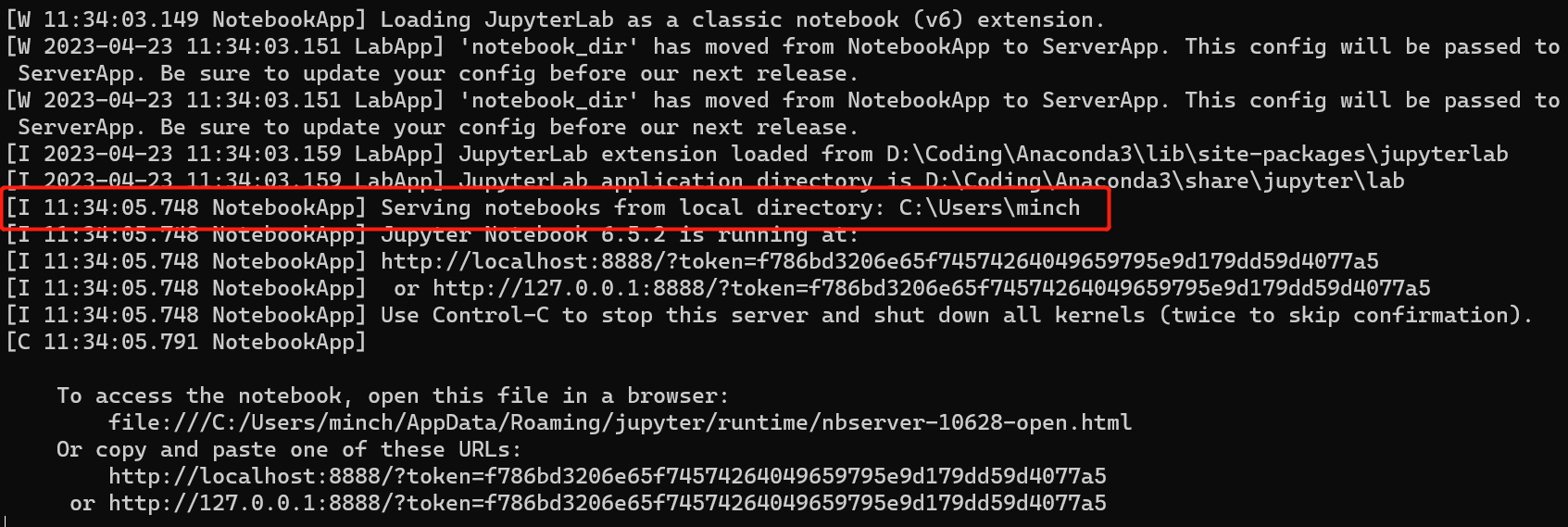 image-20230423113443692 image-20230423113443692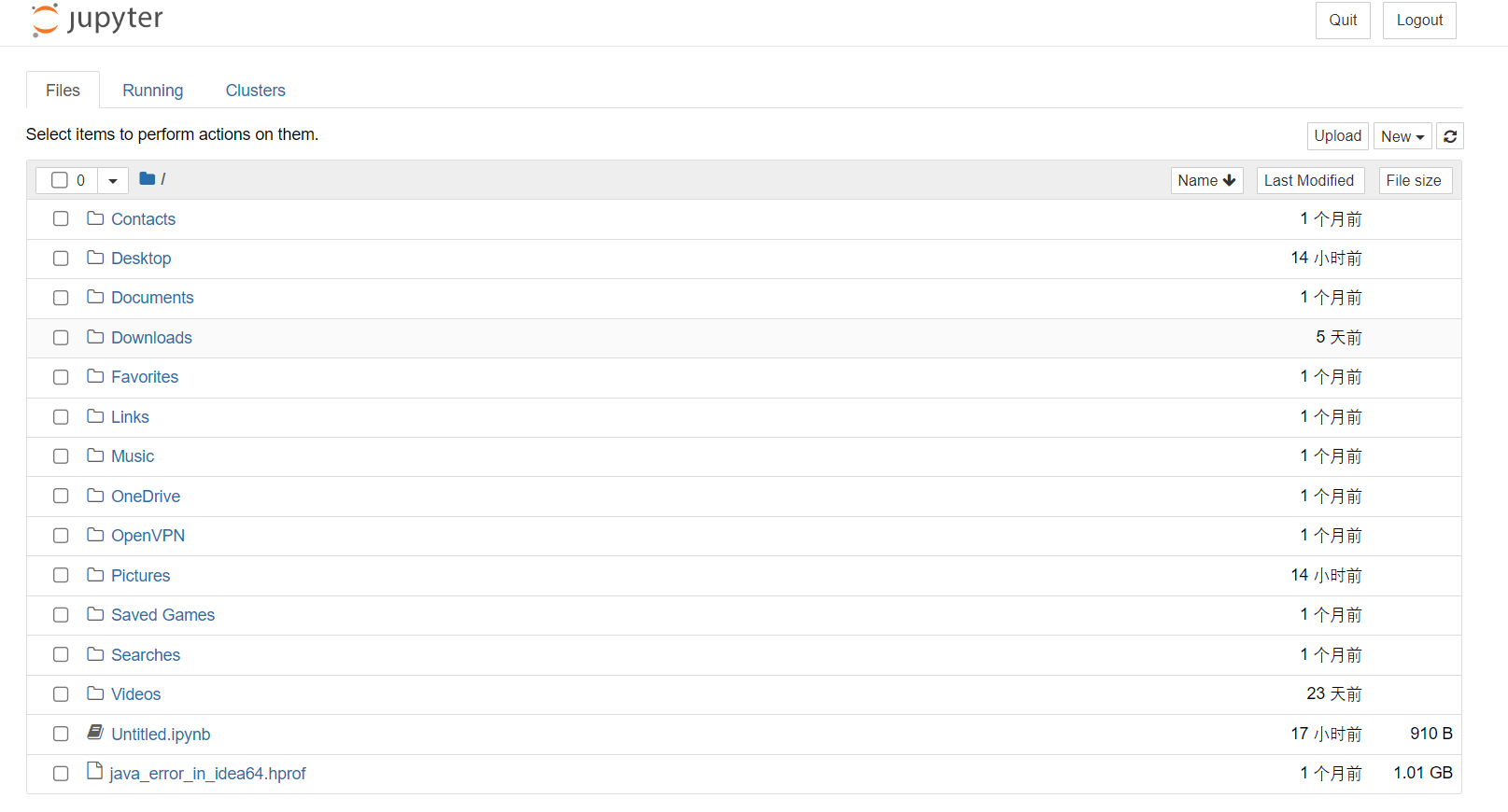 image-20230423113524823 image-20230423113524823新建一个目标文件夹 在你想放这些文件的位置新建一个目录,比如我的目录是:D:\Coding\Jupyter_PyProject 查看配置文件路径 命令窗口输入这行命令,或者在你对应的python环境下的命令窗口输入这行命令,即可查看默认的配置文件位置;但是这条命令虽然可以用于查看配置文件所在的路径,但主要用途是是否将这个路径下的配置文件替换为默认配置文件(相当于重置) 代码语言:javascript复制jupyter notebook --generate-config image-20230423114534766 image-20230423114534766修改配置文件 上面找到了配置文件的位置,现在我们只需要打开这个文件,然后编辑即可;windows比较方便,利用记事本打开可以打开,但是可能找目标代码就有点麻烦了,这里使用notepad++打开;直接Ctrl+F搜索关键字c.NotebookApp.notebook_dir,就可以找到目标代码行了; 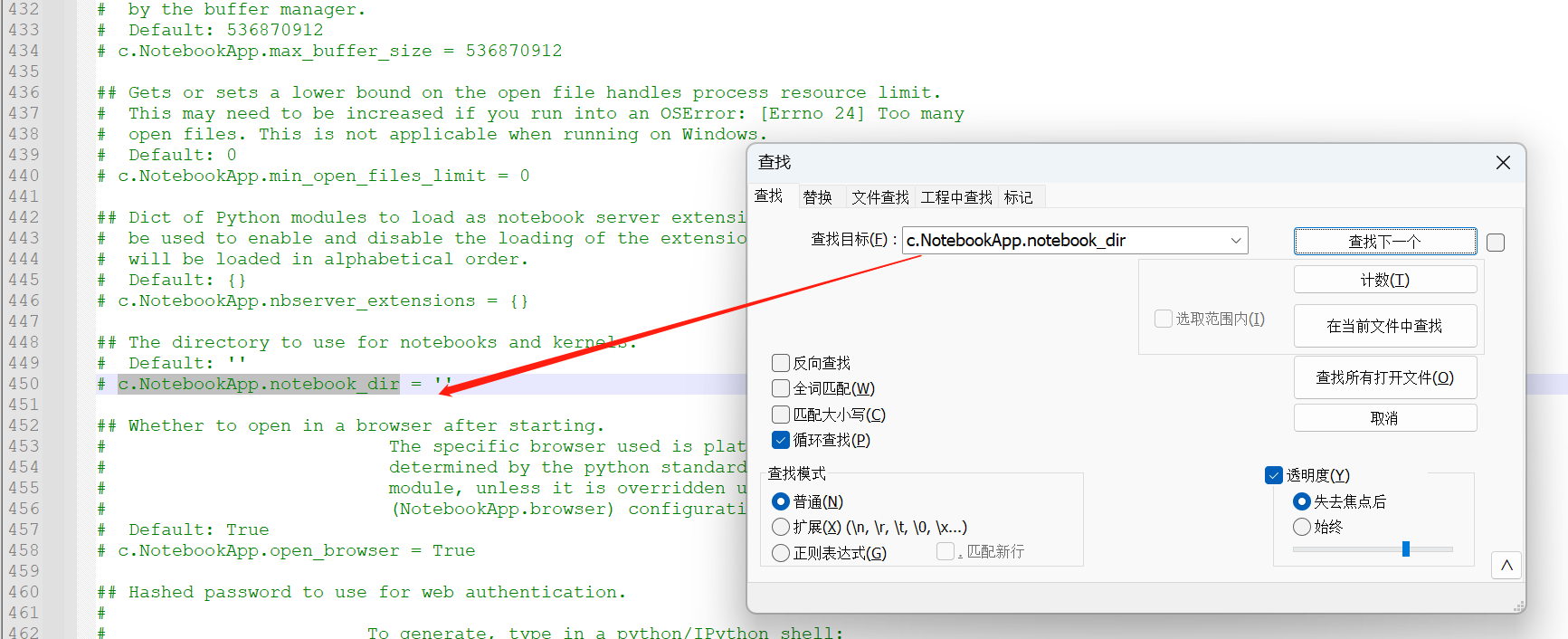 image-20230423115246543 image-20230423115246543找到这行代码后,取消注释,并在单引号内写上事先建好的用来存放文件的目录地址,保存退出; 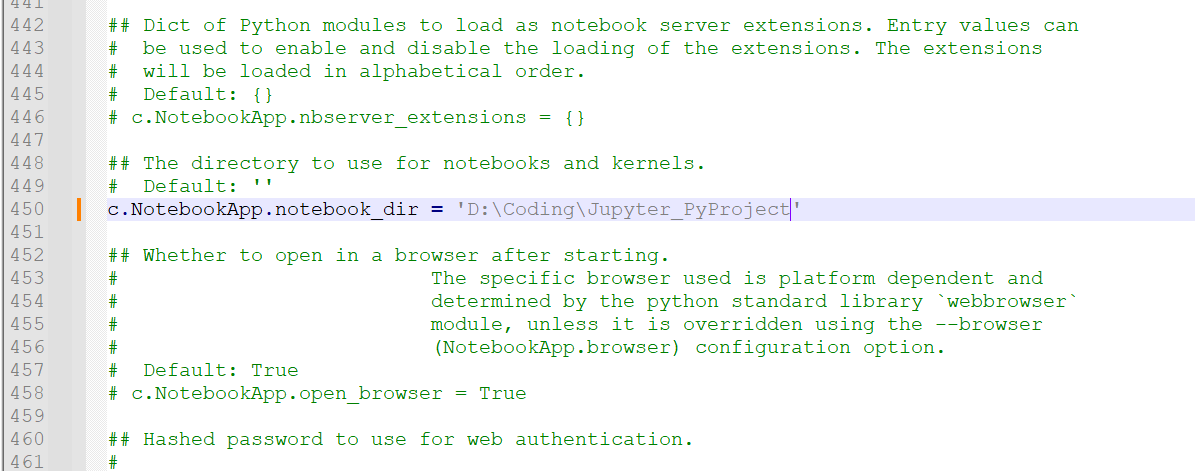 image-20230423115545054 image-20230423115545054重新启动jupyter验证配置情况; 可以看到这里已经修改成功了; 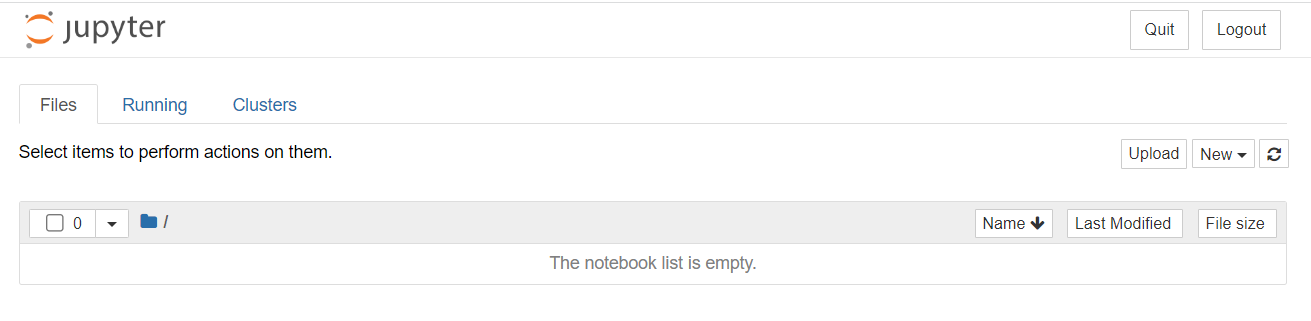 image-20230423133121188 image-20230423133121188这里有个坑 这里要强调一下通过命令打开和通过anaconda安装的时候提供的快捷方式打开,因为这里有坑,当你安装完Anaconda的时候,你会发现利用命令和快捷方式都能打开一个jupyter,这俩打开方式是不一样的,比如修改好了jupyter的启动目录,但是在使用快捷方式打开后,启动目录还是默认的目录;具体的差别请查看下面的Q&A部分; 4.界面功能 Files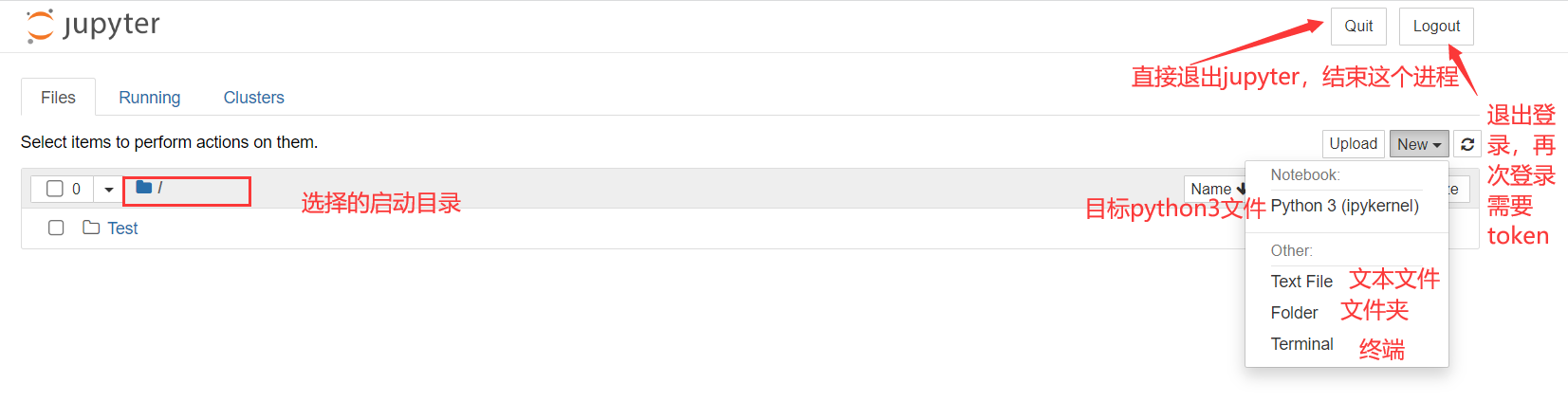 image-20230423214418700 Running
Running tab 显示了当前正在运行的内核和 Jupyter Notebook 进程。具体来说,Running tab 会列出所有当前正在运行的 Notebook,包括它的名称、所在目录、 Noteboook 文件的路径、内核(kernel)的状态、连接的用户以及它的启动时间等信息。
通过 Running tab,您可以方便地查看已经打开的 Notebook,并可以选择以不同的方式关闭它们(关闭 Notebook 不会关闭内核),如停止内核、重启内核、删除 Notebook、打开终端、查看 Notebook 的启动日志等。此外,Running tab 还提供了一些高级功能,如将多个 Notebook 捆绑到单个服务中、配置和管理 Jupyter Notebook 服务器等。 image-20230423214418700 Running
Running tab 显示了当前正在运行的内核和 Jupyter Notebook 进程。具体来说,Running tab 会列出所有当前正在运行的 Notebook,包括它的名称、所在目录、 Noteboook 文件的路径、内核(kernel)的状态、连接的用户以及它的启动时间等信息。
通过 Running tab,您可以方便地查看已经打开的 Notebook,并可以选择以不同的方式关闭它们(关闭 Notebook 不会关闭内核),如停止内核、重启内核、删除 Notebook、打开终端、查看 Notebook 的启动日志等。此外,Running tab 还提供了一些高级功能,如将多个 Notebook 捆绑到单个服务中、配置和管理 Jupyter Notebook 服务器等。
 image-20230423213901301 Clusters
在 Jupyter Notebook 中,Clusters tab 是指 Jupyter notebook 的一个组件,它是 IPython parallel 包提供的一个交互式界面,用于在多台计算机之间分配任务和协调计算。具体来说,Clusters tab 允许用户连接到一个或多个远程 IPython 核心(IPython engines),并在这些核心之间分发计算任务。
在 Clusters tab 中,用户可以通过添加、删除、启动、停止和连接到 IPython 集群来管理集群。一旦连接到集群,用户可以在各个核心之间分配计算任务,以便以最大程度地同时使用多台计算机的 CPU 和内存资源。Clusters tab 还提供了一些额外的功能,如查看集群状态、监控工作负载和任务进度等。
一般不用…
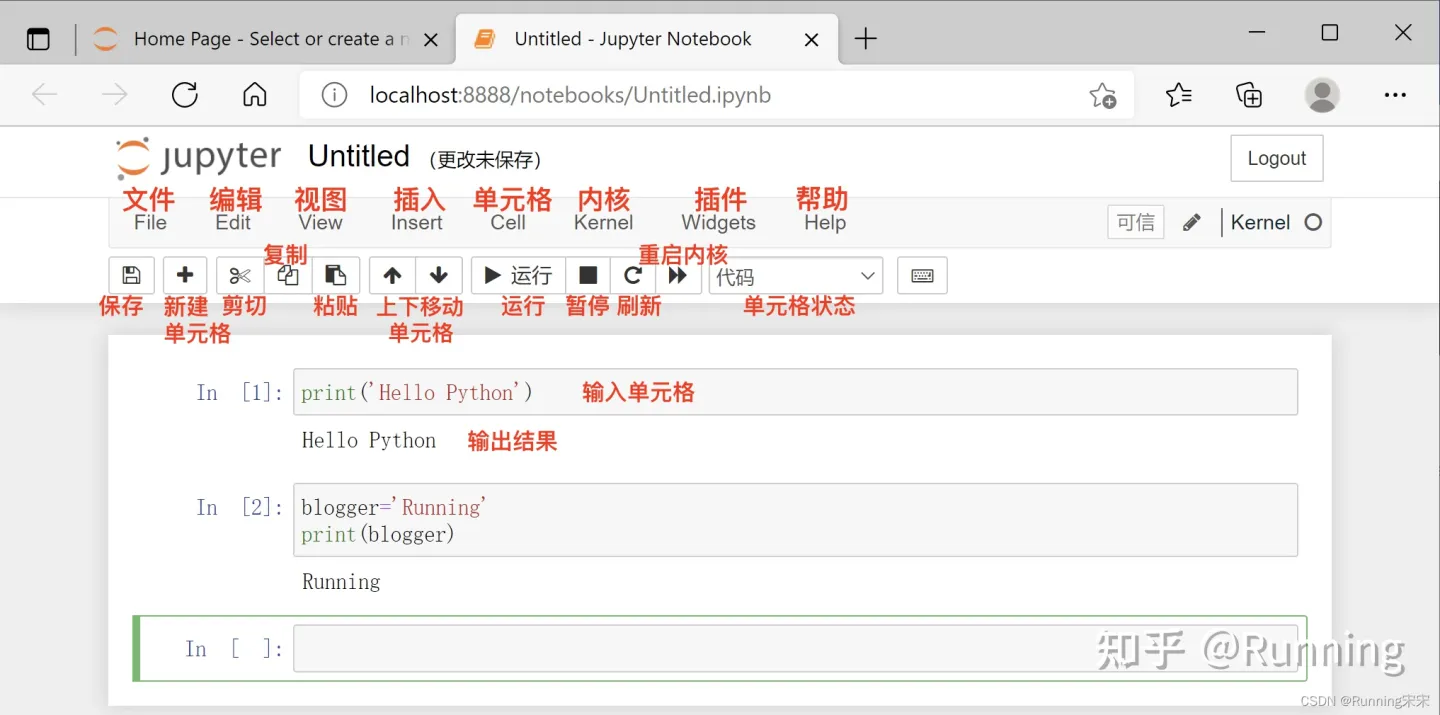
编辑器界面
这里搬运一张其他博主的图片,原文:https://zhuanlan.zhihu.com/p/441668517
其实还是比较清晰的,但是如果你还是不熟悉,就翻译呗,翻译网页就ok了,至于汉化,网上很多办法反正我都没成功。 image-20230423213901301 Clusters
在 Jupyter Notebook 中,Clusters tab 是指 Jupyter notebook 的一个组件,它是 IPython parallel 包提供的一个交互式界面,用于在多台计算机之间分配任务和协调计算。具体来说,Clusters tab 允许用户连接到一个或多个远程 IPython 核心(IPython engines),并在这些核心之间分发计算任务。
在 Clusters tab 中,用户可以通过添加、删除、启动、停止和连接到 IPython 集群来管理集群。一旦连接到集群,用户可以在各个核心之间分配计算任务,以便以最大程度地同时使用多台计算机的 CPU 和内存资源。Clusters tab 还提供了一些额外的功能,如查看集群状态、监控工作负载和任务进度等。
一般不用…
编辑器界面
这里搬运一张其他博主的图片,原文:https://zhuanlan.zhihu.com/p/441668517
其实还是比较清晰的,但是如果你还是不熟悉,就翻译呗,翻译网页就ok了,至于汉化,网上很多办法反正我都没成功。
 img5.主题扩展5.1配置方法 img5.主题扩展5.1配置方法安装 利用pip安装主题扩展 代码语言:javascript复制pip install jupyterthemes加载可用的主题列表 代码语言:javascript复制jt -l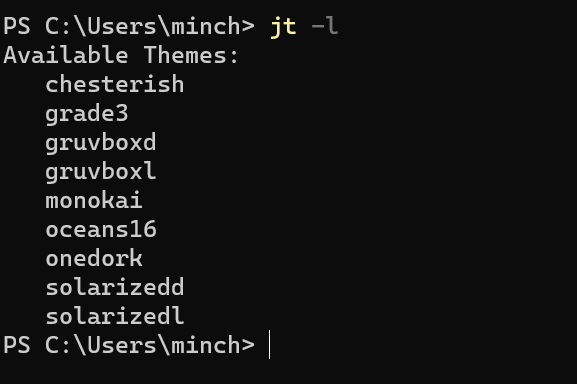 image-20230424024640368 image-20230424024640368应用某个主题 这里的主题名称就是上面主题列表中的主题名,如果命令报错,看下面的解决办法; 代码语言:javascript复制jt -t 主题名称高级的配置 代码语言:javascript复制jt -t 主题名称 -f 字体名称 -fs 字体大小 -cellw 代码单元格宽度 -T 工具栏 -N 笔记本名称详细内容参看官网:https://github.com/dunovank/jupyter-themes 还原默认主题 代码语言:javascript复制jt -rjt命令不可用解决办法 安装jupyter themes之后,运行jt命令,报错如下 代码语言:javascript复制jt : 无法将“jt”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再 试一次。 所在位置 行:1 字符: 1 + jt -l + ~~ + CategoryInfo : ObjectNotFound: (jt:String) [], CommandNotFoundException + FullyQualifiedErrorId : CommandNotFoundException解决办法就是配置一下环境变量,打开环境变量——点击系统变量——点击PATH——新建; 当然这里的路径要和你的本地环境一致; 如果不知道路径的话,可以打开命令窗口;切换到你安装jupyter themes的环境下(你没有安装多个虚拟环境,或者你jupyter就安装在默认的环境下,就不用管),运行pip show jupyterthemes; 最后不要定位到site-packages目录,要定位到Scripts目录; 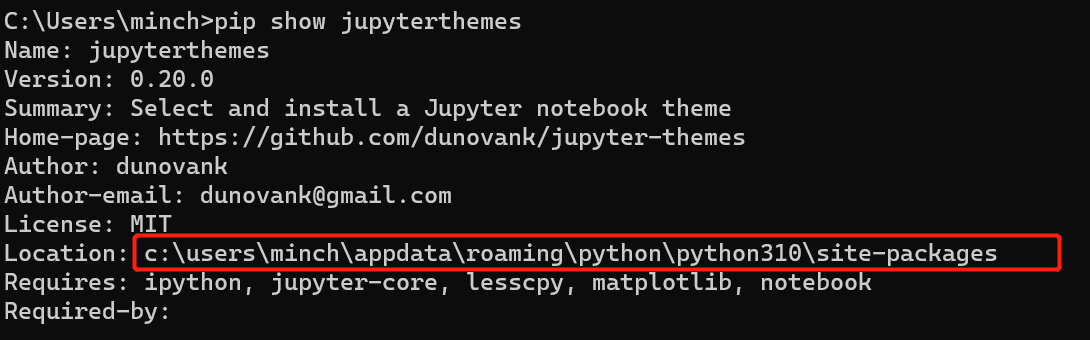 image-20230424115314361 image-20230424115314361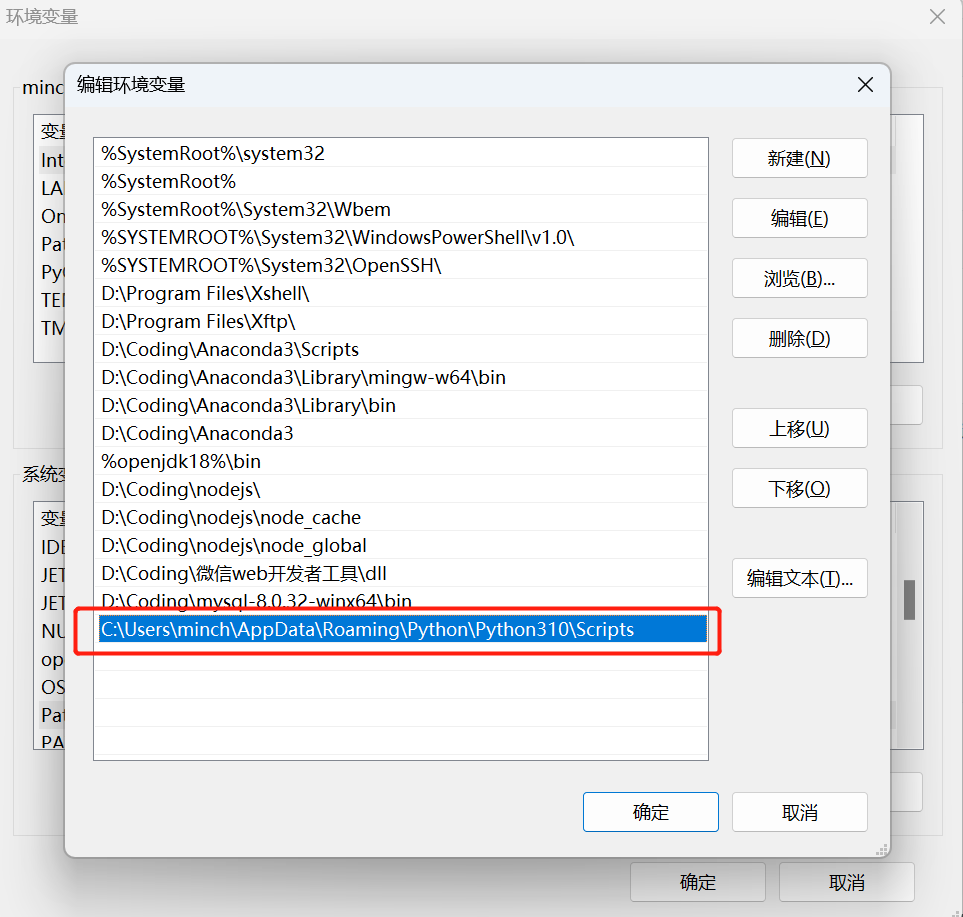 image-202304241146278085.2主题一览 chesterish image-202304241146278085.2主题一览 chesterish
 image-20230424025431263 grade3 image-20230424025431263 grade3
 image-20230424025535652 gruvboxd image-20230424025535652 gruvboxd
 image-20230424025718565 gruvboxl image-20230424025718565 gruvboxl
 image-20230424025811441 monokai image-20230424025811441 monokai
 image-20230424025838515 oceans16 image-20230424025838515 oceans16
 image-20230424025910536 onedork image-20230424025910536 onedork
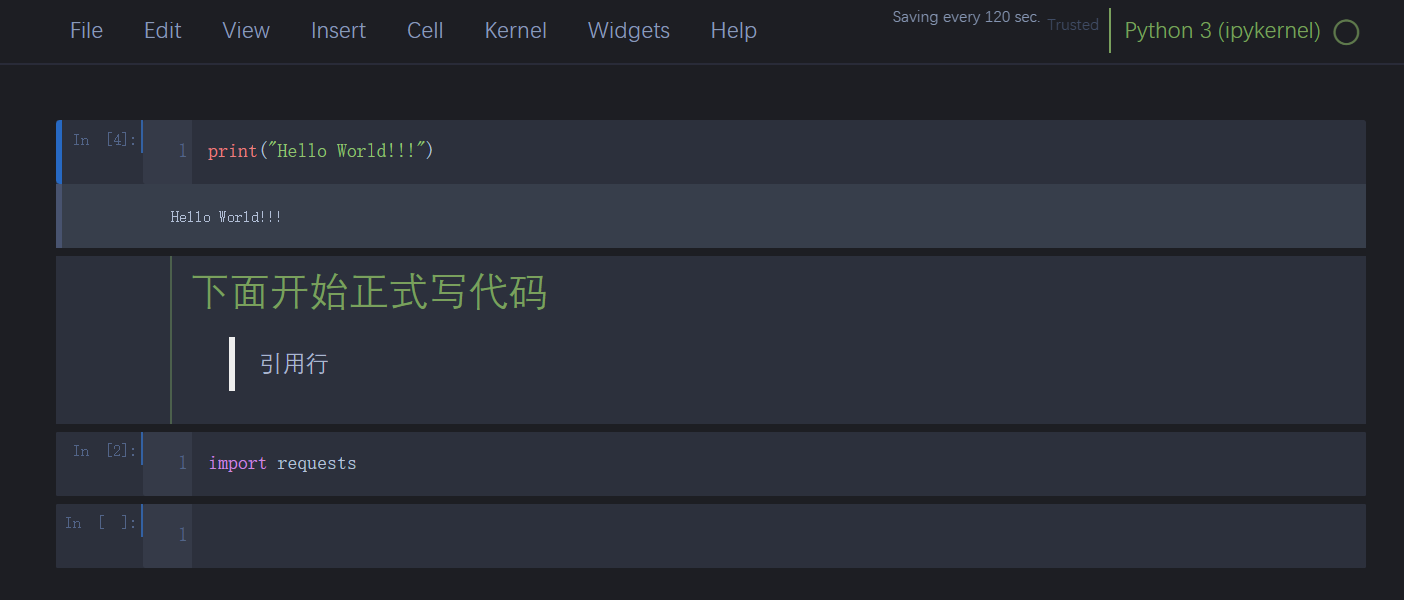 image-20230424025939437 solarizedd image-20230424025939437 solarizedd
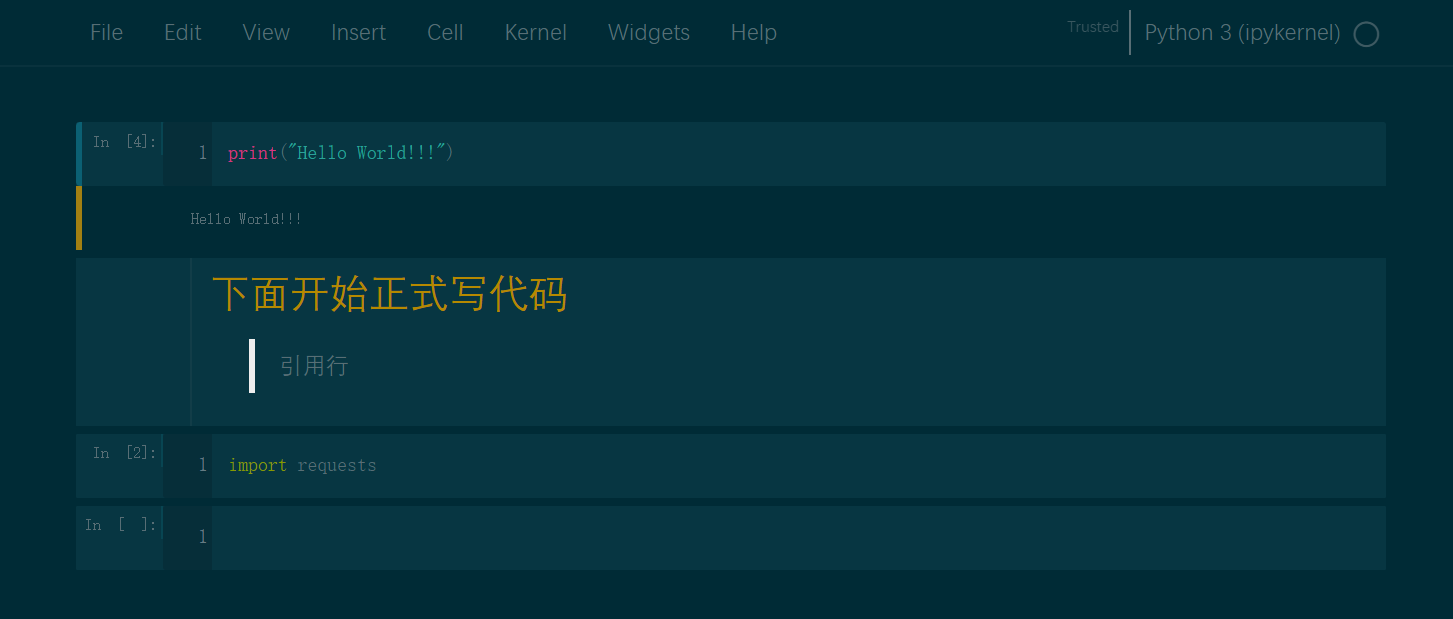 image-20230424030010676 solarizedl image-20230424030010676 solarizedl
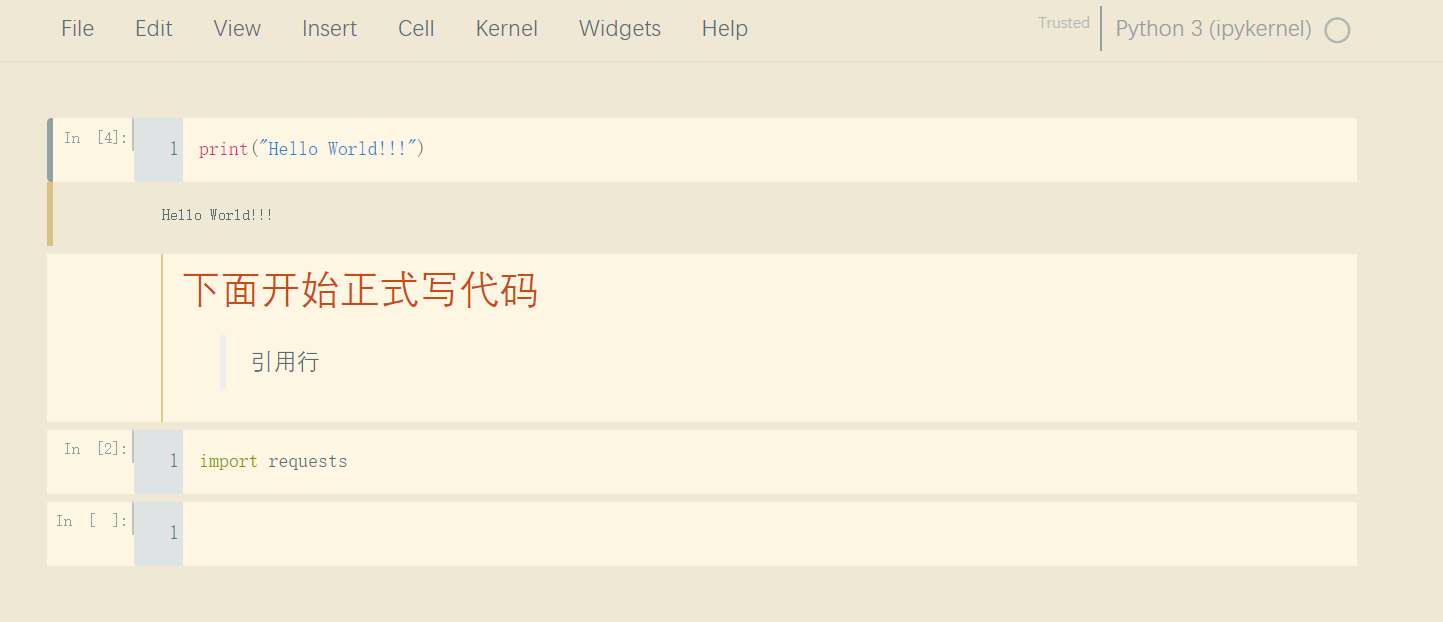 image-202304240300376066功能扩展6.1关联Anaconda环境6.1.1简介与安装 image-202304240300376066功能扩展6.1关联Anaconda环境6.1.1简介与安装nb_conda 是一个 Jupyter Notebook 的插件,它可以在 Notebook 中实现 Conda 环境和包的访问。在 Jupyter 的文件浏览器中, nb_conda 扩展会添加一个 Conda 选项卡,点击该选项卡即可查看已存在的 Conda 环境列表。通过 nb_conda,用户可以轻松地在 Notebook 中创建、使用和分享自己的 Conda 环境。 安装 代码语言:javascript复制conda install nb_conda卸载 代码语言:javascript复制canda remove nb_conda6.1.2使用简介 选择conda导航栏,就能显示anaconda的环境和包了;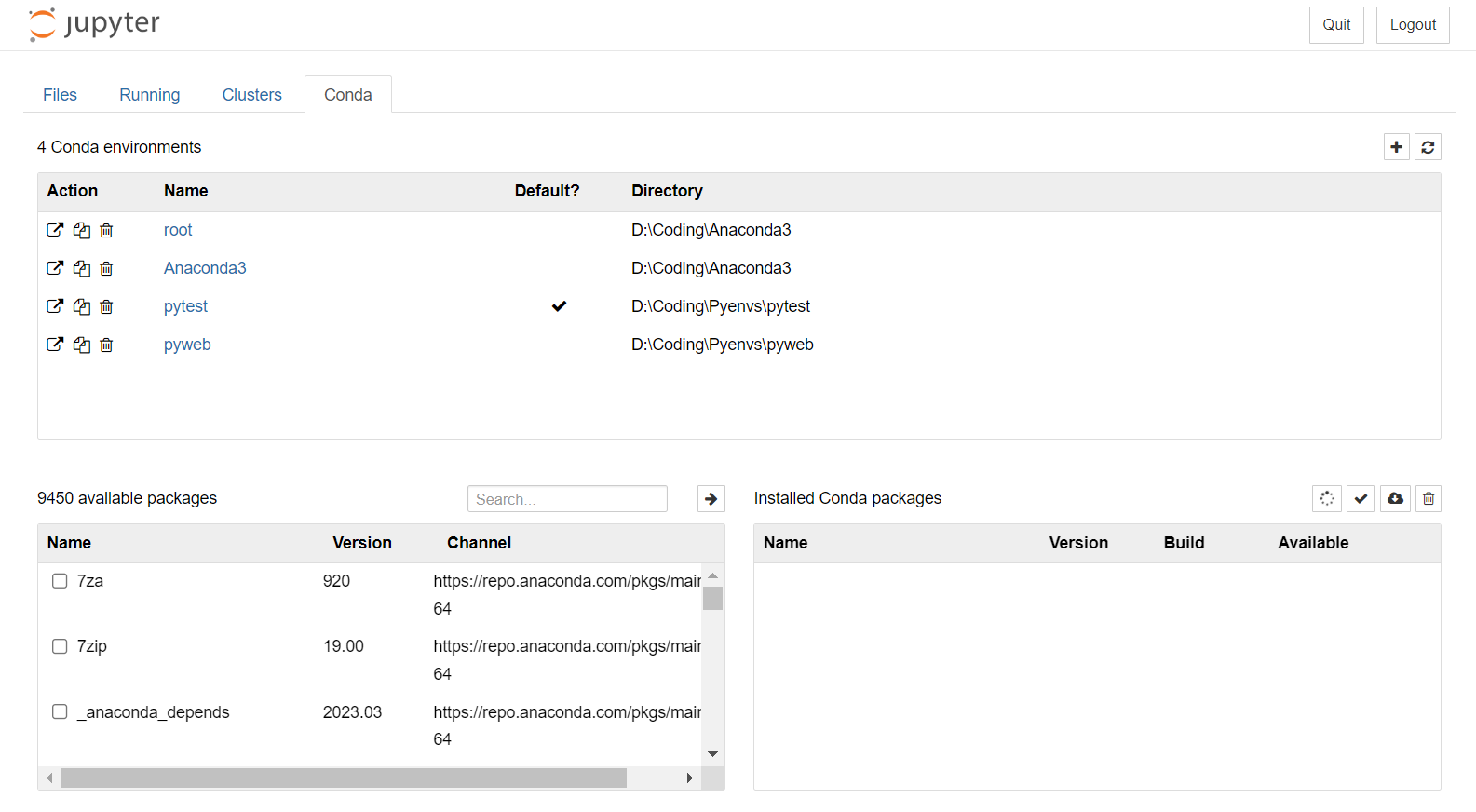 image-20230425203312630 Kernel选择 image-20230425203312630 Kernel选择
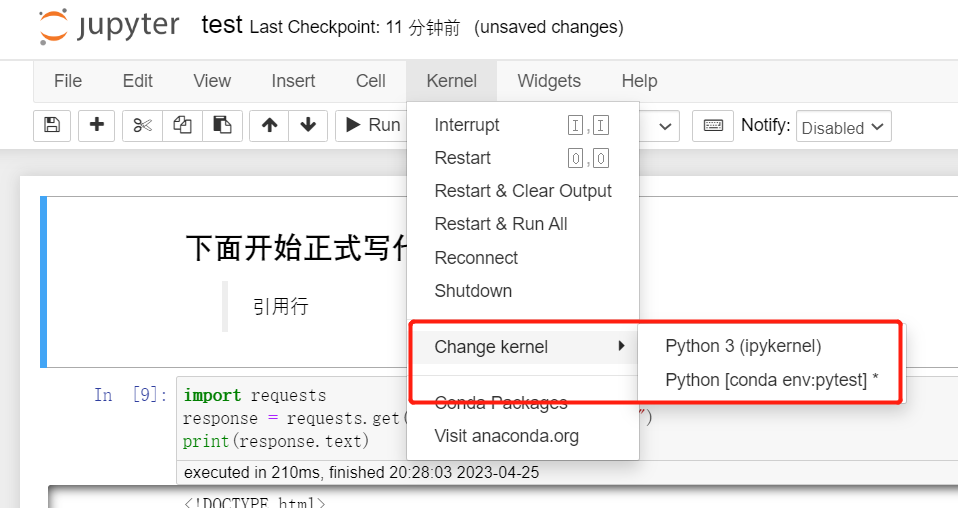 image-202304252035210536.2扩展库6.2.1简介与安装 image-202304252035210536.2扩展库6.2.1简介与安装扩展库一般涉及两个东西,一个就是jupyter_nbextensions_configurator,另一个是jupyter_contrib_nbextensions; jupyter_nbextensions_configurator 是一个用于管理和配置 Jupyter Notebook 的笔记本扩展程序的 GUI 工具。它提供了图形用户界面(GUI)来启用、禁用和配置 Jupyter Notebook 的 nbextensions 扩展程序。它还允许你使用预定义选项来配置这些扩展程序,使其更加符合你的需求。此外,它还提供了一些主题以改变笔记本的样式和交互体验。 jupyter_contrib_nbextensions 则是一组可用于增强 Jupyter Notebooks 功能的扩展程序集合。这些扩展包含多种类型的实用工具,如代码折叠、高亮显示、表格排序、导航栏等等。通过安装 jupyter_contrib_nbextensions,你可以更方便地管理你的笔记本,提高编程效率。需要注意的是,jupyter_contrib_nbextensions 中包括了 nbextensions_configurator 工具。 pip安装 代码语言:javascript复制pip install jupyter_contrib_nbextensions jupyter contrib nbextensions install --user pip install jupyter_nbextensions_configurator jupyter nbextensions_configurator enable --userconda安装 代码语言:javascript复制conda install -c conda-forge jupyter_contrib_nbextensions jupyter contrib nbextension install --user conda install -c conda-forge jupyter_nbextensions_configurator jupyter nbextensions_configurator enable --user安装后发现扩展库里面只有四五个 把扩展库卸载了重新装一遍就行了,建议一行一行的跑命令; pip卸载 pip uninstall jupyter_contrib_nbextensions anaconda卸载 conda remove jupyter_nbextensions_configurator 安装之后,启动jupyter就能看到nbextensions了,要取消图中的选择,才能使用;使用即在对应的扩展前面选中即可; 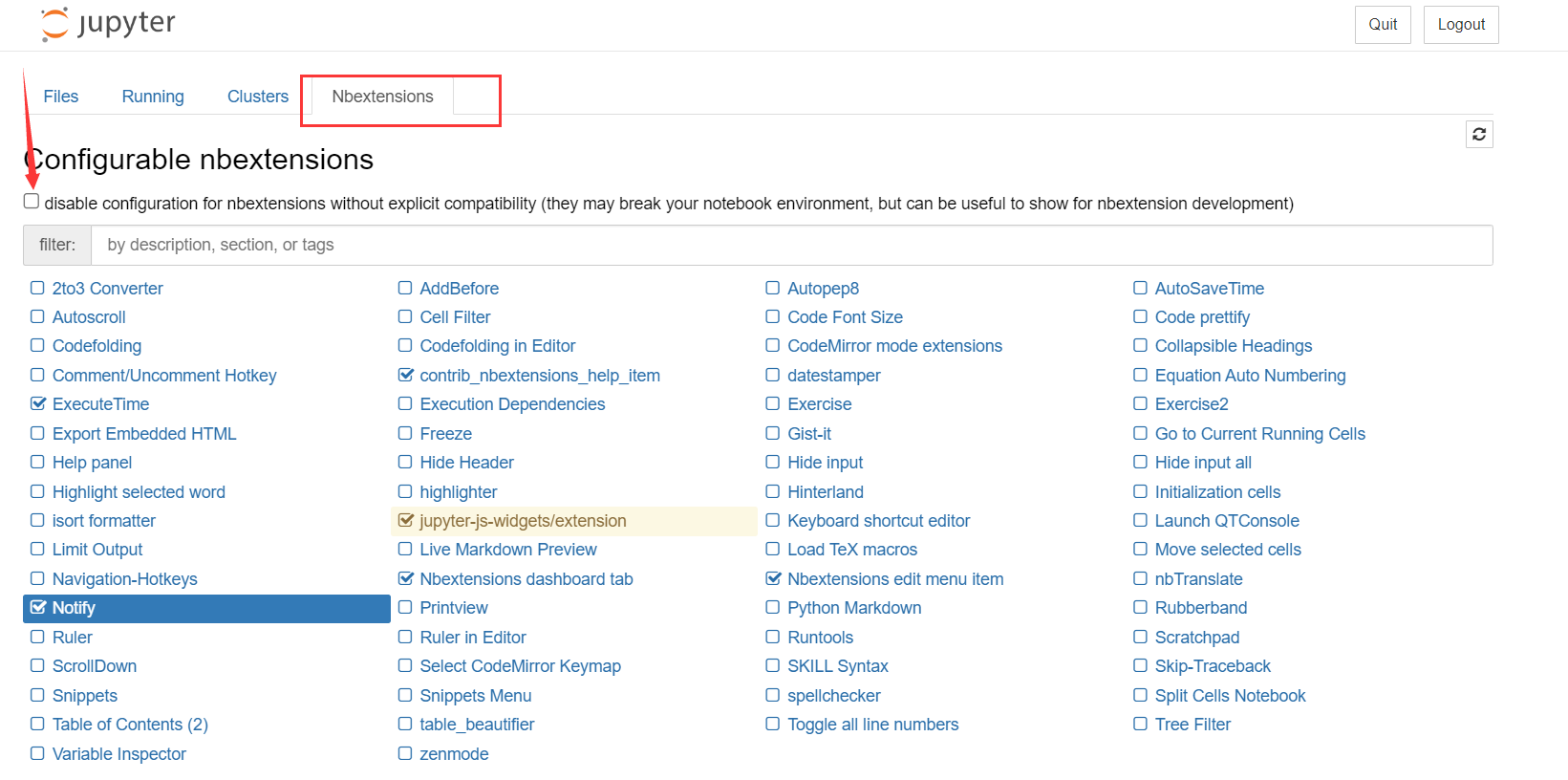 image-202304252029530776.2.1扩展推荐 Table of Contents: 自动生成文档中的目录,方便快速导航和查找内容。[1] image-202304252029530776.2.1扩展推荐 Table of Contents: 自动生成文档中的目录,方便快速导航和查找内容。[1]
 img Collapsible Headings: 折叠和展开单元格标题,节省页面空间并使整个文档更易于导航。[2]
Code Folding: 可以折叠代码单元格中的代码块,有助于隐藏不必要的细节并提高可读性。 [3]
ExecuteTime: 显示代码单元格的执行时间。[4] img Collapsible Headings: 折叠和展开单元格标题,节省页面空间并使整个文档更易于导航。[2]
Code Folding: 可以折叠代码单元格中的代码块,有助于隐藏不必要的细节并提高可读性。 [3]
ExecuteTime: 显示代码单元格的执行时间。[4]
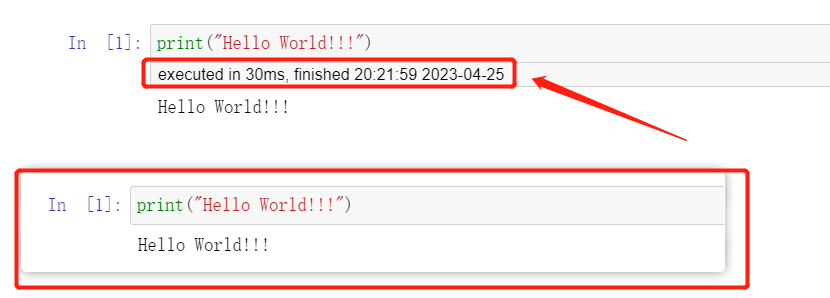 image-20230425202405625 Notify: 当代码执行完成时向浏览器推送通知。[5] image-20230425202405625 Notify: 当代码执行完成时向浏览器推送通知。[5]
部分内容及图片来源:https://cloud.tencent.com/developer/article/2135662 7.基本使用先摆上两个链接,更多详细的内容参看: Jupyter Notebook介绍、安装及使用教程 Jupyter Notebook 的快捷键Jupyter Notebook笔记本的两种模式 命令模式 命令模式将键盘命令与Jupyter Notebook笔记本命令相结合,可以通过键盘不同键的组合运行笔记本的命令。 按esc键进入命令模式。 命令模式下,左侧边框线为蓝色粗线条。 编辑模式 编辑模式使用户可以在单元格内编辑代码或文档。 编辑模式下,单元格边框和左侧边框线均为绿色。 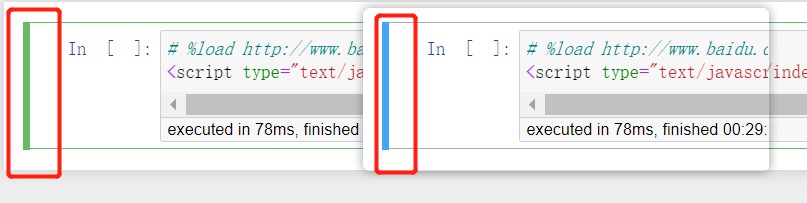 image-20230426004005339 image-20230426004005339删除单元格快捷方式:进入命令模式后双击D键 恢复单元格:进入命令模式后按Z键 Shift-Enter : 运行本单元,选中下个单元 Ctrl-Enter : 运行本单元 Alt-Enter : 运行本单元,在其下插入新单元 加载指定位置源代码 想要在Jupyter Notebook中直接加载指定位置的源代码到笔记本中; 输入以下命令运行即可加载,运行完之后,代码会加载到单元格内,该命令会被注释; 代码语言:javascript复制%load URL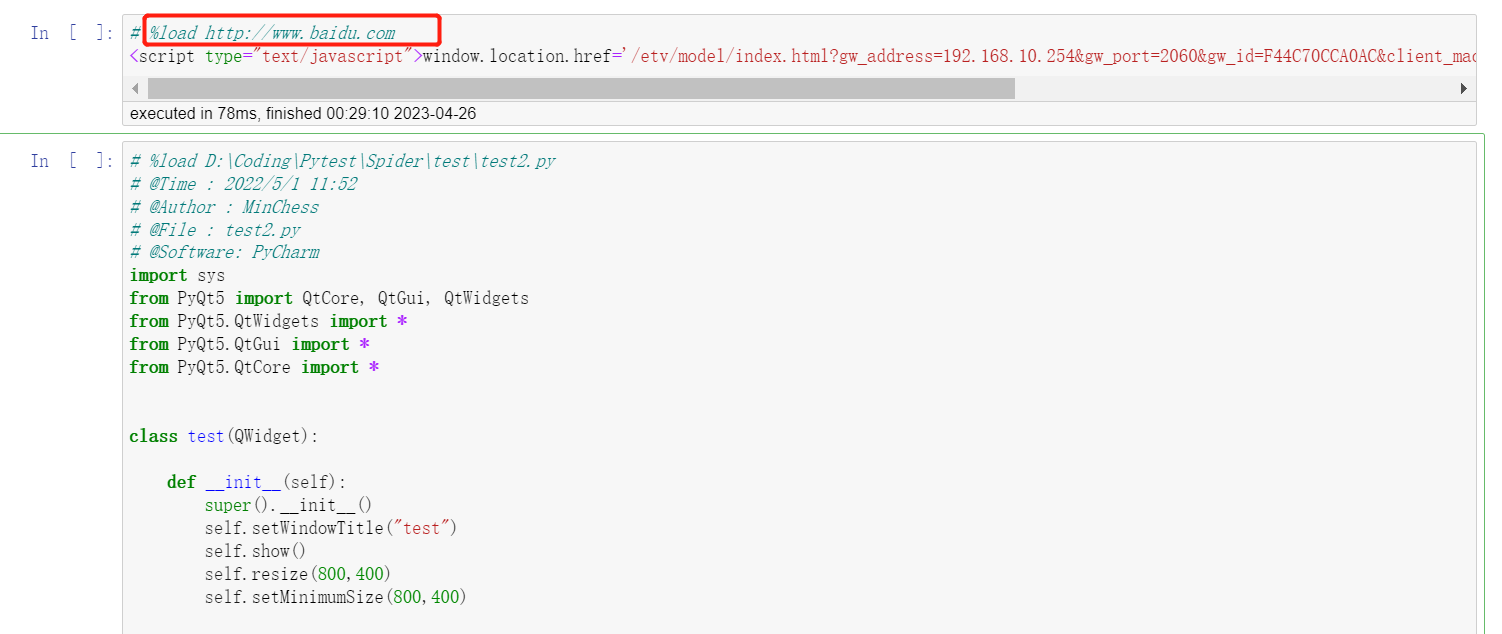 image-20230426003030312 image-20230426003030312更多魔术命令 上面就是魔术命令的一个应用,其他的还有类似获取当前文件位置的命令等等,更多内容参考官网:https://ipython.readthedocs.io/en/stable/interactive/magics.html 8.实战8.1一个简单的绘图代码语言:javascript复制#!/usr/bin/env python # coding: utf-8 # In[1]: import pandas as pd import numpy as np import matplotlib.pyplot as plt # In[2]: # 创建测试数据 df = pd.DataFrame({ 'year': [2016, 2017, 2018, 2019, 2020], 'sales': [100, 130, 150, 170, 200] }) # In[3]: # 绘制柱状图 plt.bar(df['year'], df['sales'], color='blue') plt.xlabel('Year') plt.ylabel('Sales') plt.title('Sales over Year') plt.show() # In[ ]:三个单元格分别导入包、创建测试数据、绘图; 运行需要严格按顺序执行; 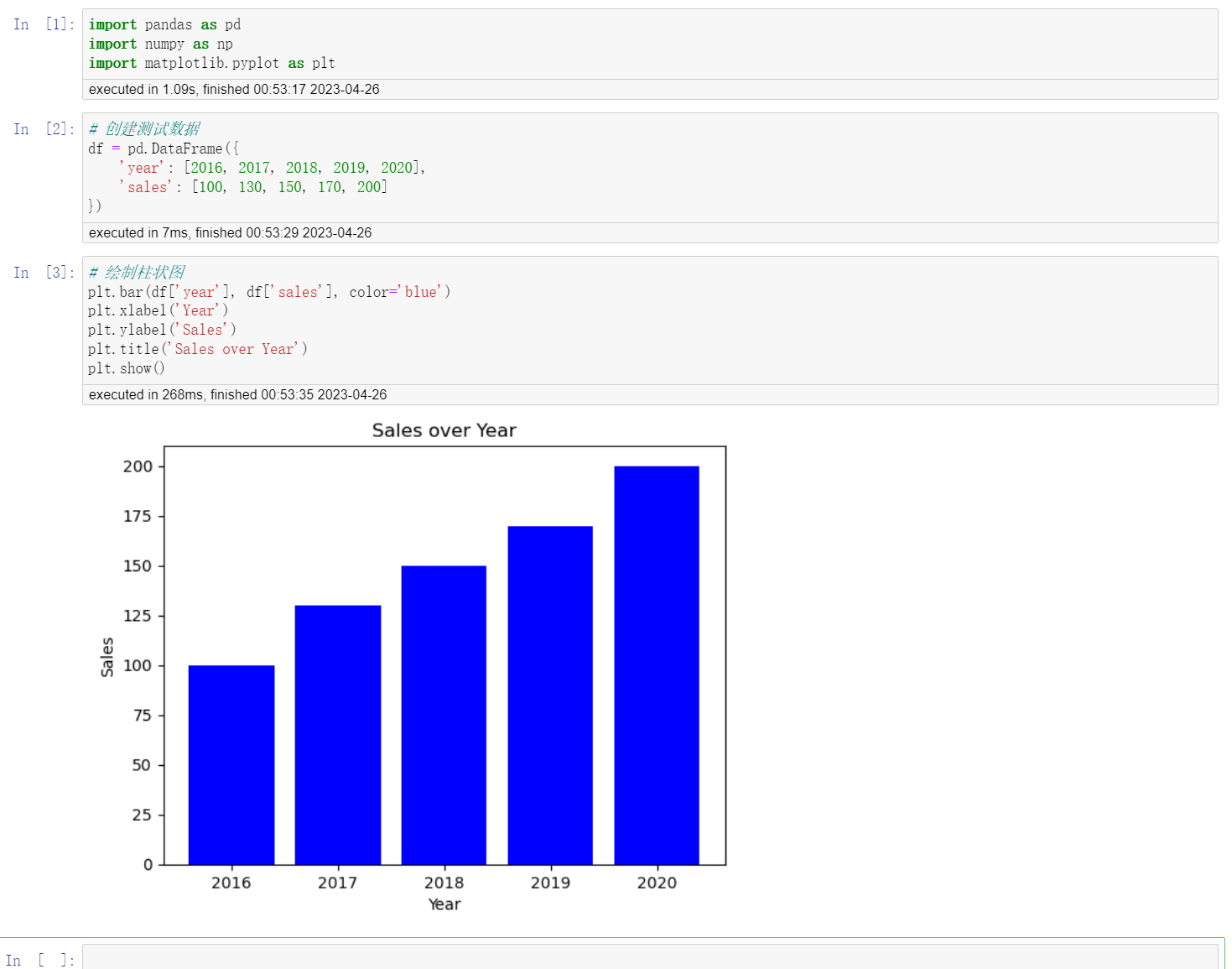 image-202304260054083788.1爬取微博热搜代码语言:javascript复制#!/usr/bin/env python
# coding: utf-8
# In[7]:
import requests
from bs4 import BeautifulSoup
import time
# In[18]:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'Cookie':'SUB=_2AkMTf37Hf8NxqwJRmPAVyG7jbol0wwrEieKlI48cJRMxHRl-yT9vqlYOtRB6OP9QKBlDDjMdGlMFok5NIqGTLxEXHcGr; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5UiecUPRV2SWjRzBIq2X0V; SINAGLOBAL=618205954960.4446.1681196722663; UOR=www.baidu.com,weibo.com,tophub.today; _s_tentry=-; Apache=5834475057987.334.1682445226156; ULV=1682445226181:3:3:1:5834475057987.334.1682445226156:1681202990452; XSRF-TOKEN=WKel-EKSczosZuoOMXKVIH9H; WBPSESS=durPiJxsbzq5XDaI2wW0N0pbOd3fbV1w3XF-VOcj7XTJ8vDiYa5jmFydo3U2yLd3wSJp3fMJK1n5h3EzWFi1ruvJTHRYOs9aoG4rZ64JjMz9qH5LbEnhw5Cxomz5i-gj'
}
url = 'https://s.weibo.com/top/summary'
# In[19]:
try:
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
print(response.text)
else:
print(f'Request failed with status code {response.status_code}')
except RequestException as e:
print(e)
# In[20]:
response_html = response.text
# In[21]:
soup = BeautifulSoup(response_html, 'lxml')
# In[22]:
hot_list = []
# In[23]:
items = soup.select('tbody > tr')
# In[31]:
for item in items:
hot_title = item.select_one('.td-02 > a').get_text(strip=True)
hot_url = 'https://s.weibo.com' + item.select_one('.td-02 > a')['href']
hot_item = {
'hot_title': hot_title,
'hot_url': hot_url
}
hot_list.append(hot_item)
# In[43]:
for i in range(len(hot_list)):
if i image-202304260054083788.1爬取微博热搜代码语言:javascript复制#!/usr/bin/env python
# coding: utf-8
# In[7]:
import requests
from bs4 import BeautifulSoup
import time
# In[18]:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'Cookie':'SUB=_2AkMTf37Hf8NxqwJRmPAVyG7jbol0wwrEieKlI48cJRMxHRl-yT9vqlYOtRB6OP9QKBlDDjMdGlMFok5NIqGTLxEXHcGr; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5UiecUPRV2SWjRzBIq2X0V; SINAGLOBAL=618205954960.4446.1681196722663; UOR=www.baidu.com,weibo.com,tophub.today; _s_tentry=-; Apache=5834475057987.334.1682445226156; ULV=1682445226181:3:3:1:5834475057987.334.1682445226156:1681202990452; XSRF-TOKEN=WKel-EKSczosZuoOMXKVIH9H; WBPSESS=durPiJxsbzq5XDaI2wW0N0pbOd3fbV1w3XF-VOcj7XTJ8vDiYa5jmFydo3U2yLd3wSJp3fMJK1n5h3EzWFi1ruvJTHRYOs9aoG4rZ64JjMz9qH5LbEnhw5Cxomz5i-gj'
}
url = 'https://s.weibo.com/top/summary'
# In[19]:
try:
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
print(response.text)
else:
print(f'Request failed with status code {response.status_code}')
except RequestException as e:
print(e)
# In[20]:
response_html = response.text
# In[21]:
soup = BeautifulSoup(response_html, 'lxml')
# In[22]:
hot_list = []
# In[23]:
items = soup.select('tbody > tr')
# In[31]:
for item in items:
hot_title = item.select_one('.td-02 > a').get_text(strip=True)
hot_url = 'https://s.weibo.com' + item.select_one('.td-02 > a')['href']
hot_item = {
'hot_title': hot_title,
'hot_url': hot_url
}
hot_list.append(hot_item)
# In[43]:
for i in range(len(hot_list)):
if i |
【本文地址】
今日新闻 |
推荐新闻 |