NLP深入学习:大模型背后的Transformer模型究竟是什么?(一) |
您所在的位置:网站首页 › nlp是怎么产生的 › NLP深入学习:大模型背后的Transformer模型究竟是什么?(一) |
NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)
|
文章目录
1. 前言2. 整体架构3. 输入部分3.1 文本嵌入(Embedding)3.2. 位置编码( Positional Encoding)3.3 输入向量
4. 参考
1. 前言
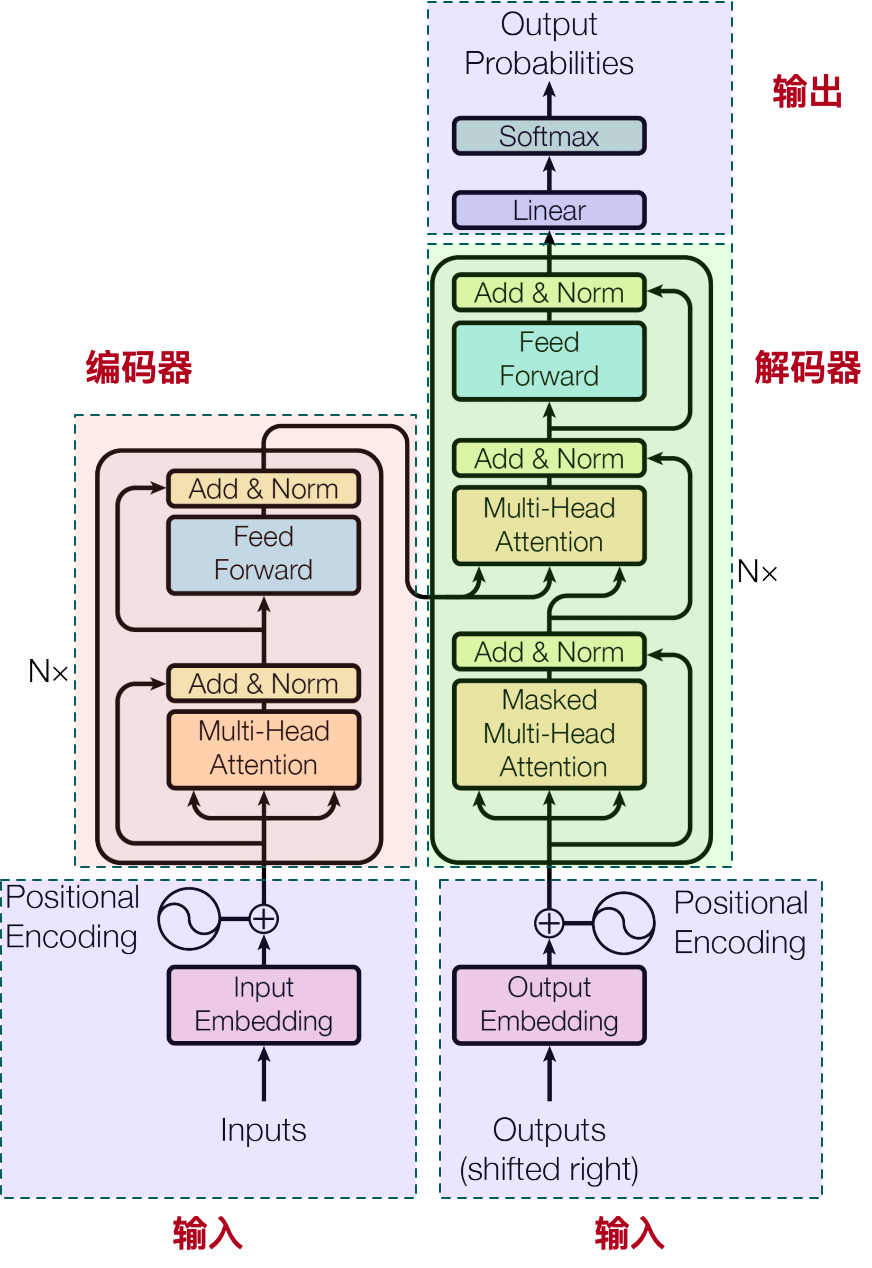
稍微熟悉 NLP 技术的同学一定听说过 Transformer 模型,当前的主流大模型,如 GPT 背后的底层核心技术,就是谷歌2017年论文《Attention Is All You Need》提到的 Transformer 模型。只能说当前很多技术依然是面向谷歌编程,熟称:谷歌大法(忧伤~)。可能会有团队研究 Transfromer 的替代者,但是无论如何 Transfromer 背后的原理都值得我们深入研究! 我一直很喜欢探讨一项技术底层的原理,这是深入了解技术的基本。在看了原论文以及一些解析的文章、视频之后,把我对 Transformer 的理解整理出一篇文章,欢迎大家一起学习探讨~ 本文主要讲解输入部分内容!后文会讲解核心的 Self-Attention 机制 2. 整体架构
从图中可以看到,整体分为四个部分: 输入部分: Input Embeddings: 输入文本首先通过词汇表查找转化为词索引,然后通过嵌入层转化为高维向量,这些向量被称为词嵌入。Positional Encoding: 为了保留序列中单词的顺序信息,Transformer 引入了位置编码。这是一种特殊的向量表示,与词嵌入相加后传给模型,其中包含了每个位置的独特信号。编码器(Encoder): 多头自注意力机制(Multi-Head Self-Attention):这是Transformer 的关键组件,它允许模型在不考虑词语顺序的情况下,一次性查看整个输入序列的信息。每个“头”都会独立计算自注意力得分,从而从不同的角度捕获输入序列的不同模式。前馈神经网络(Feedforward Network):编码器内部还包括两个子层,除了多头自注意力层外,还有一个全连接的前馈神经网络,它进一步处理自注意力后的向量表示。Layer Normalization 和 Residual Connections:每个子层前后都包含层归一化以及残差连接,以稳定训练过程并帮助信息更好地在网络中传播。解码器(Decoder): 解码器同样由多层组成,每层有自注意力子层(但这次是针对自身解码器历史输出的自注意力,防止未来信息泄露),也有针对编码器输出的注意力子层(称为“编码器-解码器注意力”),确保解码过程中能关注到输入序列的相关信息。解码器同样包含全连接的前馈神经网络层,并使用层归一化和残差连接。输出部分: 最终的解码器层输出经过一个线性层映射到目标词汇空间的大小,随后通过 softmax 函数得到概率分布,这个分布表示了每个可能的目标词作为下一个预测词的概率。 3. 输入部分 3.1 文本嵌入(Embedding)
降维处理: 文本是由词语组成的序列,传统上用词袋模型或 TF-IDF 等方法表示时,维度非常高且稀疏。Embedding 将每个词语或句子映射到一个低维、稠密的向量空间中,大大降低了数据的维度,便于进一步的计算和分析。 保留语义信息: 文本 Embedding 通常通过训练能够在特定任务上学习到词语或句子的语义和上下文信息,使得相似的文本在向量空间中有相近的位置,不相似的文本则相距较远。例如,Word2Vec、GloVe 等模型的训练目标就是为了捕捉词语之间的共现关系和语义相似性。 深度学习友好: Embedding 将文本转换为数值向量后,可以直接输入到深度学习模型中,如神经网络,用于进行情感分析、文本分类、机器翻译、问答系统等各种自然语言处理任务。 相似度计算: 文本 Embedding 可以方便地进行向量间的距离计算(如欧氏距离、余弦相似度等),用于文本相似性检索、文档聚类等任务。 一句话,文本 Embedding 是将自然语言处理中的文本数据转化为机器学习和深度学习模型能够理解和处理的数值形式,极大地提升了模型处理文本问题的能力和效率。 下面是 PyTorch 常见的 embedding 代码示例: # nn.Embedding(vocab, d_model),其中vocab是词典的大小,d_model是词嵌入的维度 embedding = nn.Embedding(10, 4) input = torch.LongTensor([[0, 1, 2, 3], [4, 5, 6, 7]]) print(embedding(input))输出: Parameter containing: tensor([[[-1.1025, 0.9953, 0.4592, 0.6081], [-0.3369, -0.2705, 0.4536, 0.6368], [ 0.0629, 1.8627, -0.7417, 0.5897], [ 0.1189, 1.3782, 1.0487, 0.3722]], [[ 0.3013, -0.0727, 1.2520, -0.0135], [ 0.1413, -0.2008, -0.1924, 1.7247], [-0.0966, -1.0898, 0.0871, 0.9234], [ 2.2679, 0.1290, -1.3277, 0.2457]]], grad_fn=) 3.2. 位置编码( Positional Encoding)
对于一个长度为 T 的语句序列,位置编码 P E PE PE 为序列中每个位置 p o s pos pos 的字生成一个同样维度 d_model 的向量,其中 i 表示词向量(Embedding)的维度。Transformer 中用周期函数(Sine/Cosine)表示位置编码: 周期函数形式(在原始Transformer论文中提出): 对于偶数索引 i: P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = sin\Big(\frac{pos}{10000^{2i/d_{model}}}\Big) PE(pos,2i)=sin(100002i/dmodelpos) 对于奇数索引 i: P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)} = cos\Big(\frac{pos}{10000^{2i/d_{model}}}\Big) PE(pos,2i+1)=cos(100002i/dmodelpos) 注意: pos 取值范围是 1 到 T(语句序列长度)i 取值范围是 0 到 embedding 的维度d_model 是 Transformer 模型的隐藏层维度周期的变化都是从 2π 到 10000 * 2π那么论文中的为什么用这种表达方式来表达位置信息呢? 充分使用了字在语句序列的位置信息,不同位置在不同维度上的频率有所不同,每一个 pos 对应的 P E PE PE 都是不一样的方便计算相对位置关系,对于任意的偏移量 k k k, P E ( p o s + k , 2 i ) = s i n ( p o s + k 1000 0 2 i / d m o d e l ) = ( 正弦展开 ) PE(pos+k, 2i) = sin\Big(\frac{pos+k}{10000^{2i/d_{model}}}\Big)=(正弦展开) PE(pos+k,2i)=sin(100002i/dmodelpos+k)=(正弦展开) 可以由 s i n ( p o s 1000 0 2 i / d m o d e l ) sin\Big(\frac{pos}{10000^{2i/d_{model}}}\Big) sin(100002i/dmodelpos) 以及 c o s ( p o s + k 1000 0 2 i / d m o d e l ) cos\Big(\frac{pos+k}{10000^{2i/d_{model}}}\Big) cos(100002i/dmodelpos+k) 的线性组合得到,这样就可以利用线性变换矩阵快速计算得到。以下是一个简单的 Python 代码示例,演示如何实现 Transformer 的 Positional Encoding: import torch import torch.nn as nn import math class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=512): """ 参数d_model: 词嵌入维度 max_len: 语句的最大序列长度 """ super(PositionalEncoding, self).__init__() # 初始化一个位置编码矩阵,大小 max_len x d_model self.encoding = torch.zeros(max_len, d_model) # 初始化位置pos矩阵,大小 max_len x 1 position = torch.arange(0, max_len).unsqueeze(1).float() # 下面对应于论文的奇数cos和偶数sin公式 # 其中 div_term 对应于嵌入向量的特征维度 div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)) self.encoding[:, 0::2] = torch.sin(position * div_term) self.encoding[:, 1::2] = torch.cos(position * div_term) self.encoding = self.encoding.unsqueeze(0) def forward(self, x): return x + self.encoding[:, :x.size(1)].detach() # 示例用法 d_model = 512 max_len = 100 pos_encoding = PositionalEncoding(d_model, max_len) # 输入序列的示例,假设序列长度为10,embedding维度为512 input_sequence = torch.rand(1, 10, d_model) # 添加位置编码 output_sequence = pos_encoding(input_sequence) print("Input sequence shape:", input_sequence.shape) print("Output sequence shape (with positional encoding):", output_sequence.shape)这个代码示例定义了一个 PositionalEncoding 的类,它继承自 nn.Module,并在 forward 方法中将位置编码添加到输入序列中。可以根据实际的模型和需求调整 d_model 和 max_len 的值。 3.3 输入向量
本文先讲到这里,后续内容更精彩,后文会讲解核心的 Self-Attention 机制 4. 参考中文自然语言处理 Transformer模型(一) Transformer - Attention is all you need 超详细图解Self-Attention 2024年终于有人把Transformer讲透彻了! 欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习; 欢迎关注知乎:SmallerFL; 也欢迎关注我的wx公众号:一个比特定乾坤 |
 文本 Embedding 是一种将文本数据转换为数值向量表示的过程,其作用主要包括:
文本 Embedding 是一种将文本数据转换为数值向量表示的过程,其作用主要包括: Transformer 模型中的 Positional Encoding 是一种为输入序列添加位置信息的方法,因为在 Transformer 的自注意力机制中,模型本身不具备对序列中元素位置的内在感知能力。为了确保模型能够理解序列中词或 token 的位置顺序,会在输入 Embedding 的基础上加上位置编码。
Transformer 模型中的 Positional Encoding 是一种为输入序列添加位置信息的方法,因为在 Transformer 的自注意力机制中,模型本身不具备对序列中元素位置的内在感知能力。为了确保模型能够理解序列中词或 token 的位置顺序,会在输入 Embedding 的基础上加上位置编码。 将位置编码向量与词嵌入相加,得到带有位置信息的输入向量:
X
p
o
s
=
E
p
o
s
+
P
E
p
o
s
X_{pos} = E_{pos} + PE_{pos}
Xpos=Epos+PEpos 其中,
E
p
o
s
E_{pos}
Epos 是词典中第 pos 个词的词嵌入向量,
P
E
p
o
s
PE_{pos}
PEpos 是位置 pos 的位置编码向量,两者维度均为 d_model。
将位置编码向量与词嵌入相加,得到带有位置信息的输入向量:
X
p
o
s
=
E
p
o
s
+
P
E
p
o
s
X_{pos} = E_{pos} + PE_{pos}
Xpos=Epos+PEpos 其中,
E
p
o
s
E_{pos}
Epos 是词典中第 pos 个词的词嵌入向量,
P
E
p
o
s
PE_{pos}
PEpos 是位置 pos 的位置编码向量,两者维度均为 d_model。【本文地址】