自然语言处理之准确率、召回率、F1理解 |
您所在的位置:网站首页 › nlp分析是什么意思 › 自然语言处理之准确率、召回率、F1理解 |
自然语言处理之准确率、召回率、F1理解
|
在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要。 1、准确率与召回率(Precision & Recall) 准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。 一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。 召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数 准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数 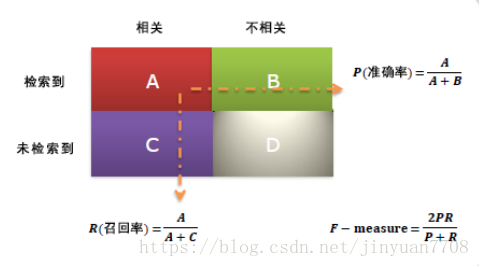
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。通常,我们希望准确率和召回率均越高越好,但事实上这两者在某些情况下是矛盾的。 比如我们只搜出了一个结果,此结果是正确的,求得precisin等于1。但是由于只搜出一个结果,recall值反而很低,接近于0。所以需要综合考量,下面介绍F-measure。 2、F-measure F-measure又称F-score,其公式为: 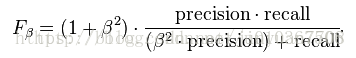
其中F2值,更加注重召回率;F0.5值更加重视准确率。 当beta=1时,就是F1-score:
F-measure综合了precision和recall,其值越高,通常表示算法性能越好。 |
【本文地址】