股票市场情绪分析 |
您所在的位置:网站首页 › nlp分析交易模型 › 股票市场情绪分析 |
股票市场情绪分析
|
股票市场情绪分析-使用机器学习方法
May 31, 2021 less than 1 minute read 通过股民对股票的评论数据来分析情绪对于股价的影响,主要使用NLP的方法来做情绪分析并进行量化。 数据爬取 评论数据依赖包:requests、bs4、time、random、csv、numpy。获取由服务器传送来的HTML代码:
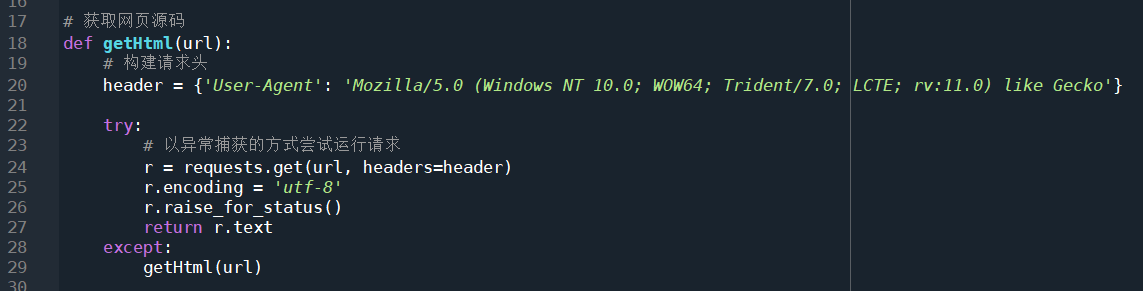
这里定义一个获取网页代码的方法,先构建请求头,来将爬虫伪装成正常的浏览器请求,这里的User-Agent字段告诉对端服务器,请求发送方是一个使用火狐Mazilla/5.0内核的浏览器,因为部分网站会对爬虫做限制,所以必要的伪装是要有的。 22行代码是一条try语句,在try内部的语句是有可能报错的,所以要使用except来捕获异常,并执行异常处理。这使用try是因为requests语句有可能会无法访问到url所指向的服务器,此时requests就会产生一条异常从而使程序退出,当异常发生时,由except捕获,并重新尝试访问url。 获取网页源码:
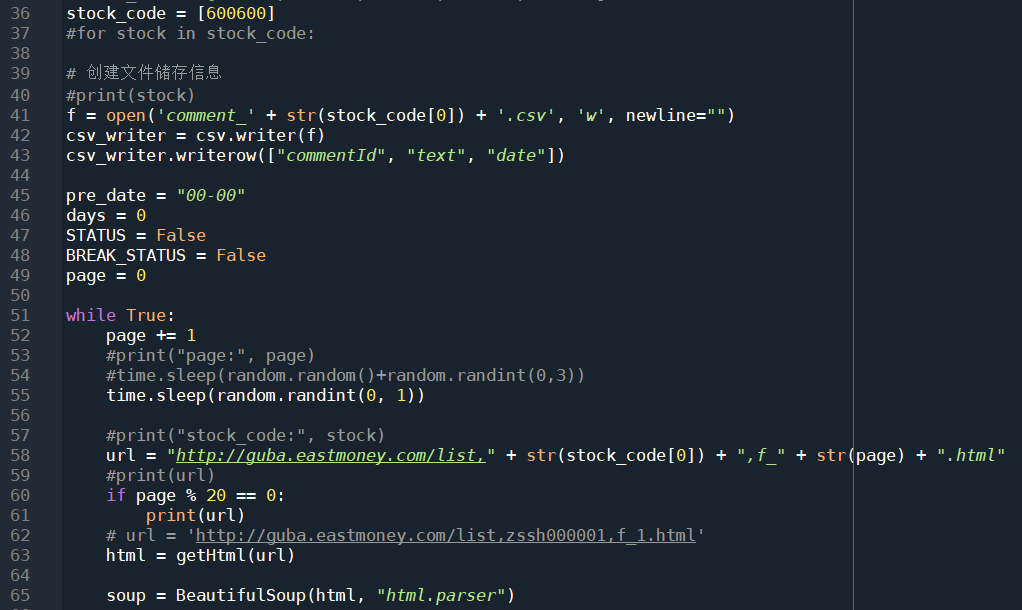
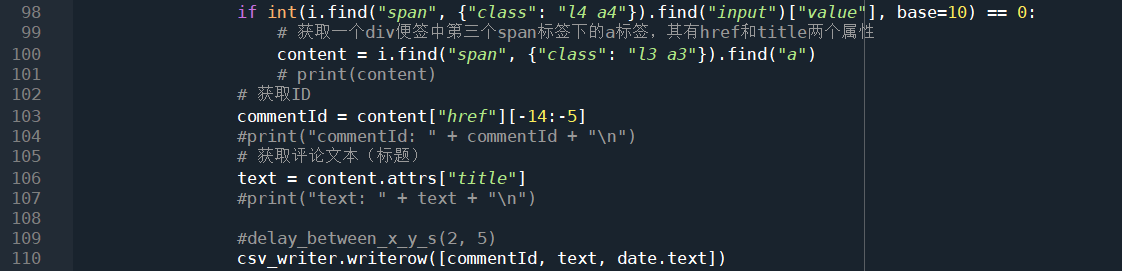
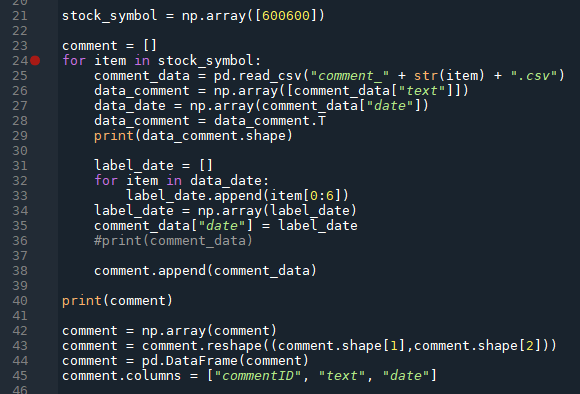
这里开始是开始构建url及请求数据。36行定义了股票代码,本次作业使用的股票是青岛啤酒,股票代码为600600。41行创建一个csv文件,并写入文件头。接下来的45~49这五行暂时跳过,这里涉及后面的代码。接下来写一个死循环,不断地遍历评论页,直到满足特定条件。在请求之前是程序随机休眠0到1秒,模拟用户不定时点击。构建url的时候要使用f_这个参数,这个参数指定了网页端的评论数据按照发布日期排序,这样爬下来的数据才是有序的,否则后面还要手动排序。每20页打印一次当前的url,防止程序崩溃死锁没有任何提示。然后63行开始调用上面定义的函数,获取网页源码,使用BeautifulSoup方法将源码还原出来。 接下来是爬虫爬取页面的开始以及结束条件,这里比较复杂。
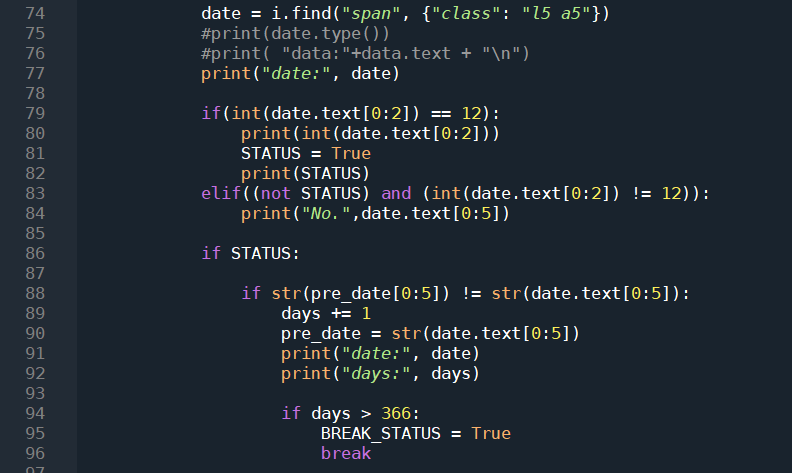
上面定义了5个参数,就是这里使用的。74行,获取当前评论的发布时间,时间格式是mm-dd;79行,判断日期的前两个字符是否为12,也就是说倒序爬取评论,开始的时间要从一年的最后一天开始计算,一旦满足了这个判断,一定说明这条评论发送自12-31这一天,将代表爬虫工作状态的STATUS变量修改为True,从此时开始爬虫正式开始工作;否则,什么都不做,继续爬取下一条评论,此处的判断由86行决定;86行,前面判断了STATUS为True,此时,开始判断有没有满足爬虫结束的条件,我将爬虫结束的条件设置为爬满365天即截止,变量名为days,此处的判断逻辑是,如果当前评论的额日期与上一条评论的日期不相同,则days+1,否则不变,pre_date默认值为00-00,这就保证了可以正确开始;94行判断是否足够一整年,如果满足条件,将退出条件BREAK_STATUS修改为True,然后使用break语句退出当前循环,此处的BREAK_STATUS并不是为了退出当前循环,而是为了退出外层循环而设置的条件。
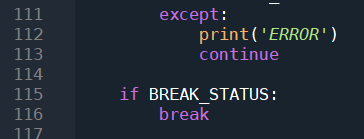
在整个过程中,任何一部的错误都会导致异常,所以全程需要套在try里面,except捕获到错误重新运行一遍,此时判断外层循环的退出条件BREAK_STATUS,如果满足,退出最外层循环,也就是那一层死循环。 源码解析,获取评论数据:
当前面的一切判断条件均满足,此时才会真正的解析评论,获取评论id及内容,并将其写入csv文件。 整个爬取过程放在腾讯云服务器上运行,使用conda环境。
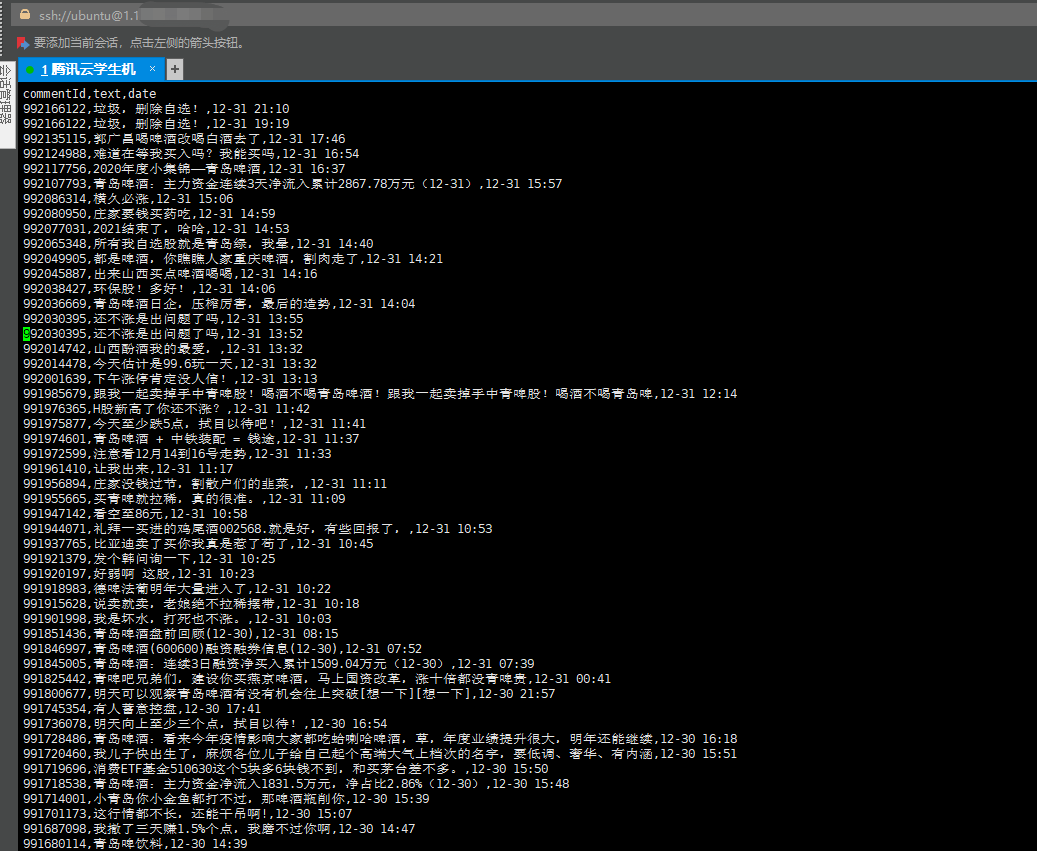
爬取结果:
构造requests请求头:
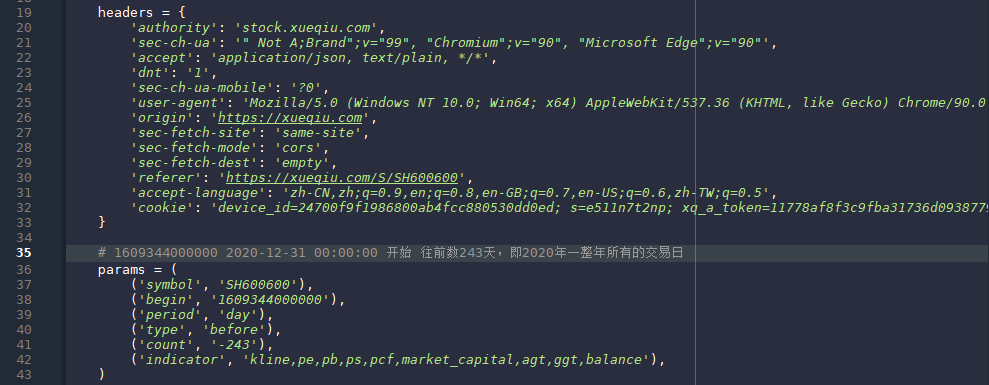
股票交易数据的爬取网站:https://xueqiu.com。36行的params定义了请求是所使用的参数,其中symbol是股票代码;begin是开始爬取的时间,这里的1609344000000是毫秒计数的时间戳,真实时间是2020-12-31 00:00:00;period是定义爬取日线、周线、月线、季线,这里的day代表爬取日线;type是从后往前爬取,所以定义为before,如果从前往后爬取,则定义为after;count代表爬取的K线数,这里的-243代表先前爬取243个交易日;最后一个参数indicator是指定爬取哪些数据,这里是网站默认的,尽量不做修改。上面的参数全部可以自定义,满足不同的数据爬取要求,对比股吧的股票交易数据,这个网站的交易数据可以自定义,而股吧一次性传输一批数据,而且有可能要求的时间段不会再一个网络包全部传送来,还要再请求第二个甚至第三个才可以。
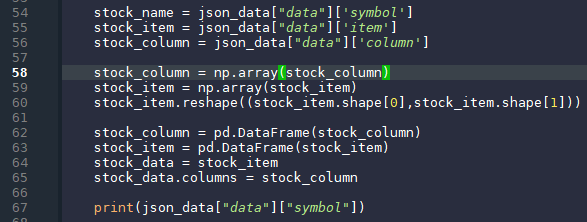
获取数据之后,使用json进行解析。 数据合并:
54行开始就是将json数据读取出来。 时间戳转换:
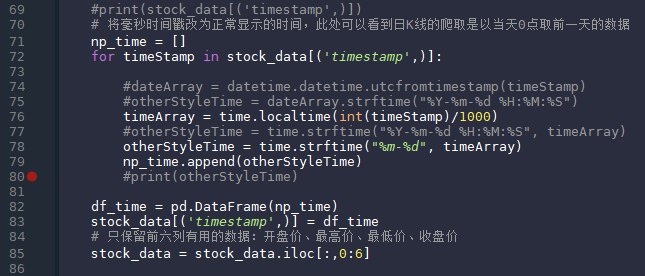
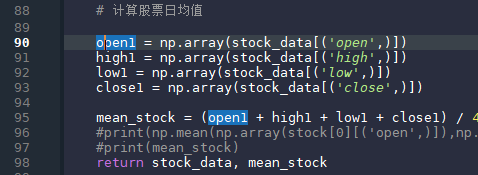
雪球这个网站使用毫秒计数的时间戳,所以爬取下来的数据需要转换成正常的时间格式。最后只保留前六列数据。 画图-日均线 计算日均线
此处不使用开盘价或者收盘价,而是使用均价,这样会相对平滑一些。这里使用python的矩阵计算,不用对每一笔数据单独相加,直接将所有交易日的开盘价、最高价、最低价、收盘价相加,这样python会自动识别,对应相加,再除以4得到均价。 画日均线
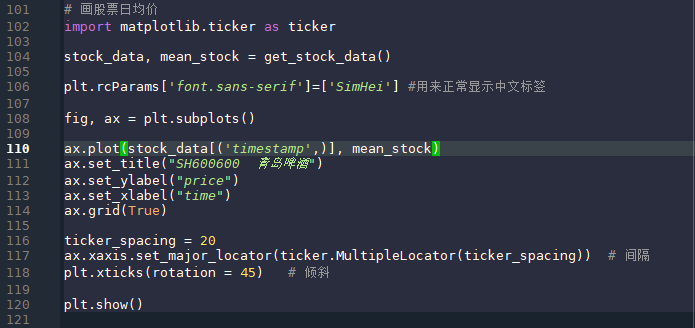
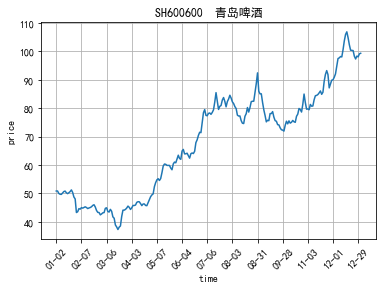
106行的plt.rcParams[‘font.sans-serif’]=[‘SimHei’]用来正常显示中文,不同的终端可能不需要这一条语句。定义fig和ax,fig是图的框架,ax是具体的图。118行定义x轴标签旋转的角度,如果不定义的话就会比较挤,甚至字符有可能会重叠,这里旋转45°。 效果如下图:
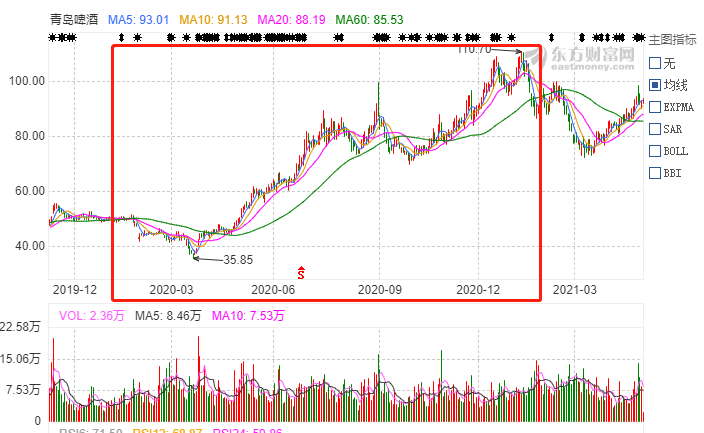
青岛啤酒的实际均线:
对比两张图可以看出均线走势相同,数据爬取以及交易数据处理正确。 股票评论数据处理
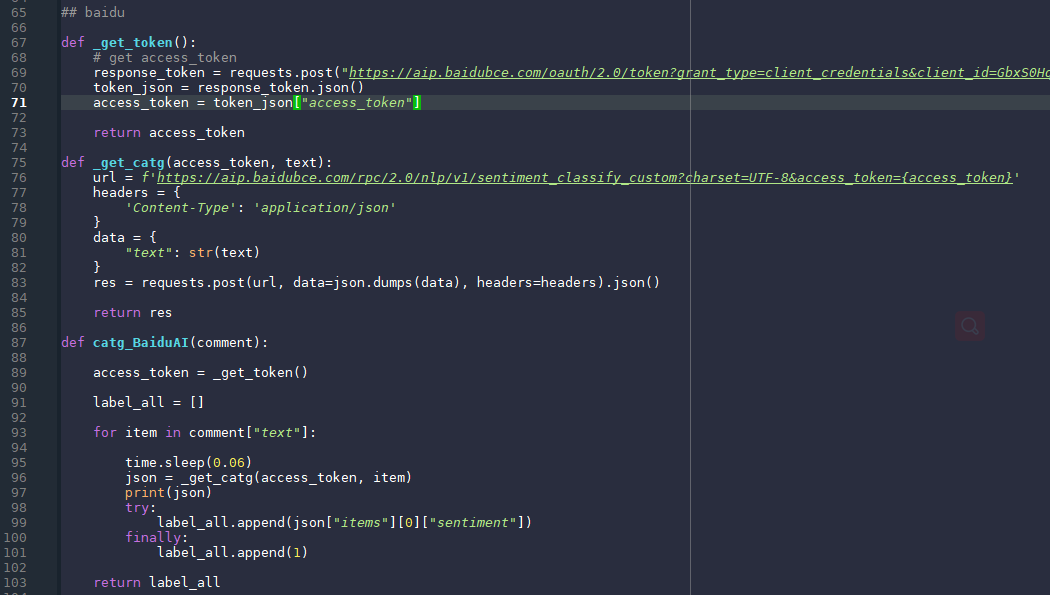
32行的for循环做时间转换,前面时间戳转换时将时间戳转为正常格式,这里将正常格式的数据分割,取前6个字符,重新赋值为date字段。 将转换完成的数据读取出来,保存在comment变量中。 股票评论分析 评论标注评论的标注使用三种方法:手动标注、Jiagu、BaiduAI训练自定义模型标注。 这里使用手动标注和Baidu AI。 首先在爬取的csv文件中取1000条数据,将其手动标注为积极与消极两个类别,在将这两类分别放在两个不同的txt文件,以方便后期将数据导入到BaiduAI去自定义模型。 BaiduAI首先登陆百度AI开放平台 (ai.baidu.com),登录之后建立一个定制自然语言处理模型,模型的训练数据就是之前手动改分出的100条积极与消极数据,然后开始训练,100条数据大约需要训练10分钟到半小时,因为这里的模型需要各种验证及防止过拟合等操作,所以会比较慢,训练数据越多速度越慢。训练完成之后会给出一个训练正确率,手动标注的1000条评论正确率为74%左右,百度给出的通用验证只有不到70%,因为这里的通用验证集使用的不是股票评论,而是购物评论,所以模型在通用数据集上的正确率较低,在股票数据集上的正确率才可以真正反映该模型的效果。训练完成后需要是模型生效,生效就是将定制化模型部署在百度AI平台,然后需要通过API方式进行调用。 下面是调用的代码:
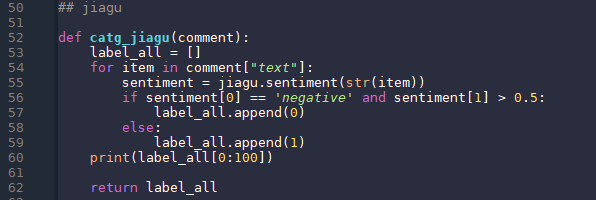
调用之前需要先获取token,此处的token是独有的,用来指定定制化模型,并验证调用者身份,此处的_get_token()函数就是定义如何获取token;_get_catg()函数定义了调用的过程;catg_BaiduAI()函数遍历每一条评论,将评论数据取出,通过get方法获取到返回内容,并且将其json格式解析出情感类别;并将所有类别append到all变量中,返回值为all变量。 jiaguJiagu使用大规模语料训练而成。将提供中文分词、词性标注、命名实体识别、情感分析、知识图谱关系抽取、关键词抽取、文本摘要、新词发现、情感分析、文本聚类等常用自然语言处理功能。参考了各大工具优缺点制作。 提供的功能有: 中文分词、词性标注、命名实体识别、知识图谱关系抽取、关键词提取、文本摘要、新词发现、情感分析、文本聚类、等等。。。 项目地址:https://github.com/ownthink/Jiagu.git 更多中文NLP项目Github地址,Jiagu是其中相对来说简单易用项目:https://github.com/crownpku/Awesome-Chinese-NLP.git 下面是jiagu的使用代码:
Jiagu.sentiment(str)方法会利用训练好的模型,自动分类str字符串,返回值是一对KV值,第一个值是说明改字符串为正类还是负类,第二个值是对应于这个类别的概率。将所有的类别信息append到all变量中,返回值为all变量。 数据合并
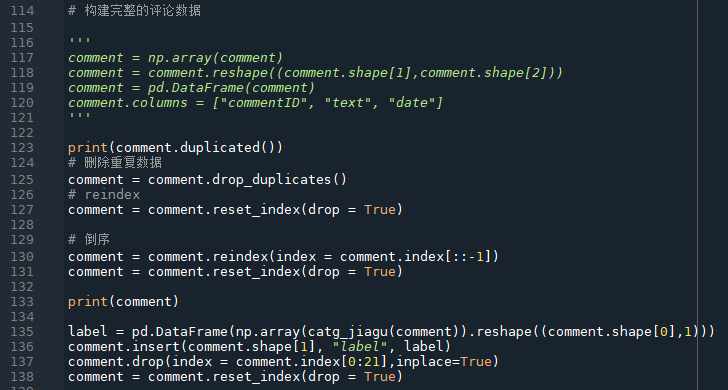
第123行,判断评论数据中是否有重复数据;125行,删除评论数据中的重复数据;删除之后,DataFrame不会重新排序,使用reset_index方法来重新排序;因为爬取的数据是倒序的,时间从后向前,所以130行使用reindex方法将评论逆置,然后重新排序;此时评论数据已经正确,接下来将之前生成的label数据加入到评论数据中;删除一些多余的数据,重新排序。 最后将评论数据保存为新的csv文件。后面是计算全部依赖该csv。 情绪计算
分析数据
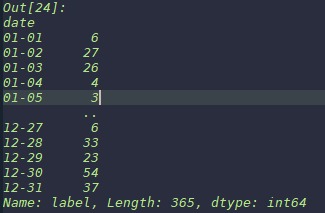
首先读取上一步生成的csv文件,17行,将date这一列做groupby,类似于SQL中的groupby,这里将相同日期的评论绑定在一起,然后计算每一组的评论数。输出如下:
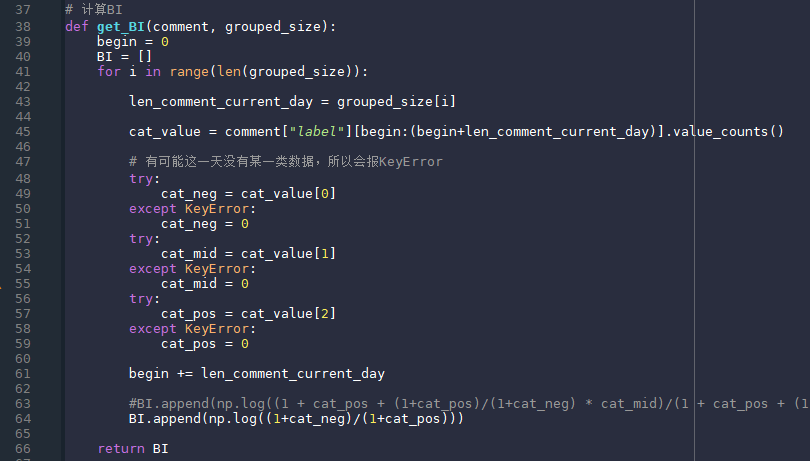
计算评论数是为了后面计算情绪指数做准备。 计算BI
BI的计算公式如下:
其中,M_p是正类的数量,M_n是负类的数量,加一是为了防止出现零值,此处还长是使用了另外一种BI计算方法,算法如下:
这个公式不仅考虑了正类与负类,还考虑了中性类别,但是分类结果并不好,所以没有使用该公式。 这里将赋值语句全部放在try中运行是因为某一天的评论数据有可能全部都是积极的或者都是消极的,没有其他类别,这样的话在公式中的解决方案就是加1,在代码里面的解决方案就是异常捕获以及异常处理。 计算自定义情绪指数
SI的计算方式要简单很多,直接计算正类或者负类在全部数据中的占比,公式如下,这里以正类为例:
这里使用异常捕获的原因在上一条中已经列明。这里使用value_counts()函数,其中参数为normalize,这个参数设置为True则代表要将计算各个值的占比,这样就不用自己定义一个计算占比的函数,节省运行时间,提高运行效率。 画情绪曲线
由于这一部分涉及到的方法比较多,所以包引用也很多。
首先读取股价数据以及股价均值。 接下来就是正式画图:
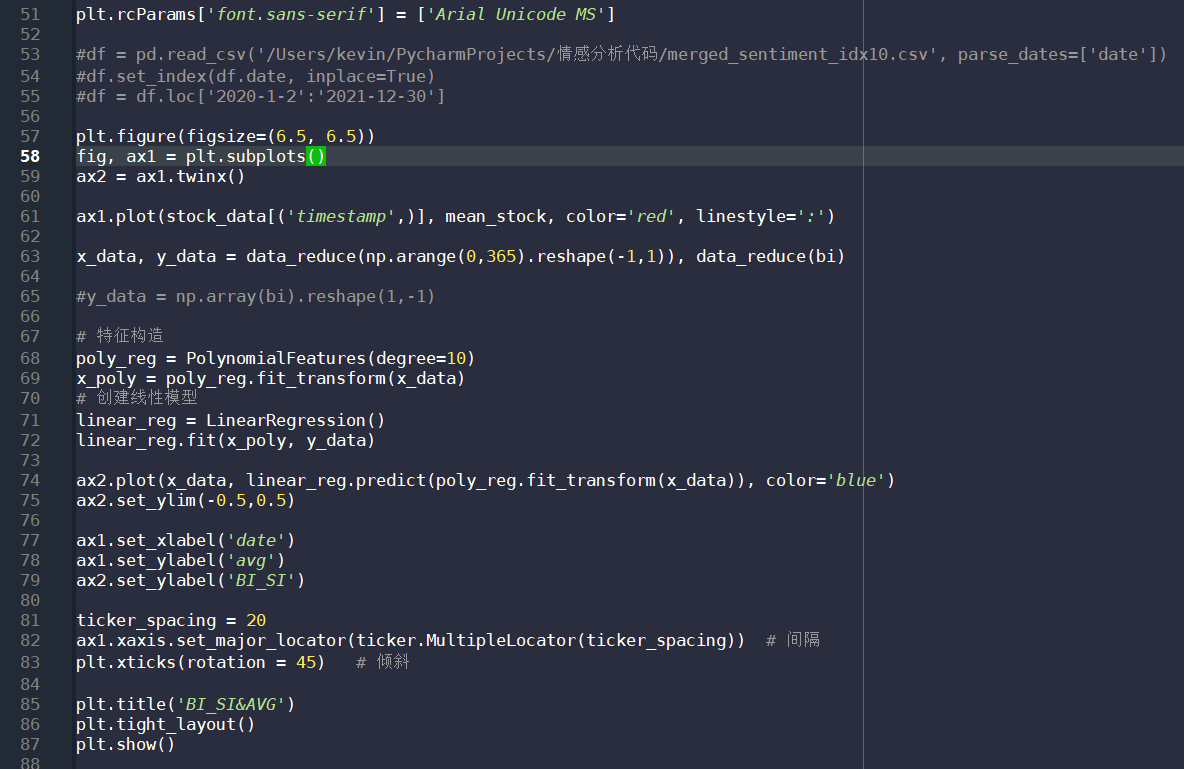
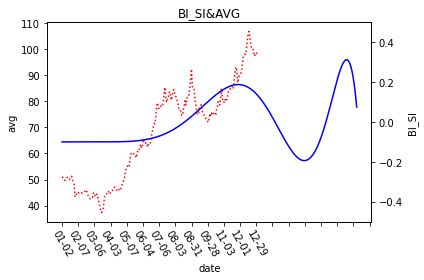
51行语句是确保画图时可以正常显示中文;57行定义一个6.5*6.5的图;因为要将两条线(股价均线、情绪曲线)话在同一张图上,所以59行定义了一个共享轴,ax1与ax2共享x轴;61行将股价均线画出来,颜色是红色,形式是点状线;63行读取之前计算的情绪数值;这里我并不是直接将情绪指数的值连成一条曲线,而是要寻找一条曲线,去拟合当前的情绪指数,这样做的话就可以在最大程度上避免数据震荡造成的曲线震荡,以至于很难看出其中的趋势变化,这里调用了sklearn这个机器学习包,选择其中的多项式拟合算法,在68行,多项式的特征数也就是项数定义为10,这个数据是在尝试了不同数值之后得到的相对较好结果,既没有过拟合,也在一定程度上可以表达出趋势变化,69行让模型去拟合,71行定义一个回归模型,让误差缩小,72行去拟合降低误差,这样就得到了一个尽量优秀的多项式模型;74行之后就是将拟合得到的情绪曲线画出来。如下图所示:
Tags: Machine Learning, NLP, Python, sklearn, Spyder Categories: Blog, Tech Updated: May 31, 2021 Twitter Facebook LinkedIn |



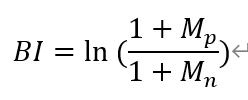
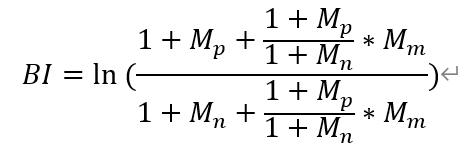
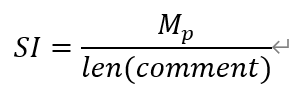
【本文地址】