NLP |
您所在的位置:网站首页 › ngram词向量 › NLP |
NLP
|
Word2vec 词向量
前置知识:需要理解基本的MLP 多层感知机(全连接神经网络) 和DL、数学相关基础知识 One-hot encoding 独热编码 刚开始,人们用one-hot编码来表示词,可见是非常低效的,因为表示每个词的向量维度都非常的高,每个词的维度都是整个词汇表的大小,一个单词可能就几万维的向量,大量冗余,而且无法反应词与词之间的关系
Word Embedding 词嵌入 我们把One-hot编码看成一个向量空间,经过转化,将其降维,并且其中每个词的位置关系可以反应词与词之间的语义关系。 我们在做英文阅读理解的时候,如果遇到一个生僻词,我们一般是通过它的上下文关系来分析,基于这个思路,我们可以假设:语义相似的词拥有相似的Context 上下文。 因此我们也有了基本的思想:拥有相似的Context 上下文的词的语义是相似的,对应的词向量也是相似的 对于以上基本思想,有两种方案: Couting-based Approach 如果单词在相同的上下文出现的次数越多,那就说明它们越相似。eg:Glove Prediction-based Approach 训练一个神经网络,输入上下文,预测一个单词,也就是输出一个词向量(word vector),预测的这个单词肯定是符合这个Context的。eg:word2vec Couting-based ApproachCouting-based Approach:the vector space model 向量空间模型 这个技术非常老,但是非常重要,是information retrieval 信息检索里面非常核心的一个技术 它使用的一个方案是 Term-Document Matrix 词频-文档矩阵,例如: 水平表示文档,垂直表示单词,表示某单词在某文档中的出现次数 对于文档,例如d1: vector of d1 = [0,4,1,4,8]对于单词,例如pusing: vector of “pusing” = [4,5,1,3,30]通过单词,我们构造出了文档对应的向量,通过文档,我们构建出了词向量。 对于文档来说,如果两个文档向量相似,我们就可以说这两个文档相似;对于单词,如果两个单词向量相似,我们也可以说这两个单词相似,就可以以此来判断文档相似性和单词相似性。 思考一个问题:每个文档中出现单词的个数是不是越多越好呢? 我们可以看出,某一文档中某单词出现的次数其实也能反应出该单词对于该文档的重要性,实际情况中并不是越多越好,因为有很多常用的冠词或其它词,例如 ‘a’ 或 ‘the’,这些单词并没有什么用,但是这些单词出现的次数越多,对应的重要性也会更大,这是不合理的。相对的,一些比较罕见的单词出现,它反而不敏感了。对词频-文档向量的改进方案 方案:给词频加一个权重 t f − i d f w , d = t f w , d ∗ l o g ( N d f w ) tf-idf_{w,d} = tf_{w,d} * log(\frac N {df_w}) tf−idfw,d=tfw,d∗log(dfwN) df_w:逆文档词频,包含该词的文档数目N:文档总数tf_w,d:文档词频,某词在文档中出现的次数它在原来词频的基础上做了一个惩罚,如果某词在很多文档都出现,那就说明它没那么重要 例如上方矩阵中的单词 “sakit” :tf-idf = [4,6,0,4,25] * log(5/4) tf:term frequence 词频 w,d:这里的下标w表示word,d表示document 存在的问题: 这个tf-idf向量有着和one-hot encoding同样的问题,虽然词频向量的维度也不是词汇表的大小了,但是它等于所有文档的个数,我们已有的文档可能几万个甚至更多,这个数字说不定比词汇表的数目还大。因此tf-idf仍然不适合用在NLP中。 虽然tf-idf向量能够表达词之间的相似性了,但是太长了,并且太稀疏 (sparse) 了,这里的稀疏是说,向量中有许多的元素为0,因为现实中众多文档中出现该词的文档数量可能并没有那么多。假设一共1w个文档,某个单词只在其中2个文档中出现,那么它的向量维度也是1w,并且有大量的0。 Prediction based ApproachPrediction based Approach:word2vec 基于预测的词向量 word2vec:word to vectorword2vec是一个学习词向量的一个框架(framework),上方的tf-idf向量方法是基于统计的 基本思想:我们有一个很大的文本数据库,把每个单词表达成可学习的向量,在每一个文档当中遍历每一个单词,把遍历到的每一个单词认为是中心词,把该词周围的词称为Context words 上下文单词,然后根据每个单词的上下文关系对每个单词的相似度做一个计算,得到词与词之间的相似性关系,利用这个相似性关系构造一个概率,例如: we have a large corpus of text. 当中心词为large时,已知上下文:we have a _____ corpus of text,预测该词为large的概率,如果说能预测出该词为large,那就说这个上下文中这六个单词的词向量可以反映出该单词的语义。假设这个词向量是准确的,我们用上下文词向量来预测该词向量,如果能预测出来,那就说明确实是准确的,如果不能预测出来,我们就根据预测的误差来调整模型 上述只是简单的介绍了idea,接下来讲述具体是怎么做的
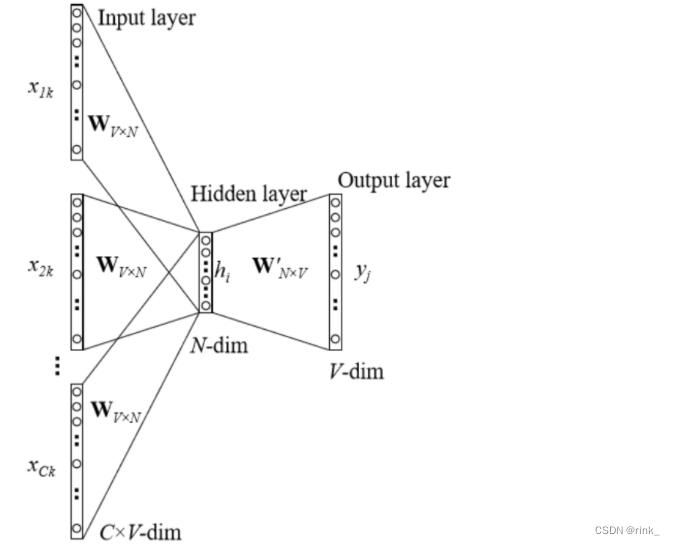
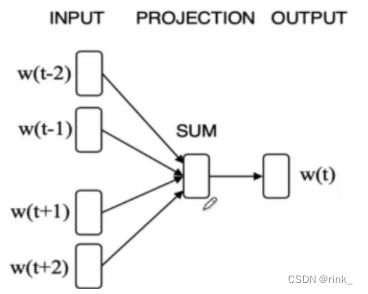
假设单词banking是上下文的几个单词共同决定的,所以对于周围的单词,都有一个预测单词为 “banking” 的条件概率 我们看到 “turning” ,那么我们有多大概率看到 “banking” 呢基本思想已经有了,关于具体是怎么操作的,有两种模型: Mikolov’s CBOW CBOW ModelCBOW:Continuous Bag Of Words 连续词袋模型 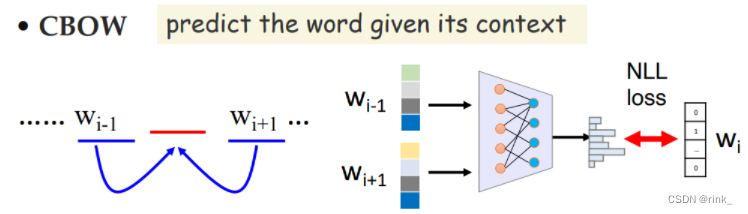
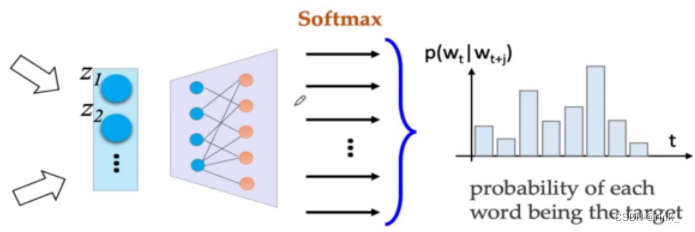
这是一个比较经典的模型 P ( w t ∣ w t − k . . . w t − 1 , w t + 1 . . . w t + k ) = s o f t m a x ( N N ( V ( w t − k ) + . . . + V ( w t + k ) ) ) P(w_t|w_{t-k}...w_{t-1} ,w_{t+1}...w_{t+k}) = softmax(NN(V(w_{t-k})+...+V(w_{t+k}))) P(wt∣wt−k...wt−1,wt+1...wt+k)=softmax(NN(V(wt−k)+...+V(wt+k))) V(w):表示某一word的词向量把上下文单词的词向量全部加起来然后输入neural network做一个softmax多分类任务,softmax方式预测出来的是一个概率分布,词汇表中的每一个词都会得到一个概率
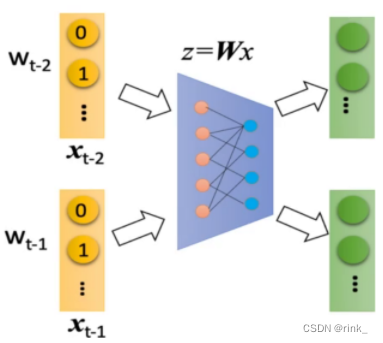
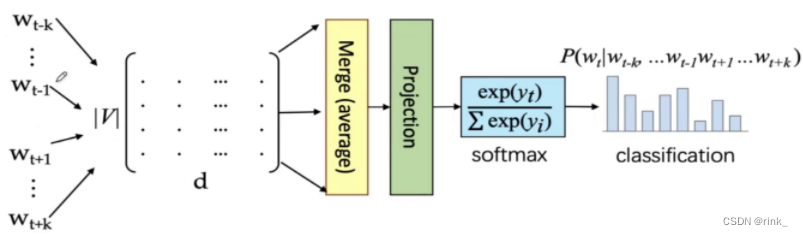
在基本思想中,我们提出要把每个单词表达成一个可学习的向量,这个操作是如何实现的呢? 公式: z i = W x i z_i = Wx_i zi=Wxi W矩阵: 词汇表矩阵,该矩阵中第一行对应词汇表中第一个单词的词向量,第二行对应词汇表中第二个单词的词向量…W开始用一个随机初始值,之后通过向量的位置关系预测出这个矩阵的值,这个矩阵是可学习的,这里先不细说对于某一个单词,输入其对应的one-hot向量,经过一个矩阵变换,转为可学习的"浓缩"后的低维词向量,这个z_i就是我们要的可学习的词向量。 表面上看它是在乘以一个矩阵,本质上它是在这个one-hot向量中找 1,也就是从词汇表矩阵W中找到输入的词对应的词向量,输入的one-hot向量本质上是输入了一个该词在词汇表中的位置,可以尝试动手计算一下,确实是这样的。 z = Wx这个操作是由一个神经网络来完成的,因此W是神经网络学到的,而不是我们事先确定的 输入一个w,输出向量z,如果输出的向量z最终表示的词不是我们想要的,那么会返回损失让神经网络进行更正,最终通过训练,神经网络自己确认得到合理的W矩阵,也就是说,每个词的词向量是神经网络自己学到的,我们并不知道为什么某个词对应的词向量是这样。
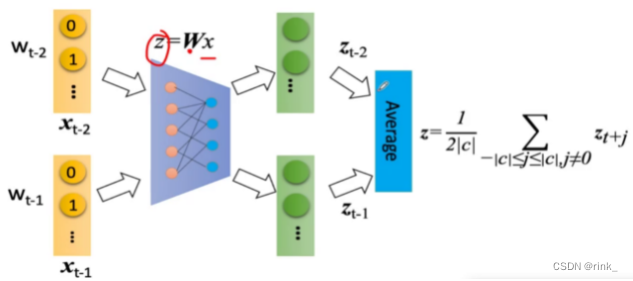
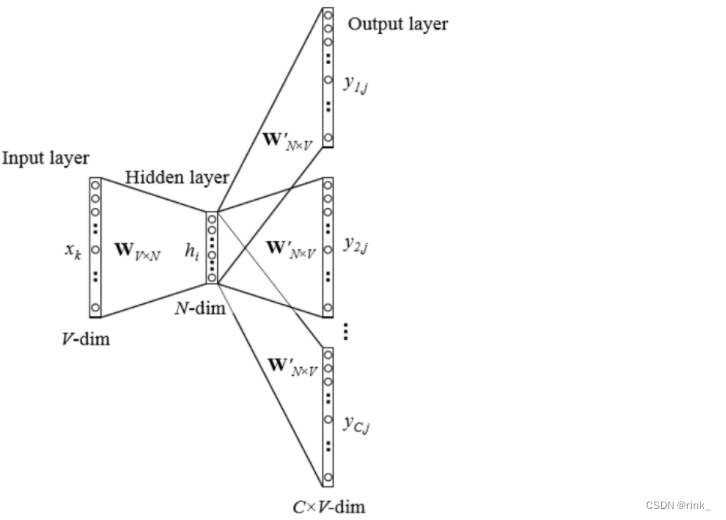
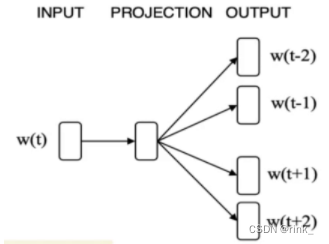
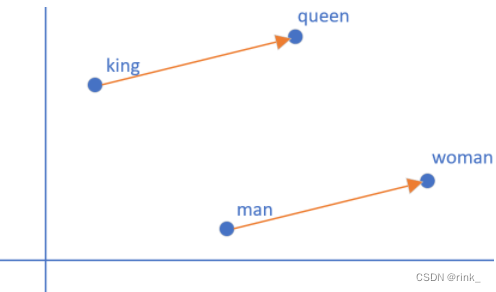
输入的w就是上下文单词的词向量,经过神经网络后转为可学习的词向量z,因为只预测一个单词,并且要预测的单词的信息就在这些上下文单词的词向量中,因此我们把这些上下文单词的词向量做一个平均,也就是一个信息融合 把信息融合(浓缩)后的词向量输入到做Softmax多分类任务的神经网络中输出概率分布做判断即可。 假设词汇表有1w个单词,本质上我们做一个1w个类的分类任务即可 损失函数:交叉熵,做训练即可 Training 损失函数:(其实就是交叉熵) L ( W , U ∣ D ) = − 1 N ∑ t − 1 N l o g p ( w t ∣ w t − k . . . w t − 1 , w t + 1 . . . w t + k ) L(W,U|D)= -\frac 1N\sum ^N_{t-1} logp(w_t|w_{t-k}...w{t-1},w_{t+1}...w_{t+k}) L(W,U∣D)=−N1t−1∑Nlogp(wt∣wt−k...wt−1,wt+1...wt+k) Skip-gram ModelSkip-gram 连续跳字模型 模型结构: 可以看出和CBOW整体没什么太大区别,只是相反而已。 CBOW是根据context word预测target word,而Skip-gram是根据target word预测context word 因为有多个输出结果,将多个输出结果的损失累加起来作为一个iter的损失,然后再算一个batch的平均损失 word2vec的效果词向量提出距今差不多也快10年了,在词向量之前,人们普遍用的方式都是tf-idf向量,词向量的出现使得我们对词的理解有了质的飞跃,他有多么神奇,可以看以下几个案例: 词的位置关系反应了词的含义之间的联系 我们事先只是找几篇文章让它去读,去做完形填空,然后它就可以以自己的方式(词向量)理解词的含义了,并且不需要人工标注,从中也可以看出,word2vec是 unsupervised learning 原本设想的是,word2vec能把单词的语义反应出来就已经很了不起了,但是它还有一个令人意想不到的功能,也就是 词推理 Word Analogy 词推理 例如:单词的类比推理 a : b,c : _ d man : woman,king : ___ queen它是如何做词推理的呢?这里以类比推理 a : b,c : _ 为例: d = a r g m a x ( x b − x a + x c ) T x i ∣ ∣ x b − x a + x c ∣ ∣ d = argmax\frac {(x_b-x_a+x_c)^Tx_i}{||x_b-x_a+x_c||} d=argmax∣∣xb−xa+xc∣∣(xb−xa+xc)Txi 其实就是在向量空间中,将词向量a和b的位置映射到c这里,看看词向量c对应的该位置的词是什么例如这个公式,举一个例子,以数学角度来看,2和3相当于4和_,因为3 = 2+1,所以 _ = 4 + 1=5,这里的1也就是3-2。也就是说,(x_b-x_a)反映的是词向量a和词向量b的关系,然后把这种关系带给c,看看词向量c的这种关系对应的词向量是哪个通过 x_c + (x_b - x_a) 得到的词向量其实本质上是在反应一种关系,也就是从词向量c出发画一条向量,看看哪个词符合这种关系,我们要怎么确定找的是哪个词向量呢? 让算出来的这个词向量和x_i做一个内积,从几何上来看其实就是词向量x_i在算出来的这个词向量上作一个投影,然后选择投影后最大的词向量,这个词向量就是x_d。作的这个投影其实就是在反应该词和词c的关系与词b和词a的关系的符合程度。x_i:词汇表单词
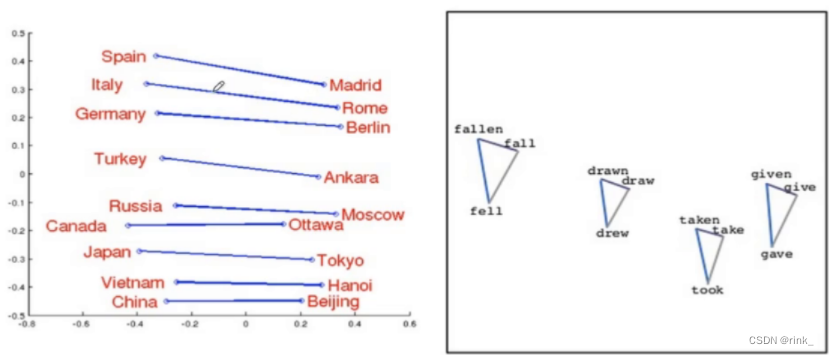
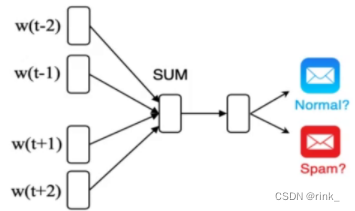
上方式子是推理得到关系后寻找最符合该关系的词的过程,本质上最主要的关系反应在于以下式子: V k i n g − V m a n + V w o m a n = V q u e e n V_{king} - V_{man} + V_{woman} = V_{queen} Vking−Vman+Vwoman=Vqueen 当然这个式子是近似成立的,标准的还要看上方式子,因为可能不存在完全相同的关系,但我们只需要寻找在已知词汇表中寻找最符合该关系的词即可 此外,如图所示,还可以反应国家和首都之间的关系 单词之间不同的形态也可以反应 word2vec也可以做分类任务,例如垃圾邮件识别 但是这种做法不合适,同时也引出了word2vec的局限性: 自然语言不仅仅只是一个包含多个单词的序列,而是多个单词以某种规律组合起来的序列,这种规律也就是我们常说的语法规则,word2vec只能学和理解每个word,但无法理解一个句子或者一段话是什么意思,它把句子中单词之间的关系丢了再回过头看看CBOW中的BOW,也就是 Bag-Of-Word,它是把一个句子看成一个袋子,里面装着很多的单词,但仅此而已,它把单词之间的关系丢掉了,但这种关系是非常重要的。例如: The food was good, not bad at all.The food was bad, not good at all.ps:本篇文章引用了 https://zhuanlan.zhihu.com/p/26306795 博客的两张图片,且该文章的讲解也很优秀,推荐阅读。 |

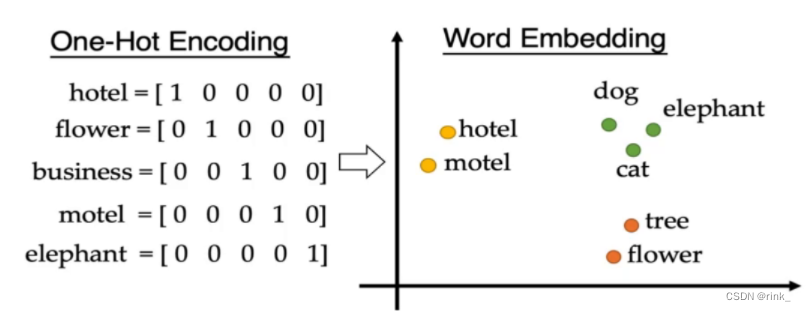 我们应该怎么去对词进行embedding呢?
我们应该怎么去对词进行embedding呢?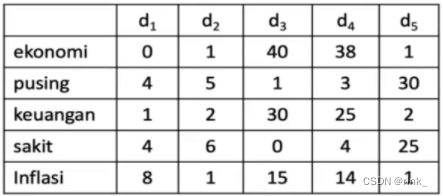 这就构成了两类向量:
这就构成了两类向量:
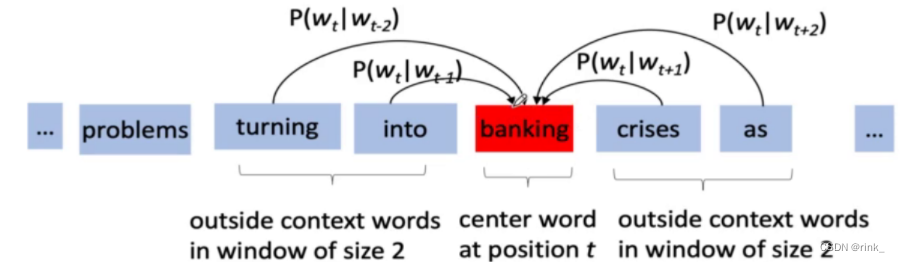

 损失函数:
L
(
W
,
U
∣
X
)
=
1
N
∑
t
−
1
N
∑
−
c
⩽
j
⩽
c
,
j
≠
0
l
o
g
(
p
(
w
t
+
j
∣
w
t
)
)
L(W,U|X) = \frac 1N\sum ^N_{t-1}\sum _{-c\leqslant j\leqslant c,j\not=0}log(p(w_{t+j}|w_t))
L(W,U∣X)=N1t−1∑N−c⩽j⩽c,j=0∑log(p(wt+j∣wt))
损失函数:
L
(
W
,
U
∣
X
)
=
1
N
∑
t
−
1
N
∑
−
c
⩽
j
⩽
c
,
j
≠
0
l
o
g
(
p
(
w
t
+
j
∣
w
t
)
)
L(W,U|X) = \frac 1N\sum ^N_{t-1}\sum _{-c\leqslant j\leqslant c,j\not=0}log(p(w_{t+j}|w_t))
L(W,U∣X)=N1t−1∑N−c⩽j⩽c,j=0∑log(p(wt+j∣wt))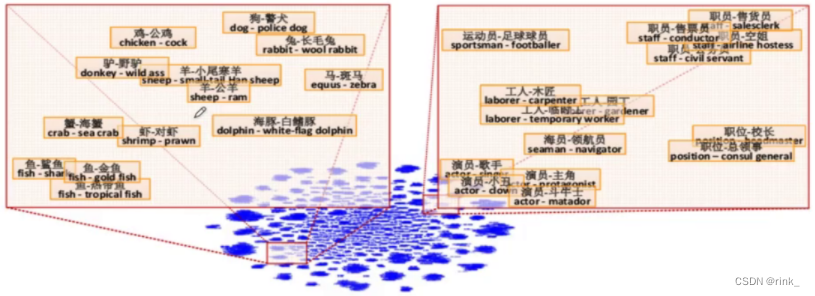
【本文地址】
今日新闻 |
推荐新闻 |