大数据技术原理与应用 概念、存储、处理、分析和应用(林子雨) |
您所在的位置:网站首页 › nosql数据库应用场景 › 大数据技术原理与应用 概念、存储、处理、分析和应用(林子雨) |
大数据技术原理与应用 概念、存储、处理、分析和应用(林子雨)
|
第五章 NoSQL数据库
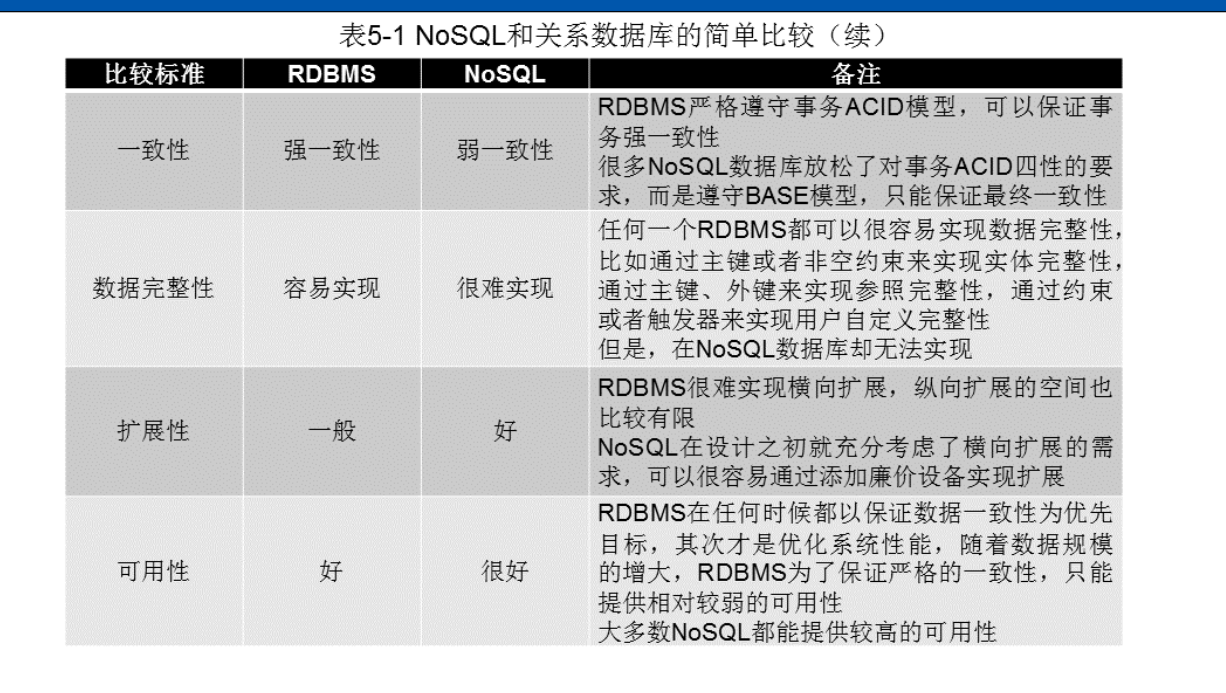
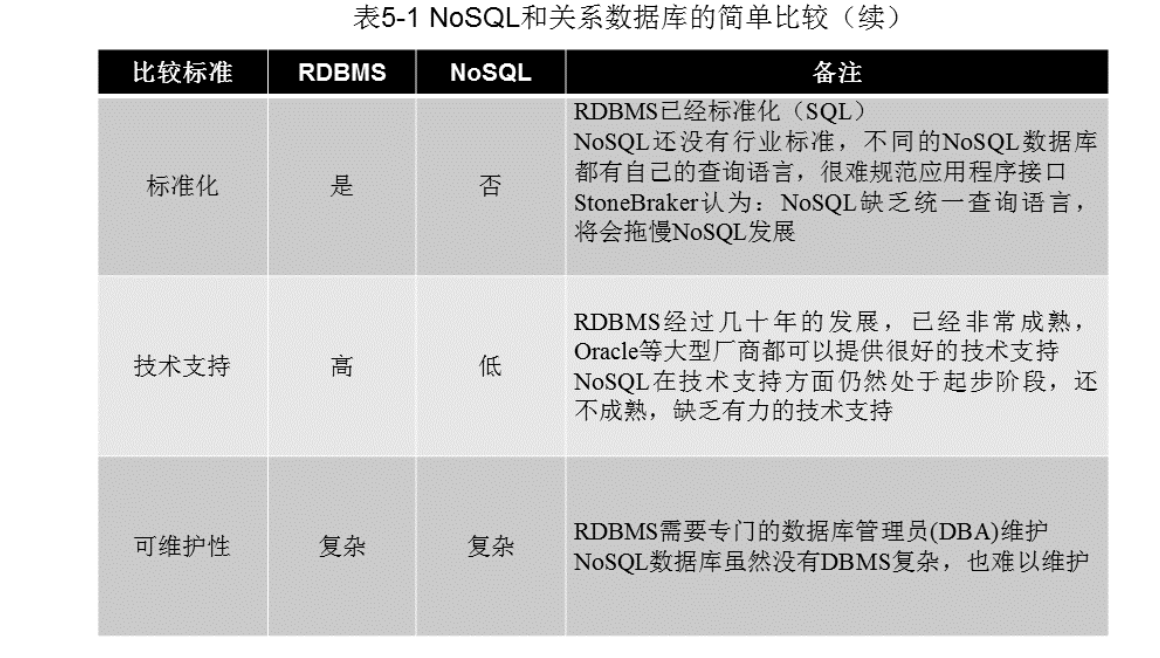
NoSQL(Not Only SQL)是指非关系型数据库,它的出现是为了解决关系型数据库在某些场景下的不足。NoSQL数据库相对于传统的关系型数据库,具有更高的可扩展性、更好的性能、更灵活的数据模型以及更低的成本等优势。 在传统的关系型数据库中,数据被存储在严格的表结构中,这样的结构导致关系型数据库在处理大规模数据、高并发访问等场景时,面临很大的挑战。NoSQL数据库则采用了更加灵活的数据模型,可以根据具体的业务需求选择适合的数据存储方式,如键值对、文档、图形等,这样可以更好地应对不同场景下的数据处理需求。 此外,NoSQL数据库通常采用分布式架构,能够轻松地实现横向扩展,即通过增加节点的方式扩展数据库的容量和性能,这样可以有效地应对大规模数据的存储和访问需求。同时,NoSQL数据库通常具有更好的读写性能,能够快速地处理海量的数据请求。 总之,NoSQL数据库的兴起,是为了更好地应对现代大数据、高并发、分布式等需求的产物。随着技术的不断发展和应用场景的不断扩展,NoSQL数据库在未来的发展前景将会越来越广阔。 5.1 NoSQL简介NoSQL(Not only SQL)是一个非关系型数据库技术的统称,它与传统的关系型数据库(如MySQL、Oracle等)不同,不需要遵循固定的表结构和数据模型,数据以键值对、文档形式或图形结构等形式存储。NoSQL数据库通常可以处理非结构化和半结构化数据,这使得它们在大数据领域的处理能力得到了广泛应用。 NoSQL数据库的兴起源于Web 2.0时代,随着互联网的普及和移动互联网的发展,数据量和种类都变得更加庞大和多样化,传统的关系型数据库在应对这种情况时显得力不从心。NoSQL数据库由于其高可扩展性、高性能和灵活性等优点,在互联网公司和大数据应用场景中得到了广泛的应用和推广。 常见的NoSQL数据库包括MongoDB、Cassandra、Redis、HBase等。每种NoSQL数据库都有其独特的特点和适用场景,开发人员需要根据具体应用场景来选择合适的数据库。 通常NoSQL数据库具有以下三个特点: 灵活的可扩展性:NoSQL数据库通常被设计为可以轻松扩展到更多的机器和节点,以满足数据存储和访问的需求。这种可扩展性基于分布式架构和水平扩展的概念,可以使NoSQL数据库支持大规模的数据存储和高并发访问。 灵活的数据模型:相比于传统的关系型数据库,NoSQL数据库通常采用更加灵活的数据模型,例如键值对、文档型、列型、图型等,使得用户可以更加方便地存储和查询不同类型的数据。 与云计算紧密结合:NoSQL数据库通常被设计为与云计算平台紧密结合,以便用户可以轻松地在云上部署和管理数据库实例。例如,NoSQL数据库可以采用分布式的架构,使用虚拟机或容器来实现弹性扩展和故障转移,并提供自动备份和恢复等功能。这些特性可以帮助用户更好地利用云计算的优势,提高数据库的可用性和性能。 5.2 NoSQL兴起的原因关系数据库是指采用关系数据模型的数据库,最早由图灵奖得主、有“关系数据库之父”之称的埃德加·弗兰克·科德于1970年提出。由于具有规范的行和列结构,因此存储在关系数据库中的数据通常也被称为“结构化数据”,用来查询和操作关系数据库的语言被称为“结构化查询语言”。由于关系数据库具有完备的数学理论基础、完善的事务管理机制和高效的查询处理引警因此在社会生产和生活中得到了广泛的应用,并从20世纪70年代到21世纪前10年直占据商业数据库应用的主流的位置。目前主流的关系数据库有 Oracle、DB2、SOL Server、Sybase、MySOL等。 尽管数据库的事务和查询机制较好地满足了银行、电信等各类商业公司的业务数据管理需求但是随着 Web 2.0的兴起和大数据时代的到来,关系数据库已经显得越来越力不从心,暴露出越来越多难以克服的缺陷。于是 NoSOL数据库应运而生,它很好地满足了 Web 2.0的需求,得到了市场的青睐。 5.2.1 关系数据库无法满足 Web 2.0的需求关系数据库无法满足 Web 2.0 的需求,主要表现在以下三个方面: 大规模数据的存储和处理:Web 2.0 时代互联网上的数据量呈爆炸式增长,传统关系数据库面对如此大规模的数据存储和处理变得力不从心。关系数据库采用的是固定的表格和预定义的模式,随着数据量的增加,需要对表格进行分区和分片,这种方法增加了数据库的复杂性和管理成本。 高并发读写请求:Web 2.0 时代互联网的用户数和数据量都呈现指数级增长,关系数据库在高并发读写请求下性能不足。由于关系数据库采用的是 ACID 事务模型,每个操作都需要先获取锁,进行磁盘 I/O 操作,再释放锁,这种锁机制会导致数据库的性能瓶颈。 低廉的硬件成本:Web 2.0 时代随着硬件成本的降低,存储海量数据的硬件设备已经不再昂贵,可以通过横向扩展的方式来处理大量数据和高并发请求。而关系数据库的垂直扩展成本较高,无法有效地利用廉价的硬件设备,难以实现横向扩展。 5.2.2 关系型数据库的关键特性在WEB 2.0时代称为“鸡肋”关系数据库的关键特性包括完善的事务机制和高效的查询机制。 高度规范化的数据结构难以应对复杂的数据需求:传统的关系型数据库需要在设计时对数据进行高度规范化,即将数据分解为不同的表,通过外键建立关联。然而,在WEB 2.0时代,数据需求越来越复杂,需要存储的数据类型也更加多样化,这导致关系型数据库在存储和查询数据方面遇到了很大的挑战。 严格的数据模式难以应对数据结构的变化:关系型数据库需要先定义好数据模式(Schema),即表结构、字段、数据类型等等,这使得数据结构的变化变得非常困难。在WEB 2.0时代,数据需求的变化速度非常快,需要对数据模式进行频繁的修改,而关系型数据库的严格数据模式限制了其灵活性。 传统的垂直扩展难以满足横向扩展的需求:关系型数据库通常采用垂直扩展的方式来提高性能,即通过增加更多的硬件资源来增加数据库的处理能力。然而,在WEB 2.0时代,数据量的增长速度非常快,垂直扩展的成本也越来越高。因此,需要采用横向扩展的方式,即通过增加更多的节点来扩展数据库的处理能力,以应对数据量的快速增长。 5.3 NOSQL 与关系数据库的比较关系数据库与NoSQL数据库各有优缺点,具体比较如下: 关系数据库优点: 数据一致性:关系型数据库支持ACID事务,能够确保数据的一致性和可靠性。 数据模型:关系型数据库采用表格数据模型,适合于结构化数据的存储和查询,且支持SQL语言,查询灵活性较高。 应用场景:关系型数据库适用于数据量相对较小、数据结构较为简单的应用场景,例如企业内部管理系统、金融系统等。 NoSQL数据库优点: 数据模型:NoSQL数据库支持多种数据模型,如键值、文档、列族、图形等,具有更好的灵活性,能够适应各种场景的数据存储和处理。 可扩展性:NoSQL数据库容易水平扩展,支持分布式架构,能够应对高并发、海量数据场景。 性能表现:NoSQL数据库在处理大量数据和高并发场景下表现更加优秀,能够提供更快的数据处理和查询速度。 应用场景:NoSQL数据库适用于数据量大、数据结构复杂的应用场景,例如互联网应用、物联网应用等。 关系数据库缺点: 不易扩展:关系型数据库不易水平扩展,需要垂直扩展,成本较高。 性能问题:随着数据量的增加,关系型数据库的性能会逐渐下降,查询速度变慢。 数据结构限制:关系型数据库只支持表格数据模型,不适用于非结构化数据存储和处理。 NoSQL数据库缺点: 数据一致性问题:NoSQL数据库支持eventual consistency和strong consistency两种模型,其中eventual consistency模型会牺牲一定的数据一致性来提高系统性能。 不支持ACID事务处理:NoSQL数据库不支持ACID事务处理,不能确保数据的一致性和可靠性。 学习成本:NoSQL数据库种类繁多,不同类型的数据库具有不同的数据模型和操作方式,需要学习成本。 
 5.4 NoSQL的四大类型
5.4 NoSQL的四大类型
一般将NoSQL数据库分为四大类:键值(Key-Value)存储数据库、列存储数据库、文档型数据库和图形(Graph)数据库。 5.4.1 键值数据库介绍 键值数据库(Key-Value Database)是一种基于键值对的 NoSQL 数据库,它将数据存储为键值对的形式,其中键(key)是一个唯一标识符,而值(value)则是与之相关联的数据。键值数据库最初被用于缓存和持久存储应用程序中的数据,如网站会话信息和计数器。随着大数据和云计算时代的到来,键值数据库得到了广泛的应用和推广。 作用 键值数据库的主要作用是提供一个快速、高效的数据存储和检索机制。它们通常采用内存存储和哈希表来加速对数据的访问。键值数据库可以用于缓存、计数器、分布式锁、队列等场景,其快速的读写性能和高可用性使其成为互联网应用程序中重要的组成部分。 产品 一些常见的键值数据库产品包括 Redis、Memcached、Riak等。其中 Redis 是最流行的键值数据库之一,它支持丰富的数据结构和功能,如字符串、哈希表、列表、集合等,并提供了丰富的操作命令和扩展插件。 应用场景 键值数据库的典型应用场景包括缓存、存储会话信息、计数器、消息队列、配置存储等。它们在处理高并发、大流量、海量数据的应用场景下表现出色。 优缺点 键值数据库的优点包括读写性能高、扩展性好、数据结构简单、支持高并发等。其缺点则包括数据查询能力较弱、不支持关系型数据模型、数据安全性较弱等。 使用者 使用键值数据库的用户包括互联网公司、移动应用程序开发者、游戏开发者等。其中,互联网公司中广泛使用 Redis 和 Memcached 来提高系统性能和响应速度。移动应用程序开发者和游戏开发者也使用键值数据库来提供快速的数据访问和实时性的数据更新。 5.4.2 列族数据库介绍 列族数据库(Column Family Database)是NoSQL数据库的一种,也被称为“列式存储数据库”(Column-Oriented Database),是按列存储数据而不是按行存储数据的一种数据库类型。与关系型数据库的表格模型不同,列族数据库中数据是按列族存储,每个列族包含多个列,每个列又包含多行数据。这种存储方式使得列族数据库在读取某个列族数据时可以提高效率,同时可以灵活添加或删除列。 作用 列族数据库的主要作用是处理大规模数据的存储和查询。相较于传统的关系型数据库,列族数据库更适合于存储非结构化数据和海量数据。列族数据库通常使用分布式架构进行数据存储和处理,因此在处理海量数据时具有很好的扩展性。 产品 常见的列族数据库产品包括Apache Cassandra、HBase、Amazon DynamoDB等。其中,Apache Cassandra是最为知名的列族数据库之一,它具有高可用性、高扩展性、分布式架构和自动数据分区等特点,被广泛应用于分布式系统和大规模数据存储。 应用 列族数据库的典型应用包括日志存储、社交网络数据存储、实时分析等。例如,Cassandra被用于存储Facebook的消息数据,HBase被用于存储Twitter的实时推文数据。 优缺点 列族数据库的优点包括:高扩展性、高性能、数据模型灵活、支持海量数据存储和处理等。同时,列族数据库也存在一些缺点,例如数据一致性难以保证、复杂查询效率低下等。 使用者 使用列族数据库的企业包括Facebook、Twitter、eBay、Netflix等,这些公司通常需要存储和处理海量的非结构化数据,列族数据库可以帮助他们高效地完成这项任务。 5.4.3 文档数据库介绍 文档数据库(Document Database)是一种NoSQL数据库,以文档作为基本存储单元。一个文档就是一个可读的、可序列化的、可以包含键值对或其他文档形式的数据容器,通常使用JSON或BSON等格式来表示文档。 作用 文档数据库的作用是提供高效的存储和查询文档数据的解决方案,适合存储半结构化和非结构化的数据,如博客、评论、产品描述、文章、日志等。 产品 常见的文档数据库产品包括MongoDB、Couchbase、CouchDB、RavenDB等。 典型应用: MongoDB:大规模数据存储、数据分析、实时数据处理、日志管理等。 Couchbase:在线事务处理、实时数据分析、缓存、数据聚合等。 CouchDB:分布式数据同步、协同编辑、移动应用存储、内容管理等。 RavenDB:跨平台应用程序存储、实时数据处理、分析和搜索等。 优缺点 优点: 易于扩展:文档数据库具有水平扩展的能力,可以很容易地添加更多的节点来增加存储容量和性能。 灵活性高:文档数据库具有灵活的数据模型,可以很好地适应各种不同的数据类型和数据结构。 查询能力强:文档数据库支持丰富的查询语言和索引技术,可以方便地查询和筛选文档数据。 缺点: 不支持事务:文档数据库通常不支持ACID事务,这可能导致一些数据一致性问题。 数据冗余:由于文档数据库通常使用冗余存储来提高查询性能,因此存储空间可能比关系型数据库更大。 不适用于复杂关系查询:虽然文档数据库支持复杂查询,但它们通常不适用于涉及多表的复杂关系查询。 使用者 文档数据库广泛应用于Web应用程序、移动应用程序、游戏等领域,特别是在需要高速读取和存储大量半结构化数据的场景中,如电商、社交网络、媒体、新闻、广告、游戏等行业。例如,MongoDB被广泛应用于社交网络、大数据存储、实时分析和日志处理等领域,Couchbase被广泛应用于高性能事务处理和实时数据分析等领域。 5.4.4 图数据库介绍 图数据库是一种专门用于存储和管理图形结构数据的数据库,图数据库是基于图论理论的应用,通过节点和边来表示和存储数据,并通过高效的图算法进行数据查询和处理。与传统的关系型数据库和键值数据库不同,图数据库的存储结构是由节点和边构成的图形结构,非常适合用于存储实体之间的关系和网络拓扑结构等数据。 作用 图数据库主要用于存储和查询具有复杂关系的数据,其数据模型能够有效地描述实体之间的关系和网络拓扑结构等信息。相比于关系型数据库,图数据库更加适合于数据的连通性分析和挖掘等领域,例如社交网络、知识图谱、地图导航等。 产品 目前市面上比较流行的图数据库产品有Neo4j、OrientDB、Titan、JanusGraph等。 典型应用 社交网络:社交网络中,人与人之间的关系可以看做是一个复杂的图形结构,图数据库可以很好地存储和处理这种数据。 知识图谱:知识图谱是一种以实体和实体之间的关系为基础的知识表示方法,图数据库可以很好地用于存储和查询知识图谱中的数据。 地图导航:地图导航中,地图上的各种元素可以看做是节点,它们之间的关系可以看做是边,图数据库可以很好地存储和处理这种数据。 优缺点: 优点: 可以存储和处理复杂关系数据:图数据库是专门用于存储和管理图形结构数据的,其数据模型可以有效地描述实体之间的关系和网络拓扑结构等信息。 查询效率高:相比于关系型数据库,图数据库更适合进行数据的连通性分析和挖掘,其高效的图算法可以在较短时间内查询和处理大规模的数据。 缺点: 数据规模受限:图数据库通常采用内存计算,对于数据规模较大的应用场景,需要借助分布式计算技术来进行扩展。 技术门槛较高:图数据库的查询语言通常采用Cypher、Gremlin等专业语言,需要具备较高的技术水平才能使用。 使用者 图数据库的使用者主要是数据分析师、人工智能工程师、网络安全工程师等技术人员。在社交网络、知识图谱、地图导航等领域,也需要使用图数据库进行数据存 5.5 NoSQL的三大基石NoSQL的三大基石包括 CAP、BASE 和最终一致性。 5.5.1 CAPCAP是指分布式系统设计中的三个重要特性,即一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。 一致性(Consistency):在分布式系统中,一致性指的是多个副本或节点之间数据一致的特性。也就是说,当系统在进行数据更新时,无论数据更新操作发生在哪个节点上,都会立即更新到其他副本节点,保证数据的一致性。 可用性(Availability):在分布式系统中,可用性指的是系统能够提供服务的能力,即系统始终能够响应用户的请求并返回结果。在某些情况下,系统可能会出现故障或网络问题导致某些节点无法提供服务,但是系统应该尽可能地保证可用性。 分区容错性(Partition Tolerance):在分布式系统中,分区容错性指的是系统能够在出现网络故障或节点故障时,仍然能够继续提供服务的能力。也就是说,系统在出现节点故障或网络分区时,仍然能够保证数据的一致性和可用性。 CAP理论认为,在分布式系统设计中,最多只能同时满足两个特性,无法同时满足三个特性。例如,当系统出现网络分区时,为了保证可用性和分区容错性,可能会出现数据不一致的情况,即无法同时满足一致性。 因此,在设计分布式系统时,需要根据具体场景和需求,权衡三个特性,选择合适的方案。例如,在对数据一致性要求比较高的场景,可以选择保证一致性和分区容错性,而牺牲一定的可用性。 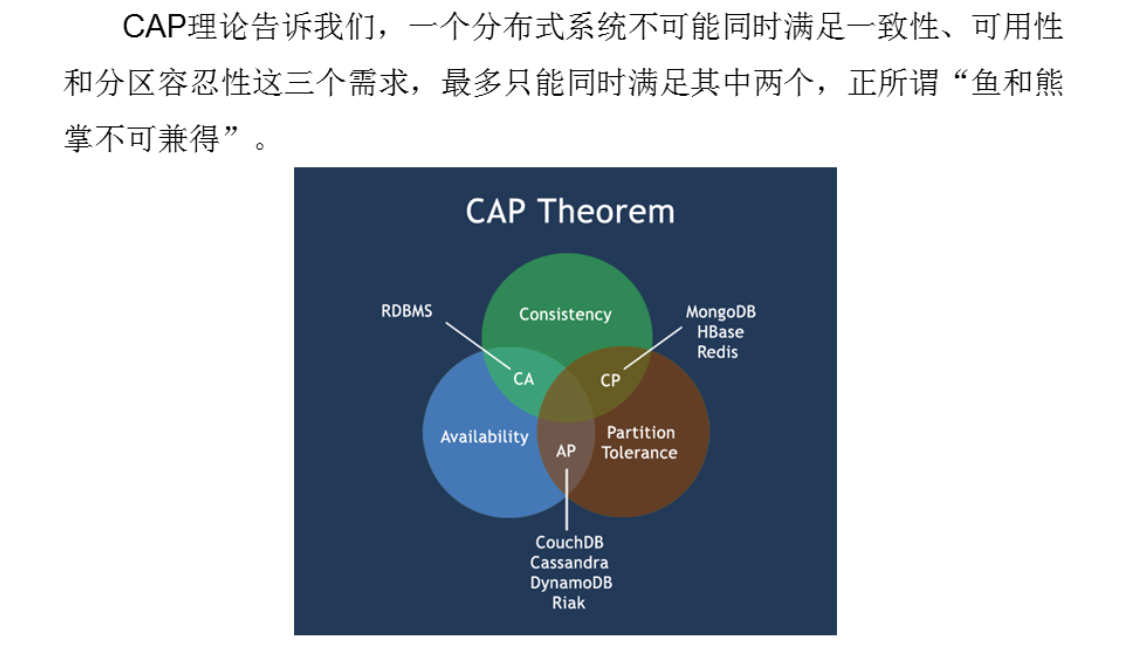 CAP原理指的是分布式系统中无法同时满足Consistency(数据一致性)、Availability(可用性)、Partition tolerance(分区容错性)这三个要求,只能满足其中的两个。这是由于在分布式系统中,由于网络的不可靠性和延迟等原因,节点之间的通信可能出现故障或延迟,导致分区的情况出现,此时就必须在一致性和可用性之间做出选择。
可以用一个餐厅的例子来解释CAP原理。假设你去一家快餐店点餐,你有三个要求:菜品必须新鲜(Consistency)、服务员必须快速提供服务(Availability)、价格必须便宜(Partition tolerance)。
现在你只能满足其中两个要求。如果你选择新鲜的菜品和快速的服务(CA),那么价格可能会更高;如果你选择新鲜的菜品和低廉的价格(CP),那么服务可能会慢一些;如果你选择低廉的价格和快速的服务(AP),那么菜品可能不太新鲜。这就是CAP原理在现实生活中的应用。
在分布式系统中,分区指的是由于网络故障或者网络延迟等原因导致节点之间无法通信,从而形成了一个或多个无法通信的子集。举个例子,假设在一个分布式系统中有3个节点,分别为A、B、C,它们通过网络互相通信。如果由于网络故障或者网络延迟等原因,节点B和节点C之间的通信出现了问题,那么节点A和节点B形成了一个子集,节点C形成了另一个子集,这种情况就称为分区。
分区会导致分布式系统中的数据一致性问题,因为当分区发生时,两个子集内的节点无法相互通信,数据的修改无法同步,可能导致数据不一致的问题。因此,在分布式系统的设计和实现中,需要采取一些策略来避免或减少分区的出现,例如引入数据备份和数据冗余等机制来增加系统的可靠性,或者使用更加复杂的一致性协议来保证数据的一致性。
CAP原理指的是分布式系统中无法同时满足Consistency(数据一致性)、Availability(可用性)、Partition tolerance(分区容错性)这三个要求,只能满足其中的两个。这是由于在分布式系统中,由于网络的不可靠性和延迟等原因,节点之间的通信可能出现故障或延迟,导致分区的情况出现,此时就必须在一致性和可用性之间做出选择。
可以用一个餐厅的例子来解释CAP原理。假设你去一家快餐店点餐,你有三个要求:菜品必须新鲜(Consistency)、服务员必须快速提供服务(Availability)、价格必须便宜(Partition tolerance)。
现在你只能满足其中两个要求。如果你选择新鲜的菜品和快速的服务(CA),那么价格可能会更高;如果你选择新鲜的菜品和低廉的价格(CP),那么服务可能会慢一些;如果你选择低廉的价格和快速的服务(AP),那么菜品可能不太新鲜。这就是CAP原理在现实生活中的应用。
在分布式系统中,分区指的是由于网络故障或者网络延迟等原因导致节点之间无法通信,从而形成了一个或多个无法通信的子集。举个例子,假设在一个分布式系统中有3个节点,分别为A、B、C,它们通过网络互相通信。如果由于网络故障或者网络延迟等原因,节点B和节点C之间的通信出现了问题,那么节点A和节点B形成了一个子集,节点C形成了另一个子集,这种情况就称为分区。
分区会导致分布式系统中的数据一致性问题,因为当分区发生时,两个子集内的节点无法相互通信,数据的修改无法同步,可能导致数据不一致的问题。因此,在分布式系统的设计和实现中,需要采取一些策略来避免或减少分区的出现,例如引入数据备份和数据冗余等机制来增加系统的可靠性,或者使用更加复杂的一致性协议来保证数据的一致性。
当处理 CAP 的问题时,可以有以下几个明显的选择,即不同产品在 CAP 理论下有不同的设计原则(见图5-4)。 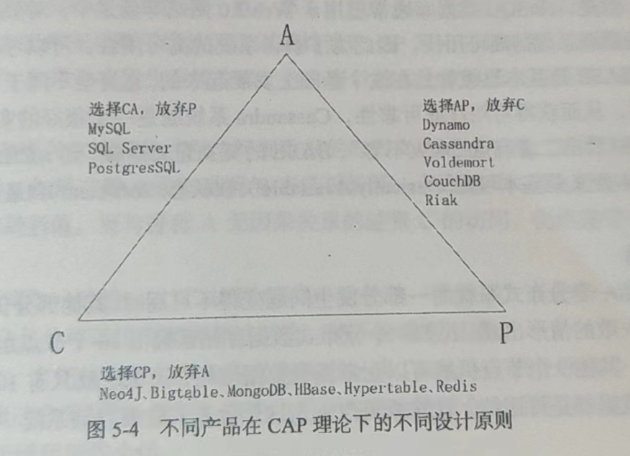
Consistency(一致性)+ Partition tolerance(分区容错性):在一些强一致性要求高、对分区容忍度较高的应用场景下,可以采用这种方案。例如,金融系统、医疗系统等。 Availability(可用性)+ Partition tolerance(分区容错性):在一些对可用性要求较高、对一致性容忍度较高的应用场景下,可以采用这种方案。例如,电商系统、社交网络等。 Consistency(一致性)+ Availability(可用性):在一些对一致性和可用性都有很高要求的场景下,可以采用这种方案。但是,这种方案在分区容错性方面的要求比较高,需要保证分区容错性。例如,在线游戏、即时通讯等。 不同的产品在 CAP 理论下有不同的设计考量,根据具体应用场景的不同,可以选择不同的方案和产品。 5.5.2 BASEBASE是指基本可用、软状态、最终一致性,是CAP理论的一个补充。与传统ACID事务不同,BASE更多地考虑可用性和性能,而不是严格的一致性。下面对BASE的每个组成部分进行解释: 基本可用(Basically Available):系统必须在故障时继续可用,并在可恢复之后尽快恢复。因此,它强调了系统的可用性而不是完整性。 软状态(Soft state):即在某个时间点上,系统的状态不必是完全确定的,它可以在不同的节点上具有不同的状态,并且这些状态在没有发生故障的情况下可以相互转换。这与传统ACID事务的“硬状态”要求形成了对比。 最终一致性(Eventually Consistent):即在某个时间点上,所有节点的数据都将达到一致状态。这可以通过异步复制和冲突解决来实现。最终一致性是在系统可用性和性能之间的一种折衷,因为为了保持一致性,系统可能需要降低可用性和性能。 BASE理论的实现方式包括缓存、异步复制、分区和分片等。BASE理论被广泛应用于大规模分布式系统、云计算等领域,它强调了可用性、性能和灵活性,为系统设计带来了新的思路。 5.5.3 最终一致性最终一致性是指在分布式系统中,不同节点上的数据在经过一段时间后最终会达成一致状态。这种一致性模型相对于强一致性模型,放弃了实时性和强制性,但是通过牺牲一定程度的一致性保证,获得了更高的可用性和性能。 最终一致性保证了一个分布式系统中的数据更新最终会被所有节点感知到并达成一致状态,但是这个一致状态的时间点是不确定的。在分布式系统中,由于网络延迟、分区等原因,不同节点上的数据可能存在短暂的不一致状态,但是随着时间的推移,所有节点最终都会收敛到一个一致的状态。 最终一致性通常采用异步复制的方式实现。每个节点都会记录下自己的更新操作,并异步地将这些更新操作发送给其它节点。由于异步复制的特性,每个节点在某一时刻看到的数据可能并不是最新的,但是随着时间的推移,数据最终会达成一致状态。 最终一致性的优点在于,它可以提高系统的可用性和性能,因为数据更新不需要等待所有节点都达成一致状态。同时,最终一致性还具有较好的扩展性,可以支持大规模分布式系统。 然而,最终一致性也存在一定的缺点,最显著的就是数据的不一致性问题。在某些场景下,数据的不一致可能会对业务造成一定的影响。因此,最终一致性需要在具体的场景下进行权衡和选择。 根据更新数据后各进程访问到数据的时间和方式的不同,最终一致性可以进行以下区分: 因果一致性(Causal Consistency):在某个进程更新了数据后,所有依赖这个数据的进程都必须在其后访问到该数据的更新值,保证了因果关系的一致性。例如,假设有一个多人在线游戏,玩家A打出了一记攻击,导致敌人B掉了100点血。这个数据更新的因果关系是A打出攻击引起了敌人B扣血。其他玩家在看到此事件后,必须以此为前提,并在后续操作中保证其一致性。 “读己之所写”一致性(Read-Your-Writes Consistency):一个进程更新了数据后,该进程后续的读操作必须能够读到自己所写的最新值,保证了读操作的一致性。例如,一个用户在社交网站上发布了一条状态更新,他自己后续访问时必须能够读取到自己所写的最新状态。 会话一致性(Session Consistency):在同一个进程中,用户进行的操作必须按照操作顺序得到相同的结果。例如,用户A登录了一个购物网站,在进行浏览、购物、结算等操作时,必须始终处于同一个“会话”状态,不会因为其他用户的操作而发生改变,保证了用户体验的一致性。 单调读一致性(Monotonic Read Consistency):如果一个进程读取了某个数据项的值后,后续的读操作必须能够读取到不小于先前读取的值,保证了读操作的单调性。例如,一个用户在购物网站上查看了商品的价格后,后续的读操作必须能够读取到不小于之前查看到的价格。 单调写一致性(Monotonic Write Consistency):一个进程写入的数据顺序必须和其它进程所看到的写入顺序一致,保证了写操作的单调性。例如,一个用户在某个云盘上上传了多个文件,其他用户必须以相同的顺序看到这些文件。 这些概念在现实生活中也有对应的例子,例如: 因果一致性:一辆汽车在一个路口发生了交通事故,这个事故对后续车辆行驶方向产生了影响,必须保证所有的车辆都知道这个影响,以免发生更多的事故。 “读己之所写”一致性:在一个大型的团队协作中,如果一个团队成员对某个文档进行了修改,其他团队成员在后续的访问中必须能够看到这个修改,以避免因为团队成员之间信息不同步而导致的协作问题。 会话一致性:在一个在线购物网站中,用户在进行购物的整个过程中必须保持在同一个会话状态下,以确保所有的操作都能被正确记录和处理。 单调读一致性:一个电商网站在某个商品页面上显示了一个特定的价格,那么所有的用户在后续的访问中都应该能够看到同样的价格,即使这个价格已经发生了改变。 单调写一致性:在一个在线投票系统中,所有的用户在对某个提案进行投票之后,投票系统必须保证对这个提案的投票结果是单调递增的,即后续的投票结果必须包含前面的投票结果,而不能出现投票结果被覆盖的情况。 5.6 从NoSQL到NewSQL 数据库NoSQL和NewSQL都是数据库技术中的一种类型,它们与传统的关系型数据库有所不同。 NoSQL数据库是指不使用关系型模型的、非结构化的、分布式的数据库系统,例如MongoDB、Cassandra、Redis等。NoSQL数据库通常具有高可扩展性、高可用性和高性能等优点,适合处理海量数据和高并发的场景,但也存在一些限制,如缺乏事务支持和一致性问题。 NewSQL数据库则是在保持关系型数据库ACID事务的特性的基础上,通过新的架构和算法来提高可扩展性、可用性和性能等方面的表现。NewSQL数据库的目标是要同时拥有传统关系型数据库的事务处理能力和NoSQL数据库的分布式、高可扩展性等特性。一些NewSQL数据库包括TiDB、CockroachDB、VoltDB等。 从NoSQL到NewSQL的发展历程,主要体现了数据库技术的发展趋势,以及不同场景下的需求变化。在处理海量数据和高并发访问等场景下,NoSQL数据库的分布式、高可扩展性和高性能等优势逐渐被广泛认可,但也受到了一些限制。而NewSQL数据库则是在传统关系型数据库的基础上,结合了分布式、高可扩展性和高性能等特性,使得它在适用于大规模数据处理和高并发访问的同时,也具有ACID事务保证的优点。 |
【本文地址】
今日新闻 |
推荐新闻 |