NLP |
您所在的位置:网站首页 › nlp综述方法怎么分类 › NLP |
NLP
|
文章目录
文章目录 社区检测(Community Detection) 社区 社区检测 社区检测与聚类的对比分析 鲁汶算法(Louvain ) 莱顿社区检测(Leiden) 标签传播算法(Label propagation algorithm) 强连接组件(Strongly Connected Components) 弱连接组件(Weakly Connected Components) 三角形计数(Triangle Count) 局部聚类系数(Local Clustering Coefficient) 其他 总结 参考链接
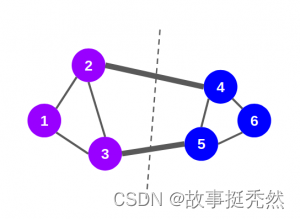
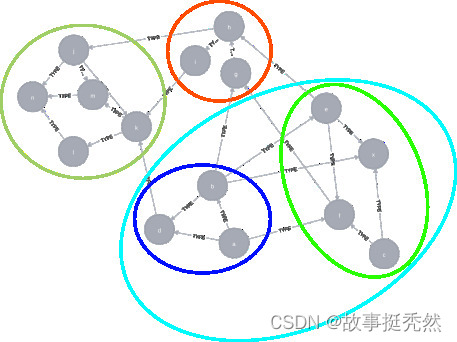
社区检测(Community Detection) 社区检测(Community Detection)又被称为是社区发现。它是用来揭示网络聚集行为的一种技术。 社区检测算法用于评估节点组如何聚类或分区,以及它们增强或分离的趋势。 社区 社区是许多网络的属性,其中一个特定的网络可能有多个社区,因此社区内的节点是密集连接的。 多个社区中的节点可以重叠。例如日常中的微信、QQ、抖音,我们每天可能会与自己的朋友、同事、家人和生活中其他一些重要的人进行大量互动。它们在我们的社交网络中形成了一个非常密集的社区。 就图而言,社区可以定义为节点的子集,这些节点彼此紧密连接,而与同一图中其他社区中的节点松散连接。(网络节点在社区内紧密连接成紧密的组,而社区之间则松散连接。) 对于日常微信、QQ或 抖音 等社交媒体平台,我们试图在这些平台上与其他人联系。最终,一段时间后,我们最终与属于不同社交圈的人建立了联系。这些社交圈可以是一群亲戚、同学、同事等。这些社交圈也就是社区! 每个社区是一个子图,包含顶点和边。
社区检测 社区检测(community detection)又被称为是社区发现,它是用来揭示网络聚集行为的一种技术。社区检测实际就是一种网络聚类的方法,这里的“社区”,我们可以将其理解为一类具有相同特性的节点的集合。
社区检测算法的一个关键作用在于可用于从网络中提取有用的信息。 社区检测面临的最大挑战是社区结构没有普遍定义(与和聚类类似,没标签,无法直接评价效果的好坏)。 为什么要社区检测? 在分析不同的网络时,发现其中的社区可能很重要。 社区检测技术对于社交媒体算法很有用,可以发现具有共同兴趣的人并保持他们紧密联系。 社区检测可用于机器学习中,以检测具有相似属性的组并出于各种原因提取组。例如,该技术可用于发现社交网络或股票市场中的操纵群体。 社区检测与聚类的对比分析 聚类是一种机器学习技术,其中相似的数据点根据它们的属性被分组到同一个簇中。尽管聚类可以应用于网络,但它是无监督机器学习中一个更广泛的领域,可以处理多种属性类型。聚类算法倾向于将单个外围节点与其应属于的社区分开。社区检测是专门为网络分析量身定制的,网络分析依赖于称为边的单一属性类型。 社区检测类似于聚类,但是,聚类和社区检测技术都可以应用于许多网络分析问题,并且可能会根据领域产生不同的优缺点。 术语定义模块化 是对网络或图结构的度量,它衡量网络划分为模块(也称为组、集群或社区)的强度。 高度模块化的网络在模块内的节点之间具有密集的连接,但在不同模块中的节点之间具有稀疏的连接。模块化通常用于检测网络中社区结构的优化方法。然而,已经表明模块化受到分辨率限制,因此无法检测到小型社区。包括动物大脑在内的生物网络表现出高度的模块化。 模块化是落在给定组内的边缘的分数减去边缘随机分布的预期分数。未加权和无向图的模块化值在范围内[-0.5,1](模块化是介于 -0.5(非模块化聚类)和 1(完全模块化聚类)之间的尺度值,用于衡量社区内部边相对于社区外部边的相对密度)。 如果组内边缘的数量超过基于机会预期的数量,则为正。对于给定的网络顶点划分为一些模块,模块性反映了模块内边缘的集中度,与所有节点之间的随机分布的链接相比,无论模块如何。 在给定的网络中可以有任意数量的社区,并且它们的大小可以不同。这些特征使得社区的检测过程非常困难。然而,在社区检测领域提出了许多不同的技术、算法,由上面的社区检测与聚类的对比分析可知,社区检测算法若细细研究,可纳入的算法较多。 针对图算法(即图谱中,我们可用到的一些算法)进行整合,接下来介绍几种图算法中常用的社区检测算法。 鲁汶算法(Louvain ) 鲁汶方法是一种检测大型网络中社区的算法。它最大化了每个社区的模块化分数,其中模块化量化了分配给社区的节点的质量。这意味着评估社区中节点的密集程度,以及它们在随机网络中的连接程度。 Louvain 算法是一种分层聚类算法,它以递归方式将社区合并到单个节点中,并在压缩图上执行模块化聚类。(这意味着在每个群集步骤之后,属于同一群集的所有节点都将减少到单个节点。同一集群节点之间的关系成为自有关系,与其他集群节点的关系连接到集群代表。然后,此精简图用于运行下一级别的聚类分析。重复该过程,直到群集稳定。) 在社区检测的Louvain方法中,首先通过在所有节点上局部优化模块化来找到小社区,然后将每个小社区分组为一个节点,并重复第一步。即为迭代重复两个阶段: 节点的局部移动 网络聚合
该算法从 N 个节点的加权网络开始。 在第一阶段,算法为网络的每个节点分配一个不同的社区。然后对于每个节点,它考虑邻居并评估模块化增益通过从当前社区中删除特定节点并放置在邻居的社区中。如果增益为正且最大化,则该节点将被放置在邻居的社区中。如果没有正收益,该节点将留在同一个社区中。这个过程被重复应用到所有节点,直到没有进一步的改进。当获得局部最大值时,Louvain 算法的第一阶段停止。在第二阶段,该算法将在第一阶段找到的社区作为节点来构建一个新的网络。一旦第二阶段完成,算法会将第一阶段重新应用于生成的网络。重复这些步骤,直到网络没有变化并且获得最大的模块化。
Louvain社区检测算法在此过程中发现社区的社区。由于易于实现以及算法的速度,它非常受欢迎。然而,该算法的一个主要限制是在主存储器中使用网络存储。 莱顿社区检测(Leiden) 莱顿算法是一种用于检测大型网络中的社区的算法。该算法将节点分离成不相交的社区,从而最大化每个社区的模块化得分。模块化量化了将节点分配给社区的质量,即社区中节点的密集连接程度,与它们在随机网络中的连接程度相比。 Leiden算法是一种分层聚类算法,它通过贪婪地优化模块化和在压缩图中重复的过程,递归地将社区合并到单个节点中。它修改了鲁汶算法以解决其一些缺点,即鲁汶发现的一些社区联系不紧密的情况。这是通过定期将社区随机分解为较小的连接良好的社区来实现的。 莱顿算法的三个阶段是, 节点的局部移动 分区的细化 基于细化分区的网络聚合 在细化阶段,算法试图从第一阶段提出的分区中识别出细化的分区。第一阶段提出的社区可能在第二阶段进一步分裂成多个分区。细化阶段不遵循贪心方法,并且可能将节点与随机选择的社区合并,从而增加质量函数。这种随机性允许更广泛地发现分区空间。同样在第一阶段,莱顿对鲁汶采取了不同的方法。与第一次访问所有节点完成后访问网络中的所有节点不同,Leiden 只访问那些邻域发生变化的节点。
标签传播算法(Label propagation algorithm) 标签传播算法 (LPA) 是一种用于在图形中查找社区的快速算法。它仅使用网络结构作为其指导来检测这些社区,并且不需要预定义的目标函数或有关社区的先验信息。 LPA的工作原理是在整个网络中传播标签,并基于这种标签传播过程形成社区。 标签传播是一种半监督机器学习算法,将标签分配给以前未标记的数据点。在算法开始时,数据点的(通常很小的)子集具有标签(或分类)。这些标签在整个算法过程中传播到未标记的点。 优缺点: 优点:与其他算法相比标签传播在其运行时间和网络结构所需的先验信息量方面具有优势(不需要事先知道参数)。缺点:它不会产生唯一的解决方案,而是许多解决方案的集合。在初始条件下,节点带有一个标签,表示它们所属的社区。社区中的成员身份会根据相邻节点拥有的标签而变化。此更改受节点一度内的最大标签数的限制。每个节点都用一个唯一的标签初始化,然后标签在网络中扩散。因此,密集连接的组很快就达到了一个共同的标签。当在整个网络中创建许多这样的密集(共识)组时,它们会继续向外扩展,直到不能这样做。 该算法的工作原理如下: 每个节点都使用唯一的社区标签(标识符)进行初始化。 这些标签通过网络传播。 在每次迭代传播时,每个节点都会将其标签更新为其邻居的最大数量所属的标签。关系是任意但确定地断开的。 当每个节点都具有其邻居的多数标签时,LPA 达到收敛状态。 如果实现了收敛或用户定义的最大迭代次数,则 LPA 将停止。 随着标签的传播,密集连接的节点组很快就会就唯一标签达成共识。在传播结束时,只有少数标签将保留 - 大多数将消失。在收敛时具有相同社区标签的节点称为属于同一社区。 LPA的一个有趣的功能是,可以为节点分配初步标签,以缩小生成的解决方案的范围。这意味着它可以用作半监督的方式来寻找我们亲自挑选一些初始社区的社区。 强连接组件(Strongly Connected Components) 强连接组件 (SCC) 算法在有向图中查找最大连接节点集。如果集合内每对节点之间都有一条有向路径,则该集合被视为强连接组件。它通常在图形分析过程的早期使用,以帮助我们了解图形的结构。 在有向图的数学理论中,如果每个顶点都可以从其他每个顶点到达,则称该图为强连接图。任意有向图的强连接组件形成一个子图的分区,这些子图本身是强连接的。 对顶点之间在每个方向上都有一条路径,则称为强连接图。即,从该对中的第一个顶点到第二个顶点存在一条路径,从第二个顶点到第一个顶点存在另一条路径。
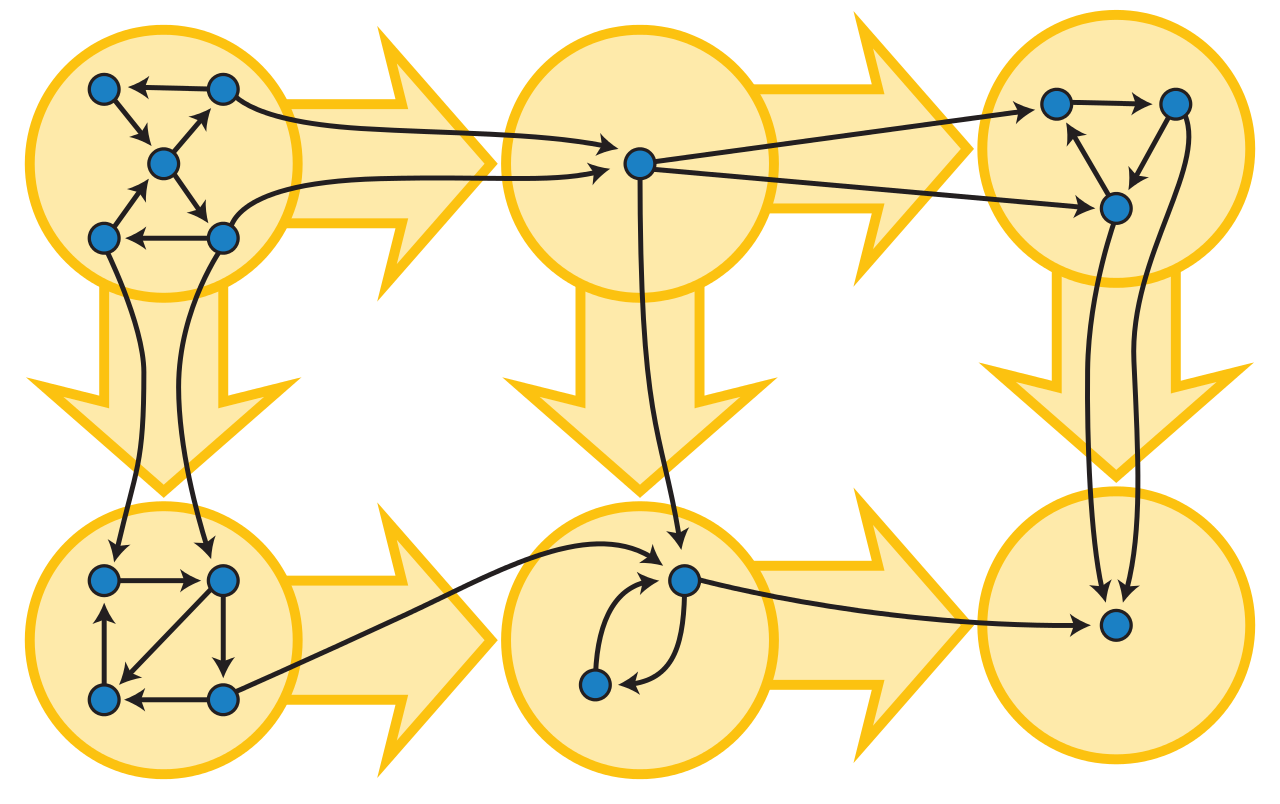
黄色有向无环图是蓝色有向图的浓缩。它是通过将蓝色图的每个强连通分量收缩为单个黄色顶点而形成的。 用例
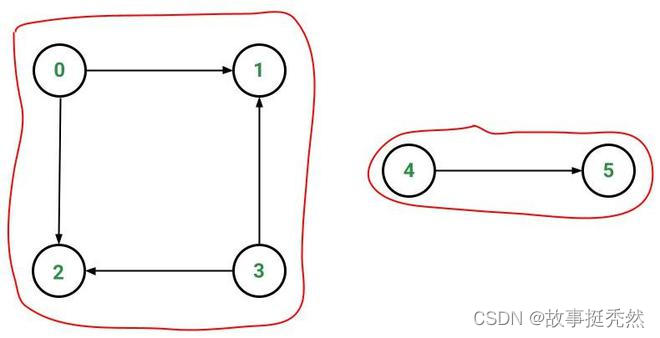
在对强大跨国公司的分析中,SCC可用于找出每个成员直接或间接拥有其他成员股份的一组公司。虽然它有好处,例如降低交易成本和增加信任,但这种类型的结构会削弱市场竞争。 在测量多跳无线网络中的路由性能时,SCC 可用于计算不同网络配置的连通性。 强连接组件算法可以用作许多图形算法的第一步,这些算法仅适用于强连接图形。在社交网络中,一群人通常有很强的联系(例如,一个班级或任何其他常见地方的学生)。这些组中的许多人通常喜欢一些常见的页面,或者玩普通的游戏。SCC算法可用于查找此类组,并向组中尚未喜欢这些页面或游戏的用户推荐常用页面或游戏。 弱连接组件(Weakly Connected Components) 弱连接组件(WCC) 算法在无向图中查找连接的节点集,其中同一集中的所有节点形成一个连接的组件。WCC通常在分析的早期用于理解图形的结构。使用 WCC 了解图形结构可以在已识别的集群上独立运行其他算法。作为有向图的预处理步骤,它有助于快速识别断开连接的组。 给定一个有向图,弱连通分量 (WCC) 是原始图的子图,其中所有顶点通过某种路径相互连接,忽略边的方向。在无向图的情况下,弱连接组件也是强连接组件。该模块还包括许多对 WCC 输出进行操作的辅助函数。
在上面的有向图中,有两个弱连通分量: [0, 1, 2, 3] [4, 5] 三角形计数(Triangle Count) 三角形计数算法计算图形中每个节点的三角形数。三角形是一组三个节点,其中每个节点与其他两个节点有关系。在图论术语中,这有时被称为3集团。 三角形计数在社交网络分析中越来越受欢迎,它用于检测社区并测量这些社区的凝聚力。它还可用于确定图形的稳定性,并且通常用作网络索引计算的一部分,例如聚类系数。三角形计数算法还用于计算局部聚类系数。 Triangle Count算法如下: 计算每个结点的邻结点。 统计对每条边计算交集,并找出交集中id大于前两个结点id的结点。 对每个结点统计Triangle总数,注意只统计符合计算方向的Triangle Count。 注意:计算三角形时,要有计算方向(如,起始结点id |


【本文地址】
今日新闻 |
推荐新闻 |